Instruction-Level Pipelining
Posted 菜菜粥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Instruction-Level Pipelining相关的知识,希望对你有一定的参考价值。
The speed of execution programs is influenced by many factors
- One way to improve performance is to use faster circuit technology to build the processor and the main memory.
通过用效率更高的电路技术来构建处理器和内存,提高性能, - Another way is that more than one operation can be performed at the same time.
在相同的时间内,让更多的操作,被执行
程序执行(有很多的fetch-excete指令组成)

指令
clock 1 2 3 4
Fetch1 Exec1
Fetch2 Exec2
Fetch3 Exec3
分析:
- 没有用 pipelining,执行这段程序需要6个时钟单位
- 使用后,执行这段程序,只要4个时钟单位
- 这是因为后一条指令可以和前一条指令同时进行(当然 each separate hardware unit has
individual control logic 如果指令之间相互影响,那么这里也就不可以同时进行了
还有就是每个微操作的时间要差不多, 否则就会产生等待,同样效果也是不佳的) - 为什么不是起头并进,因为bus总线,每次只能一条指令使用的,这是cpu和计算机的结构限制,如果你用多总线,那么成本,复杂性,都会增加好多
要求
- The pipeline consists several sequential stages.(因为跳转执行的情况,效果不是很好,这也是为什么c语言要尽量小用goto语句,因为你要重复重新的构建流水线,这样效率就低了)
- Each stage is implemented by special hardware unit.
- The required time of implement the operation of each stage is same.
指令流水线的时空图 x轴表示时间 y轴表示 m条指令,每条指令n个微操作
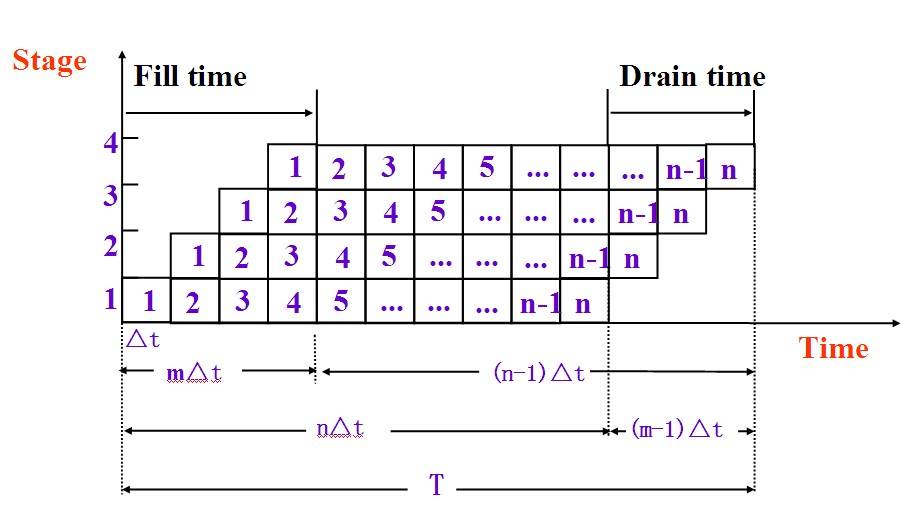
- Fill time:从开始执行第一条指令,到最后一条指令的执行执行,为什么,是这样,因为你只有判断到后面没有指令了,才能确定是不是full time(构建时间),所以区间是这样子,和Drain time 不对称
- Drain time:从 第一条指令的末尾,到程序的结束的这段时间是,排空时间
- Total time: 这个当然就是程序执行所有的时间
- Throughput rate:每一个时钟周期,执行的指令的条数 (吞吐率)
- Speedup ratio: 没用了pipeinling的程序执行时间/用pipeinling的程序执行时间(加速率)
- Efficiency: 没用pipeinling的总时间/ 总区域的时间(相当于用长方形包住区域 每条指令加上等待时间).
Suppose we have a m-stage pipeline, the clock cycle time is ∆t, that is, it takes ∆t time per stage. Assume also we have n instruction to process.
- Fill time: m ∆t
- Drain time: (m-1) ∆t
- Total time: T= (n+m-1) ∆t
- Throughput rate: n / 【(n+m-1) ∆t】
- Speedup ratio: n*m*∆t/【(n+m-1) ∆t】 显然>=1
- Efficiency:E = n*m*∆t/(m*T) 即 Throughput rate 乘上一个 ∆t
以上是关于Instruction-Level Pipelining的主要内容,如果未能解决你的问题,请参考以下文章