恐怖的ChatGPT!
Posted zhangyanfei01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恐怖的ChatGPT!相关的知识,希望对你有一定的参考价值。
大家好,我是飞哥!
不知道大家那边咋样。反正我最近感觉是快被ChatGPT包围了。打开手机也全是ChatGPT相关的信息,我的好几个老同学都在问我ChatGPT怎么用,部门内也在尝试用ChatGPT做一点新业务出来。
那就干脆我就趁清明假期这一天宝贵的时间,自己也投入学习了一下。今天把我的思考以一篇文章的形式总结给大伙,给大家交份作业。文末再推荐一个圈内最近很火的新社区。
对于ChatGPT,我学习的结果就是,这玩意儿真心强大,大概率不是一阵转瞬即逝的风,很有可能会引领下一波的科技革命。
在说ChatGPT以前,先容飞哥来扯扯互联网最近这二十年的发展。然后你就能理解ChatGPT强在哪儿了。
其实最近二十年互联网此起彼伏的新产品,看起来发展的杂乱无章,但其实都是有一个核心逻辑在,那就是加速信息流转效率。
过去二十年的互联网大致可以分为三个时代。
第一个时代是门户网站时代。这个时代的产品是把互联网上的网页分门别类地按照某种结构组织一下。然后用户可以按照类型到门户上寻找自己想要的类型的信息。新浪、网易、搜狐三大门户网站,再加上后起之秀腾讯新闻都算是这个时代的典型产品。
第二个时代是搜索引擎时代。随着信息进一步爆炸,门户网站那少的可怜的点击入口已经无法满足对海量信息的组织和查阅。所以一种新的基于爬虫和索引的产品诞生了,就是搜索引擎。它把海量的网页上的信息都通过索引组织了起来。用户仅仅只需要通过一个简单的搜索框就可以查阅互联网上的海量信息。国外的Google、国内的百度,还有飞哥我所工作过的腾讯搜搜,还有搜狗都是这个信息分发时代的产品。
第三个时代是个性化推荐时代。这个时代,信息进一步爆炸。用户可能连有价值的信息相关的检索词都想不出来了。这时候优质的内容就需要通过个性化推荐的方式触达用户。让用户更低成本地找到自己感兴趣的信息。在这个新的时代里最典型的公司就是字节跳动。不管是图文类的新闻,还是短视频都是通过个性化推荐来送给用户的。字节算是踏上了这波技术分发趋势,一举从2012年的一家小创业公司,做成现在比肩腾讯阿里的大厂。
那未来的信息分发技术变革趋势是啥?之前我是有点没太想明白还能有啥比个性化推荐更牛的新的分发方式。但看到ChatGPT后,我似乎看到了下一场信息分发革命的触发点。
先来咬文嚼字说一下ChatGPT的这个名词。Chat不用说了,就是聊天形式。主要是GPT,它的全称是“Generative Pre-trained Transformer”。其中Generative含义是生成式的,我认为这是最具突破性的技术关键点。
在互联网发展的前三个时代里,无论是门户网站、搜索引擎、甚至是后来的个性化推荐,它们所能做的就是把别人生产的信息推荐给你而已,区别仅仅只是分发的方式效率越来越高。
而ChatGPT不同的是,它不仅仅只是简单地把已有的文章,视频分发给你。而是做的更进一步,直接把海量的内容自己先消化(训练)一遍,然后按照你的要求生成一份新的。
以前你的导师让你写一篇论文,你可能是网上搜索半天,然后自己消化消化,再按自己的理解写一篇新的出来。现在ChatGPT也具备了这个能力了,它可以帮你按你的要求生成一篇新论文!
以前你的老板让你画一副画,你自己得学习好多年,然后才能开始自己的创作。而现在ChatGPT也具备了画画的学习能力,可以直接按你的想法给你画一幅。
以前的互联网在你的工作中只是一个提供原材料的角色,现在ChatGPT直接给你提供成品了。这种技术突破力真的不可谓不大。
所以,我隐隐约约地感觉到,我之前所没想通下一代的信息技术分发方式,现在来看,我觉得可能就是ChatGPT了。人类未来10年、20年甚至30年的最大革命可能就是它。
扯完了互联网,再来容飞哥扯一扯ChatGPT和人的大脑的关系。
你可能会想,这哪儿能有啥可比性,我们人类的大脑可是这个地球上最聪明的东西。
我们来回顾下ChatGPT3.5,在这个版本里参数只有1750亿个。所以ChatGPT刚刚出来的时候,甚至还遭受了很多人的耻笑。说这玩意儿很多时候都是在一本正经的胡说。
而现在才刚刚过去了几个月,一个100w亿参数的GPT-4模型就已经可以开放给大众使用了。这家伙已经能轻松通过美国的律师考试,且考进了前10%的排名。除了律师考试,GPT-4还在美国大学入学测试SAT中考到710分,这是一个美国大学录取的水平。还在大学的基础微积分课程中获得4的成绩(5分为满分)。
再来看看我们引以为傲的人类的大脑。我们人类的大脑皮层包含了大约140~160亿个神经元,我们的小脑包含了大约550~700亿个神经元,负责思考的大脑皮层里每一个神经元平均有3w多个突出。简单算一下,大脑皮层的神经元链接总数大约是(140亿~160亿)*3w/2,约等于210w亿到240w亿。
确实,目前人类大脑神经元的数量的200多万亿还领先于ChatGPT4的100万亿个参数。或者你也有可能会说,人类碳基的神经元和硅基里的参数没啥可比性。但你不要忘了一个事情,那就是技术爆炸。
ChatGPT现在还只是个婴儿时期的产品。再等上十年二十年之后呢,它的训练参数再翻个十倍百倍的是个大概率事件。而我们人类的大脑在十年时间维度上,基本可以等同于不变。那个时候的ChatGPT,绝对会在绝大部分工作上都比我们人类完成的要好。未来AI的写作能力、编程能力、绘画能力、推理能力、编剧能力全面超过人类专业人士应该只是时间问题。
所以,现在各个大厂都在争先恐后地入局。应该都是看到了ChatGPT可能会引领的下一场场新技术革命,谁跑的慢了,可能就会在下一个时代中被甩下巨头的列车。
那我们普通的技术人能做什么呢?虽然我们现在都还没太完全想明白。但有一点是明确的,那就是我们可以先了解起来。个人确实不容易找到方向,那就让我们加入到一个大社群中来碰撞一下。
我挑选了一个比较优秀的知识星球,我也刚以嘉宾的身份加入到其中。我之所以注意到这个星球,是因为这个星球刚刚运营13天就突破了8000多人,发展非常迅速。
我加入之前找星主洋哥也聊了一下,了解到他不是兼职在搞这个事情。也是已经雇佣了全职员工,而且也在注册公司,准备全力投入到ChatGPT这场盛宴中来。得知我也在了解ChatGPT,洋哥很爽快地把我邀请进星球当嘉宾。所以如果你加进来后,也可以在星球里和我互动。
这个星球中还邀请了很多行业内的AI大咖,比如腾讯的大模型技术专家、阿里的大模型技术专家、虾皮算法部门技术专家、头条的算法专家、商汤的AI产品专家,再比如已经将ChatGPT赋能到自己创业上的考考CEO等等。甚至还有好几个光年之外(王慧文AI创业团队)的超级大咖加入,甚至互联网超级投资大佬吴世春也加入了!
不光人多,活跃度也是非常的高。各路大佬都在踊跃地发表自己的新理解。
星球里虽然只有短短的13天,但也已经发展出了成体系的内容建设。

而且星主洋哥的目标也不是做星球。而是想通过星球把有共同爱好和目标的人聚集到一起,将来发展成一个AI创投社区,搞成一个大平台。甚至是你有什么好的项目都可以在这个平台推广融资,而不仅仅局限于学习。
汇总说下这个星球能给大家提供什么:
1.这里有AI行业内的高手,为你分享ChatGPT最新的玩法。
2.你可以在这里找到志同道合的小伙伴,一起探讨甚至实现AI创业。
3.系列AI训练课程,持续且免费的供应给会员,带领大家在AI时代做应用。
4.一个月最少一次AI领域大佬的技术直播,上周末已经举办第一次,有系列录播。
5.4月6日前加入星球的小伙伴,都有一项额外福利,送星球合伙人研发的ZelinAI,ZelinAI原价全年999元,星球会员一年免费!它让小白也能用好ChatGPT,甚至能零代码创建AI应用。
现在星球在运营初期,正式运营价格定为699,目前加入是最低价198。等后面人数破万以后,大概率是会涨价。趁现在还只是在商场一顿饭钱的价格,可以入手!

ChatGPT的N种用法(持续更新中。。。)
目录
- 前言
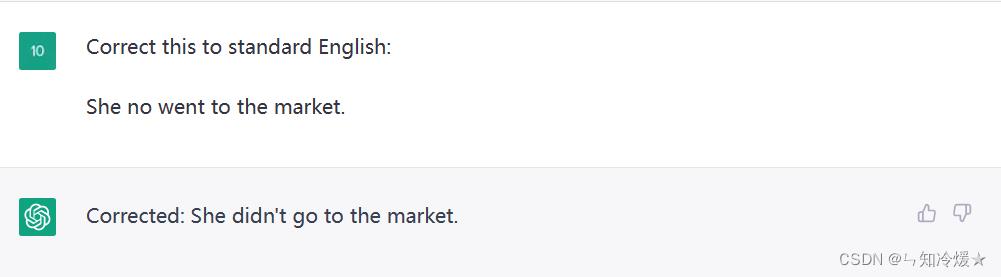
- 一、语法更正
- 二、文本翻译
- 三、语言转换
- 四、代码解释-1
- 五、代码解释-2
- 六、修复代码错误
- 六、作为百科全书
- 七、信息提取
- 七、好友聊天
- 八、创意生成器
- 九、采访问题
- 十、论文大纲
- 十一、故事创作
- 十二、问题类比
- 二十、闲聊机器人
- 总结
前言
当今的ChatGPT是一个强大的语言模型,它可以帮助您创建出色的产品并提高您的业务成功率。ChatGPT利用大规模的自然语言处理和机器学习算法,可以进行自然而流畅的对话,理解自然语言问题和回答。您可以使用ChatGPT来建立智能客服、智能助手、文本自动补全、语音识别和机器翻译等多种产品。ChatGPT可以快速适应新的数据和新的场景,使用ChatGPT,您可以轻松实现个性化、高效率和全天候的服务。让ChatGPT帮助您推动业务的增长!一、语法更正
用途:文章、论文等润色。
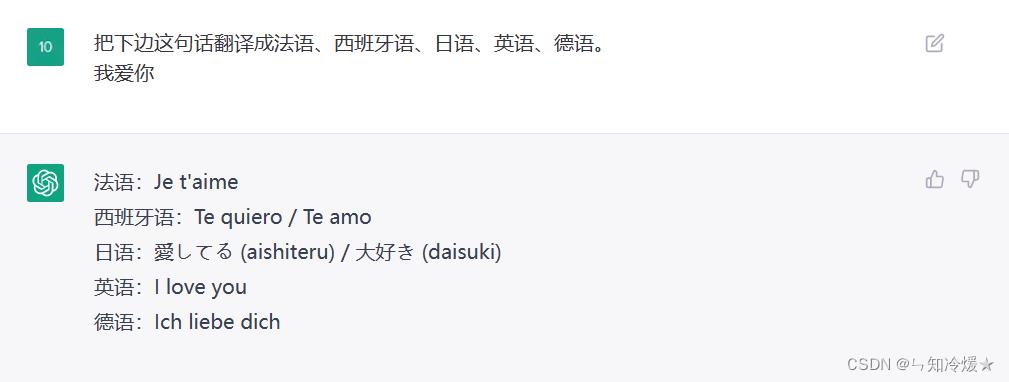
二、文本翻译
用途:日常学习、商务翻译等。
三、语言转换
3-1、Python–>JAVA
用途:工作用途,不同语言工程师之间的合作,更加方便。

import numpy as np
import plotly.express as px
def thresholding_algo(y, lag, threshold):
"""
:param y: 输入列表
:param lag: 滑动窗口大小
:param threshold: 调节系数,用于调节容忍范围的大小。
:return:
"""
# signals:信号列表
signals = np.zeros(len(y))
avgFilter = np.zeros(len(y))
# 初始化平均值列表、差值列表
avgFilter[lag - 1] = np.mean(y[0:lag])
dif_li = [0] * len(y)
for i in range(lag, len(y)):
if i < len(y) - lag - 30:
for j in range(i + 11, len(y)):
if y[j] >= y[i - 1]:
break
if j >= len(y) - 30:
back = y[i - 1]
else:
back = np.mean(y[j + 11:j + 20 + lag])
else:
back = y[i - 1]
# 前后均值差值计算
tmp = abs(back - avgFilter[i - 1])
dif = (tmp if tmp > 1 else 1)
if abs(y[i] - avgFilter[i - 1]) > dif * threshold:
signals[i] = (1 if y[i] > avgFilter[i - 1] else -1)
avgFilter[i] = np.mean(y[(i - lag):i])
y[i] = avgFilter[i - 1]
else:
signals[i] = 0
avgFilter[i] = np.mean(y[(i - lag):i])
dif_li[i] = dif
return dict(signals=np.asarray(signals),
avgFilter=np.asarray(avgFilter),
y=np.asarray(y),
dif=np.asarray(dif_li),
)

public static Map<String, double[]> thresholding_algo(double[] y, int lag, double threshold)
double[] signals = new double[y.length];
double[] avgFilter = new double[y.length];
Arrays.fill(avgFilter, 0.0);
avgFilter[lag - 1] = mean(Arrays.copyOfRange(y, 0, lag));
double[] dif_li = new double[y.length];
Arrays.fill(dif_li, 0.0);
for (int i = lag; i < y.length; i++)
int j;
if (i < y.length - lag - 30)
for (j = i + 11; j < y.length; j++)
if (y[j] >= y[i - 1])
break;
double back;
if (j >= y.length - 30)
back = y[i - 1];
else
back = mean(Arrays.copyOfRange(y, j + 11, j + 20 + lag));
else
back = y[i - 1];
double tmp = Math.abs(back - avgFilter[i - 1]);
double dif = tmp > 1 ? tmp : 1;
if (Math.abs(y[i] - avgFilter[i - 1]) > dif * threshold)
signals[i] = y[i] > avgFilter[i - 1] ? 1 : -1;
avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));
y[i] = avgFilter[i - 1];
else
signals[i] = 0;
avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));
dif_li[i] = dif;
Map<String, double[]> result = new HashMap<>();
result.put("signals", signals);
result.put("avgFilter", avgFilter);
result.put("y", y);
result.put("dif", dif_li);
return result;
private static double mean(double[] array)
double sum = 0.0;
for (double d : array)
sum += d;
return sum / array.length;
四、代码解释-1
用途:当我们来到一家新的公司,发现前任工程师留下了一摊谁都看不懂的代码,这时候,如果有个人能帮我们解释一下这些代码是什么意思,那简直不要太开心。

def Fusion_algorithm(y_list):
"""
最终的融合算法
1、第一次遍历列表: 处理掉小于上一个值的点,使其等于上一个值。
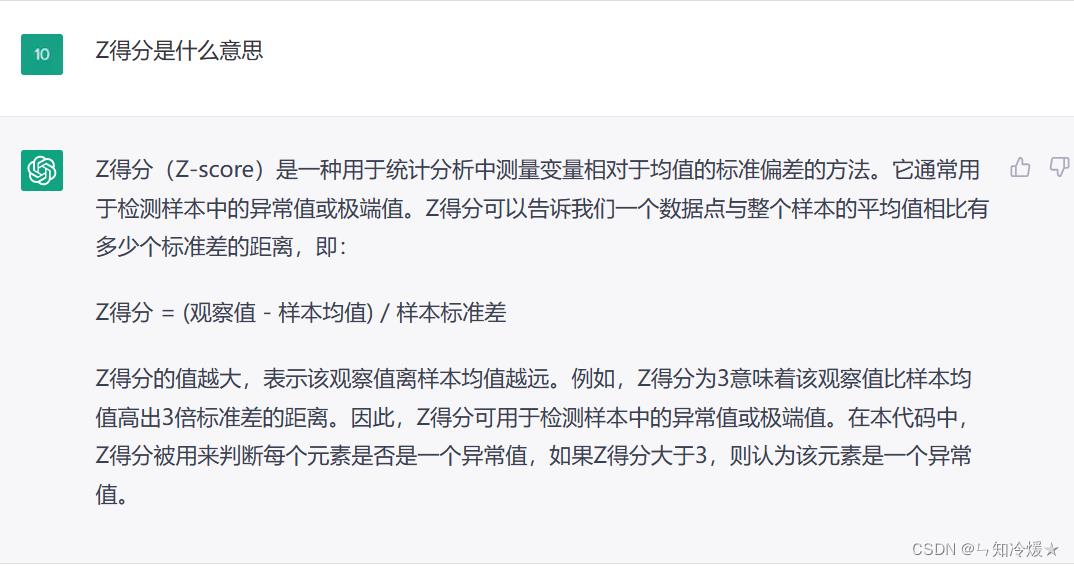
2、第二次使用z-score来处理异常点:一种基于统计方法的时序异常检测算法借鉴了一些经典的统计方法,比如Z-score和移动平均线
该算法将时间序列中的每个数据点都看作是来自一个正态分布,通过计算每个数据点与其临接数据点的平均值和标准差,可以获得Z-score
并将其用于检测异常值,将z-score大于3的数据点视为异常值,缺点:如果异常点太多,则该算法的准确性较差。
3、
:param y_list: 传入需要处理的时间序列
:return:
"""
# 第一次处理
for i in range(1, len(y_list)):
difference = y_list[i] - y_list[i - 1]
if difference <= 0:
y_list[i] = y_list[i - 1]
# 基于突变检测的方法:如果一个数据点的值与前一个数据点的值之间的差异超过某个阈值,
# 则该数据点可能是一个突变的异常点。这种方法需要使用一些突变检测算法,如Z-score突变检测、CUSUM(Cumulative Sum)
# else:
# if abs(difference) > 2 * np.mean(y_list[:i]):
# y_list[i] = y_list[i - 1]
# 第二次处理
# 计算每个点的移动平均值和标准差
ma = np.mean(y_list)
# std = np.std(np.array(y_list))
std = np.std(y_list)
# 计算Z-score
z_score = [(x - ma) / std for x in y_list]
# 检测异常值
for i in range(len(y_list)):
# 如果z-score大于3,则为异常点,去除
if z_score[i] > 3:
print(y_list[i])
y_list[i] = y_list[i - 1]
return y_list

五、代码解释-2
备注:上一个代码解释,我们可以看到,答案或许受到了代码中注释的影响,我们删掉注释,再来一次。对于解释中一些不懂的点,我们可以连续追问!

import numpy as np
from sklearn.ensemble import IsolationForest
import plotly.express as px
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import json
def Fusion_algorithm(y_list):
for i in range(1, len(y_list)):
difference = y_list[i] - y_list[i - 1]
if difference <= 0:
y_list[i] = y_list[i - 1]
# else:
# if abs(difference) > 2 * np.mean(y_list[:i]):
# y_list[i] = y_list[i - 1]
ma = np.mean(y_list)
std = np.std(y_list)
z_score = [(x - ma) / std for x in y_list]
for i in range(len(y_list)):
if z_score[i] > 3:
print(y_list[i])
y_list[i] = y_list[i - 1]
return y_list

六、修复代码错误
用途:写完一段代码后发现有错误?让chatGPT来帮你!

### Buggy Python
import Random
a = random.randint(1,12)
b = random.randint(1,12)
for i in range(10):
question = "What is "+a+" x "+b+"? "
answer = input(question)
if answer = a*b
print (Well done!)
else:
print("No.")

六、作为百科全书
用途:chatGPT可以解释你所有的问题!但是列出小说这个功能有些拉跨,经过测试只有科幻小说列的还可以,其他类型不太行,可能chatgpt训练工程师是个科幻迷!

七、信息提取
用途:作为自然语言处理界的大模型,怎么能少得了信息提取呢?
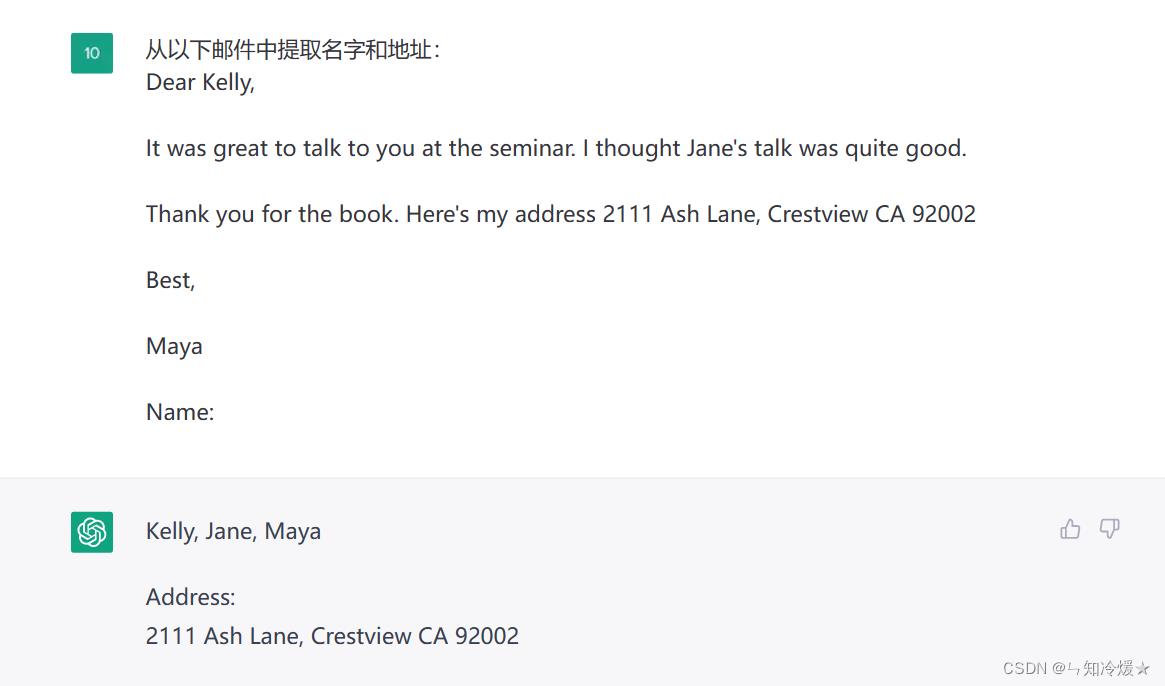
七、好友聊天
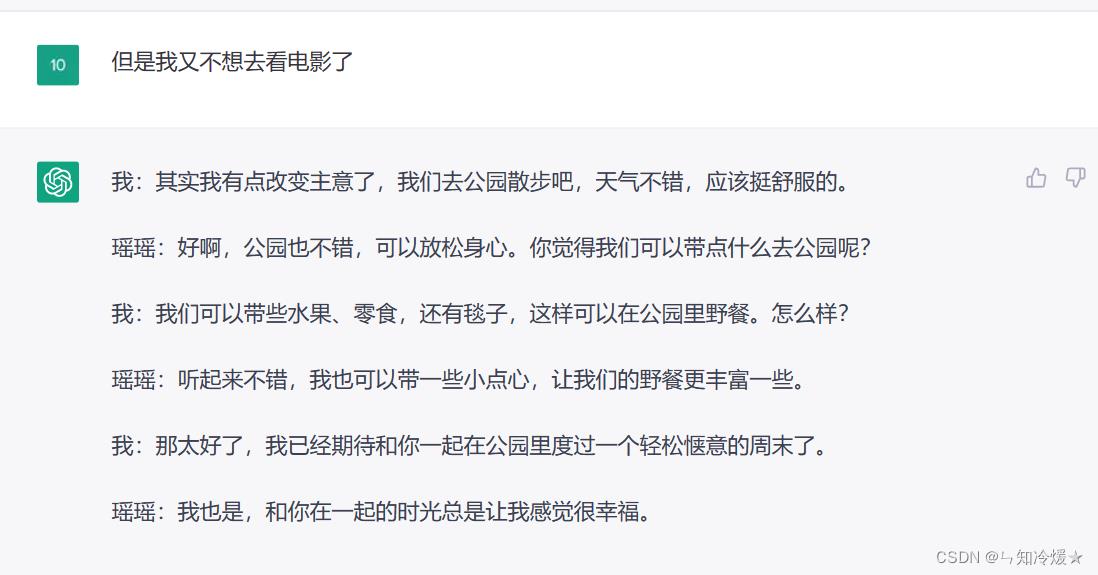
用途:输入对方性格模拟聊天,这方面功能不太完善,可能有新鲜玩法我还没有挖掘出来。

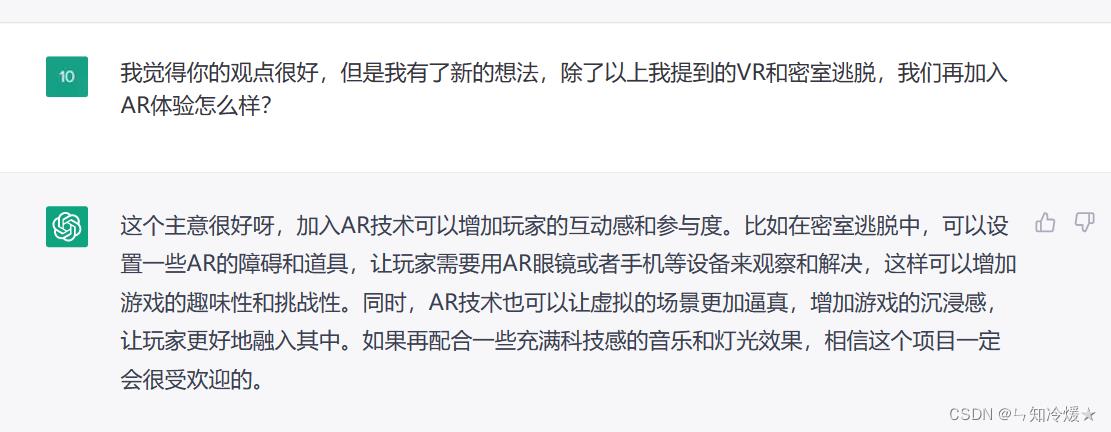
八、创意生成器
用途:是不是常常会在创新上遇到思维瓶颈不知道怎么做?不要担心,让chatGPT帮你生成创意!
8-1、VR和密室结合

8-2、再结合AR
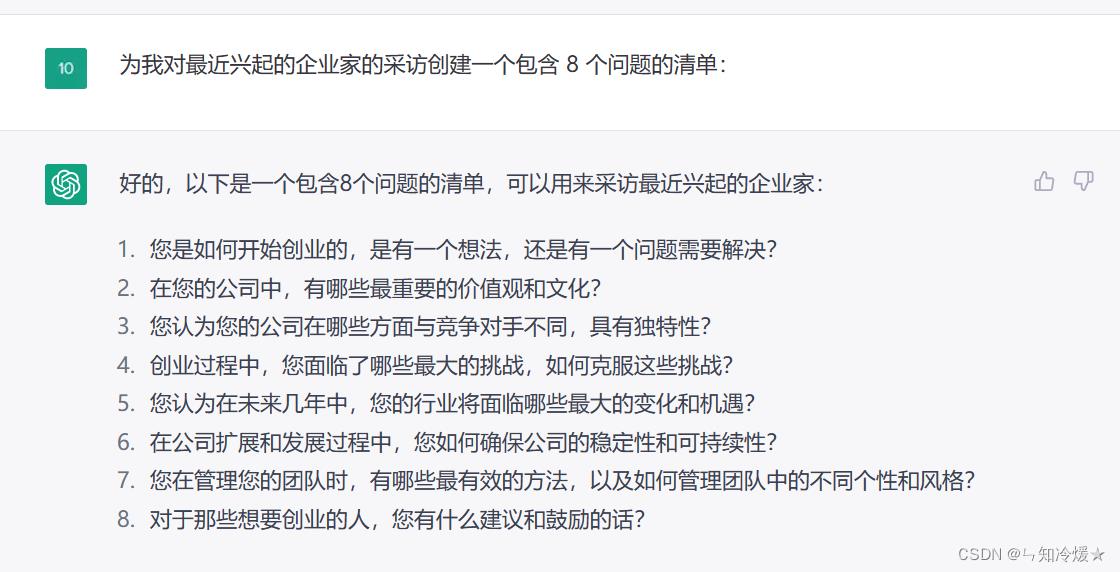
九、采访问题
用途: 可能您是一个媒体工作者,采访问题不知道怎么写?chatGPT可以帮您解决。
9-1、采访问题清单
9-2、采访问题清单并给出相应答案

十、论文大纲
用途: 这个功能对于研究生简直不要太爽了,一直在郁闷大纲怎么写,直接列出来大纲简直帮了我天大的忙!对于大纲中不理解的点,直接要求chatGPT给出进一步解释。代码也可以有!那一章的内容不太会写,直接让chatGPT安排,这样,一篇论文很快就写出来啦!
10-1、创建论文大纲

10-2、解释大纲内容

class PBA(nn.Module):
def __init__(self, PerformanceThreshold, DistributionType, AttentionWeightRange):
super(PBA, self).__init__()
self.PerformanceThreshold = PerformanceThreshold
self.DistributionType = DistributionType
self.AttentionWeightRange = AttentionWeightRange
def forward(self, input, performance_scores):
# 计算注意力分数
attention_scores = []
for i in range(len(input)):
if performance_scores[i] > self.PerformanceThreshold:
attention_scores.append(performance_scores[i])
else:
attention_scores.append(0.0)
# 将性能分数映射到注意力权重
if self.DistributionType == "softmax":
attention_weights = F.softmax(torch.tensor(attention_scores), dim=0)
elif self.DistributionType == "sigmoid":
attention_weights = torch.sigmoid(torch.tensor(attention_scores))
else:
raise ValueError("Unknown distribution type: ".format(self.DistributionType))
# 缩放注意力权重到指定范围
attention_weights = attention_weights * (self.AttentionWeightRange[1] - self.AttentionWeightRange[0]) + self.AttentionWeightRange[0]
# 计算加权输入
weighted_input = torch.mul(input, attention_weights.unsqueeze(1).expand_as(input))
output = torch.sum(weighted_input, dim=0)
return output
十一、故事创作
用途: 这个功能真的太太太棒了,以后我自己列提纲出来就可以写小说啦!
11-1、爱情故事

11-2、恐怖故事


十二、问题类比
二十、闲聊机器人
用途:这个不多说了,用来闲聊体验感真的很不错。
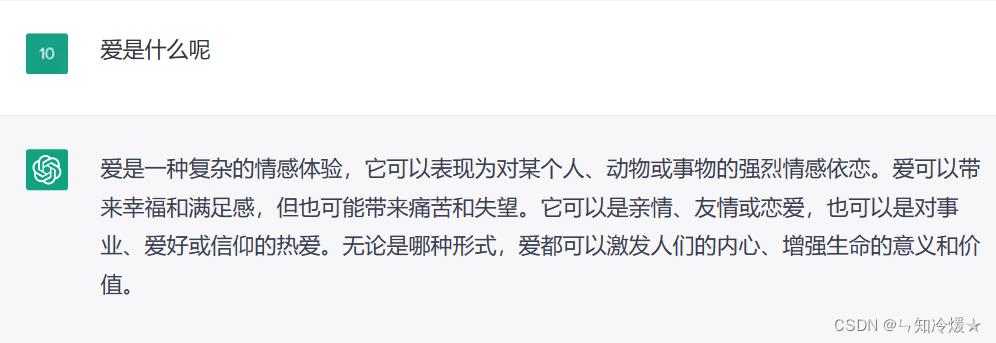

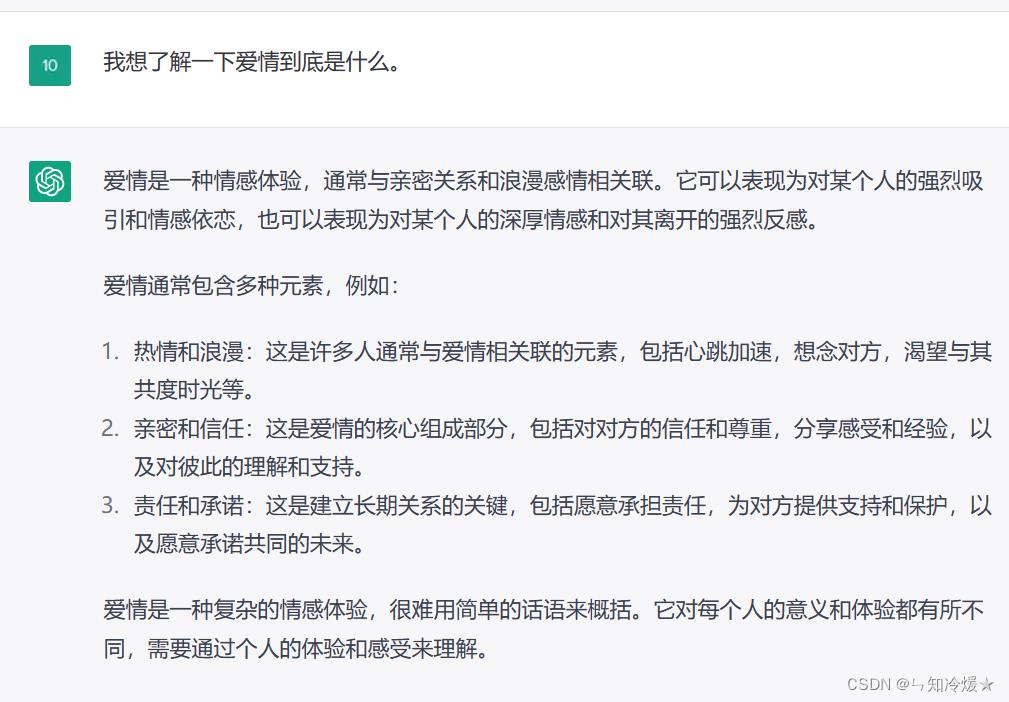
总结
emmm,今天白嫖chatGPT次数太多了,request请求被禁止了,那就改天再请求啦~
以上是关于恐怖的ChatGPT!的主要内容,如果未能解决你的问题,请参考以下文章