JavaScript数据结构和算法
Posted 求知如渴、虚心若愚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript数据结构和算法相关的知识,希望对你有一定的参考价值。
前言
在过去的几年中,得益于Node.js的兴起,javascript越来越广泛地用于服务器端编程。鉴于JavaScript语言已经走出了浏览器,程序员发现他们需要更多传统语言(比如C++和Java)提供的工具。这些工具包括传统的数据结构(如链表,栈,队列,图等),也包括传统的排序和查找算法。本文主要是总结什么情况下使用何种数据结构较好,并没有细讲里面的原理和实现方式,仅仅提供给阅读过《数据结构和算法》的同学作为总结和参考笔记,如果未细究过数据结构和算法的同学,本文也可以作为一个方向,希望能引导你去深究数据结构和算法。
为什么要学习数据结构和算法
数据结构和算法对于很多前端工程师来说,一直觉得是可有可无的,但其实不然,个人觉得,前端工程师其实是最需要重视数据结构和算法的人,因为前端所做的东西是用户访问网站第一眼看到的东西,特别在移动浪潮到来之后,对用户体验越来越高,对前端提出了更高的要求,面对越来越复杂的产品,需要坚实的数据结构和算法基础才能驾驭。
如果没有学习过计算机科学的程序员,当我们在处理一些问题时,比较熟悉的数据结构就是数组,数组无疑是一个很好的选择。但很多时候,对于很多复杂的问题,数组就显得太过简陋了,当学习了数据结构和算法之后,对于很多编程问题,当想到一个合适的数据结构后,设计和实现解决这些问题的算法就手到擒来。
相关知识点——数据结构、排序算法和查找算法
相关讲解细分:
数据结构:列表、栈、队列、链表、字典、散列、图和二叉查找树
排序算法:冒牌排序、选择排序、插入排序、希尔排序、归并排序和快速排序
查找算法:顺序查找和二分查找
列表
在日常生活中,人们经常使用列表:待办事项列表、购物清单、最佳十名榜单等等。而计算机程序也在使用列表,在下面的条件下,选择列表作为数据结构就显得尤为有用:
- 数据结构较为简单
- 不需要在一个长序列中查找元素,或者对其进行排序
反之,如果数据结构非常复杂,列表的作用就没有那么大了。
栈
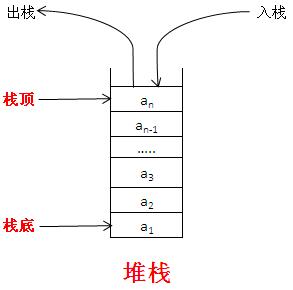
栈是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端称为栈顶。想象一下,我们平常在饭馆见到的一摞盘子就是现实世界常见的栈的例子,只能从最上面取盘子,盘子洗干净后,也只能放在最上面。栈被称为一种后入先出的数据结构。是一种高效的数据结构,因为数据只能在栈顶添加或删除,所以这样的操作很快。
使用条件:
- 只要数据的保存满足
后入先出或先进后出的原理,都优先考虑使用栈
队列
队列也是一种列表,不同的是队列只能在队尾插入元素,在队首删除元素。想象一下,我们在银行排队,排在最前面的人第一个办理业务,而后面来的人只能排在队伍的后面,直到轮到他们为止。
使用条件:
- 只要数据的保存满足
先进先出、后入后出的原理,都优先考虑使用队列
常见应用场景:
- 队列主要用在和时间有关的地方,特别是操作系统中,队列是实现多任务的重要机制
- 消息机制可以通过队列来实现,进程调度也是使用队列来实现

链表
链表也是一种列表,为什么需要出现链表,JavaScript中数组的主要问题时,它们被实现成了对象,与其他语言(比如C++和Java)的数组相对,效率很低。如果你发现数组在实际使用时很慢,就可以考虑使用链表来代替它。
使用条件:
- 链表几乎可以用在任何可以使用
一维数组的情况中。如果需要随机访问,数组仍然是更好的选择。

字典
字典是一种以键-值对行驶存储数据的数据结构,JavaScript中的Object类就是以字典的形式设计的。JavaScript可以通过实现字典类,让这种字典类型的对象使用起来更加简单,字典可以实现对象拥有的常见功能,并相应拓展自己想要的功能,而对象在JavaScript编写中随处可见,所以字典的作用也异常明显了。
散列
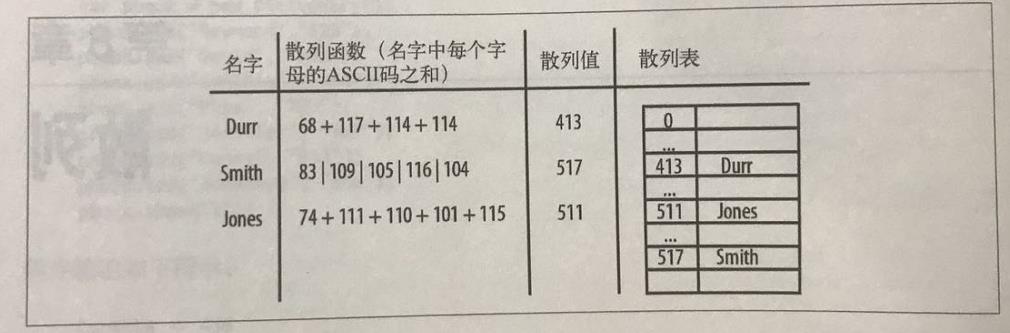
散列(也称为哈希表)是一种的常用的数组存储技术,散列后的数组可以快速地插入或取用。散列使用的数据结构叫做散列表。在散列表上插入、删除和取用数据都非常快,但对于查找操作来说却效率低下,比如查找一组数组中的最大值和最小值。这些操作需要求助于其他数据结构,比如下面介绍的二叉查找树。
散列表在JavaScript中可以基础数组去进行设计。数组的长度是预先设定的,所有元素根据和该元素对应的键,保存在数组的特定位置,这里的键和对象的键是类型的概念。使用散列表存储数组时,通过一个散列函数将键映射为一个数字,这个数字的范围是0到散列表的长度。
即使使用一个高效的散列函数,依然存在将两个键映射为同一个值得可能,这种现象叫做碰撞。常见碰撞的处理方法有:开链法和线性探测法(具体概念有兴趣的可以网上自信了解)
使用条件:
- 可以用于数据的插入、删除和取用,不适用于查找数据
图
图由边的集合及顶点的集合组成。地图是我们身边很常见的现实场景,比如每两个城镇都由某种道路相连。上面的每个城镇可以看作一个顶点,连接城镇的道路便是边。边由顶点对(v1, v2)定义,v1和v2分别是图中的两个顶点。顶点也有权重,也成为成本。如果一个图的顶点对是有序的,则称之为有向图(例如常见的流程图),反之,称之为无序图。
使用场景(用图对现实中的系统建模):
- 交通系统,可以用顶点表示街道的十字路口,边可以表示街道。加权的边可以表示限速或者车道的数量。可以用该系统判断最佳路线及最有可能堵车的街道。
- 任何运输系统都可以用图来建模。比如,航空公司可以用图来为其飞行系统建模。将每个机场看成顶点,将经过两个顶点的每条航线看作一条边。加权的边可以表示从一个机场到另一个机场的航班成本,或两个机场间的距离,这取决于建模的对象是什么。
搜索图的算法主要有两种: 深度优先搜索和广度优先搜索。
二叉树和二叉查找树
树是计算机科学中经常用到的一种数据结构。树是一种非线性的数据结构,以分层的方式存储数据。
二叉树每个节点的子节点不允许超过两个。一个父节点的两个子节点分别称为左节点和右节点,通过将子节点的个数限定为2,可以写出高效的程序在树中插入、查找和删除数据。
二叉查找树(BST)是一种特殊的二叉树,相对较小的值保存在左节点中,较大的值保存在右节点中。这一特性使得查找的效率很高,对于数值型和非数值型的数据,比如单词和字符串,都是如此。
二叉查找树实现方法
function Node(data, left, right) { // 创建节点
this.data = data;
this.left = left;
this.right = right;
this.show = show
}
function show () { // 显示树的数据
return this.data
}
function BST () { // 二叉查找树类
this.root = null;
this.insert = insert;
this.inOrder = inOrder; // inOrder是遍历BST的方式
}
function insert (data) { // 向树中插入数据
var n = new Node(data, null, null)
if (this.root == null) {
this.root = n;
} else {
var current = this.root;
var parent;
while (true) {
parent = current
if (data < current.data) {
current = current.left;
if (current == null) {
parent.left = n;
break;
}
} else {
current = current.right;
if (current == null) {
parent.right = n;
break;
}
}
}
}
}
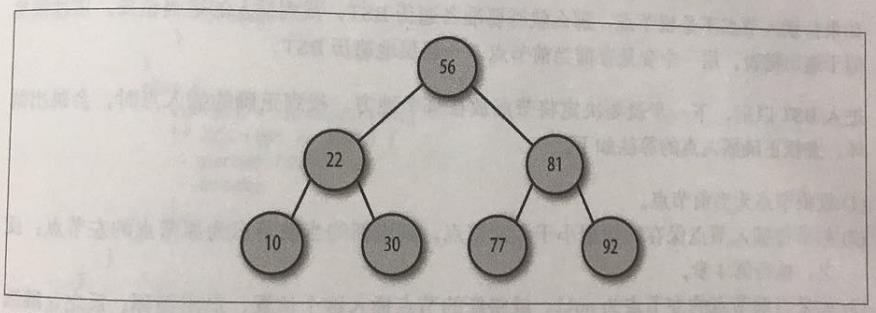
遍历BST的方式有三种:中序遍历(以升序访问树中所有节点,先访问左节点,再访问根节点,最后访问右节点)、先序遍历(先访问根节点,再以同样的方式访问左节点和右节点)、后序遍历(先访问叶子节点,从左子树到右子树,再到根节点)
排序算法
基本排序算法
基本排序算法,其核心思想是指对一组数组按照一定的顺序重新排列。重新排列时用到的技术是一组嵌套的for循环。其中外循环会遍历数组的每一项,内循环则用于比较元素。
冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
function bubbleSort (arr) {
var i = arr.length;
while (i > 0) {
var pos = 0
for (var j = 0; j < i; j++) {
if (arr[j] > arr[j+1]){
pos = j
var temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
}
}
i = pos
}
return arr
}
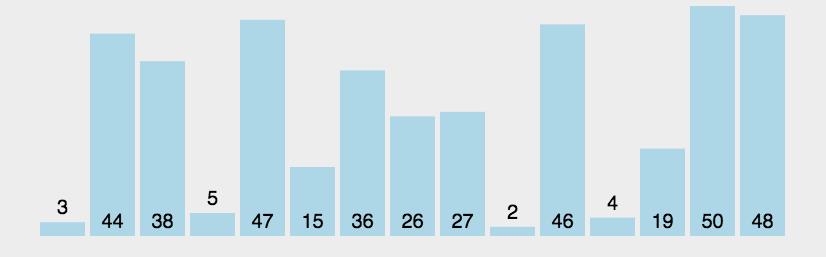
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(bubbleSort(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
function selectionSort (arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len-1; i++) {
minIndex = i;
for (var j = i+1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j
}
}
temp = arr[minIndex]
arr[minIndex] = arr[i]
arr[i] = temp
}
return arr
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(selectionSort(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
function insertSort (arr) {
var len = arr.length
for (i = 1; i < len; i++) {
var key = arr[i]
var j = i - 1
while (j >= 0 && arr[j] > key) {
arr[j+1] = arr[j]
j--;
}
arr[j+1] = key
}
return arr
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(insertSort(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
高级排序算法
高级数据排序算法,通常用于处理大型数据集的最高效排序算法,它们处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个,下面我们将介绍希尔排序、归并排序和快速排序。
希尔排序
1959年Shell发明,第一个突破O(n^2)的排序算法;是简单插入排序的改进版;它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。
function shellSort (arr) {
var len = arr.length;
var temp, gap = 1;
while (gap < len /3 ) {
gap = gap * 3 + 1
}
while (gap >= 1) {
for (var i = gap; i < len; i++) {
temp = arr[i]
for (var j = i - gap; j >= 0 && arr[j] > temp; j-=gap) {
arr[j+gap] = arr[j]
}
arr[j+gap] = temp
}
gap = (gap - 1) / 3
}
return arr
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(shellSort(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]

归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
function mergeSort (arr) {
var len = arr.length
if (len < 2) {
return arr
}
var middle = Math.floor(len / 2)
var left = arr.slice(0, middle)
var right = arr.slice(middle)
return merge (mergeSort(left), mergeSort(right));
}
function merge (left, right) {
var result = []
while (left.length && right.length) {
if (left[0] < right[0]) {
result.push(left.shift())
} else {
result.push(right.shift())
}
}
while (left.length) {
result.push(left.shift())
}
while (right.length) {
result.push(right.shift())
}
return result
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(mergeSort(arr));
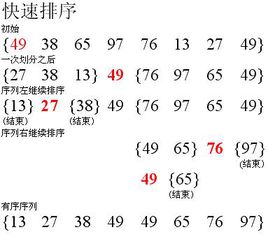
快速排序
快速排序是处理 大数据集最快的排序算法之一。它是一种分而治之的算法,通过递归的方法将数据依次分解为包含较小元素和较大元素的不同子序列。该算法不断重复这个步骤知道所有数据都是有序的。
这个算法首先要在列表中选择一个元素作为基准值。数据排序围绕基准值进行,将列表中小于基准值的元素移到数组的底部,将大于基准值的元素移到数组的顶部。
function qSort (arr) {
if (arr.length == 0) {
return []
}
var left = []
var right = []
var pivot = arr[0]
for (var i = 1; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
return qSort(left).concat(pivot, qSort(right))
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(qSort(arr));
检索算法
在列表中查找数据有两种方式:顺序查找和二分查找。顺序查找适用于元素随机排列的列表;二分查找适用于元素已排序的列表。二分查找效率更高,但是必须在进行查找之前花费额外的时间将列表中的元素排序。
顺序查找
对于查找数据,最简单的方法就是从列表的第一个元素开始对列表元素逐个进行判断,直到找到了想要的结果,或者直到列表结尾也没有找到。这种方法称为顺序查找,有时也被称为线性查找。
function seqSearch (arr, data) {
for (var i = 0; i < arr.length; i++) {
if (arr[i] == data) {
return i;
}
}
return -1;
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(seqSearch(arr, 15))
二分查找
二分法查找,也称折半查找,是一种在有序数组中查找特定元素的搜索算法。查找过程可以分为以下步骤:
- 首先,从有序数组的中间的元素开始搜索,如果该元素正好是目标元素(即要查找的元素),则搜索过程结束,否则进行下一步。
- 如果目标元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半区域查找,然后重复第一步的操作。
- 如果某一步数组为空,则表示找不到目标元素。
function binSearch (arr, data) {
var low = 0;
var high = arr.length - 1
while (low <= high) {
var middle = Math.floor((low + high) / 2)
if (arr[middle] < data) {
low = middle + 1
} else if (arr[middle] > data) {
high = middle - 1
} else {
return middle
}
}
return -1
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(binSearch(arr, 15))
摘自:http://www.cnblogs.com/roam/p/7423805.html
以上是关于JavaScript数据结构和算法的主要内容,如果未能解决你的问题,请参考以下文章