c语言编程替换文件中字符串
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c语言编程替换文件中字符串相关的知识,希望对你有一定的参考价值。
实现记事本替换功能:有一个文件a1.txt里面存有大量的字符,现在需要替换其中的一些字符,用户输入要替换的字符串,和被替换成的字符串,例如输入:
aabac
abc
则如果a1.txt中有字符串aabac就会被替换成abc
谁能写出符合题意的源程序,我给他加50分
方法和详细的操作步骤如下:
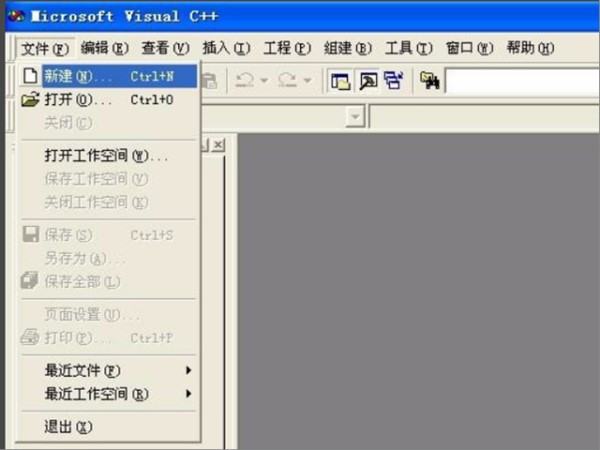
1、第一步,依次单击visual C ++ 6.0的“文件”-->“新建”-->“文件”-->“C++ Source File”选项,见下图,转到下面的步骤。
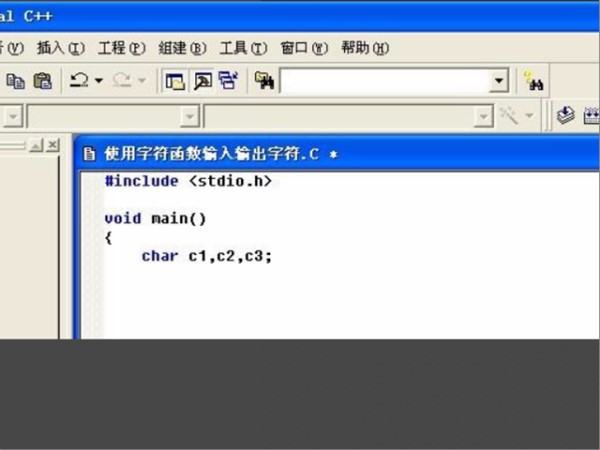
2、第二步,执行完上面的操作之后,定义变量,代码见下图,转到下面的步骤。
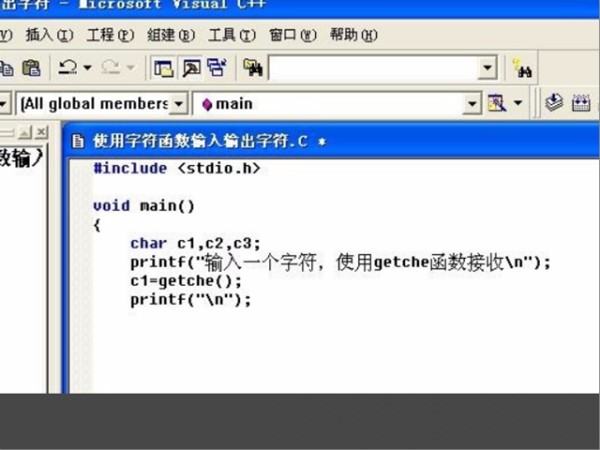
3、第三步,执行完上面的操作之后,输入一个字符,使用getche函数接收,代码见下图,转到下面的步骤。
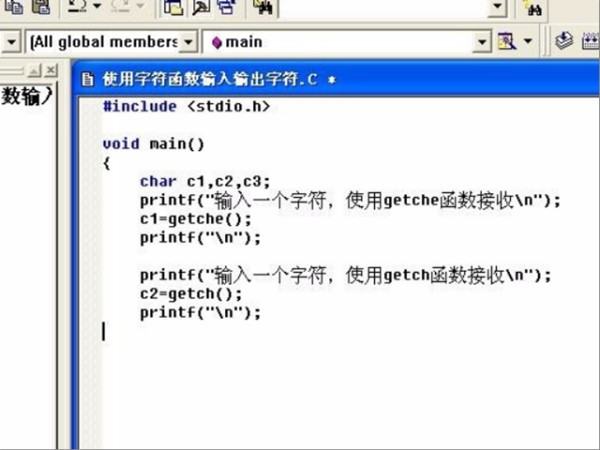
4、第四步,执行完上面的操作之后,输入如下代码,见下图,转到下面的步骤。
5、第五步,执行完上面的操作之后,再输入如下代码,见下图,转到下面的步骤。
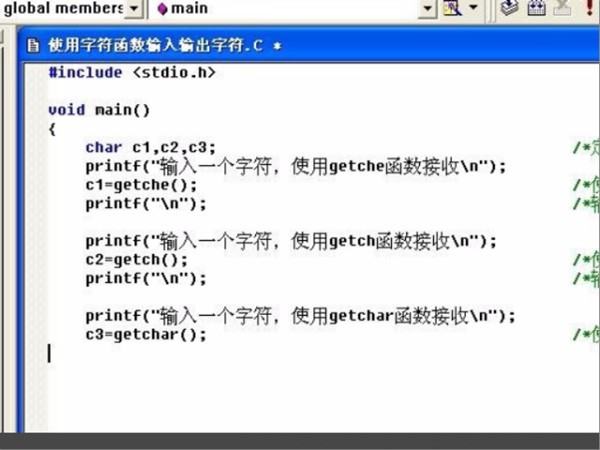
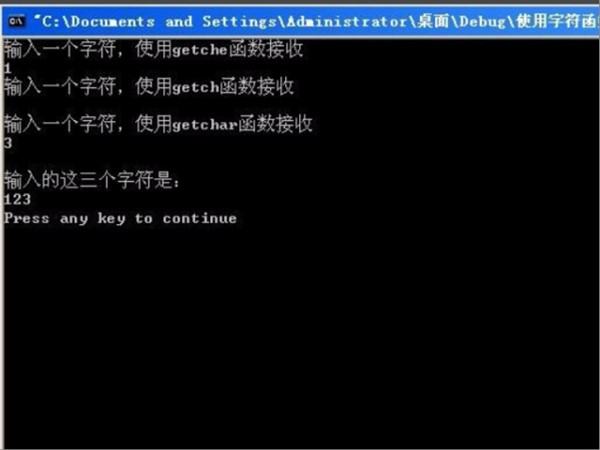
6、第六步,执行完上面的操作之后,输出最终结果,见下图。这样,就解决了这个问题了。
/* Filename: word-replace.c
* Description: 替换文件中指定的单词为其他字符串并输出到指定的文件中
*/
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<ctype.h>
#define MAX_WORDS_LEN 50 // 单词的最大长度限制
typedef enum FALSE = 0, TRUE = 1 BOOL;
struct Word
char str[MAX_WORDS_LEN + 1]; // 存储字符串
BOOL isWord; // 是否为单词
;
typedef struct Node // 使用链表存储解析后的字符串
struct Word word;
struct Node *next;
*List;
enum Option // 单词替换选项
MATCH_WORD_CASE, // 精确匹配单词区分大小写
MATCH_WORD_NOCASE, // 匹配单词但不区分大小写
;
// 函数功能:出错处理方法,打印出错信息并退出程序
void complain(const char *msg)
printf("%s\n", msg);
exit(EXIT_FAILURE);
// 函数功能:将结构体单词 w 插入不带头节点的单向不循环链表 L 的末尾
// 参数L:不带头节点的单向不循环链表的表头指针
// 参数w:指向待插入链表 L 的结构体单词信息的指针
void insert_list(List * L, const struct Word *w)
struct Node *node = (struct Node *)malloc(sizeof(struct Node));
node->word = *w, node->next = NULL;
if (*L != NULL) // 链表非空,则寻找链表的末尾并插入
struct Node *p;
for (p = *L; p->next != NULL; p = p->next) ;
p->next = node;
else // 链表为空,直接插入
*L = node;
// 函数功能:打印不带头节点的单向不循环链表,参数L为该链表的表头指针
void print_list(List L)
for (struct Node * p = L; p; p = p->next)
printf("%s|%d\n", p->word.str, p->word.isWord);
// 函数功能:销毁不带头节点的单向不循环链表,参数L为该链表的表头指针
void dump_list(List L)
for (struct Node * p = L, *n; p; p = n)
n = p->next;
free(p);
// 函数功能:不区分大小写的字符串比较函数,该函数不是标准C语言的库函数
int stricmp(const char *dst, const char *src)
int ch1, ch2;
do
if (((ch1 = (unsigned char)(*(dst++))) >= 'A') && (ch1 <= 'Z'))
ch1 += 0x20;
if (((ch2 = (unsigned char)(*(src++))) >= 'A') && (ch2 <= 'Z'))
ch2 += 0x20;
while (ch1 && (ch1 == ch2));
return (ch1 - ch2);
// 函数功能:解析文件指针fp_ro所指文件中的字符串,将其中的单词和非单词分离
// 出来,并将分离的结果存储到不带头节点的单向不循环链表L中。如果
// 函数成功执行,返回TRUE,否则返回FALSE。
BOOL word_parse(FILE * fp_ro, List * L)
if (fseek(fp_ro, 0L, SEEK_END))
return FALSE;
const long fsize = ftell(fp_ro);
if (fseek(fp_ro, 0L, SEEK_SET))
return FALSE;
char *buf = (char *)malloc(fsize + 1);
if (buf && fread(buf, fsize, 1, fp_ro) != 1 && ferror(fp_ro))
complain("Internal error.");
struct Word w;
char pword[MAX_WORDS_LEN + 1];
for (size_t i = 0, index = 0; i < (size_t) fsize;)
index = 0;
while (!isalpha(buf[i]) && i < (size_t) fsize) // 非字母
pword[index++] = buf[i++];
if (index == MAX_WORDS_LEN) // 缓冲区溢出情况的处理
pword[index] = '\0'; // strncpy不自动添加'\0'
strncpy(w.str, pword, index + 1);
w.isWord = FALSE;
insert_list(L, &w);
index = 0;
if (index != 0)
pword[index] = '\0'; // strncpy不自动添加'\0'
strncpy(w.str, pword, index + 1);
w.isWord = FALSE;
insert_list(L, &w);
index = 0;
while (isalpha(buf[i]) && i < (size_t) fsize) // 单词
pword[index++] = buf[i++];
if (index == MAX_WORDS_LEN) // 缓冲区溢出情况的处理
complain("Too long word in source file.");
if (index != 0)
pword[index] = '\0'; // strncpy不自动添加'\0'
strncpy(w.str, pword, index + 1);
w.isWord = TRUE;
insert_list(L, &w);
free(buf);
return TRUE;
// 函数功能:根据替换选项opt,替换在不带头节点的单向不循环链表L中的
// 单词fnd为新的字符串rep,并返回替换的次数。
int word_replace(List L, enum Option opt, const char *fnd, const char *rep)
int rep_cnt = 0; // 替换发生的次数
switch (opt)
case MATCH_WORD_CASE:
for (struct Node * p = L; p; p = p->next)
if (p->word.isWord == TRUE && strcmp(p->word.str, fnd) == 0)
strcpy(p->word.str, rep), rep_cnt++;
break;
case MATCH_WORD_NOCASE:
for (struct Node * p = L; p; p = p->next)
if (p->word.isWord == TRUE && stricmp(p->word.str, fnd) == 0)
strcpy(p->word.str, rep), rep_cnt++;
break;
default:
fprintf(stderr, "Invalid option for function %s.", __func__);
return rep_cnt;
// 函数功能:将不带头节点的单向不循环链表 L 中的单词(字符串)按顺序存入由
// fp_wr所指的文件中。如果函数成功执行,返回TRUE,否则返回FALSE。
BOOL word_save(FILE * fp_wr, List L)
if (fseek(fp_wr, 0L, SEEK_SET))
return FALSE;
for (struct Node * p = L; p; p = p->next)
fprintf(fp_wr, "%s", p->word.str);
return TRUE;
// 程序功能:以文件为单位,执行单词替换
// 参数格式:命令 源文件 目标文件 查找的单词 替换的单词
int main(int argc, const char *argv[])
// 参数合法性检查
if (argc != 5 || strcmp(argv[1], argv[2]) == 0 ||
strlen(argv[3]) > MAX_WORDS_LEN || strlen(argv[4]) > MAX_WORDS_LEN)
complain("参数错误!\n"
"参数格式:命令 源文件 目标文件 查找的单词 替换的单词");
FILE *fin = fopen(argv[1], "rt");
FILE *fout = fopen(argv[2], "wt");
const char *const fnd = argv[3];
const char *const rep = argv[4];
if (fin == NULL || fout == NULL)
complain("文件输入输出错误!\n");
List L = NULL; // 不带头结点的单向链表的表头指针
if (word_parse(fin, &L) == FALSE)
complain("Parse error.");
print_list(L);
int rep_cnt = word_replace(L, MATCH_WORD_CASE, fnd, rep);
printf("共发生替换 %d 次。\n", rep_cnt);
word_save(fout, L);
dump_list(L);
fclose(fin);
fclose(fout);
return 0;
参考技术B /*文件字符串替换实用程序,算法简练有效*/
编译环境vc2005/dev-c++
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define N 10000 /* 设定文件最大字符个数不超过10000,可更改 */
int main()
int i=0,j,k=0,m=0,pos=0,max,len1,len2;
char s[N],t[N],a[200],s1[200],s2[200];
FILE *fp;
printf("Please input file name:\n");/*输入文件名*/
gets(a);
printf("Please input original string:\n");/*输入要替换的字符串*/
gets(s1);
printf("Please input new string:\n");/*输入被替换成的字符串*/
gets(s2);
len1=strlen(s1);
len2=strlen(s2);
if ((fp=fopen(a,"r"))==NULL)/*设定文件位于当前目录下,可更改为绝对路径*/
printf("Open file %s error! Strike any key to exit!",a);
system("pause");
exit(1);
s[i++]=fgetc(fp);
while(!feof(fp))
s[i++]=fgetc(fp);
fclose(fp);
max=i-1;/* 函数feof()最后会读两次,所以必须减1 */
for(i=0;i<max-len1;i++)
for(j=0;j<len1&&(s[i+j]==s1[j]);j++);
if(j!=len1)
continue;/* 不相等则i加1进行下一次外循环 */
else
for(k=0;k<i-pos;k++)/* pos记录开始复制的位置 */
t[m++]=s[pos+k];
pos=i+len1;
for(k=0;k<len2;k++)/* 字符串替换 */
t[m++]=s2[k];
for(k=pos;k<max;k++)/* 复制剩余字符 */
t[m++]=s[k];
max=m;/* max是替换后文件的字符总数 */
fp=fopen(a,"w");
printf("\n\nThe results are:\n\n");
for(j=0;j<max;j++)
putchar(t[j]); /* 结果显示到屏幕 */
fputc(t[j],fp); /* 同时结果写入到当前目录下的新文件001.txt中 */
printf("\n\n");
fclose(fp);
system("pause");
return 0;
本回答被提问者采纳
《C程序设计语言》笔记 (十四) 参考手册6
预处理
预处理器执行宏替换 条件编译以及包含指定的文件 以#开头的命令行(#前可以有空格)就是预处理器处理的对象 预处理过程可以划分为几个连续的阶段 1.将三字符序列转换为等价字符。如果操作系统需要,还要在源文件的各行之间插入换行符 2.将指令行中位于换行符前的反斜杠\删除,以把各指令行连接起来 3.将程序分成用空白符分隔的记号,注释将被替换为一个空白符。 接着执行预处理指令,并进行宏替换 4.将字符串常量和字符串字面量中的转义字符序列替换为等价字符,然后把相邻的字符串字面值连接起来 5.收集必要的程序和数据,并将外部函数和对象的引用与其定义相连接,翻译经过以上处理得到的结果,然后与其他程序和库连接起来
12.1 三字符序列
C语言源程序的字符集是7位ASCII码的子集,但它是ISO 646-1983不变代码集的超集 为了将程序通过这种缩减的字符集表示出来,下列所示的所有三字符序列都要用相应的单个字符替换 这种替换在进行所有其他处理之前进行 ??=
12.2行连接
通过将以反斜杠\结束的指令行末尾的反斜杠和其后的换行符删除掉,可以将若干指令行合并成一行 这种处理要在分隔记号之前进行
12.3宏定义和扩展
类似于下列形式的控制指令 #define 标识符 记号序列 将使得预处理器把该标识符后续出现的各个实例用给定的记号序列替换 记号序列前后的空白符都将被丢弃掉 第二次用#define指令定义同一标识符是错误的 类似于下列形式的标识符 #define 标识符(标识符表) 记号标记 是一个带有参数的宏定义,其中第一个标识符与圆括号(之间没有空格) 同第一种形式一样,记号序列前后的空白符都将被丢弃。 如果要对宏进行重定义,则必须保证其参数个数 拼写及记号序列都与前面的定义相同 #undef 用于取消标识符的预处理器定义 将#undef应用于未知标识符并不会导致错误 按照第二种形式定义宏时,标识符及其后用一对圆括号括起来,由逗号分隔的记号序列就构成了一个宏调用 宏调用的实际参数是用逗号分隔的记号序列 用引号或嵌套的括号括起来的逗号不能用于实际参数 在处理的过程中,实际参数不进行宏扩展 宏调用时,实际参数的数目必须与定义中形式参数的数目匹配
12.4文件包含
#include <文件名> 把该行替换为文件名指定的文件的内容 #include "文件名" 从源文件的位置开始搜索指定文件,如果没有找到指定的文件,则按照第一种方式处理 #include 记号序列 #include 文件可以嵌套
12.5条件编译
if行: #if 常量表达式 #ifdef 标识符 #ifndef 标识符 elif部分: elif行 文本 elif部分 elif行 #elif 常量表达式 else 部分 else 行 文本 else 行 # else
12.6行控制
为了便于其他预处理器生成C语言 #line 常量 ‘ 文件名" #line 常量 将使编译器认为: 下一行源代码的行号是以十进制常量的形式给出的 并且,当前的输入文件是由该标识符命名的
12.7错误信息生成
#error 记号序列 使预处理器打印包含该记号序列的诊断信息
12.8pragma
#pragma 记号序列 将使预处理器执行一个与具体实现相关的操作 无法识别pragma将被忽略
12.9空指令
# 形式的预处理器将不执行任何操作
12.10预定义名字
某些标识符是预定义的,扩展后将生成特定的信息 它们同预处理器表达式运算符defined一样,不能取消定义或重新定义 __LINE__ 包含当前源文件函数 __FILE__ 包含正在编译的源文件的字符串 __DATE__ 编译日期 "Mmm dd yyyy" __TIME__ 编译时间 "hh:mm:ss" __STDC__ 整型常量1
13语法
存储类说明符:one of auto register static extern typedef 类型说明符:one of void char short int long float double signed unsigned 类型限定符:one of const volatile 结构或联合:one of struct union 枚举说明符: enum 常量: 整型常量 字符常量 浮点常量 枚举常量 控制指令: #define 标识符 记号序列 #define 标识符 (标识符表) 记号序列 #undef 标识符 #include <文件名> #include "文件名" #include 记号序列 #line 常量 "文件名" #line 常量 #error 记号序列 #pragma 记号序列
以上是关于c语言编程替换文件中字符串的主要内容,如果未能解决你的问题,请参考以下文章