elasticsearch基本查询笔记(二)-- 分词查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch基本查询笔记(二)-- 分词查询相关的知识,希望对你有一定的参考价值。
参考技术A 首先了解一下什么是keyword,举个例子:建立一个索引test_index,将字段name设置为keyword类型。
然后查询该mapping是否已经构建成功。
得到如下结果:
表示已经创建成功。
在该索引test_index下建立数据:
使用term查询数据,name为“奥尼尔”:
得到结果:
接下来使用term查询数据,name为“奥尼”:
得到结果:
因为字段被设置成keyword类型,录入数据该字段是不会被分词,所以使用term查询时候,需要全匹配才能查询到。
更新test_index的mapping:
查看mapping:
添加数据:
然后我们查询school字段:
结果:
可以发现,即使没有输入完整的查询条件,也能将school为"hello world"的内容查询到。
如果我们完整查询:
结果:
完整输入结果查找不到。
因为text,会将字段进行分词,如“hello world”会被分词为["hello","world",...],而term必须匹配到数组中的一项,才能查出结果。
elastic会对查询语句进行分词
term 查询语句不分词
keyword字段不分词
term查询keyword字段,需要完全匹配
text字段分词
term查询text字段,必须为text字段分词后中的某一个才行。如“我真帅”分词为["我","真","帅"],term必须为“我”或“真”或“帅”,才能查到,而“我帅”、“真帅”不行。
match 查询语句分词
keyword字段不分词
match查询keyword字段,需要完全匹配
text字段分词
match查询text字段,只需要match分词结果中和text分词有匹配就可以查出。如“我真帅”分词为["我","真","帅"],match的查询语句“真帅”被分词为["真","帅"],其中“真”、“帅”能匹配上text字段的分词结果,所以能查出。
match_phrase 查询语句分词
keyword字段不分词
match_phrase 查询keyword字段,需要完全匹配
text字段分词
match_phrase 查询text字段,只需要match_phrase 分词结果中和text分词有匹配且查询语句必须包含在text分词结果中,同时顺序相同且连续,才可以查出。如“我真帅”分词为["我","真","帅",“真帅”],match_phrase 的查询语句“真帅”被分词为["真帅"],其中“真帅”能匹配上text字段的分词结果,连续且顺序相同,所以能查出。
ElasticSearch_03_ES的基本筛选条件
系列文章目录
文章目录
前言
一、基本语法使用
1.1 _search接口获取所有数据
_search这个GET类型的接口,不需要params和body,可以查询整个es所有的数据
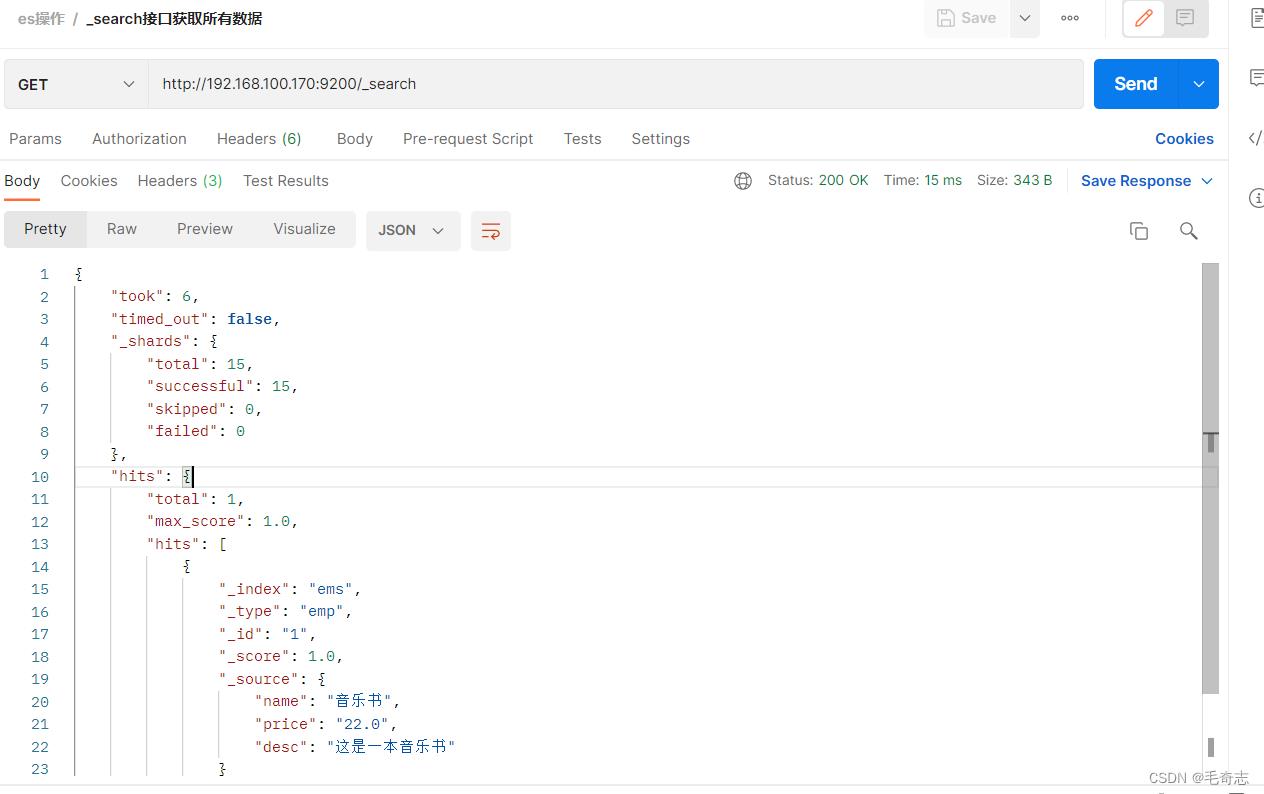
took:耗费了几毫秒
timed_out:是否超时,false是没有,默认无timeout
_shards:shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
hits 返回es存放的所有的数据
hits.total:本次搜索,返回了几条结果
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据,默认查询前10条数据,按_score降序排序
1.2 文档操作
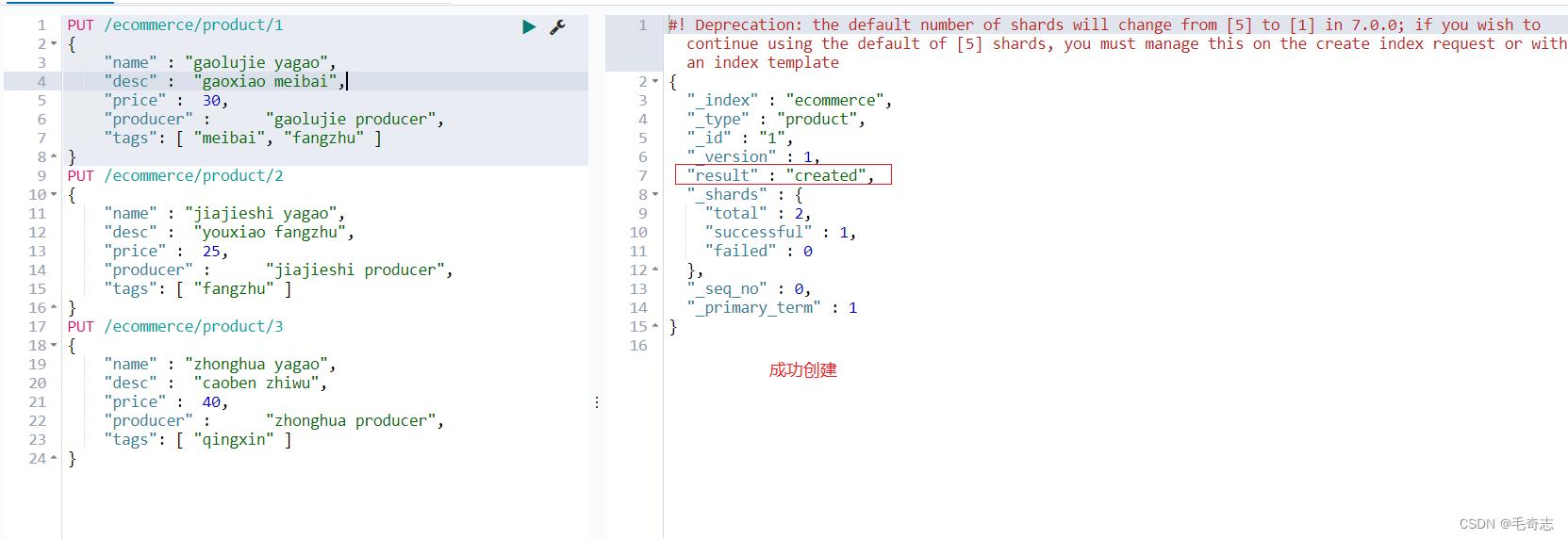
插入文档
PUT /ecommerce/product/1
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
PUT /ecommerce/product/2
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
PUT /ecommerce/product/3
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
PUT /ecommerce/product/1 表示的含义:ecommerce 电子商务是索引名称,product 产品是type类型名称,最后 1 表示序号
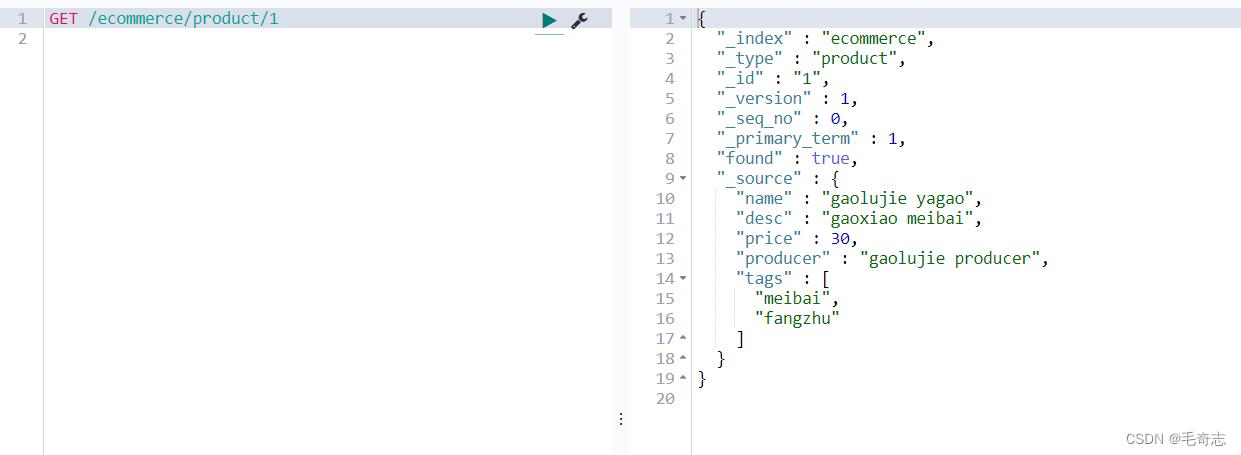
查询文档
GET /ecommerce/product/1
url 相同,只是 请求类型 改成了 GET,符合 restful 风格
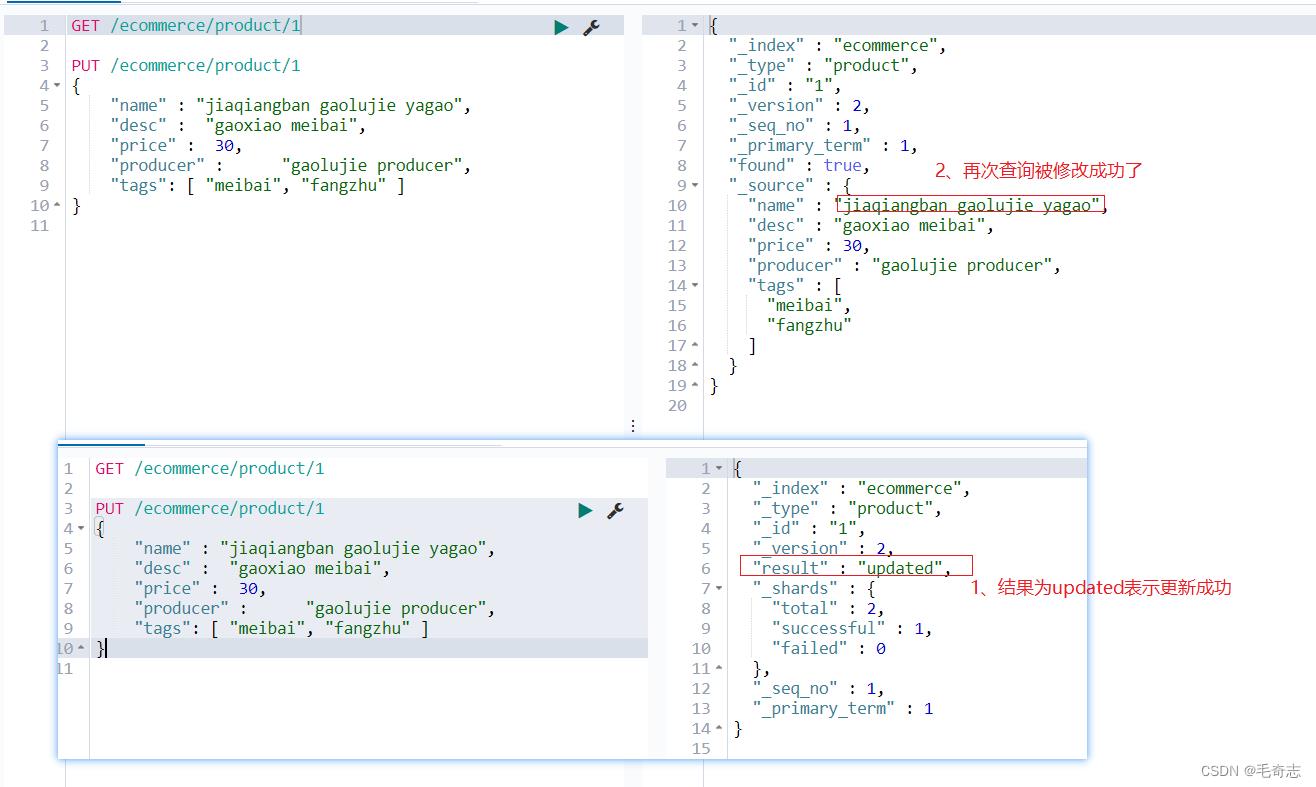
修改文档
PUT /ecommerce/product/1
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
url 相同,只是 请求类型 改成了 PUT,符合 restful 风格
修改文档底层原理:
- 修改本质是删除:es会将老的document标记为deleted(逻辑删除),然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除(物理删除)标记为deleted的document。
- 各个filed均替换(删除旧的,新建新的):document是不可变的,如果要修改document的内容,可以通过全量替换,直接对document重新建立索引,替换里面所有的内容。而且,替换必须带上所有的field,即使这个filed的值和之前相同,也要带上,否则其他数据会丢失。
查询所有的索引和查询所有的数据
GET _cat/indices?v&pretty
GET _search

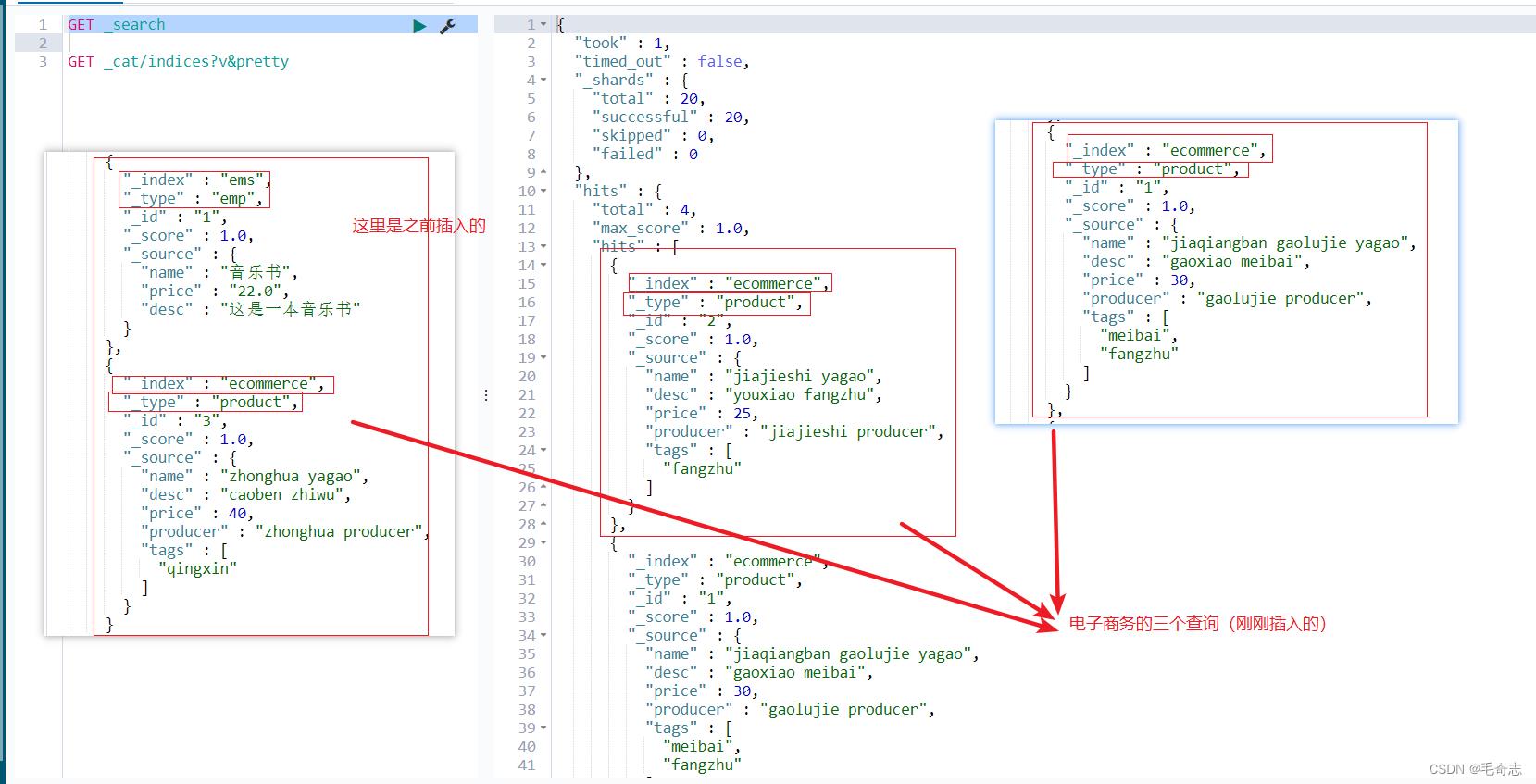
删除文档
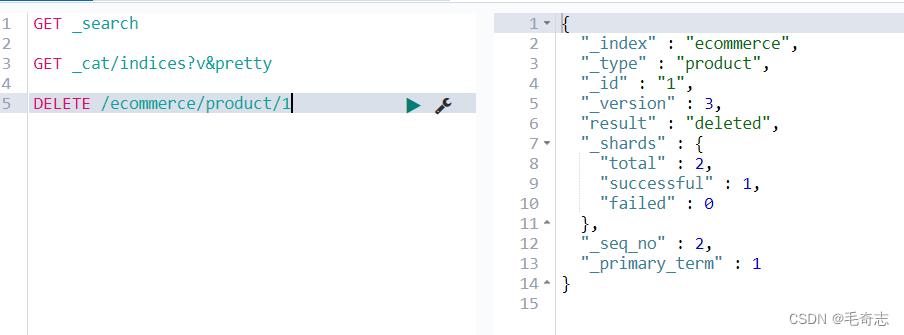
注意:在删除一个document之后,我们可以从侧面证明,它不是立即物理删除的,因为它的一些版本号等信息还是保留的。
删除之后,这里表示只剩下两个了,序号为1的没有了
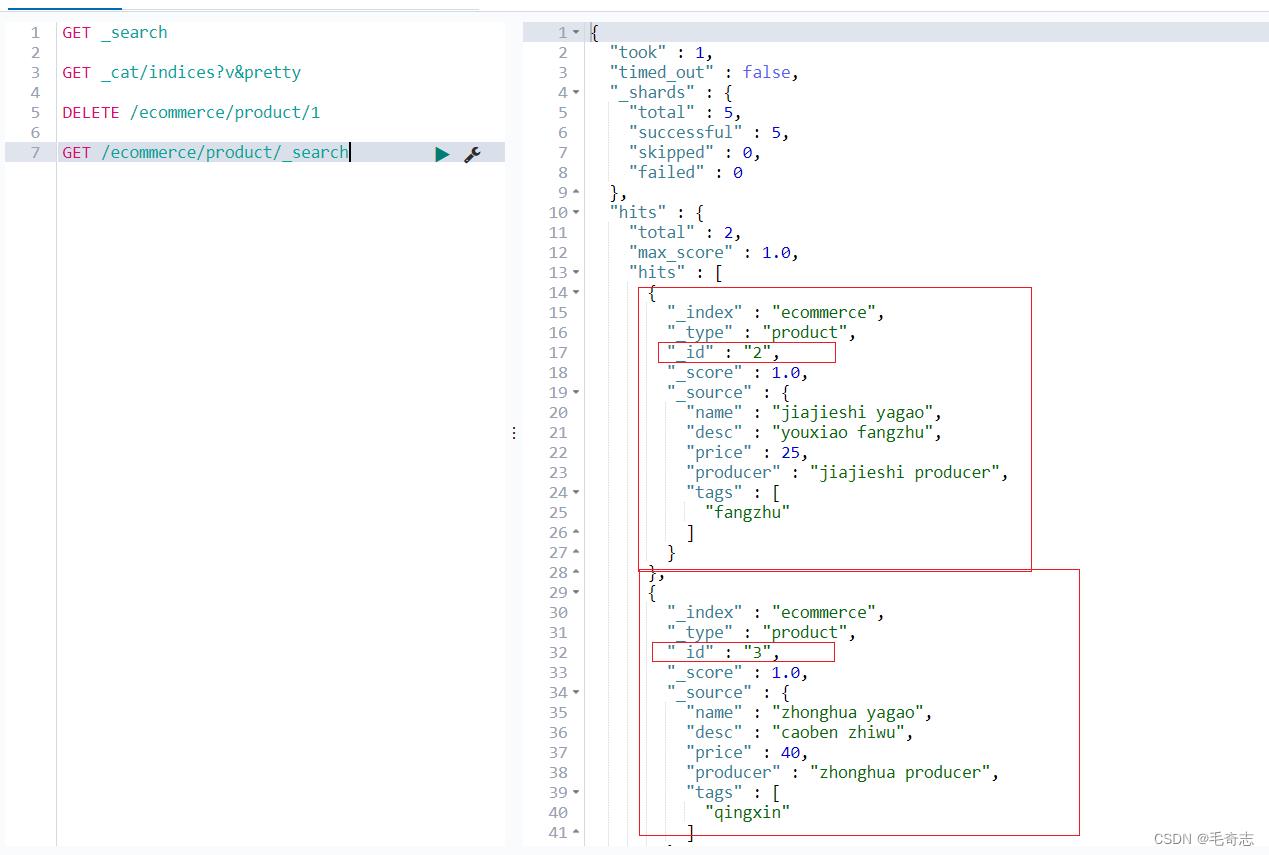
二、各种各样的查询条件
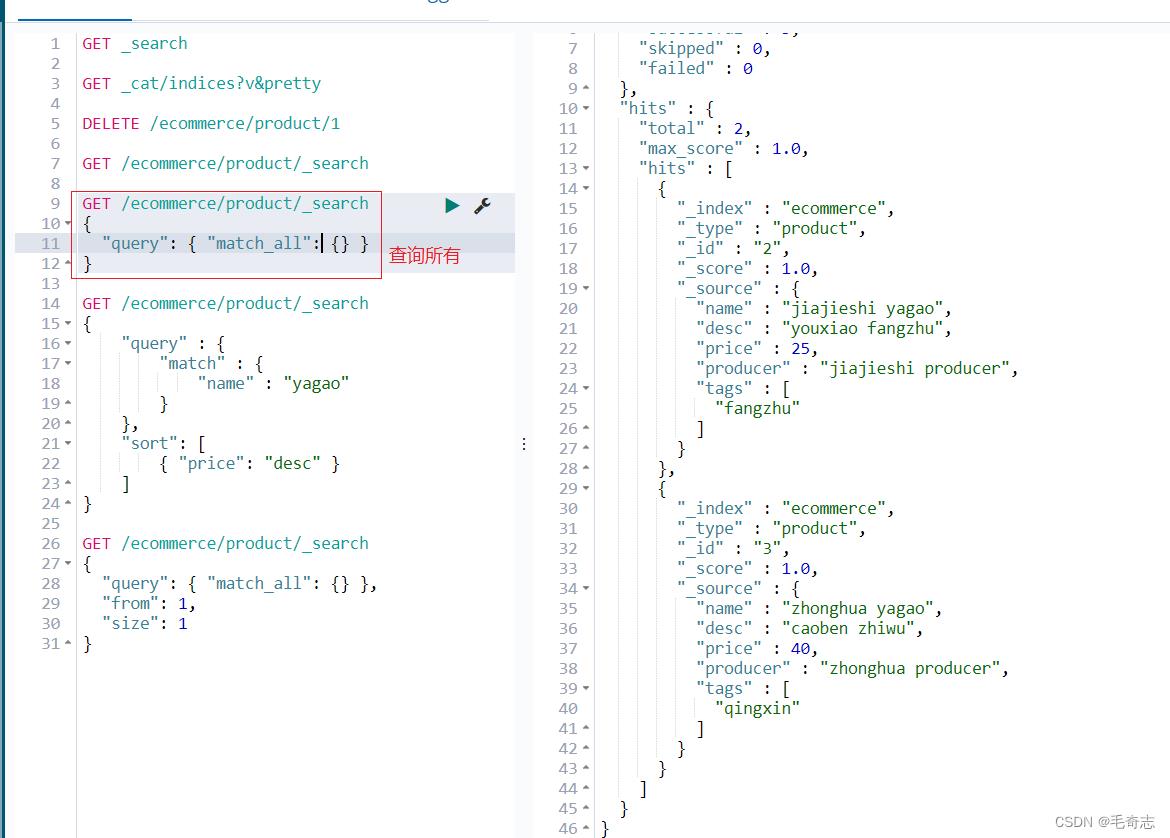
2.1 查询所有
GET /ecommerce/product/_search
"query": "match_all":
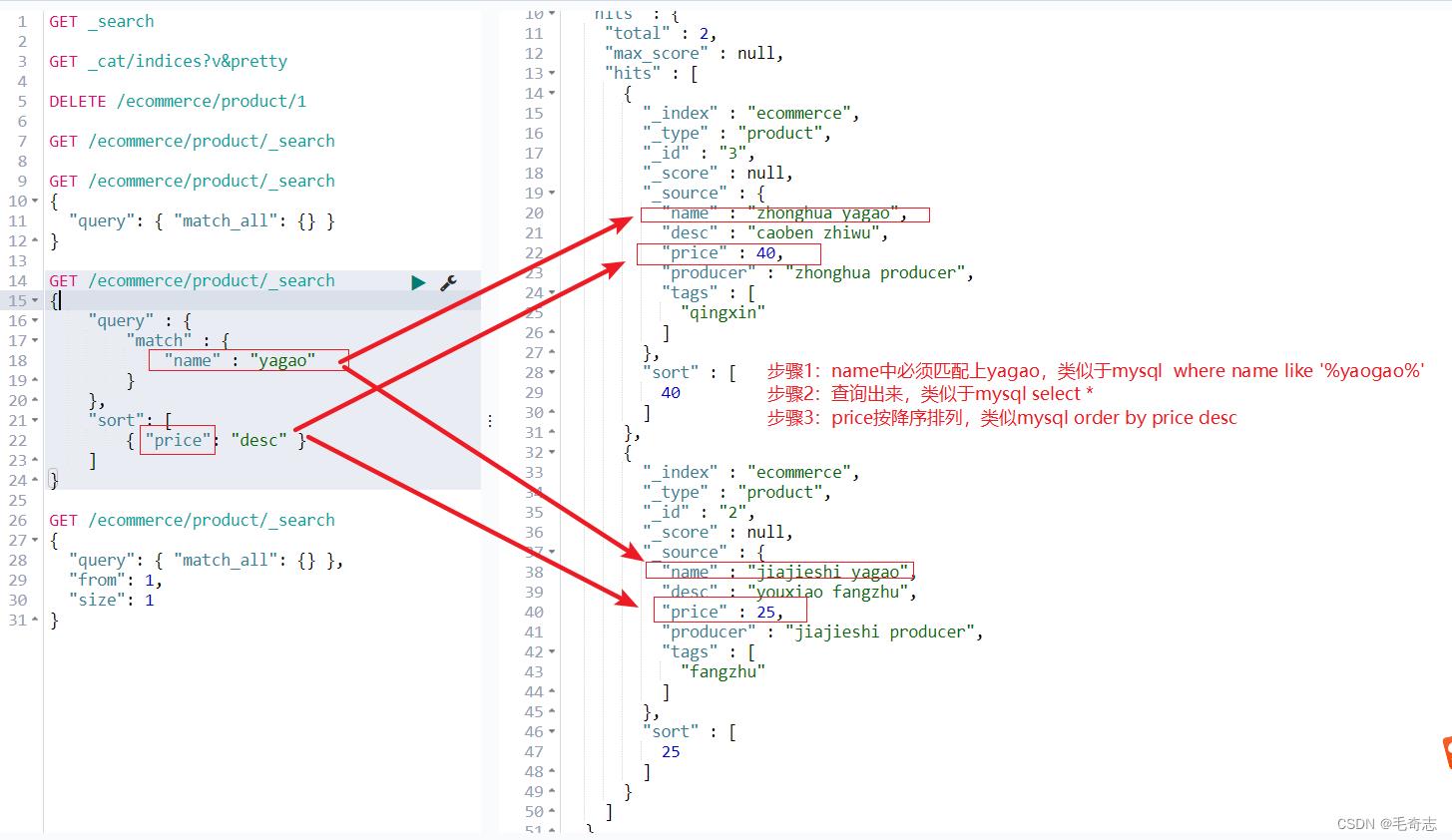
2.2 值匹配和输出结构按price倒序输出
GET /ecommerce/product/_search
"query" :
"match" :
"name" : "yagao"
,
"sort": [
"price": "desc"
]
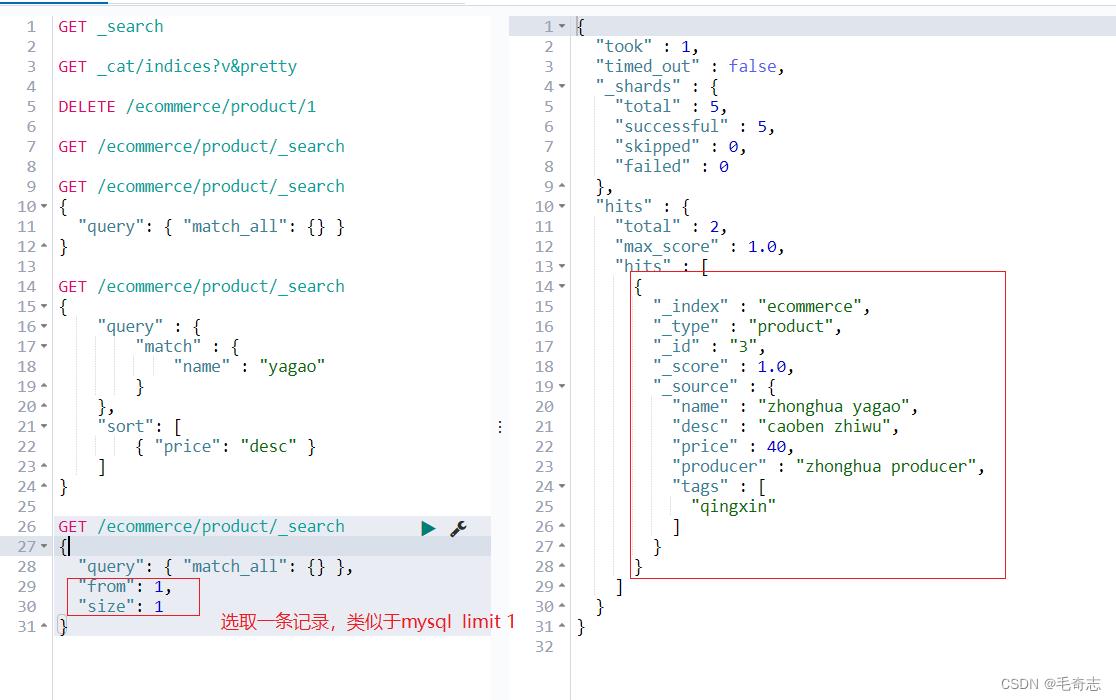
2.3 仅输出需要的数量
GET /ecommerce/product/_search
"query": "match_all": ,
"from": 1,
"size": 1
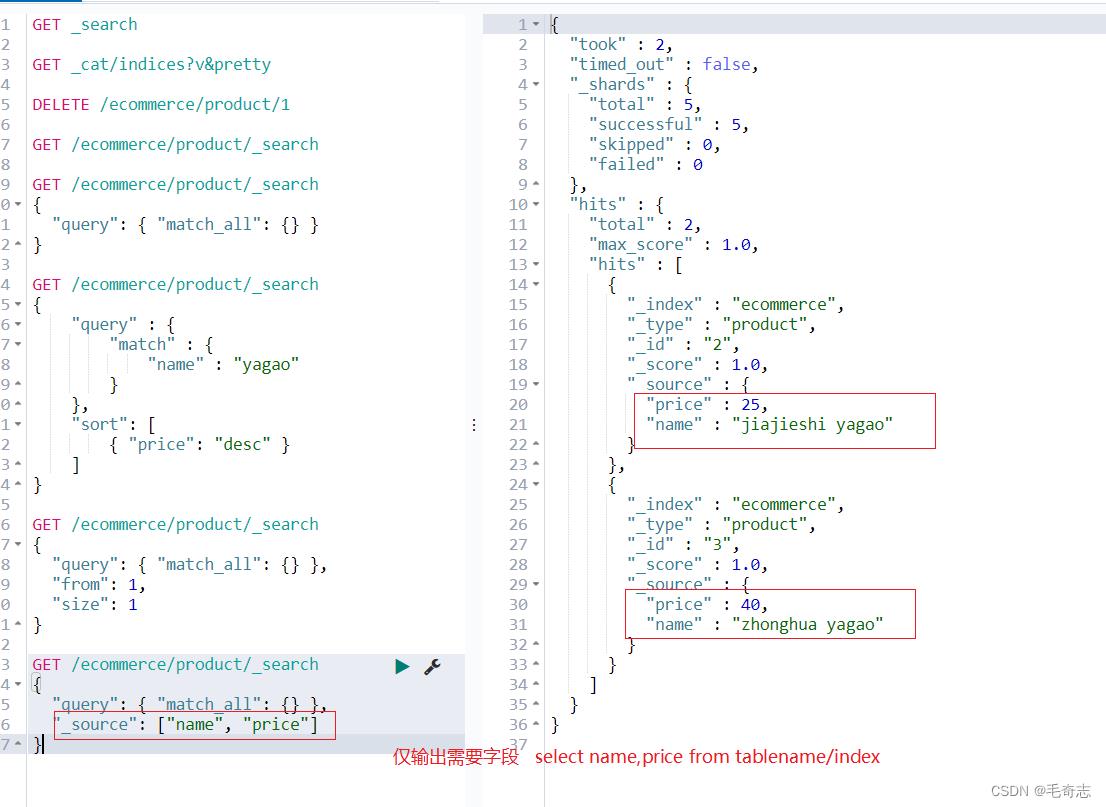
2.4 仅输出需要的字段
GET /ecommerce/product/_search
"query": "match_all": ,
"_source": ["name", "price"]
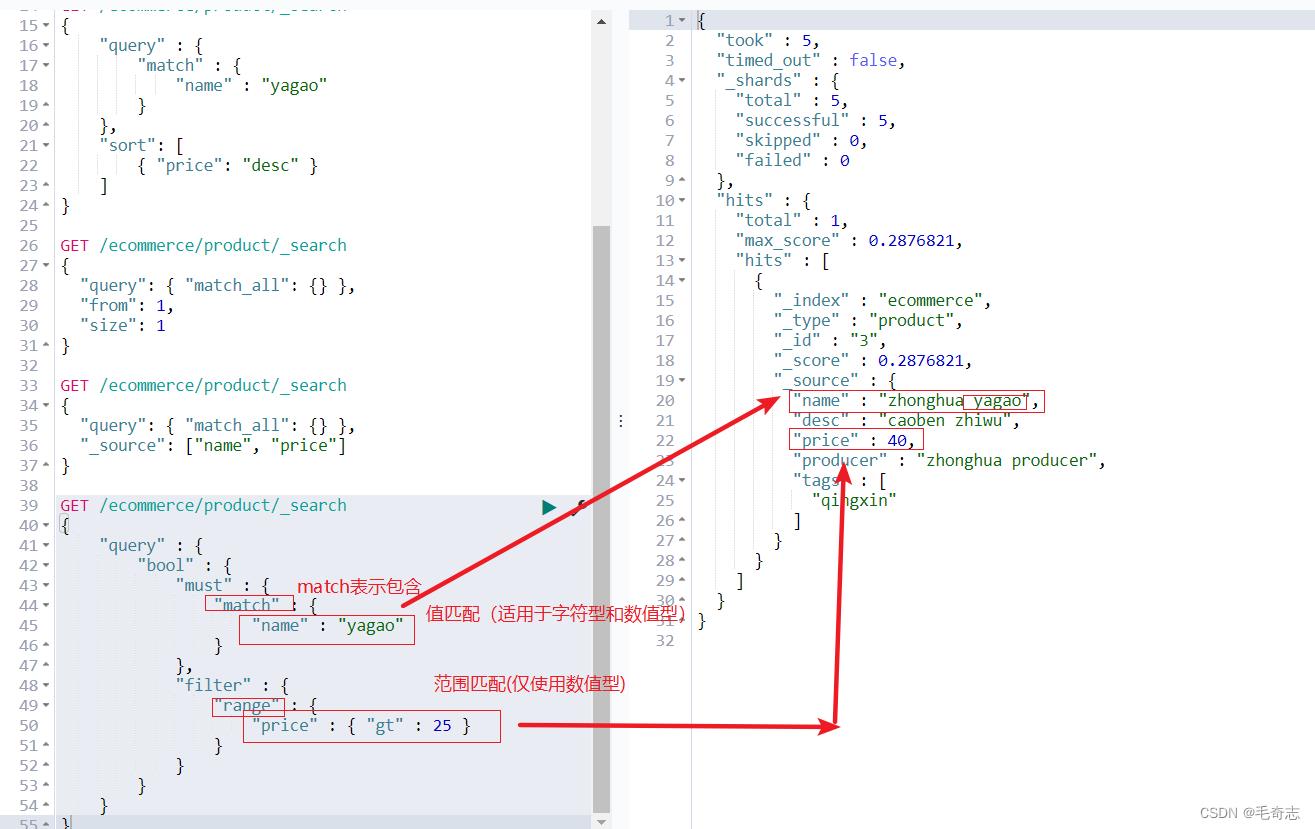
2.5 值匹配和范围匹配
GET /ecommerce/product/_search
"query" :
"bool" :
"must" :
"match" :
"name" : "yagao"
,
"filter" :
"range" :
"price" : "gt" : 25
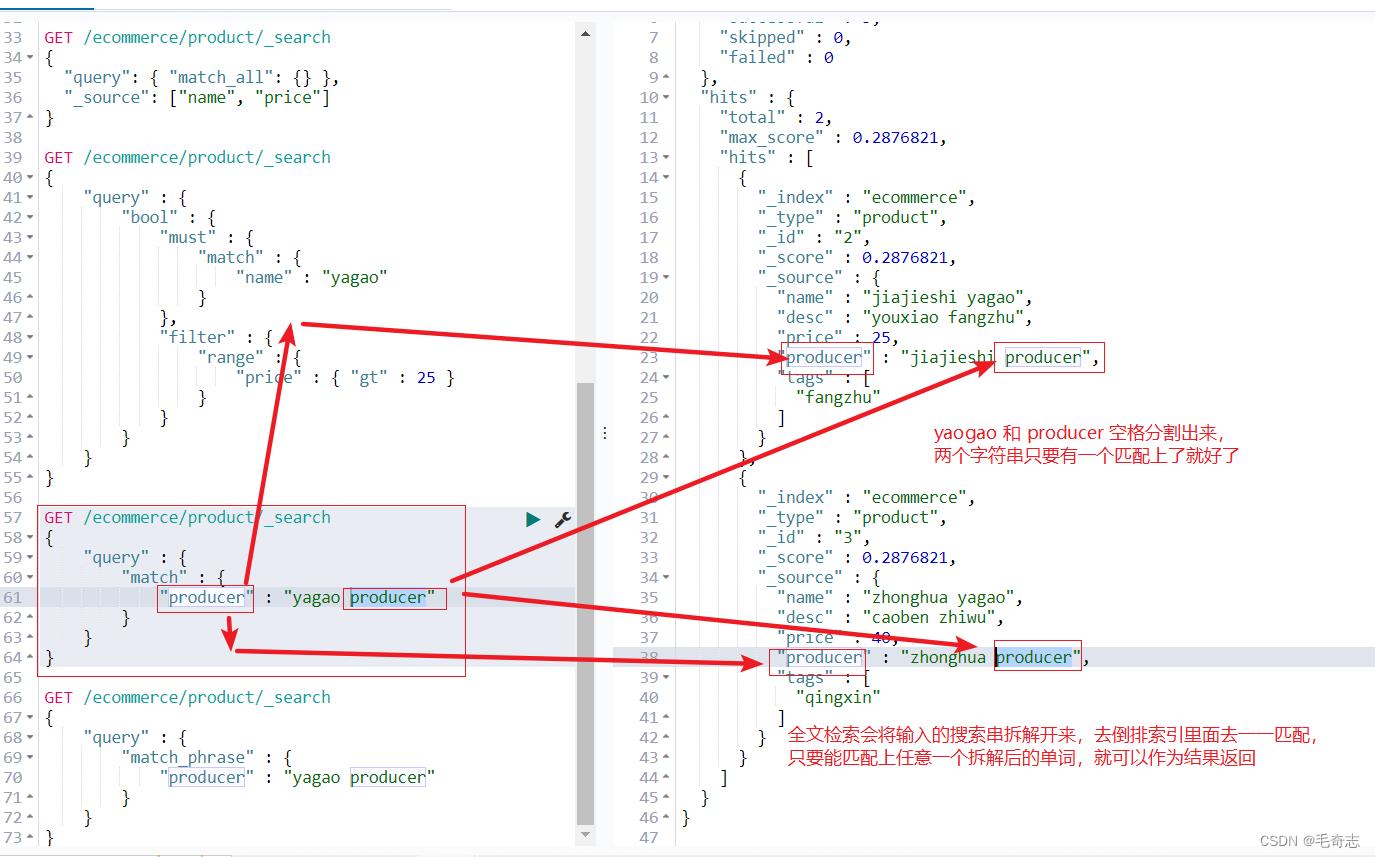
2.6 match表示空格分词中任意一个匹配
1、全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
2、phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
GET /ecommerce/product/_search
"query" :
"match" :
"producer" : "yagao producer"
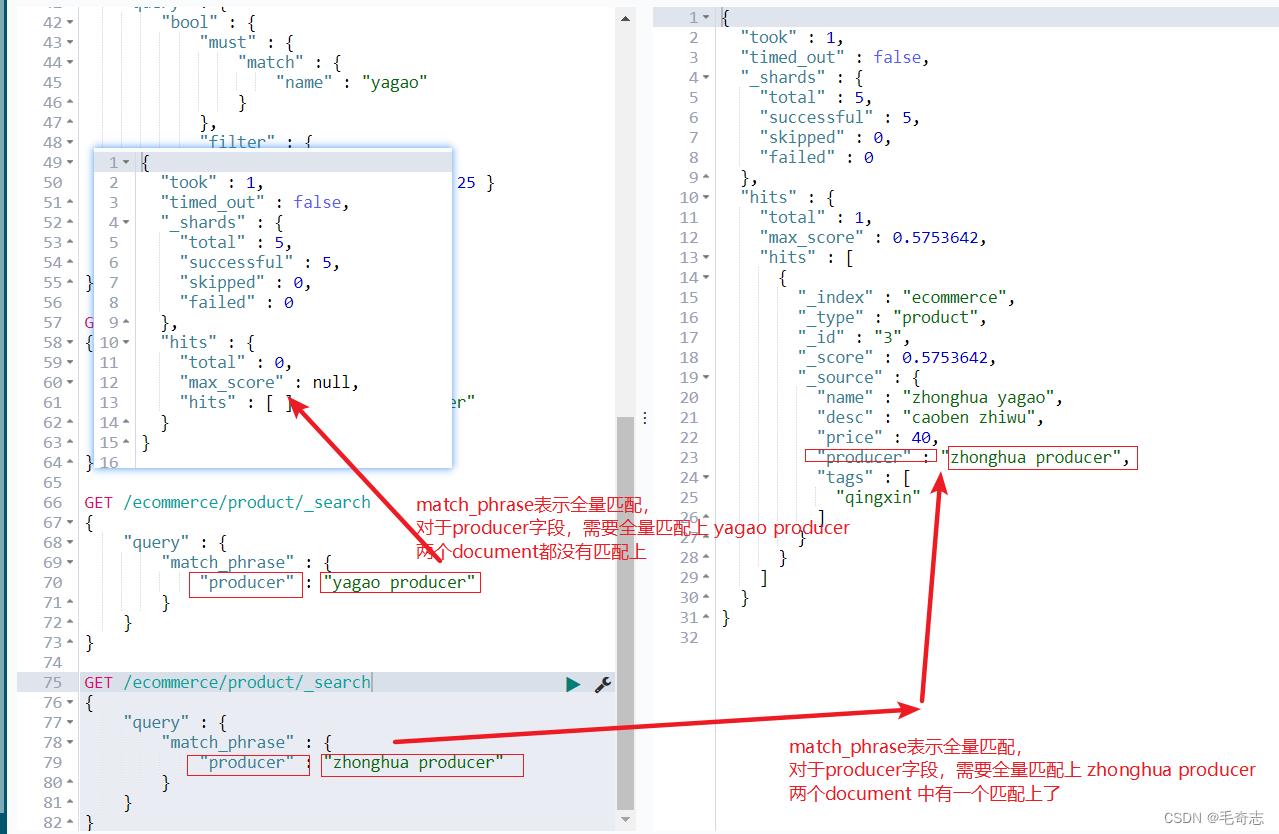
2.7 match_phrase表示整个字符串完全匹配上
GET /ecommerce/product/_search
"query" :
"match_phrase" :
"producer" : "yagao producer"
GET /ecommerce/product/_search
"query" :
"match_phrase" :
"producer" : "zhonghua producer"
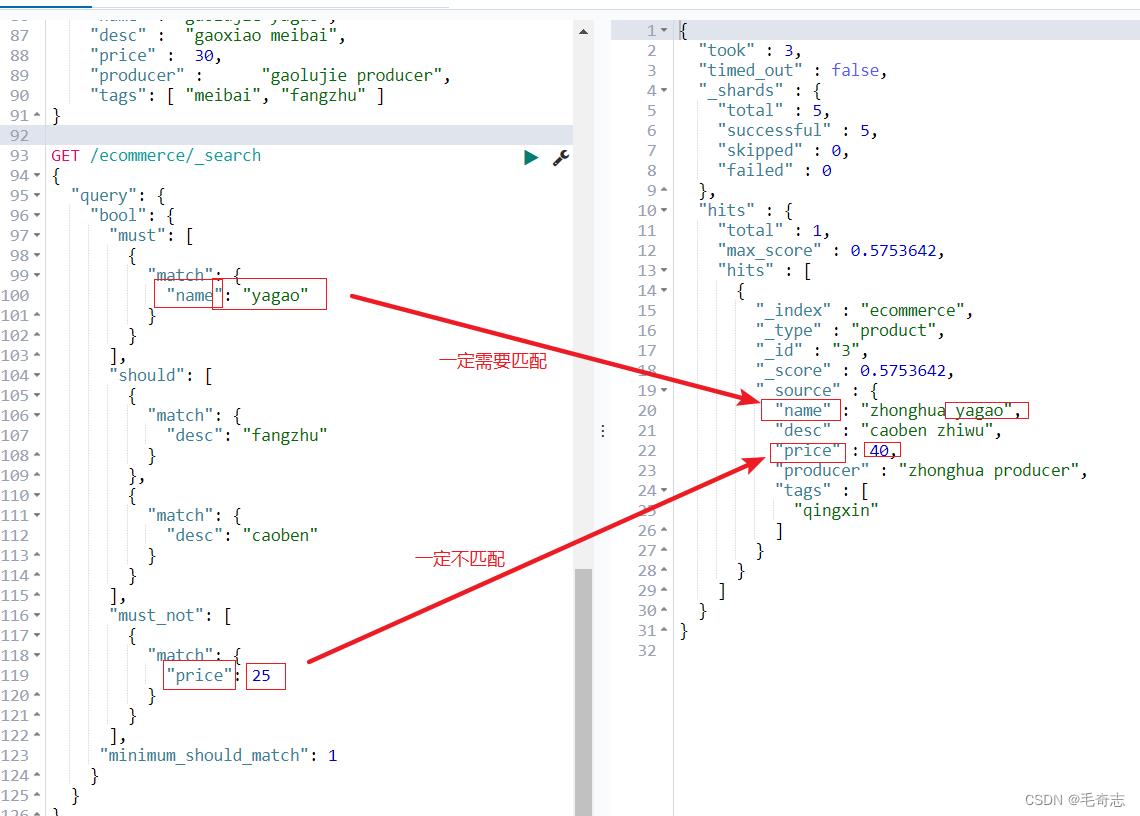
2.8 三种匹配强度must should must_not
GET /ecommerce/_search
"query":
"bool":
"must": [
"match":
"name": "yagao"
],
"should": [
"match":
"desc": "fangzhu"
,
"match":
"desc": "caoben"
],
"must_not": [
"match":
"price": 25
],
"minimum_should_match": 1
总结
对比学习法一种很快的学习方法,es的查询语句可以对比mysql的来学习
倒序输出,类似mysql的 order by xxx desc
限制输出数量,类似mysql的 limit xxx
仅输出需要的字段,类似mysql的 select filed1,filed2
值匹配和范围匹配,类似mysql的 where filed = xxx and num_bak > xxx
分词匹配 match
全值匹配 match_phrase
三个匹配强度 must should must not
以上是关于elasticsearch基本查询笔记(二)-- 分词查询的主要内容,如果未能解决你的问题,请参考以下文章