算法基础知识(全连接层、LSTM、激励函数)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法基础知识(全连接层、LSTM、激励函数)相关的知识,希望对你有一定的参考价值。
参考技术A 1、全连接层作用:全连接的一个作用是维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。
全连接另一个作用是隐含语义的表达(embedding),把原始特征映射到各个隐语义节点(hidden node)。对于最后一层全连接而言,就是分类的显示表达
2、简述LSTM如何解决梯度消失
LSTM有能力向单元状态中移除或添加信息,通过门结构来管理,包括“遗忘门”,“输出门”,“输入门”。通过门让信息选择性通过,来去除或增加信息到细胞状态. 模块中sigmoid层输出0到1之间的数字,描述了每个成分应该通过门限的程度。0表示“不让任何成分通过”,而1表示“让所有成分通过!
一个对RNN和LSTM分析比较好的连接 (注意理解体会一下他说的公式)
3、激励函数:
作者这篇激励函数写的也很好 (我们实际中一般遇见都是非线性问题,所以对特征做了加权线性操作需要通过非线性的激励函数做非线性的变换)
激励函数选择
4、BP的反向推导( 详细参考 )( 参考2 )
caffe源码 全连接层
图示全连接层
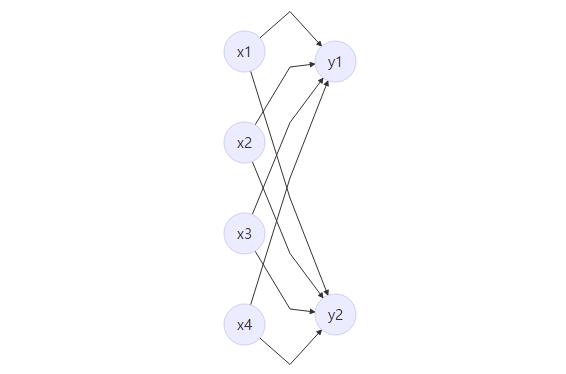
- 如上图所示,该全链接层输入n * 4,输出为n * 2,n为batch
- 该层有两个参数W和B,W为系数,B为偏置项
- 该层的函数为F(x) = W*x + B,则W为4 * 2的矩阵,B 为 1 * 2 的矩阵
从公式理解全连接层
假设第N层为全连接层,输入为Xn,输出为Xn+1,其他与该层无关的信息可以忽略
- 该层公式有Xn+1 = Fn(Xn) = W * Xn + B
前向传播
- 已知Xn,Xn+1 = W * Xn + B, 为前向传播
反向传播
反响传播这里需要求两个梯度,loss 对 W的梯度 和 loss 对 B 的梯度,
- loss 对 W 的梯度
- 具体公式如下:
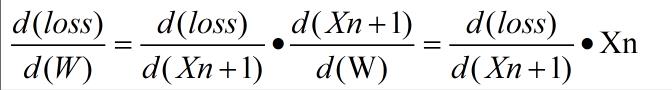
- 具体公式如下:
- loss 对 B 的梯度
- 具体公式如下:
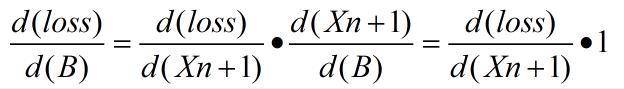
- 具体公式如下:
- 上面两个梯度都用到了loss 对 该层输出的梯度,所以在这层应该把loss 对该层输入的梯度传递到上一层。
- 具体公式如下:
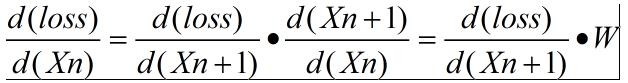
- 具体公式如下:
caffe中innerproduct的代码
前向传播
这一步在代码里面分为两步:
- Xn+1 = W * Xn,如下图:
- Xn+1 = Xn+1 + B,如下图:
- 和上面推导的一样


反向传播
这里需要求三个梯度,loss 对 W的梯度 ,loss 对 B的梯度, loss 对 Xn的梯度
- loss 对 W 的梯度
- 公式:
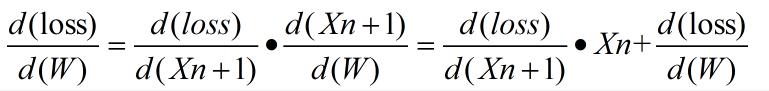
- 代码:

- 以上公式和推导的公式有点区别,后面加多loss 对W 的梯度,实现的是累积梯度
- 公式:
- loss 对 B 的梯度
- 公式:
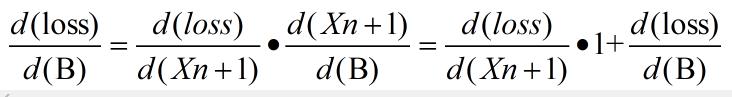
- 代码:

- 以上公式和推导的公式有点区别,后面加多loss 对B 的梯度,实现的是累积梯度
- 公式:
- loss 对 Xn 的梯度,:
- 公式:
- 代码:

- 公式和推导的并无区别
- 公式:
以上是关于算法基础知识(全连接层、LSTM、激励函数)的主要内容,如果未能解决你的问题,请参考以下文章