怎么用labelme标注交通灯
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么用labelme标注交通灯相关的知识,希望对你有一定的参考价值。
参考技术A LabelImg 是一个开源图像标注工具,它允许用户在图像上定义矩形框来标记目标对象,这些标记框可以用于训练深度学习模型。在使用 LabelImg 标注交通灯的过程中,需要先准备好包含交通灯的图像。然后打开 LabelImg,选择要标注的图片并绘制出交通灯所在的矩形框。在每个矩形框上添加一个对应的标签,例如 \"traffic light\" 或者 \"红绿灯\" 等等。重复此操作,直到所有的交通灯都被标注完毕。
在完成标注后,可以将标注结果以 XML 文件的形式保存下来,以便后续使用。这样,我们可以利用这些标注数据来训练深度学习模型,用于交通信号灯的检测和识别任务。
需要注意的是,在标注过程中,要尽量保证标注的准确性和一致性,避免重复标注和标注遗漏,以提高后续训练模型的效果
使用labelme标注数据集并转化为CoCo数据集
使用labelme标注数据
- 安装labelme
pip install lebelme - 安装完成后使用labelme
在命令窗口输入labelme
- 导入需要标注的数据
Open Dir -> 选择要导入的文件夹 -> 设置自动保存[左上角(File -> Save Automatically)]-> Create Polygons[左侧工具栏]
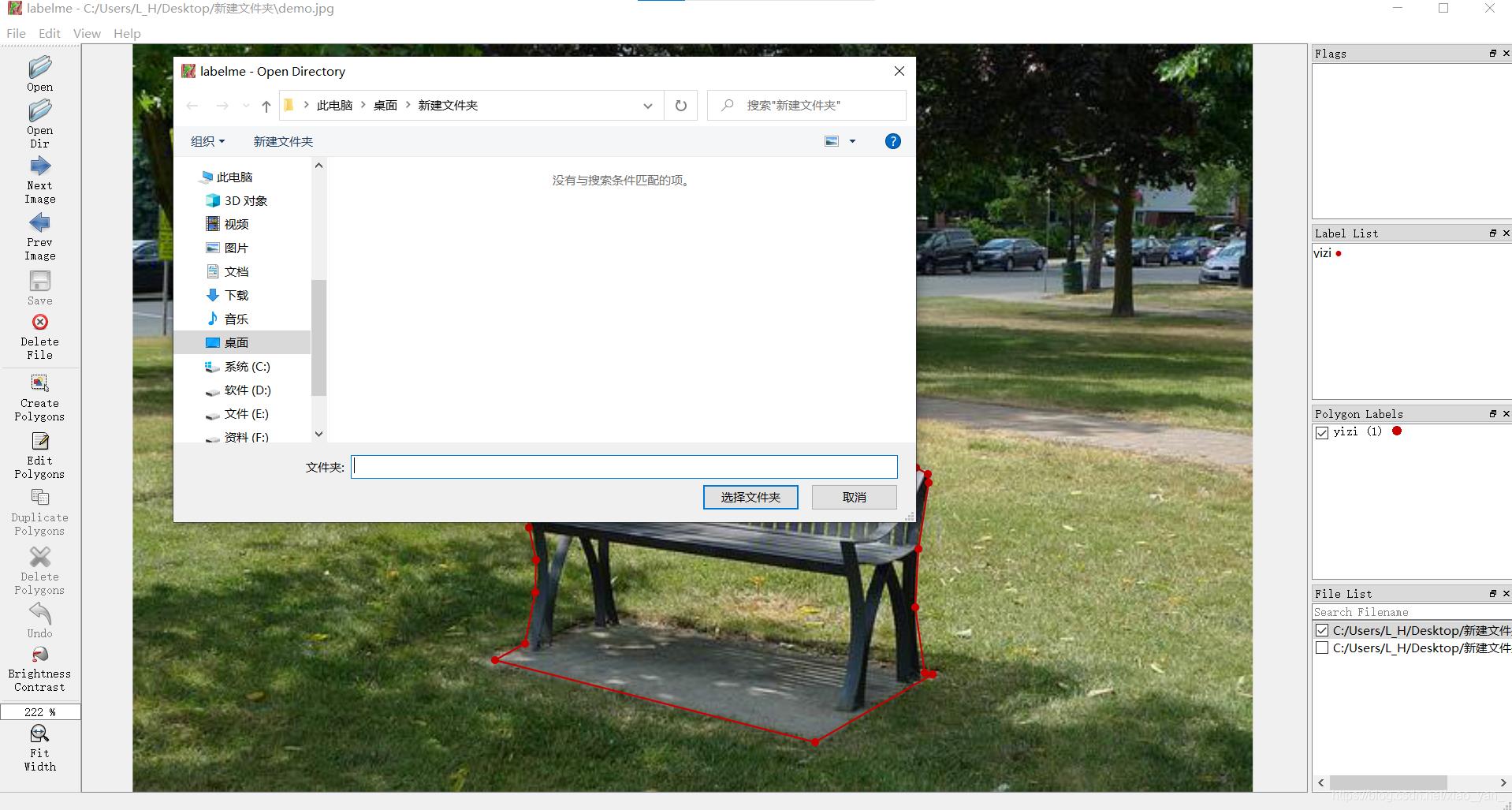
- 对图片进行标注
注意:
- 标注要准确,尽可能表的详细
- 标注物体时需要标注物体最大的范围
- 尽可能多的点去标记
产生的json文件(与标注文件在同一目录)

将labelme数据集转化为CoCo数据集
- rename.py
用于对数据集中图片以及json文件的重命名 - format.py
用于替换json中不合法的imagePath - checkClasses
用于检测当前一共标注了多少class 并对检测结果进行输出 - labelme2coco.py
用于生成coco形式的数据集
使用
rename.py文件
import os
this_dir_path = './'
json_index = 0 # 表示从那个序号开始更改.json文件名
png_index = 0 # 表示从那个序号开始更改.png文件名
for file in os.listdir(this_dir_path):
file_path = os.path.join(this_dir_path, file)
if os.path.splitext(file_path)[-1] == '.png':
new_file_path = '.'+'/'.join((os.path.splitext(file_path)[0].split('\\\\'))[:-1]) + '/{:0>4}_Color.png'.format(png_index)
png_index += 1
print(file_path+'---->'+new_file_path)
os.rename(file_path, new_file_path)
elif os.path.splitext(file_path)[-1] == '.json':
new_file_path = '.'+'/'.join((os.path.splitext(file_path)[0].split('\\\\'))[:-1]) + '/{:0>4}_Color.json'.format(json_index)
json_index += 1
print(file_path+'---->'+new_file_path)
os.rename(file_path,new_file_path)
format.py文件
import os
import re
dir_path = './'
pattern = re.compile('"imagePath": "(.+?png)",')
for file in os.listdir(dir_path):
if os.path.splitext(file)[-1] != '.json':
continue
with open(os.path.join(dir_path, file), encoding='utf-8') as f:
content = f.read()
imagePath = pattern.findall(content)[0]
print('imagePath ',imagePath)
new_content = content.replace(imagePath, os.path.splitext(file)[0]+'.png')
with open(os.path.join(dir_path, file), 'w', encoding='utf-8') as nf:
nf.write(new_content)
checkClasses.py文件
import os
import re
CLASS_NAMES = ['CA001', 'CA002', 'CA003', 'CA004',
'CD001', 'CD002', 'CD003']
CLASS_REAL_NAMES = ['draw_paper', 'roll_paper', 'toothbrush',
'tape','apple', 'pear', 'melon']
CLASS_NAME_DICT = {
'CA001': 'draw_paper',
'CA002': 'roll_paper',
'CA003': 'toothbrush',
'CA004': 'tape',
'CD001': 'apple',
'CD002': 'pear',
'CD003': 'melon',
}
dir_path = './'
pattern = re.compile('"label": "([A-Z]{2}[0-9]{3}(?:.+)?)",')
class_ids = []
for file in os.listdir(dir_path):
if os.path.splitext(file)[-1] != '.json':
continue
with open(os.path.join(dir_path, file), 'r+', encoding='utf-8') as f:
content = f.read()
image_class_ids = pattern.findall(content)
for id in image_class_ids:
if id not in class_ids:
if len(id) > 5:
print("Find invalid id !!")
content = content.replace(id, id[:5])
with open(os.path.join(dir_path, file), 'w', encoding='utf-8') as f:
f.write(content)
else:
class_ids.append(id)
print('一共有{}种class'.format(len(class_ids)))
print('分别是')
index = 1
for id in class_ids:
print('"{}",'.format(id), end="")
index += 1
print()
index = 1
for id in class_ids:
print('"{}":{},'.format(id, index))
index += 1
for id in class_ids:
print("'{}',".format(CLASS_NAME_DICT[id]),end="")
可以不适用ID,直接使用真实名字来标注!
import os
import json
import numpy as np
import glob
import shutil
import cv2
from sklearn.model_selection import train_test_split
np.random.seed(41)
# 0为背景
classname_to_id = {
"CA002": 1, # 从1开始标注
"CA004": 2,
"CA003": 3,
"CD006": 4,
"CD002": 5,
"CD001": 6,
"ZA001": 7,
"ZA003": 8,
"ZA002": 9,
}
class Lableme2CoCo:
def __init__(self):
self.images = []
self.annotations = []
self.categories = []
self.img_id = 0
self.ann_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1) # indent=2 更加美观显示
# 由json文件构建COCO
def to_coco(self, json_path_list):
self._init_categories()
for json_path in json_path_list:
obj = self.read_jsonfile(json_path)
self.images.append(self._image(obj, json_path))
shapes = obj['shapes']
for shape in shapes:
annotation = self._annotation(shape)
self.annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
instance = {}
instance['info'] = 'spytensor created'
instance['license'] = ['license']
instance['images'] = self.images
instance['annotations'] = self.annotations
instance['categories'] = self.categories
return instance
# 构建类别
def _init_categories(self):
for k, v in classname_to_id.items():
category = {}
category['id'] = v
category['name'] = k
self.categories.append(category)
# 构建COCO的image字段
def _image(self, obj, path):
image = {}
from labelme import utils
img_x = utils.img_b64_to_arr(obj['imageData'])
h, w = img_x.shape[:-1]
image['height'] = h
image['width'] = w
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
# 构建COCO的annotation字段
def _annotation(self, shape):
# print('shape', shape)
label = shape['label']
points = shape['points']
annotation = {}
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(classname_to_id[label])
annotation['segmentation'] = [np.asarray(points).flatten().tolist()]
annotation['bbox'] = self._get_box(points)
annotation['iscrowd'] = 0
annotation['area'] = 1.0
return annotation
# 读取json文件,返回一个json对象
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
# COCO的格式: [x1,y1,w,h] 对应COCO的bbox格式
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
if __name__ == '__main__':
labelme_path = "../../../xianjin_data-3/"
saved_coco_path = "../../../xianjin_data-3/"
print('reading...')
# 创建文件
if not os.path.exists("%scoco/annotations/" % saved_coco_path):
os.makedirs("%scoco/annotations/" % saved_coco_path)
if not os.path.exists("%scoco/images/train2017/" % saved_coco_path):
os.makedirs("%scoco/images/train2017" % saved_coco_path)
if not os.path.exists("%scoco/images/val2017/" % saved_coco_path):
os.makedirs("%scoco/images/val2017" % saved_coco_path)
# 获取images目录下所有的joson文件列表
print(labelme_path + "/*.json")
json_list_path = glob.glob(labelme_path + "/*.json")
print('json_list_path: ', len(json_list_path))
# 数据划分,这里没有区分val2017和tran2017目录,所有图片都放在images目录下
train_path, val_path = train_test_split(json_list_path, test_size=0.1, train_size=0.9)
print("train_n:", len(train_path), 'val_n:', len(val_path))
# 把训练集转化为COCO的json格式
l2c_train = Lableme2CoCo()
train_instance = l2c_train.to_coco(train_path)
l2c_train.save_coco_json(train_instance, '%scoco/annotations/instances_train2017.json' % saved_coco_path)
for file in train_path:
# shutil.copy(file.replace("json", "jpg"), "%scoco/images/train2017/" % saved_coco_path)
img_name = file.replace('json', 'png')
temp_img = cv2.imread(img_name)
try:
cv2.imwrite("{}coco/images/train2017/{}".format(saved_coco_path, img_name.replace('png', 'jpg')),temp_img)
except Exception as e:
print(e)
print('Wrong Image:', img_name )
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
for file in val_path:
# shutil.copy(file.replace("json", "jpg"), "%scoco/images/val2017/" % saved_coco_path)
img_name = file.replace('json', 'png')
temp_img = cv2.imread(img_name)
try:
cv2.imwrite("{}coco/images/val2017/{}".format(saved_coco_path, img_name.replace('png', 'jpg')), temp_img)
except Exception as e:
print(e)
print('Wrong Image:', img_name)
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
# 把验证集转化为COCO的json格式
l2c_val = Lableme2CoCo()
val_instance = l2c_val.to_coco(val_path)
l2c_val.save_coco_json(val_instance, '%scoco/annotations/instances_val2017.json' % saved_coco_path)
将图片转化为JPG格式,并且自动生成CoCo数据集
以上是关于怎么用labelme标注交通灯的主要内容,如果未能解决你的问题,请参考以下文章