什么叫缓存?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么叫缓存?相关的知识,希望对你有一定的参考价值。
所谓的缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例。这样做可以减少系统开销,提高系统效率。
1、通过文件缓存;顾名思义文件缓存是指把数据存储在磁盘上,不管你是以XML格式,序列化文件DAT格式还是其它文件格式;
2、内存缓存;也就是创建一个静态内存区域,将数据存储进去,例如我们B/S架构的将数据存储在Application中或者存储在一个静态Map中。
3、本地内存缓存;就是把数据缓存在本机的内存中。
4、分布式缓存机制;可能存在跨进程,跨域访问缓存数据
对于分布式的缓存,此时因为缓存的数据是放在缓存服务器中的,或者说,此时应用程序需要跨进程的去访问分布式缓存服务器。

扩展资料
当我们在应用中使用跨进程的缓存机制,例如分布式缓存memcached或者微软的AppFabric,此时数据被缓存在应用程序之外的进程中。
每次,当我们要把一些数据缓存起来的时候,缓存的API就会把数据首先序列化为字节的形式,然后把这些字节发送给缓存服务器去保存。
同理,当我们在应用中要再次使用缓存的数据的时候,缓存服务器就会将缓存的字节发送给应用程序,而缓存的客户端类库接受到这些字节之后就要进行反序列化的操作了,将之转换为我们需要的数据对象。
参考技术A缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。
由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。因为缓存往往使用的是RAM(断电即掉的非永久储存),所以在用完后还是会把文件送到硬盘等存储器里永久存储。
电脑里最大的缓存就是内存条了,最快的是CPU上镶的L1和L2缓存,显卡的显存是给显卡运算芯片用的缓存,硬盘上也有16M或者32M的缓存。

扩展资料:
硬盘的缓存主要起三种作用:
1,预读取
当硬盘受到CPU指令控制开始读取数据时,硬盘上的控制芯片会控制磁头把正在读取的簇的下一个或者几个簇中的数据读到缓存中(由于硬盘上数据存储时是比较连续的,所以读取命中率较高)。
当需要读取下一个或者几个簇中的数据的时候,硬盘则不需要再次读取数据,直接把缓存中的数据传输到内存中就可以了,由于缓存的速率远远高于磁头读写的速率,所以能够达到明显改善性能的目的。
2,写入
当硬盘接到写入数据的指令之后,并不会马上将数据写入到盘片上,而是 先暂时存储在缓存里,然后发送一个“数据已写入”的信号给系统,这时系统就会认为数据已经写入,并继续执行下面的工作,而硬盘则在空闲(不进行读取或写入的时候)时再将缓存中的数据写入到盘片上。
虽然对于写入数据的性能有一定提升,但也不可避免地带来了安全隐患——数据还在缓存里的时候突然掉电,那么这些数据就会丢失。
对于这个问题,硬盘厂商们自然也有解决办法:掉电时,磁头会借助惯性将缓存中的数据写入零磁道以外的暂存区域,等到下次启动时再将这些数据写入目的地。
3,临时存储
有时候,某些数据是会经常需要访问的,像硬盘内部的缓存(暂存器的一种)会将读取比较频繁的一些数据存储在缓存中,再次读取时就可以直接从缓存中直接传输。
缓存就像是一台计算机的内存一样,在硬盘读写数据时,负责数据的存储、寄放等功能。这样一来,不仅可以大大减少数据读写的时间以提高硬盘的使用效率。
同时利用缓存还可以让硬盘减少频繁的读写,让硬盘更加安静,更加省电。更大的硬盘缓存,你将读取游戏时更快,拷贝文件时候更快,在系统启动中更为领先。
缓存容量的大小不同品牌、不同型号的产品各不相同,早期的硬盘缓存基本都很小,只有几百KB,已无法满足用户的需求。
16MB和32MB缓存是现今主流硬盘所采用,而在服务器或特殊应用领域中还有缓存容量更大的产品,甚至达到了64MB、128MB等。大容量的缓存虽然可以在硬盘进行读写工作状态下,让更多的数据存储在缓存中,以提高硬盘的访问速率,但并不意味着缓存越大就越出众。
缓存的应用存在一个算法的问题,即便缓存容量很大,而没有一个高效率的算法,那将导致应用中缓存数据的命中率偏低,无法有效发挥出大容量缓存的优势。
算法是和缓存容量相辅相成,大容量的缓存需要更为有效率的算法,否则性能会大大折扣,从技术角度上说,高容量缓存的算法是直接影响到硬盘性能发挥的重要因素。更大容量缓存是未来硬盘发展的必然趋势。
参考技术B缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。
由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
因为缓存往往使用的是RAM(断电即掉的非永久储存),所以在用完后还是会把文件送到硬盘等存储器里永久存储。电脑里最大的缓存就是内存条了,最快的是CPU上镶的L1和L2缓存,显卡的显存是给显卡运算芯片用的缓存,硬盘上也有16M或者32M的缓存。
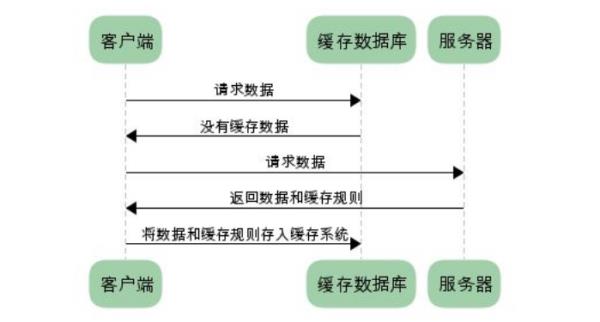
扩展资料
缓存工作原理:
缓存的工作原理是当CPU要读取一个数据时,首先从CPU缓存中查找,找到就立即读取并送给CPU处理;没有找到,就从速率相对较慢的内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在CPU缓存中,只有大约10%需要从内存读取。
这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
RAM(Random-Access
Memory)和ROM(Read-Only
Memory)相对的,RAM是掉电以后,其中的信息就消失那一种,ROM在掉电以后信息也不会消失那一种。
RAM又分两种,一种是静态RAM,SRAM(Static
RAM);一种是动态RAM,DRAM(Dynamic RAM)。前者的存储速率要比后者快得多,使用的内存一般都是动态RAM。
为了增加系统的速率,把缓存扩大就行了,扩的越大,缓存的数据越多,系统就越快了,缓存通常都是静态RAM,速率是非常的快, 但是静态RAM集成度低,价格高,由此可见,扩大静态RAM作为缓存是一个非常愚蠢的行为。
但是为了提高系统的性能和速率,必须要扩大缓存, 这样就有了一个折中的方法,不扩大原来的静态RAM缓存,而是增加一些高速动态RAM做为缓存,
这些高速动态RAM速率要比常规动态RAM快。
但比原来的静态RAM缓存慢, 把原来的静态RAM缓存叫一级缓存,而把后来增加的动态RAM叫二级缓存。
参考资料:百度百科-缓存
参考技术C缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。
因为缓存往往使用的是RAM(断电即掉的非永久储存),所以在用完后还是会把文件送到硬盘等存储器里永久存储。电脑里最大的缓存就是内存条了,最快的是CPU上镶的L1和L2缓存,显卡的显存是给显卡运算芯片用的缓存,硬盘上也有16M或者32M的缓存。
扩展资料
缓存的工作原理是当CPU要读取一个数据时,首先从CPU缓存中查找,找到就立即读取并送给CPU处理;没有找到,就从速率相对较慢的内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在CPU缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
参考资料来源:百度百科:缓存
参考技术D缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
因为缓存往往使用的是RAM(断电即掉的非永久储存),所以在用完后还是会把文件送到硬盘等存储器里永久存储。电脑里最大的缓存就是内存条了,最快的是CPU上镶的L1和L2缓存,显卡的显存是给显卡运算芯片用的缓存,硬盘上也有16M或者32M的缓存。
扩展资料:
工作原理
1、读取顺序
CPU要读取一个数据时,首先从Cache中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入Cache中,可以使得以后对整块数据的读取都从Cache中进行,不必再调用内存。
正是这样的读取机制使CPU读取Cache的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在Cache中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先Cache后内存。
2、缓存分类
Intel从Pentium开始将Cache分开,通常分为一级高速缓存L1和二级高速缓存L2。在以往的观念中,L1 Cache是集成在CPU中的,被称为片内Cache。
在L1中还分数据Cache(D-Cache)和指令Cache(I-Cache)。它们分别用来存放数据和执行这些数据的指令,而且两个Cache可以同时被CPU访问,减少了争用Cache所造成的冲突,提高了处理器效能。
3、读取命中率
CPU在Cache中找到有用的数据被称为命中,当Cache中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。从理论上讲,在一颗拥有2级Cache的CPU中,读取L1 Cache的命中率为80%。
参考资料:百度百科-缓存
看了阿里大佬用的本地缓存,那叫一个优雅!

本文经授权转载自微信公众号:阿里开发者,作者:杨贤(临景)
Java缓存技术可分为远端缓存和本地缓存,远端缓存常用的方案有著名的redis和memcache,而本地缓存的代表技术主要有HashMap,Guava Cache,Caffeine和Encahche。远端缓存将在后面的博文中进行深入探讨,此处挖个坑,因此本篇博文仅覆盖了本地缓存,且突出探讨高性能的本地缓存。
本篇博文将首先介绍常见的本地缓存技术,对本地缓存有个大概的了解;其次介绍本地缓存中号称性能最好的Cache,可以探讨看看到底有多好?怎么做到这么好?最后通过几个实战样例,在日常工作中应用高性能的本地缓存。
一、 Java本地缓存技术介绍
1.1 HashMap
通过Map的底层方式,直接将需要缓存的对象放在内存中。
优点:简单粗暴,不需要引入第三方包,比较适合一些比较简单的场景。
缺点:没有缓存淘汰策略,定制化开发成本高。
public class LRUCache extends LinkedHashMap
/**
* 可重入读写锁,保证并发读写安全性
*/
private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private Lock readLock = readWriteLock.readLock();
private Lock writeLock = readWriteLock.writeLock();
/**
* 缓存大小限制
*/
private int maxSize;
public LRUCache(int maxSize)
super(maxSize + 1, 1.0f, true);
this.maxSize = maxSize;
@Override
public Object get(Object key)
readLock.lock();
try
return super.get(key);
finally
readLock.unlock();
@Override
public Object put(Object key, Object value)
writeLock.lock();
try
return super.put(key, value);
finally
writeLock.unlock();
@Override
protected boolean removeEldestEntry(Map.Entry eldest)
return this.size() > maxSize;
1.2 Guava Cache
Guava Cache是由Google开源的基于LRU替换算法的缓存技术。但Guava Cache由于被下面即将介绍的Caffeine全面超越而被取代,因此不特意编写示例代码了,有兴趣的读者可以访问Guava Cache主页。
优点:支持最大容量限制,两种过期删除策略(插入时间和访问时间),支持简单的统计功能。
缺点:springboot2和spring5都放弃了对Guava Cache的支持。
1.3 Caffeine
Caffeine采用了W-TinyLFU(LUR和LFU的优点结合)开源的缓存技术。缓存性能接近理论最优,属于是Guava Cache的增强版。
public class CaffeineCacheTest
public static void main(String[] args) throws Exception
//创建guava cache
Cache<String, String> loadingCache = Caffeine.newBuilder()
//cache的初始容量
.initialCapacity(5)
//cache最大缓存数
.maximumSize(10)
//设置写缓存后n秒钟过期
.expireAfterWrite(17, TimeUnit.SECONDS)
//设置读写缓存后n秒钟过期,实际很少用到,类似于expireAfterWrite
//.expireAfterAccess(17, TimeUnit.SECONDS)
.build();
String key = "key";
// 往缓存写数据
loadingCache.put(key, "v");
// 获取value的值,如果key不存在,获取value后再返回
String value = loadingCache.get(key, CaffeineCacheTest::getValueFromDB);
// 删除key
loadingCache.invalidate(key);
private static String getValueFromDB(String key)
return "v";
1.4 Encache
Ehcache是一个纯java的进程内缓存框架,具有快速、精干的特点。是hibernate默认的cacheprovider。
优点:支持多种缓存淘汰算法,包括LFU,LRU和FIFO;缓存支持堆内缓存,堆外缓存和磁盘缓存;支持多种集群方案,解决数据共享问题。
缺点:性能比Caffeine差
public class EncacheTest
public static void main(String[] args) throws Exception
// 声明一个cacheBuilder
CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withCache("encacheInstance", CacheConfigurationBuilder
//声明一个容量为20的堆内缓存
.newCacheConfigurationBuilder(String.class,String.class, ResourcePoolsBuilder.heap(20)))
.build(true);
// 获取Cache实例
Cache<String,String> myCache = cacheManager.getCache("encacheInstance", String.class, String.class);
// 写缓存
myCache.put("key","v");
// 读缓存
String value = myCache.get("key");
// 移除换粗
cacheManager.removeCache("myCache");
cacheManager.close();
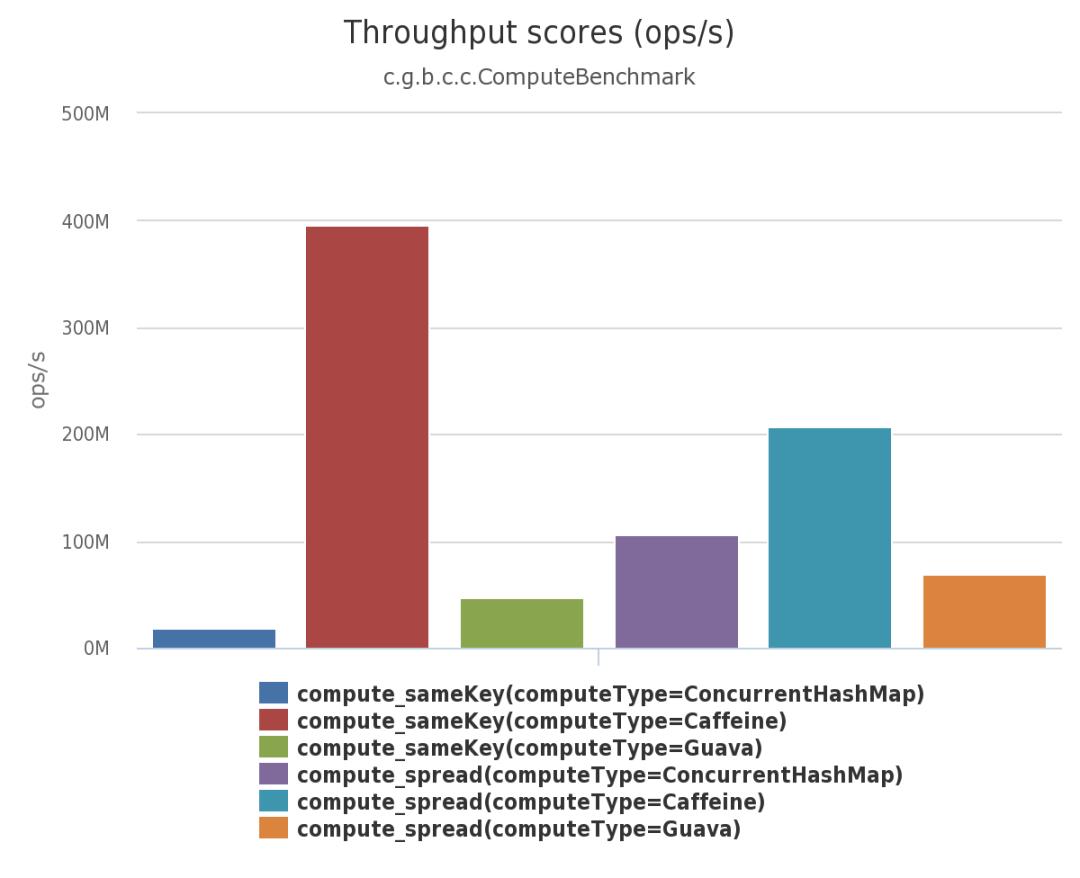
在Caffeine的官网介绍中,Caffeine在性能和功能上都与其他几种方案相比具有优势,因此接下来主要探讨Caffeine的性能和实现原理。
二、高性能缓存Caffeine
2.1 缓存类型
2.1.1 Cache
Cache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
// 查找一个缓存元素, 没有查找到的时候返回null
Graph graph = cache.getIfPresent(key);
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回null
graph = cache.get(key, k -> createExpensiveGraph(key));
// 添加或者更新一个缓存元素
cache.put(key, graph);
// 移除一个缓存元素
cache.invalidate(key);Cache 接口提供了显式搜索查找、更新和移除缓存元素的能力。当缓存的元素无法生成或者在生成的过程中抛出异常而导致生成元素失败,cache.get 也许会返回 null 。
2.1.2 Loading Cache
LoadingCache<Key, Graph> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> createExpensiveGraph(key));
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回null
Graph graph = cache.get(key);
// 批量查找缓存,如果缓存不存在则生成缓存元素
Map<Key, Graph> graphs = cache.getAll(keys);一个LoadingCache是一个Cache 附加上 CacheLoader能力之后的缓存实现。
如果缓存不错在,则会通过CacheLoader.load来生成对应的缓存元素。
2.1.3 Async Cache
AsyncCache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.buildAsync();
// 查找一个缓存元素, 没有查找到的时候返回null
CompletableFuture<Graph> graph = cache.getIfPresent(key);
// 查找缓存元素,如果不存在,则异步生成
graph = cache.get(key, k -> createExpensiveGraph(key));
// 添加或者更新一个缓存元素
cache.put(key, graph);
// 移除一个缓存元素
cache.synchronous().invalidate(key);AsyncCache就是Cache的异步形式,提供了Executor生成缓存元素并返回CompletableFuture的能力。默认的线程池实现是 ForkJoinPool.commonPool() ,当然你也可以通过覆盖并实现 Caffeine.executor(Executor)方法来自定义你的线程池选择。
2.1.4 Async Loading Cache
AsyncLoadingCache<Key, Graph> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
// 你可以选择: 去异步的封装一段同步操作来生成缓存元素
.buildAsync(key -> createExpensiveGraph(key));
// 你也可以选择: 构建一个异步缓存元素操作并返回一个future
.buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
// 查找缓存元素,如果其不存在,将会异步进行生成
CompletableFuture<Graph> graph = cache.get(key);
// 批量查找缓存元素,如果其不存在,将会异步进行生成
CompletableFuture<Map<Key, Graph>> graphs = cache.getAll(keys);AsyncLoadingCache就是LoadingCache的异步形式,提供了异步load生成缓存元素的功能。
2.2 驱逐策略
基于容量
// 基于缓存内的元素个数进行驱逐
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.maximumSize(10_000)
.build(key -> createExpensiveGraph(key));
// 基于缓存内元素权重进行驱逐
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.maximumWeight(10_000)
.weigher((Key key, Graph graph) -> graph.vertices().size())
.build(key -> createExpensiveGraph(key));基于时间
// 基于固定的过期时间驱逐策略
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(key -> createExpensiveGraph(key));
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> createExpensiveGraph(key));
// 基于不同的过期驱逐策略
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.expireAfter(new Expiry<Key, Graph>()
public long expireAfterCreate(Key key, Graph graph, long currentTime)
// Use wall clock time, rather than nanotime, if from an external resource
long seconds = graph.creationDate().plusHours(5)
.minus(System.currentTimeMillis(), MILLIS)
.toEpochSecond();
return TimeUnit.SECONDS.toNanos(seconds);
public long expireAfterUpdate(Key key, Graph graph,
long currentTime, long currentDuration)
return currentDuration;
public long expireAfterRead(Key key, Graph graph,
long currentTime, long currentDuration)
return currentDuration;
)
.build(key -> createExpensiveGraph(key));基于引用
// 当key和缓存元素都不再存在其他强引用的时候驱逐
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> createExpensiveGraph(key));
// 当进行GC的时候进行驱逐
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.softValues()
.build(key -> createExpensiveGraph(key));2.3 刷新机制
LoadingCache<Key, Graph> graphs = Caffeine.newBuilder()
.maximumSize(10_000)
.refreshAfterWrite(1, TimeUnit.MINUTES)
.build(key -> createExpensiveGraph(key));只有在LoadingCache中可以使用刷新策略,与驱逐不同的是,在刷新的时候如果查询缓存元素,其旧值将仍被返回,直到该元素的刷新完毕后结束后才会返回刷新后的新值。
2.4 统计
Cache<Key, Graph> graphs = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();通过使用Caffeine.recordStats()方法可以打开数据收集功能。Cache.stats()方法将会返回一个CacheStats对象,其将会含有一些统计指标,比如:
hitRate(): 查询缓存的命中率
evictionCount(): 被驱逐的缓存数量
averageLoadPenalty(): 新值被载入的平均耗时
配合SpringBoot提供的RESTful Controller,能很方便的查询Cache的使用情况。
三、Caffeine在SpringBoot的实战
按照Caffeine Github官网文档的描述,Caffeine是基于Java8的高性能缓存库。并且在Spring5(SpringBoot2.x)官方放弃了Guava,而使用了性能更优秀的Caffeine作为默认的缓存方案。
SpringBoot使用Caffeine有两种方式:
方式一:直接引入Caffeine依赖,然后使用Caffeine的函数实现缓存
方式二:引入Caffeine和Spring Cache依赖,使用SpringCache注解方法实现缓存
下面分别介绍两种使用方式。
方式一:使用Caffeine依赖
首先引入maven相关依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>其次,设置缓存的配置选项
@Configuration
public class CacheConfig
@Bean
public Cache<String, Object> caffeineCache()
return Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterWrite(60, TimeUnit.SECONDS)
// 初始的缓存空间大小
.initialCapacity(100)
// 缓存的最大条数
.maximumSize(1000)
.build();
最后给服务添加缓存功能@Slf4j
@Service
public class UserInfoServiceImpl
/**
* 模拟数据库存储数据
*/
private HashMap<Integer, UserInfo> userInfoMap = new HashMap<>();
@Autowired
Cache<String, Object> caffeineCache;
public void addUserInfo(UserInfo userInfo)
userInfoMap.put(userInfo.getId(), userInfo);
// 加入缓存
caffeineCache.put(String.valueOf(userInfo.getId()),userInfo);
public UserInfo getByName(Integer id)
// 先从缓存读取
caffeineCache.getIfPresent(id);
UserInfo userInfo = (UserInfo) caffeineCache.asMap().get(String.valueOf(id));
if (userInfo != null)
return userInfo;
// 如果缓存中不存在,则从库中查找
userInfo = userInfoMap.get(id);
// 如果用户信息不为空,则加入缓存
if (userInfo != null)
caffeineCache.put(String.valueOf(userInfo.getId()),userInfo);
return userInfo;
public UserInfo updateUserInfo(UserInfo userInfo)
if (!userInfoMap.containsKey(userInfo.getId()))
return null;
// 取旧的值
UserInfo oldUserInfo = userInfoMap.get(userInfo.getId());
// 替换内容
if (!StringUtils.isEmpty(oldUserInfo.getAge()))
oldUserInfo.setAge(userInfo.getAge());
if (!StringUtils.isEmpty(oldUserInfo.getName()))
oldUserInfo.setName(userInfo.getName());
if (!StringUtils.isEmpty(oldUserInfo.getSex()))
oldUserInfo.setSex(userInfo.getSex());
// 将新的对象存储,更新旧对象信息
userInfoMap.put(oldUserInfo.getId(), oldUserInfo);
// 替换缓存中的值
caffeineCache.put(String.valueOf(oldUserInfo.getId()),oldUserInfo);
return oldUserInfo;
@Override
public void deleteById(Integer id)
userInfoMap.remove(id);
// 从缓存中删除
caffeineCache.asMap().remove(String.valueOf(id));
方式二:使用Spring Cache注解
首先引入maven相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>其次,配置缓存管理类
@Configuration
public class CacheConfig
/**
* 配置缓存管理器
*
* @return 缓存管理器
*/
@Bean("caffeineCacheManager")
public CacheManager cacheManager()
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterAccess(60, TimeUnit.SECONDS)
// 初始的缓存空间大小
.initialCapacity(100)
// 缓存的最大条数
.maximumSize(1000));
return cacheManager;
最后给服务添加缓存功能
@Slf4j
@Service
@CacheConfig(cacheNames = "caffeineCacheManager")
public class UserInfoServiceImpl
/**
* 模拟数据库存储数据
*/
private HashMap<Integer, UserInfo> userInfoMap = new HashMap<>();
@CachePut(key = "#userInfo.id")
public void addUserInfo(UserInfo userInfo)
userInfoMap.put(userInfo.getId(), userInfo);
@Cacheable(key = "#id")
public UserInfo getByName(Integer id)
return userInfoMap.get(id);
@CachePut(key = "#userInfo.id")
public UserInfo updateUserInfo(UserInfo userInfo)
if (!userInfoMap.containsKey(userInfo.getId()))
return null;
// 取旧的值
UserInfo oldUserInfo = userInfoMap.get(userInfo.getId());
// 替换内容
if (!StringUtils.isEmpty(oldUserInfo.getAge()))
oldUserInfo.setAge(userInfo.getAge());
if (!StringUtils.isEmpty(oldUserInfo.getName()))
oldUserInfo.setName(userInfo.getName());
if (!StringUtils.isEmpty(oldUserInfo.getSex()))
oldUserInfo.setSex(userInfo.getSex());
// 将新的对象存储,更新旧对象信息
userInfoMap.put(oldUserInfo.getId(), oldUserInfo);
// 返回新对象信息
return oldUserInfo;
@CacheEvict(key = "#id")
public void deleteById(Integer id)
userInfoMap.remove(id);
四、Caffeine在Reactor的实战
Caffeine和Reactor的结合是通过CacheMono和CacheFlux来使用的,Caffine会存储一个Flux或Mono作为缓存的结果。
首先定义Caffeine的缓存:
final Cache<String, String> caffeineCache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(30))
.recordStats()
.build();CacheMono
final Mono<String> cachedMonoCaffeine = CacheMono
.lookup(
k -> Mono.justOrEmpty(caffeineCache.getIfPresent(k)).map(Signal::next),
key
)
.onCacheMissResume(this.handleCacheMiss(key))
.andWriteWith((k, sig) -> Mono.fromRunnable(() ->
caffeineCache.put(k, Objects.requireNonNull(sig.get()))
));lookup方法查询cache中是否已存在,如果不存在,则通过onCacheMissResume重新生成一个Mono,并通过andWriteWith方法将结果存入缓存中。
CacheFlux
final Flux<Integer> cachedFluxCaffeine = CacheFlux
.lookup(
k ->
final List<Integer> cached = caffeineCache.getIfPresent(k);
if (cached == null)
return Mono.empty();
return Mono.just(cached)
.flatMapMany(Flux::fromIterable)
.map(Signal::next)
.collectList();
,
key
)
.onCacheMissResume(this.handleCacheMiss(key))
.andWriteWith((k, sig) -> Mono.fromRunnable(() ->
caffeineCache.put(
k,
sig.stream()
.filter(signal -> signal.getType() == SignalType.ON_NEXT)
.map(Signal::get)
.collect(Collectors.toList())
)
));同理CacheFlux的用法也类似。
参考:
https://www.javadevjournal.com/spring-boot/spring-boot-with-caffeine-cache/
https://sunitc.dev/2020/08/27/springboot-implement-caffeine-cache/
https://github.com/ben-manes/caffeine/wiki/Population-zh-CN
Guava Cache主页:https://github.com/google/guava/wiki/CachesExplained
Caffeine的官网:https://github.com/ben-manes/caffeine/wiki/Benchmarks
以上是关于什么叫缓存?的主要内容,如果未能解决你的问题,请参考以下文章