在mysql数据库中如何让某个字段有重复的只取一条
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在mysql数据库中如何让某个字段有重复的只取一条相关的知识,希望对你有一定的参考价值。
表table_a 有4条数据
id A B C D
01 ab 1a2 1b2 121
02 ab 2a3 3b3 4a1
03 ac 1a2 1b2 121
04 ac 2a4 3b2 52g
如何让A字段有重复的只取一条 比如
01 ab 1a2 1b2 121
03 ac 1a2 1b2 121
实现的方法和详细的操作步骤如下:
1、第一步,使用navicat连接到mysql数据库并创建一个新的用户表,见下图,转到下面的步骤。
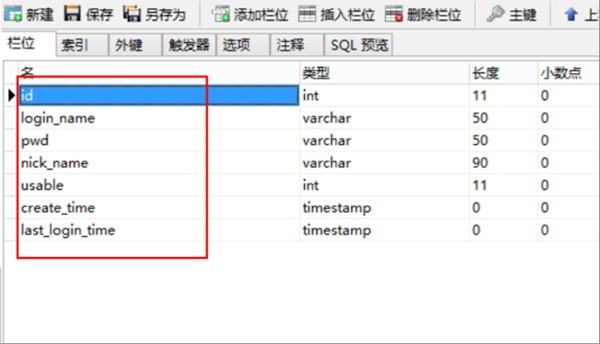
2、第二步,完成上述步骤后,填写一些测试内容以演示测试结果,见下图,转到下面的步骤。
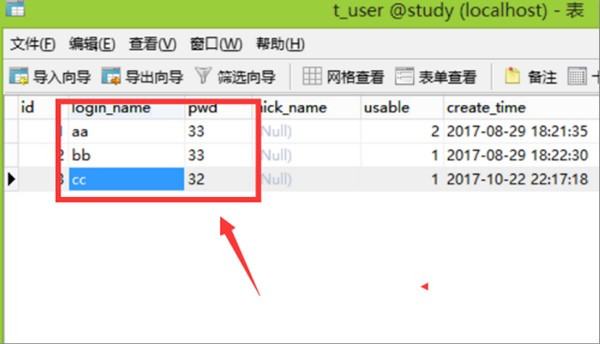
3、第三步,完成上述步骤后,选择用户名,然后单击鼠标右键以选择“设计表”选项,见下图,转到下面的步骤。
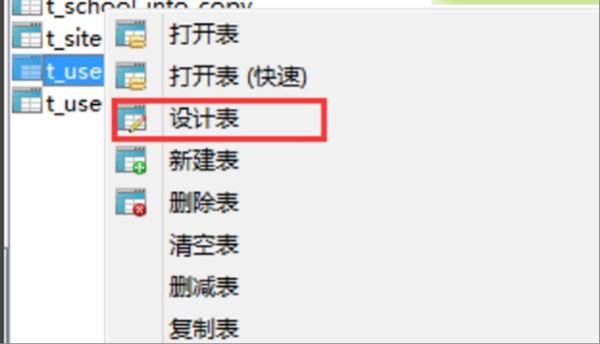
4、第四步,完成上述步骤后,切换到设计表中的“索引”标签,见下图,转到下面的步骤。
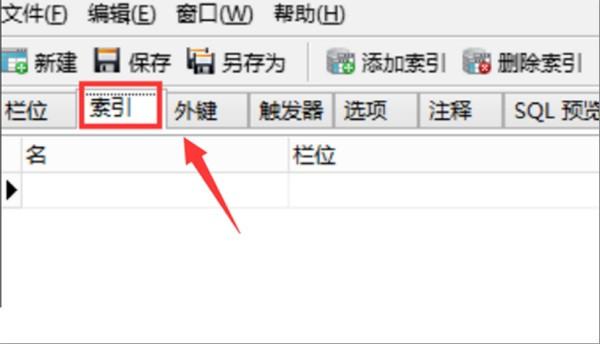
5、第五步,完成上述步骤后,开始添加索引。如果不需要索引名称,则默认情况下可以为空。该工具将自动生成与字段名称相同的名称。单击字段后面的按钮以显示选择框,选择需要唯一约束的字段。在这里,登录到名称字段,见下图,转到下面的步骤。
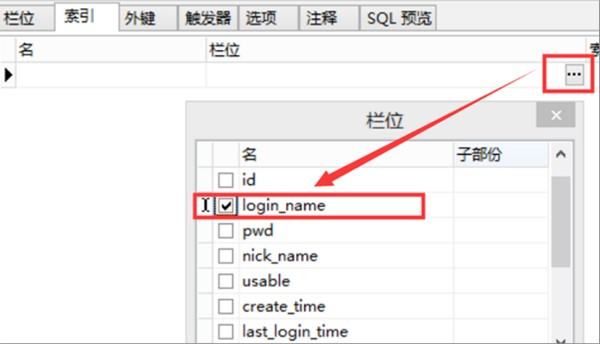
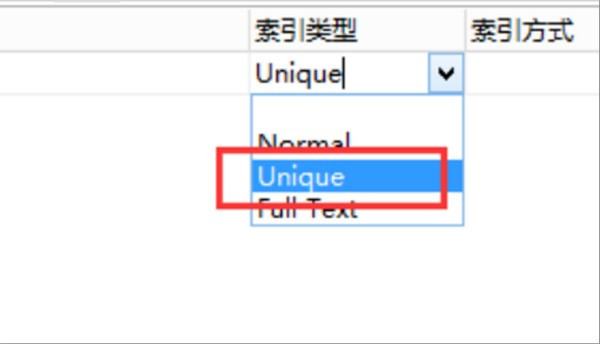
6、第六步,完成上述步骤后,选择“索引类型”选项,唯一约束必须选择“Unique”类型,见下图,转到下面的步骤。
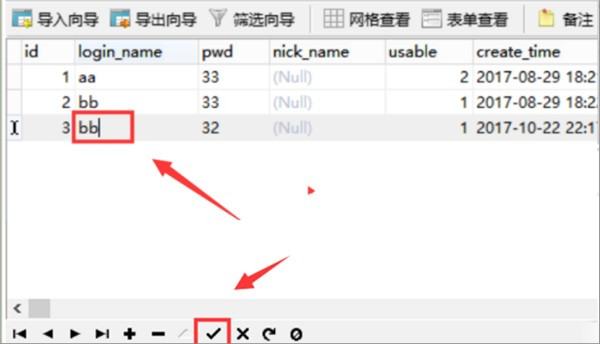
7、第七步,完成上述步骤后,将第三条数据的登录名修改为与第二条数据相同,然后单击下面的复选标记按钮进行保存,见下图,转到下面的步骤。
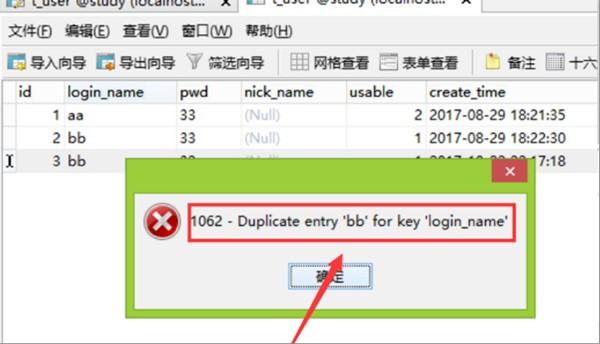
8、第八步,完成上述步骤后,保存时将报告错误,提示“Duplicate entry 'bb' for key 'login_name'”,重复的登录名无法成功保存,表明添加的唯一约束已生效,见下图。这样,就解决了这个问题了。
select *
from table_a a
where not exists (
select 1 from table_a b
where b.A = a.A
and b.id < a.id
) 参考技术B select * from table_a where id in (select min(id) from table_a group by a) 参考技术C 我知道oracle有个row_number()函数可以实现某个字段排序,然后取重复的一条,下面的博客链接是mysql实现oracle的row_number()函数功能,看看有没有启发吧。
http://1055592535.iteye.com/blog/1679470 参考技术D 可以试试distinct
一条SQL删除重复记录,重复的只保留一条
情景:
我们的数据库中可能会存在很多因各种原因而重复的记录,我们需要对这些重复的记录进行删除,每组组重复的记录只保留一条就行
例如我们有这么个表:两个框框都是有重复记录的,红框和绿框都只需要留下一条,其他的都干掉。
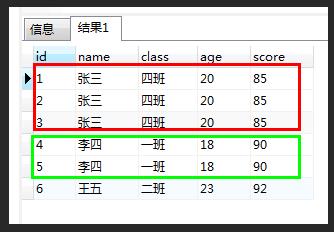
前提:
1:每天记录都要有一个唯一id
2:每组重复的记录要有字段能进行分组,例如上面我们按name、class、age、score相同的就是一组。
数据宝贵,请先备份!!!
数据宝贵,请先备份!!!
数据宝贵,请先备份!!!
放上整条SQL:
DELETE FROM "t_hw_test_del" t3 WHERE 1 = 1 AND EXISTS ( SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL AND t1."id" = t3."id" )
按步分析:
1:找到我们需要的记录,因为我们可能只是要处理某天的记录,所以要先筛选一下,我这里用1=1来代替
SELECT * FROM "t_hw_test_del" WHERE 1 = 1
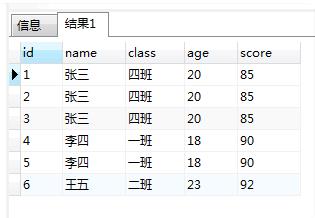
SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score"
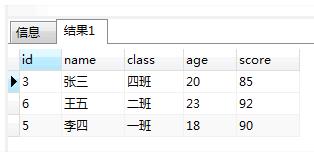
3:用我们找到的需要处理的记录和要保留的记录关联起来, 用分组字段和唯一id关联,左联
SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score"
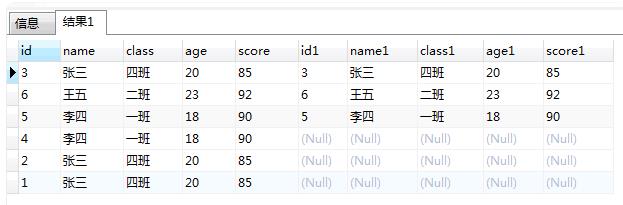
4:右表为null的记录,对应的左表记录就是我们要删掉的,加个条件右表为null
SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL
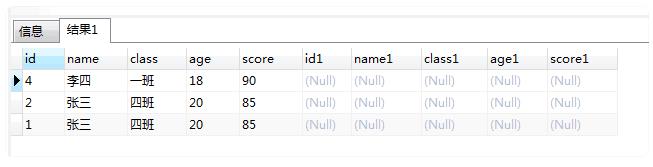
5: 用我们原来的记录id在我们不需要的记录里面找,如果这条记录在我们不需要的记录集里,那这条记录就可以删除
DELETE FROM "t_hw_test_del" t3 WHERE 1 = 1 AND EXISTS ( SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL AND t1."id" = t3."id" )
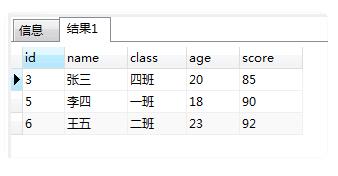
6: 检查一下结果符不符合我们的要求
SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1
以上是关于在mysql数据库中如何让某个字段有重复的只取一条的主要内容,如果未能解决你的问题,请参考以下文章