一文入门NodeJS
Posted 逸鹏说道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文入门NodeJS相关的知识,希望对你有一定的参考价值。
NodeJS¶
1.环境配置¶
之前讲ES6的时候有提过一部分Node的知识,简单回顾下:一文读懂ES6
1.1.NPM国内镜像¶
npm国内镜像:https://npm.taobao.org
配置国内源:npm install -g cnpm --registry=https://registry.npm.taobao.org
然后就可以把cnpm当作npm来用了,比如之前的React组件案例:
cnpm install reactcnpm install react-domcnpm i babel-core@old
卸载安装的包:npm uninstall -g uuid用npm而不是cnpm
常用参数说明:
i是install的简写-g是安装到全局环境中(默认是当前目录)-D添加为开发依赖(-D ==> --save-dev开发环境)-S添加为生产依赖(-S ==> --save生产环境)- eg:
cnpm i express -S
- eg:
eg:cnpm init之后: 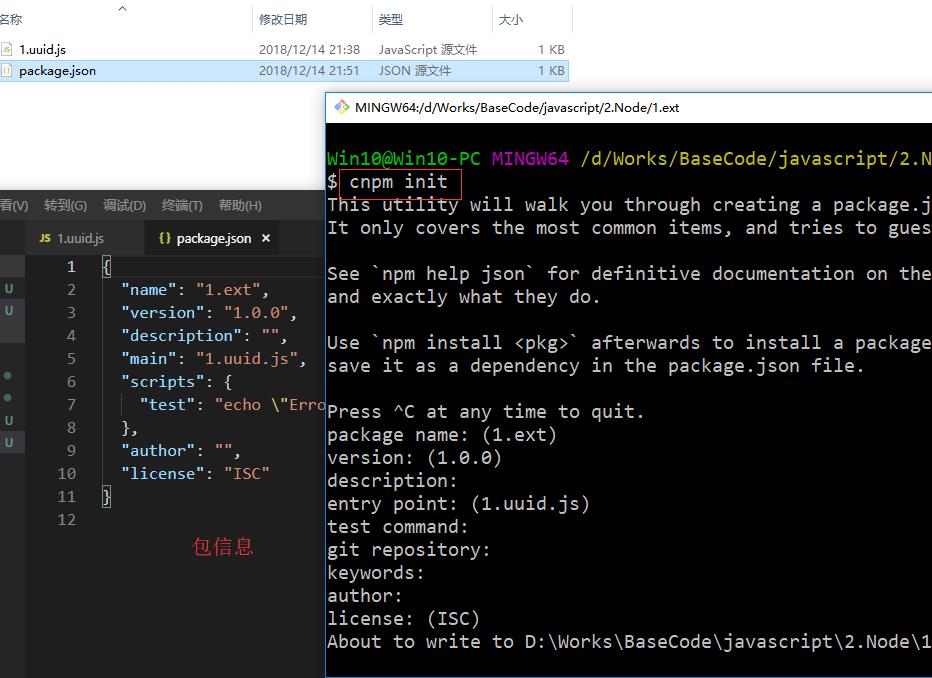
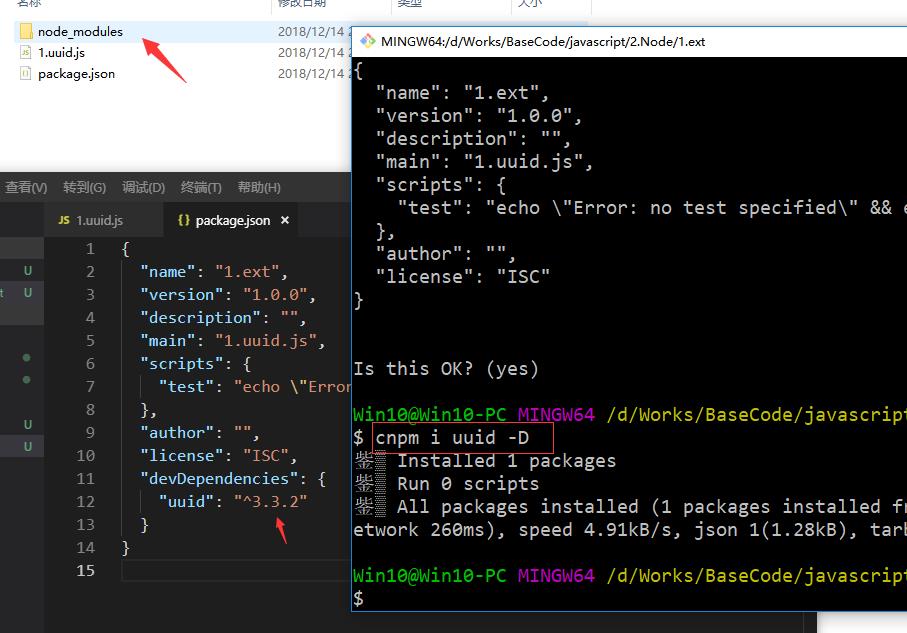
PS:你把依赖包删了也没事,执行cnpm i就会会根据package.json自动安装依赖包
课外阅读:
npm如何管理依赖包的版本
https://www.jianshu.com/p/1470c5d7b8c3
禁止npm自动升级依赖包以及所有下级依赖包版本的方法
https://www.jianshu.com/p/f481cf9b08171.2.VSCode调试¶
这个之前也说过,可以看看:VSCode and NoteBook for JavaScript | NodeJS,简单说下:
每次F5运行的时候选一下NodeJS,或者添加一下调试的配置文件
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "启动程序",
"program": "${workspaceFolder}/${relativeFile}"
}
]
}
nodejs用法和js基本一样,只是多了些服务器的模块,eg: 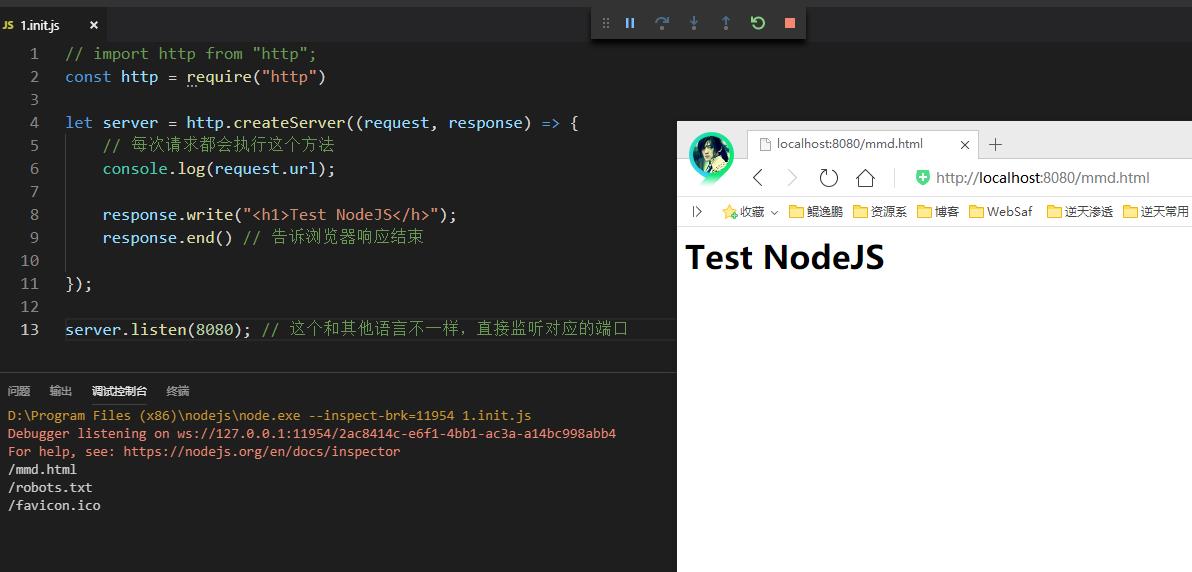
配置NodeJS和html¶
如果想同时运行nodejs和html再添加下配置就行了,比如:
{
"version": "0.2.0",
"configurations": [
{
"type": "chrome",
"request": "launch",
"name": "Launch Chrome against localhost",
"url": "http://localhost:8080/${relativeFile}",
"webRoot": "${workspaceFolder}"
},
{
"type": "node",
"request": "launch",
"name": "启动程序",
"program": "${workspaceFolder}/${relativeFile}"
}
]
}
配置完成后:想运行HTML就选择谷歌浏览器 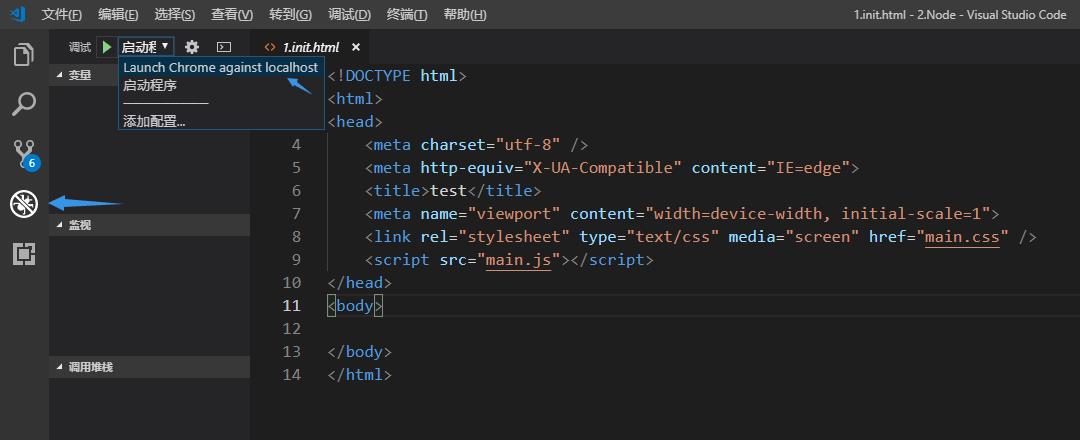
想运行nodejs的js文件就选择启动程序(现在运行JS文件的时候,F5即可自动切换成node) 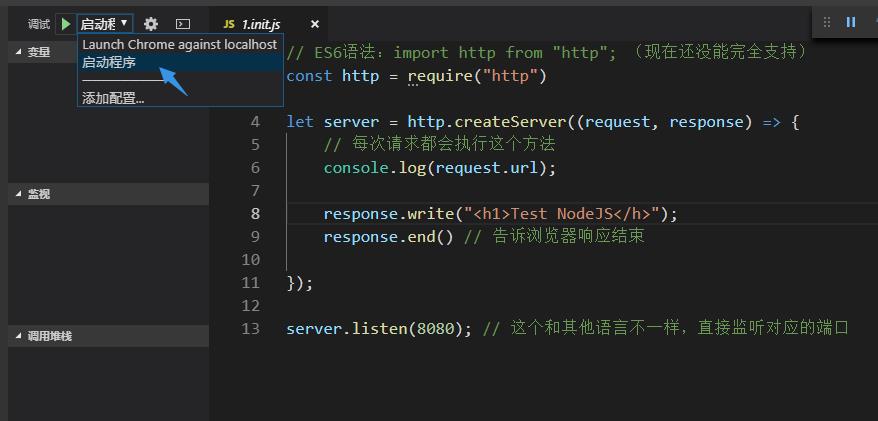
配置说明¶
${workspaceRoot}VS Code当前打开的文件夹${file}当前打开的文件${relativeFile}相对于workspaceRoot的相对路径${fileBasename}当前打开文件的文件名${fileDirname}所在的文件夹,是绝对路径${fileExtname}当前打开文件的扩展名
1.3.Jupyter NoteBook¶
ijavascript依赖于Python2.7,详细过程:Jupyter NoteBook IJavaScript 配置
# 如果nodejs和npm没安装可以先安装下
sudo apt-get install nodejs npm
# 把ijavascript安装到全局环境中
sudo npm install -g ijavascript
# 安装
ijsinstall
然后就和Python一样用了: 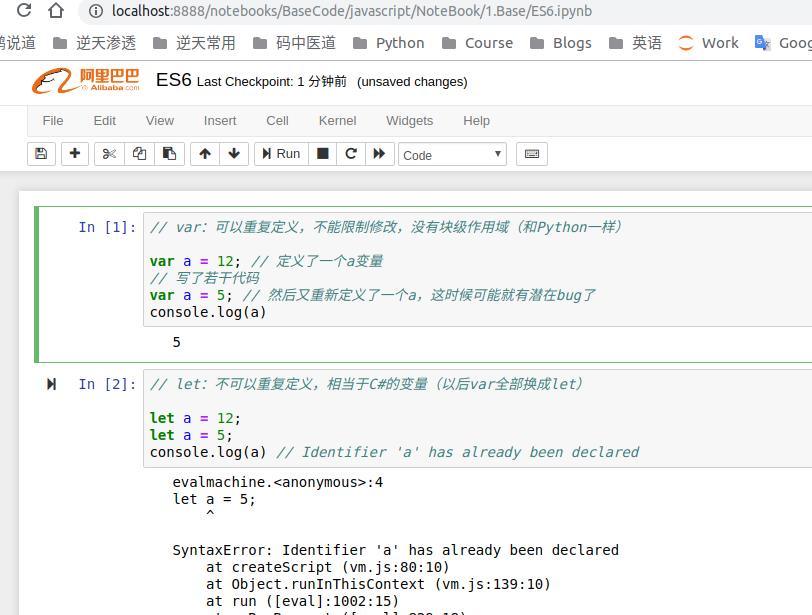
2.常用模块¶
这块官方文档写的很详细,我就简单说说,后面用到再详细说
中文文档:http://nodejs.cn/api
2.1.http(常用)¶
文档:http://nodejs.cn/api/http.html or https://nodejs.org/api/http.html
NodeJS既然作为服务器,那得先有个服务器的样子,我们来个简单的案例:
node
// ES6语法:import http from "http"; (现在还没能完全支持)
const http = require("http")
// 创建一个服务器
let server = http.createServer((request, response) => {
// 每次请求都会执行这个方法
console.log(request.url);
response.write("<h1>Test NodeJS</h>");
response.end() // 告诉浏览器响应结束
});
// 服务器启动并监听指定端口
server.listen(8080); // 这个和其他语言不一样,直接监听对应的端口效果:
其他内容需要结合其他模块一起讲解
2.2.fs(常用)¶
文档:http://nodejs.cn/api/fs.html or https://nodejs.org/api/fs.html
这个是IO对应的模块,推荐使用异步方法,简单看看:(xxxFileSync是同步方式,不建议使用)
const fs = require("fs");
// 文件读取
fs.readFile("test.txt",(ex,data) => {
// 如果文件不存在就输出错误信息
if(ex){
console.log(ex);
}else{
console.log(data.toString());
}
});
console.log("[ReadFile异步验证]我出现就是异步");
// 创建一个文件
fs.writeFile("test.txt","文本内容",ex => {
if(ex){
// 出错就输出info
console.log(ex);
}
});
console.log("[WriteFile异步验证]我出现就是异步");
// 文件追加
fs.appendFile("test.txt","追加内容",ex => {
if(ex){
// 出错就输出info
console.log(ex);
}
});
console.log("[AppendFile异步验证]我出现就是异步");
// 现在再读着看看
fs.readFile("test.txt",(ex,data) => {
// 如果文件不存在就输出错误信息
if(ex){
console.log(ex);
}else{
console.log(data.toString());
}
});
PS:如果文件不是文本文件,就不能toString了(data默认是buffer类型)
node
fs.readFile("知识星球.png", (ex, data) => {
if (ex) {
console.log("读取错误:", ex);
} else {
console.log(data); // 看看buffer是啥样的
fs.writeFile("test.png", data, ex => {
if (ex) {
console.log("复制错误:", ex);
}
});
}
});效果:
<Buffer 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 00 00 02 10 00 00 02 61 08 06 00 00 00 10 7e 89 ed 00 00 20 00 49 44 41 54 78 01 ec bd 07 98 64 57 79 ... >图片照常打开: 
简单小结一下:
- 读取文件:
fs.readFile("xxx", (ex, data) => { }); - 创建文件:
fs.writeFile("xxx", data, ex => {}); - 追加文件:
fs.appendFile("xxx", data, ex => {}); data是buffer类型,内置了:toString():buffer转换成字符串toJSON():buffer转化成Json
// 看个案例
data = { "name": "小明", "age": "23" };
fs.writeFile("to.txt", data, ex => {
if (ex) {
console.log(ex);
}
});
fs.readFile("to.txt", (ex, data) => {
if (ex) {
console.log(ex);
} else {
console.log(data);
console.log(data.toJSON());
console.log(data.toString());
console.log(data.toLocaleString());
}
});
注意点¶
上面几个方法(eg:readFile)都是先把数据都缓存到内存中,然后才回调,这样比较浪费内存,对于大文件不友好,so ==> 流走起
Stream(常用)¶
用法比较简单,看个案例:
node
const fs = require("fs");
let rs = fs.createReadStream("知识星球.png");
let ws = fs.createWriteStream("test.png");
// 可以这么理解,rs是水龙头防水的地方,写反了也就出不了水了
rs.pipe(ws); // 创建一个管道,流从r端到w端还有一些类似于监听的事件:
node
const fs = require("fs");
let rs = fs.createReadStream("知识星球.png");
let ws = fs.createWriteStream("test.png");
rs.pipe(ws); // 创建一个管道,流从r端到w端
// 可以理解为错误触发的事件
rs.on("error", ex => {
console.log("读取失败", ex);
});
rs.on("end", () => {
console.log("读取完成");
});
ws.on("error", ex => {
console.log("写入失败", ex);
});
// 注意,写入流完成不叫end
ws.on("finish", () => {
console.log("写入完成");
});2.3.url(常用)¶
文档:http://nodejs.cn/api/url.html or https://nodejs.org/api/url.html
说url模块之前得先说下querystring模块
1.querystring¶
文档:http://nodejs.cn/api/querystring.html or https://nodejs.org/api/querystring.html
这个是专门针对参数进行解析的,来个案例:
const querystring = require("querystring");
let jd_qs = "keyword=空气净化器&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&psort=3&stock=1&wtype=1&cod=1&click=2";
// 咋一看,好像挺方便,但是有坑:看下一个demo
let str = querystring.parse(jd_qs);
console.log(str)
// 用户请求一般都是类似于这样的
let jd_url = "https://search.jd.com/Search?keyword=空气净化器&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&psort=3&stock=1&wtype=1&cod=1&click=2";
// querystring.parse 只是对?后面(不包括`?`)的参数进行解析(以`=`和`&`分隔)
str = querystring.parse(jd_url);
console.log(str);
const url = require("url");
// port=null说明是默认端口(http:80,https:443)
let jd_url = "https://search.jd.com/Search?keyword=空气净化器&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&psort=3&stock=1&wtype=1&cod=1&click=2";
let str = url.parse(jd_url);
console.log(str); // 发现query并没有解析
// 想要解析`query`,可以多传一个参数
str = url.parse(jd_url, true);
console.log(str); // 对query解析
PS:一般都是这么用的:
node
// {a, b} = {a:21,b=34,c=22} 只要对应即可解包,如果想取别名可以使用:{a:xx, b} = {...}
let { pathname, query } = url.parse(request.url, true);3.前几个模块的综合案例¶
结合上面的HTTP模块,来个简单的web服务器:
node
const fs = require("fs");
const url = require("url");
const http = require("http");
// 创建服务
let server = http.createServer((request, response) => {
// 请求
// {a, b} = {a:21,b=34,c=22} 只要对应即可解包,如果想取别名可以使用:{a:xx, b} = {...}
let { pathname, query } = url.parse(request.url, true);
console.log(query, pathname);
// 读取对应文件
fs.readFile(`www${pathname}`, (ex, data) => {
if (ex) {
// 返回404状态码,并设置编码为UTF-8
response.writeHeader(404, {
"Content-Type": "text/html;charset=utf-8"
});
// 提示需要在 writeHeader 之后,不然访问的是浏览器404页面
response.write("<h1>访问的页面不存在~</h1>");
} else {
response.write(data);
}
// 响应结束
response.end();
});
});
// 服务器启动并监听指定端口
server.listen(8080);输出:(www目录就两个文件,一个test.html,一个test.png)
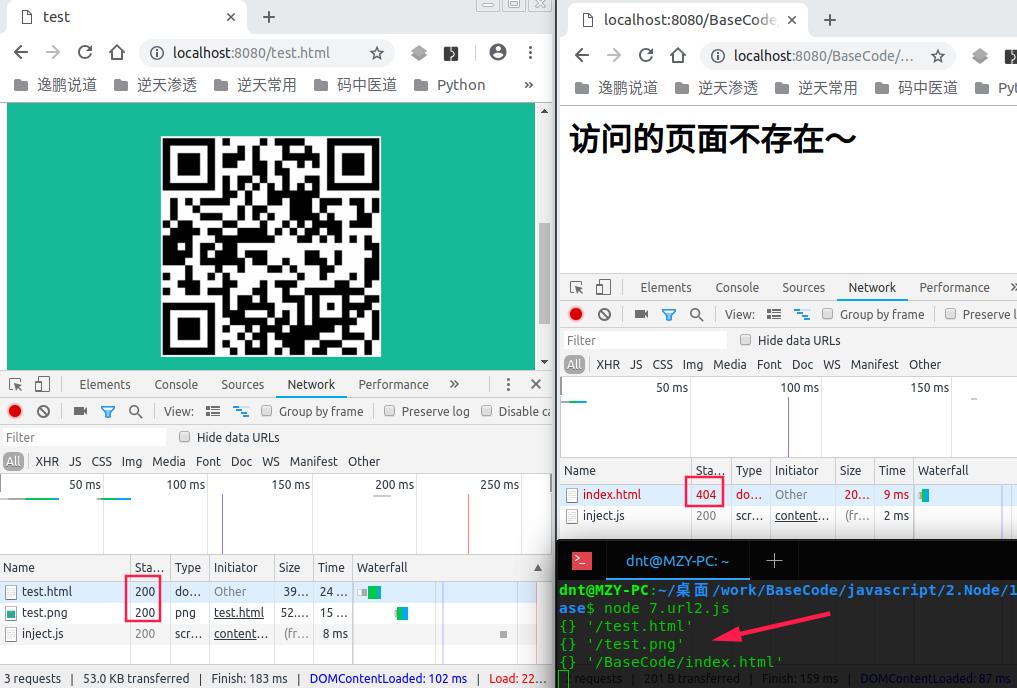
推荐写法:
node
const fs = require("fs");
const url = require("url");
const http = require("http");
let server = http.createServer((request, response) => {
let { pathname } = url.parse(request.url, true);
console.log(pathname);
let rs = fs.createReadStream(`www${pathname}`);
// `request`和`response`就是一个典型的读写流(`ReadStream`、`WriteStream`)
rs.pipe(response);
// 读取失败 ==> 404
rs.on("error", ex => {
response.writeHeader(404);
response.write("404 Not Found");
response.end();
});
});
server.listen(8080);PS:request和response就是一个典型的读写流(ReadStream、WriteStream)
2.4.zlib(常用)¶
文档:http://nodejs.cn/api/zlib.html or https://nodejs.org/api/zlib.html
先看个案例:(zlib是读写流)
node
const fs = require("fs");
const zlib = require("zlib");
// 读写流
let gz = zlib.createGzip();
// 读流
let rs =fs.createReadStream("./www/jquery-2.1.1.js");
// 写流
let ws =fs.createWriteStream("test.js.gz");
// 可以这么理解:(gz是读写流)
// rs水龙头先传给了gz,gz又当一个水龙头传给了ws
rs.pipe(gz).pipe(ws);
ws.on("finish",()=>{
console.log("写入完毕");
});效果: 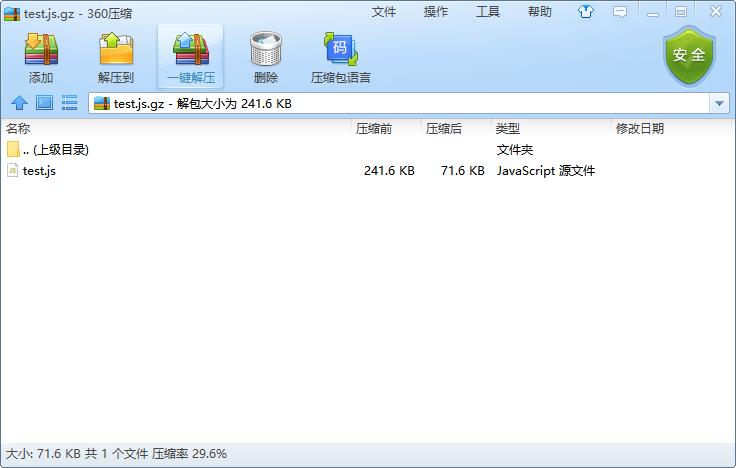
静态服务器¶
结合上面再来个加强版:
node
const fs = require("fs");
const zlib = require("zlib");
const http = require("http");
let server = http.createServer((request, response) => {
// let { pathname } = url.parse(request.url);
console.log(request.url);
let rs = fs.createReadStream(`www${request.url}`);
let gz = zlib.createGzip();
// 响应之前告诉浏览器是gzip的格式
response.setHeader("Content-Encoding", "gzip");
// 返回gzip压缩后的文件
rs.pipe(gz).pipe(response);
// 读取失败,404错误
rs.on("error", ex => {
response.removeHeader("Content-Encoding");
// 返回404状态码,并设置编码为UTF-8
response.writeHeader(404, {
"Content-Type": "text/html;charset=utf-8"
});
// 提示需要在 writeHeader 之后,不然访问的是浏览器404页面
response.write("<h2>您访问的页面不存在~</h2>");
response.end();
});
});
server.listen(8080, () => {
console.log("服务器启动成功,端口:8080");
});输出对比: 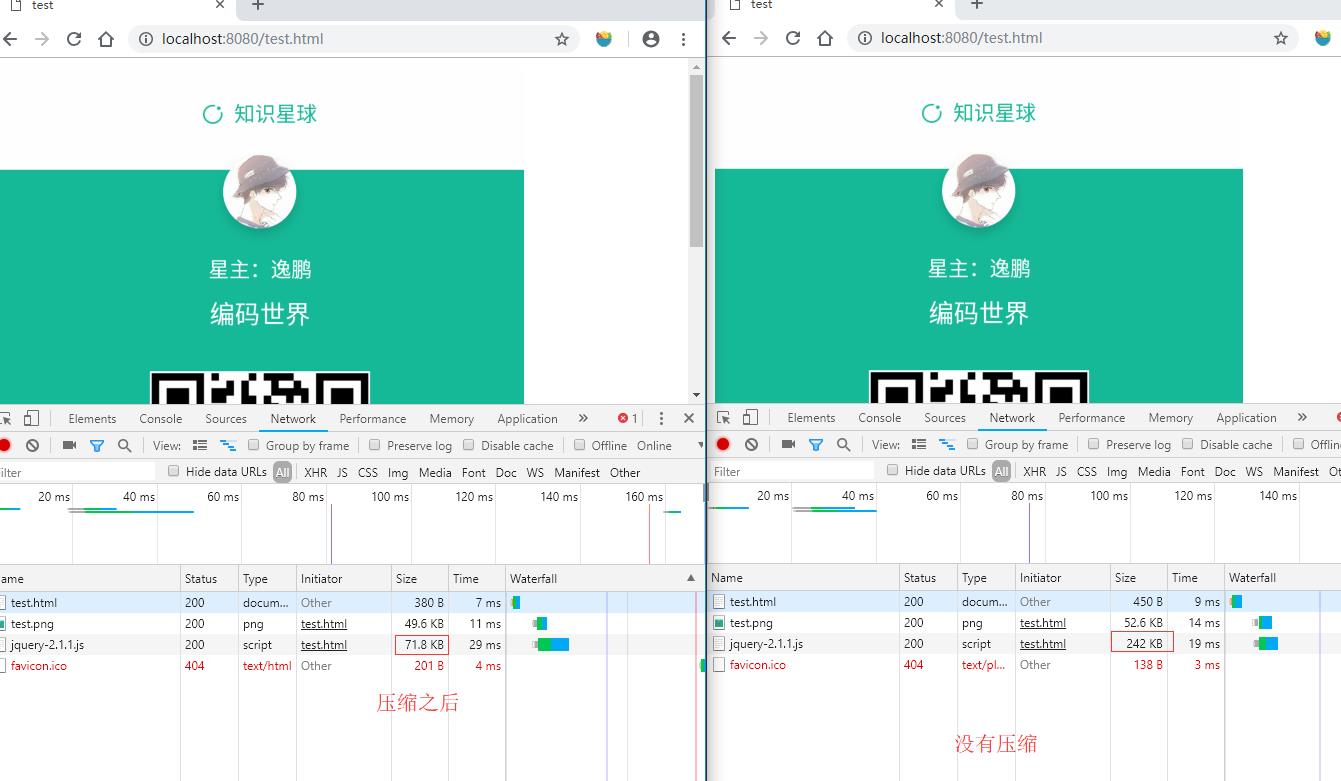
2.5.path¶
文档:http://nodejs.cn/api/path.html or https://nodejs.org/api/path.html
这个主要是针对路径的模块,看个案例:path.parse()
const path = require("path");
let file_name = "./images/png/小明.png";
// 文件路径 ./images/png
console.log(path.dirname(file_name));
// 提取出用 `/` 隔开的 `path` 的最后一部分
// 小明.png
console.log(path.basename(file_name));
// 文件后缀 .png
console.log(path.extname(file_name));
// 文件信息 {root: "", dir: "./images/png", base: "小明.png", ext: ".png", name: "小明"}
console.log(path.parse(file_name)); // 这个经常使用
// ------------------------------
// 当前文件所在文件夹绝对路径
console.log(path.resolve());
// 文件的绝对路径
console.log(path.resolve(file_name));
// 可以看看path的完整信息
console.log(path);
2.6.crypto¶
文档:http://nodejs.cn/api/crypto.html or https://nodejs.org/api/crypto.html
这块主要就是用来加密(签名)的,很简单:
const cypto = require("crypto");
let obj = cypto.createHash("md5");
// // PS:分多次提交也一样:
// obj.update("123");
// obj.update("456");
obj.update("123456");
// e10adc3949ba59abbe56e057f20f883e
console.log(obj.digest("hex"));
let obj2 = cypto.createHash("sha1");
obj2.update("123456");
// 7c4a8d09ca3762af61e59520943dc26494f8941b
console.log(obj2.digest("hex"));
let obj3 = cypto.createHash("sha256");
obj3.update("123456");
// 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
console.log(obj3.digest("hex"));
const os = require("os");
// cup核数
console.log(os.cpus().length);
// 输出我老电脑CPU详细信息
console.log(os.cpus());
2.8.多进程¶
可以参考我之前讲的Python多进程进行对比学习:https://www.cnblogs.com/dotnetcrazy/p/9363810.html
基础入门¶
node
const os = require("os");
const process = require("process");
const cluster = require("cluster");
// 主进程:分配任务
if (cluster.isMaster) {
console.log(`主进程PID:${process.pid}`);
for (let i = 0; i < os.cpus().length; i++) {
cluster.fork();
}
} else {
// 子进程执行任务
console.log(`当前进程PID:${process.pid},父进程PPID:${process.ppid}`);
}输出:
主进程PID:20680
当前进程PID:20620,父进程PPID:20680
当前进程PID:23340,父进程PPID:20680
当前进程PID:11644,父进程PPID:20680
当前进程PID:22144,父进程PPID:20680服务器的案例¶
node
const os = require("os");
const http = require("http");
const process = require("process");
const cluster = require("cluster");
// 主进程:分配任务
if (cluster.isMaster) {
console.log(`主进程PID:${process.pid}`);
for (let i = 0; i < os.cpus().length; i++) {
cluster.fork();
}
} else {
// 子进程执行任务
http.createServer((request, response) => {
console.log(`当前进程PID:${process.pid},父进程PPID:${process.ppid}`);
response.write("Fork Test");
response.end();
}).listen(8080, () => {
console.log(`服务器启动成功,当前端口:8080,进程PID:${process.pid}`);
});
}输出: 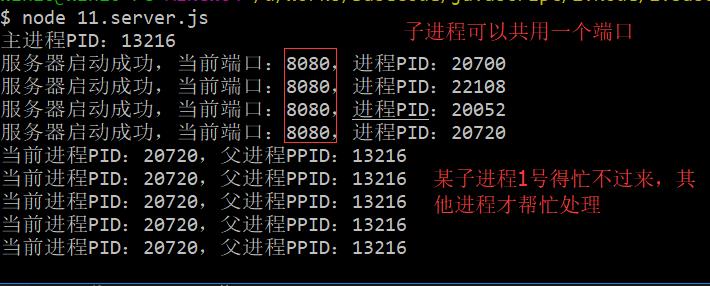
注意点¶
PS:NodeJS注意下面几地方:
- 子进程可以共用一个端口
- 并发的时候,如果不等到某个核的CPU100%,其他核的CPU就看戏(不工作)
2.9.uuid¶
这个是第三方模块,如果没安装:
cnpm initcnpm i uuid -D(开发环境) orcnpm i uuid -S(生产环境)
使用案例:
node
const uuid = require("uuid/v4");
let uid = uuid();
console.log(uid);输出:
65334387-110e-489a-b4c5-cb19cb3875d0以上是关于一文入门NodeJS的主要内容,如果未能解决你的问题,请参考以下文章