RabbitMQ消息过滤的一个思路
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ消息过滤的一个思路相关的知识,希望对你有一定的参考价值。
参考技术A生产者 Producer 向 一个 队列发送消息,并且为消息打上不同的 Tag。假设这个队列有 3 个消费者:Consumer #[1:3],Consumer #1 只想消费 tag1 标记的消息,Consumer #2 只想消费 tag2 标记的消息,Consumer #3 只想消费 tag3 标记的消息。
生产者 publish 消息时,将 Tag 保存在 Map<String, Object> 类型的 header 字段,作为构建 AMQP.BasicProperties 参数
消费者如何告知 Broker 只消费特定 Tag?
假设 Consumer #1 只希望消费带 tag1 标记的消息,那么 Consumer #1 可以在向 Broker 请求 Basic.Consume 指令时,捎带自己期望的 Tag 字符串。Client 在具体生成 consumerTag 时可以用 Tag 关键字加上随机字符串(避免 consumerTag 重复):
消费者通过 Basic.Consume 指令来监听队列的消息,这些消费者信息服务端是如何存储的?
保存在队列主进程(Pid)的 state 中(具体调试可以通过 sys:get_state(Pid) )
并且队列进程在初始化时,会进行 consumers 初始化:
consumers 字段实际由 priority_queue:new() 初始化。当有新的 consumer 注册到队列进程,那么会调用 rabbit_queue_consumers 模块的 add_consumer 方法来向 priority_queue 添加一个元素;同理当有 consumer下线时,最终也会调用该模块的 remove_consumer 方法。 priority_queue 完整实现见 附二
Broker 向 Consumer 投递消息时,底层是通过 rabbit_amqqueue_process 调用 rabbit_queue_consumers 模块的 deliver 方法。默认采用
从 priority_queue 中获取一个 QEntry( ChPid, Consumer ),然后通过 FetchFun 从队列中获取消息,发送到 ChPid(Channel 进程)
在 consumers 不为空的情况下,通过 FetchFun 获取消息,此时可以获取该消息的 header,取出 Tag 值(如果消息打了 Tag 标记),然后通过 priority_queue 的 filter/2 方法
在 Pred 实现中,我们可以判断当前消息 Tag 值是否被包含在 consumerTag 中,从而可以过滤出消费特定 tag 的consumers,最后向这些 consumers 中的一个发送 Message 消息。
附一 (队列进程 state 中的 consumers 信息例子)
附二 (priority_queue 模块实现
rabbit_common )
注 :上述思路建议在测试环境测试,考虑到有可能出现的性能问题,作为一个调研也会有很多工作要做,整个过程会涉及 RabbitMQ 服务端源码改造、编译、打包( rabbitmq-public-umbrella )以及客户端的相关改造,如果能实际尝试下,也会有不小的收获。
Rabbitmq的简单概述和源码部署
一、 RabbitMQ概述
1.1 基本概述
RabbitMQ是一种消息中间件,能够很好的处理来自客户端的异步消息发送及请求,将消息发送放入到服
务端的队列池中,而接收端可以根据RabbitMQ配置的转发机制接收和过滤服务端转发来的消息。RabbitMQ
可以根据指定的消息转发规则进行消息的转发、缓冲和持久化操作,RabbitMQ主要用在多服务器间或单
服务器的子系统间进行通信,是分布式系统标准的配置。
同时它支持多个消息传递协议。RabbitMQ可以部署在分布式配置中,以满足高弹性、高可用性需求。
1.2 基本原理
http://www.rabbitmq.com/getstarted.html
队列、生产者、消费者
队列是RabbitMQ的内部对象,用于存储消息。生产者(下图中的P)生产消息并投递到队列中,消费者
(下图中的C)可以从队列中获取消息并消费。
In the diagram below, "P" is our producer and "C" is our consumer. The box in the middle is a
queue - a message buffer that RabbitMQ keeps on behalf of the consumer.

Work Queues
多个消费者可以订阅同一个队列在这种模式下,RabbitMQ会默认把P发的消息依次分发给各个消费者
(C),跟负载均衡差不多,而不是每个消费者都收到所有的消息并处理

Exchange、Binding
刚才我们看到生产者将消息投递到队列中,实际上这在RabbitMQ中这种事情永远都不会发生。实际的情
况是,生产者将消息发送到Exchange(交换器,下图中的X),再通过Binding将Exchange与Queue关联起来。

Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
Exchange Type、Bingding key、routing key
在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key。在绑定多个Queue
到同一个Exchange的时候,这些Binding允许使用相同的binding key。
生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则,
生产者就可以在发送消息给Exchange时,通过指定routing key来决定消息流向哪里。
RabbitMQ常用的Exchange Type有四种:fanout、direct、topic、headers
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
headers: 通过headers 来决定把消息发给哪些queue (一般不用)
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
二、 基础环境安装
安装rabbitmq需依赖erlang环境
2.1 基础编译说明
安装包说明:
mq: rabbitmq-server-generic-unix-3.7.7.tar.xz
erlang: otp_src_20.3.tar.gz
Below is the list of dependencies of RabbitMQ server as of 3.7.x:
erlang >= 19.3. Erlang can installed from a number of repositories
erlang源码下载地址:
http://erlang.org/download/otp_src_20.3.tar.gz
2.2 erlang编译安装
2.2.1 安装基础依赖编译环境
yum -y install gcc gcc-c++ m4 ncurses-devel openssl-devel unixODBC unixODBC-devel
2.2.2 编译安装erlang
cd otp_src_20.3
./configure --prefix=/usr/local/erlang
--with-ssl
--enable-threads
--enable-kernel-poll
--enable-hipe
make && make install
2.2.3 加入环境变量
vim /etc/profile
PATH=$PATH: /usr/local/erlang/bin
export $PATH
source /etc/profile
三、 安装配置RabbitMQ
3.1 创建运行账户
useradd rabbitmq
passwd rabbitmq
3.2 安装RabbitMQ
下载地址
tar -xJf rabbitmq-server-generic-unix-3.7.7.tar.xz
将安装包部署到/opt目录
mv rabbitmq_server-3.7.7 /opt/ rabbitmq
加入全局系统环境变量,也可以加入应用账户自己的环境变量中
vim /etc/profile
PATH=$PATH: /usr/local/erlang/bin: /opt/ rabbitmq/sbin
export $PATH
source /etc/profile
3.3 配置RabbitMQ
http://www.rabbitmq.com/admin-guide.html # 所有配置指导
http://www.rabbitmq.com/documentation.html #所有配置文档
http://www.rabbitmq.com/configure.html#configuration-files #官方配置说明
默认rabbitmq没有提供配置文件,自行创建
配置信息的配置文件: /opt/rabbitmq/etc/rabbitmq/rabbitmq.conf
环境变量的配置文件: /opt/rabbitmq/etc/rabbitmq/rabbitmq-env.conf
配置模板下载: https://github.com/rabbitmq/rabbitmq-server/tree/master/docs
3.3.1 创建数据存储和日志存放路径
默认的数据存储路径和日志路径在/opt/rabbitmq/var下,我已经删除了,自行定义
注意:服务器设置为以系统用户rabbitmq运行 。如果更改节点数据库或日志的位置,则必须确保文件由该用户所有
创建独立配置数据存储和日志存放路径
mkdir /opt/rabbitmq/{data,logs}
定义/opt/rabbitmq/etc/rabbitmq/rabbitmq-env.conf环境变量,rabbitmq启动时从配置中读取路径参数
不依赖系统自定义变量
RABBITMQ_NODENAME=rabbit_node1 #自行定义
RABBITMQ_HOME=/opt/rabbitmq
RABBITMQ_CONFIG_FILE=${RABBITMQ_HOME}/etc/rabbitmq/rabbitmq
RABBITMQ_LOG_BASE=${RABBITMQ_HOME}/logs
RABBITMQ_MNESIA_BASE=${RABBITMQ_HOME}/data/mnesia
RABBITMQ_ENABLED_PLUGINS_FILE=${RABBITMQ_HOME}/etc/rabbitmq/enabled_plugins
RABBITMQ_GENERATED_CONFIG_DIR=${RABBITMQ_HOME}/data/config
RABBITMQ_ADVANCED_CONFIG_FILE=${RABBITMQ_HOME}/etc/rabbitmq/advanced
RABBITMQ_SCHEMA_DIR=${RABBITMQ_HOME}/data/schema
RABBITMQ_PLUGINS_DIR=${RABBITMQ_HOME}/plugins
RABBITMQ_PID_FILE=${RABBITMQ_HOME}/logs/rabbitmq.pid
3.3.2 修改配置调整参数
参考 http://www.rabbitmq.com/production-checklist.html
修改/opt/rabbitmq/etc/rabbitmq/rabbitmq.conf
num_acceptors.tcp = 15
接受TCP侦听器连接的Erlang进程数。Default: 10,根据业务自行调整
reverse_dns_lookups = false 关闭dns反向解析,默认true
#资源限制和流控
如果没有足够的空闲系统内存,将会对操作系统交换造成不利影响,甚至会导致RabbitMQ进程终止
vm_memory_high_watermark.relative = 0.6
#The recommended vm_memory_high_watermark range is 0.40 to 0.66
#Values above 0.7 are not recommended. The OS and file system must be left with at least 30% of the
#memory, otherwise performance may degrade severely due to paging
tcp_listen_options.backlog = 1024 默认128, tcp侦听队列根据并发量自行调整
#日志配置
log.dir = /opt/rabbitmq/logs
log.file = rabbit.log
log.file.level = info
#其他调优参数根据并发量自行调整,没有特殊要求默认参数即可
3.3.3 打开文件句柄设置
Make sure your environment allows for at least 50K open file descriptors for effective
RabbitMQ user, including in development environments.
# vim /etc/security/limits.conf
rabbitmq soft nofile 65535
rabbitmq hard nofile 65535
3.3.4 RabbitMQ启动与停止
启动rabbitmq:rabbitmq-server start
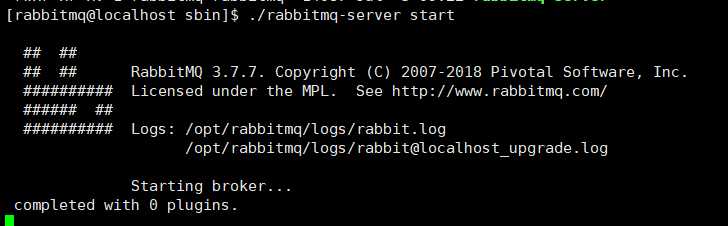
关闭rabbitmq: rabbitmqctl stop

需要注意的是,此时不仅关闭了Rabbit应用程序,同时也关闭了Erlang节点。有时候我们只想关闭
Rabbit 应用程序,而保留Erlang节点继续为其它程序服务(特别是在集群或分布式环境中,一个Erlang
节点上可能同时运行着其它的Erlang程序,所以这样的关闭节点是不可取的)
我们只需要使用./rabbitmqctl stop_app即可只关闭运行着的Rabbit程序,如下:


RabbitMQ后台运行

3.3.5 用户管理
删除默认用户(安全原因)
rabbitmqctl delete_user guest

创建业务连接账户
语法: rabbitmqctl add_user Username Password

修改用户的密码
语法: rabbitmqctl change_password Username Newpassword

查看用户

3.3.6 角色管理
在RabbitMQ中,角色致分为超级管理员、监控者、策略制定者、普通管理者以及其他
http://www.rabbitmq.com/management.html #官方文档
(1) 超级管理员(administrator)
可登陆管理控制台(启用managementplugin的情况下),可查看所有的信息,并且可以对用户,策
略(policy)进行操作。
(2) 监控者(monitoring)
可登陆管理控制台(启用managementplugin的情况下),同时可以查看rabbitmq节点的相关信息(进
程数,内存使用情况,磁盘使用情况等)
(3) 策略制定者(policymaker)
可登陆管理控制台(启用managementplugin的情况下),同时可以对policy进行管理。但无法查看
节点的相关信息
(4) 普通管理者(management)
仅可登陆管理控制台(启用managementplugin的情况下),无法看到节点信息,也无法对策略进行
管理。
(5) 其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
设置用户角色
语法:rabbitmqctl set_user_tags Username administrator
操作前paytest用户未被指定角色
操作后paytest角色
3.3.7 权限管理
当系统只给特地的业务使用时,可以使用系统默认的vhost ,默认为/。建议根据业务命名vhost
新增虚拟主机:rabbitmqctl add_vhost vhost_name
删除虚拟主机:rabbitmqctl delete_vhost vhost_name
查看虚拟主机
设置权限
下面就以给用户paytest赋予访问控制的读、写及配置权限为例,开通远程连接
语法:rabbitmqctl set_permissions -p vhost_name Username “.*” “.*” “.*”
查看用户权限
语法: rabbitmqctl list_permissions -p vhost_name
删除权限
语法:rabbitmqctl clear_permissions -p vhost_name Username
NOTE:
-p pay:代表set_permissions控制条目应该应用到哪个vhost上;
paytest:代表被授权的用户名字;
“.*” “.*” “.*”:分别代表配置、读和写权限,而其中的”.*”为正则表达式,代表匹配所有权限
set_permissions [-p <vhostpath>] <user> <conf> <write> <read>
用户仅能对其所能访问的virtual hosts中的资源进行操作。这里的资源指的是virtual hosts中的
exchanges、queues等,操作包括对资源进行配置、写、读。配置权限可创建、删除、资源并修改
资源的行为,写权限可向资源发送消息,读权限从资源获取消息。
2 exchange和queue的declare与delete分别需要exchange和queue上的配置权限
2 exchange的bind与unbind需要exchange的读写权限
2 queue的bind与unbind需要queue写权限exchange的读权限
2 发消息(publish)需exchange的写权限
2 获取或清除(get、consume、purge)消息需queue的读权限
3.3.8 服务维护统计
http://www.rabbitmq.com/management.html #官方文档
http://www.rabbitmq.com/monitoring.html #官方文档
Note:
多节点,一定要做时间同步,确保每个节点时间一致
如果我们需要查看数据的统计情况,那么就需要一些样板数据,所以我们需要创建个队列,并将队
列与交换机或转发器进行绑定,使产生些数据供查看统计(目前队列没有数据,看到是空的)
查看队列
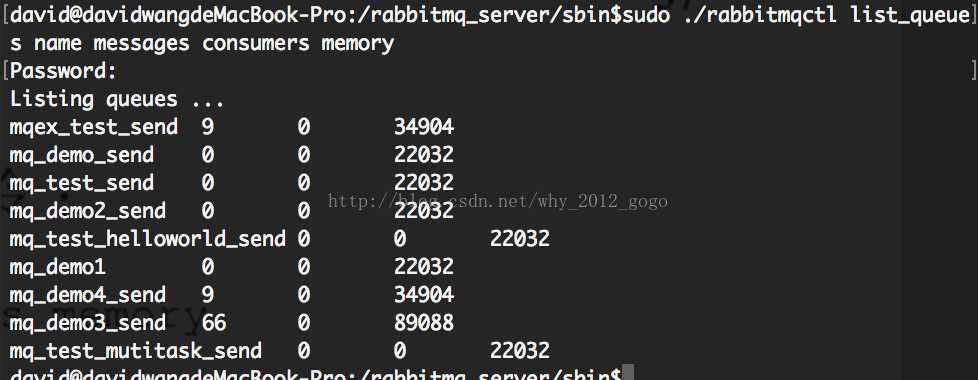
查看默认虚拟机上所有的队列列表(list_queues):rabbitmqctl list_queues
查看虚拟机上队列的名字、消息数目、消费者数目及内存使用情况:
从网上截取例子:
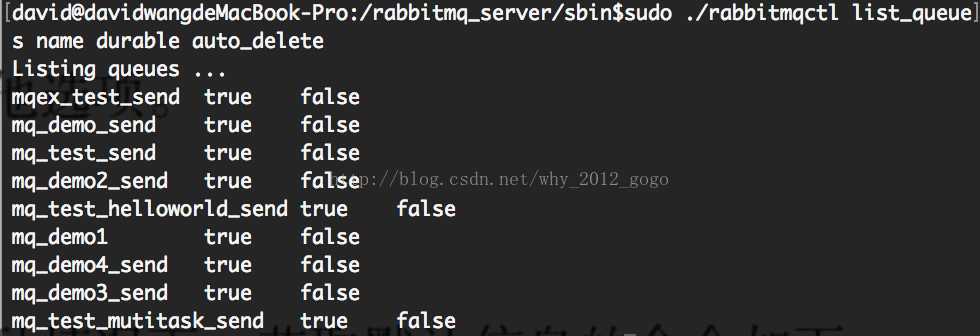
可以查看队列声明时的属性特征,具体如下
查看交换机
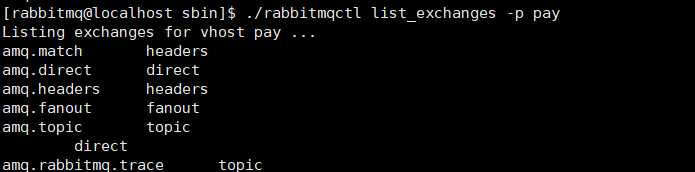

我们查看了交换机的名字、类型、是否持久化及是否会被系统自动删除等信息。
查看绑定到交换机的队列
目前没有数据

附录A
1、 RabbitMQ端口说明
4369:epmd,RabbitMQ节点和CLI工具使用的对等发现服务
5672,5671:AMQP 0-9-1和1.0客户端使用没有和使用TLS
25672:用于节点间和CLI工具通信(Erlang分发服务器端口)并从动态范围分配(默认情况下限
于单个端口,计算为AMQP端口+ 20000)。除非确实需要这些端口上的外部连接(例如,
群集使用联合或CLI工具在子网外的计算机上使用),否则不应公开这些端口。有关详情, 请
参阅网络指南
35672-35682:由CLI工具(Erlang分发客户端端口)用于与节点通信,并从动态范围(计算为服
务器分发端口+ 10000到服务器分发端口+ 10010)进行分配。有关详情, 请参阅网络指南
15672:HTTP API客户端,管理UI和rabbitmqadmin(仅当启用了管理插件时)
61613,61614:没有和使用TLS的STOMP客户端(仅当启用了STOMP插件时)
1883,8883 :( 如果启用了MQTT插件,则没有和使用TLS的MQTT客户端
15674:STOMP-over-WebSockets客户端(仅当启用了Web STOMP插件时)
15675:MQTT-over-WebSockets客户端(仅当启用了Web MQTT插件时)
2、常用命令
[[email protected] sbin]# ./rabbitmqctl
Usage:
rabbitmqctl [-n <node>] [-q] <command> [<command options>]
Options:
-n node
-q
Default node is "[email protected]", where server is the local host. On a host
named "server.example.com", the node name of the RabbitMQ Erlang node will
usually be [email protected] (unless RABBITMQ_NODENAME has been set to some
non-default value at broker startup time). The output of hostname -s is usually
the correct suffix to use after the "@" sign. See rabbitmq-server(1) for
details of configuring the RabbitMQ broker.
Quiet output mode is selected with the "-q" flag. Informational messages are
suppressed when quiet mode is in effect.
Commands:
stop [<pid_file>]
stop_app
start_app
wait <pid_file>
reset
force_reset
rotate_logs <suffix>
cluster <clusternode> ...
force_cluster <clusternode> ...
cluster_status
add_user <username> <password>
delete_user <username>
change_password <username> <newpassword>
clear_password <username>
set_user_tags <username> <tag> ...
list_users
add_vhost <vhostpath>
delete_vhost <vhostpath>
list_vhosts [<vhostinfoitem> ...]
set_permissions [-p <vhostpath>] <user> <conf> <write> <read>
clear_permissions [-p <vhostpath>] <username>
list_permissions [-p <vhostpath>]
list_user_permissions [-p <vhostpath>] <username>
list_queues [-p <vhostpath>] [<queueinfoitem> ...]
list_exchanges [-p <vhostpath>] [<exchangeinfoitem> ...]
list_bindings [-p <vhostpath>] [<bindinginfoitem> ...]
list_connections [<connectioninfoitem> ...]
list_channels [<channelinfoitem> ...]
list_consumers [-p <vhostpath>]
status
environment
report
eval <expr>
close_connection <connectionpid> <explanation>
trace_on [-p <vhost>]
trace_off [-p <vhost>]
set_vm_memory_high_watermark <fraction>
3、rabbit角色说明
l none
不能访问 management plugi
l management
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
l policymaker
management可以做的任何事外加:
查看、创建和删除自己的virtual hosts所属的policies和parameters
l monitoring
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual hosts的全局的统计信息
l administrator
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections
4、Exchange Type说明
l fanout转发器,是几种转发器中转发消息最快的一种,其路由规则会将消息转发给与转发器绑定的每一个队列中,也就是轮循转发相同消息给队列
l direct转发器,会根据当前发送和接受端协商的统一的routing key来完全匹配转发消息,也就是转发器发送标有routing key标志的路由信息,只有接收端的binding key与routing key与之相同,才会接收到信息
l topic转发器,相对于direct转发器,topic可以转发符合多个条件的消息,也就是发送端发送消息,而接受端可以灵活配置接收消息的路由规则,例如:msg.#和msg.*,前者能够接收msg.log.info和msg.log类型消息,而后者则能接收到msg.*类型消息,所以#号代表一个或多个单词匹配,而*则代表一个单词匹配了,实际上就是正常的规则过滤机制
l headers转发器,也是用的比较少的转发器,原因请查看第一部分介绍。此种转发器,忽略了路由routing key规则,使用了健-值对形式匹配规则,此种转发器规定,在接受端必须使用x-match,它目前有两种类型:all和any,前者代表所有的键-值都满足后,才能收到信息,而后者则满足任意个就可以收到消,这个会在后续文章介绍,这里只需了解即可
5、图形化管理RabbitMQ
http://www.rabbitmq.com/management.html # 官网文档
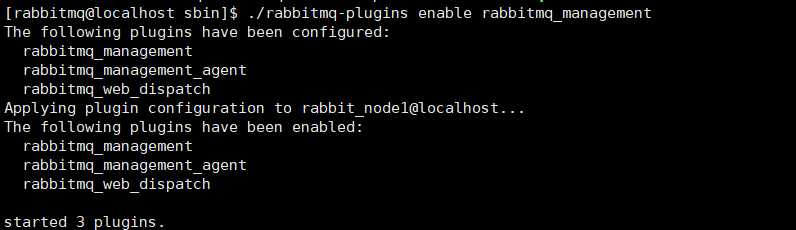
开启管理插件
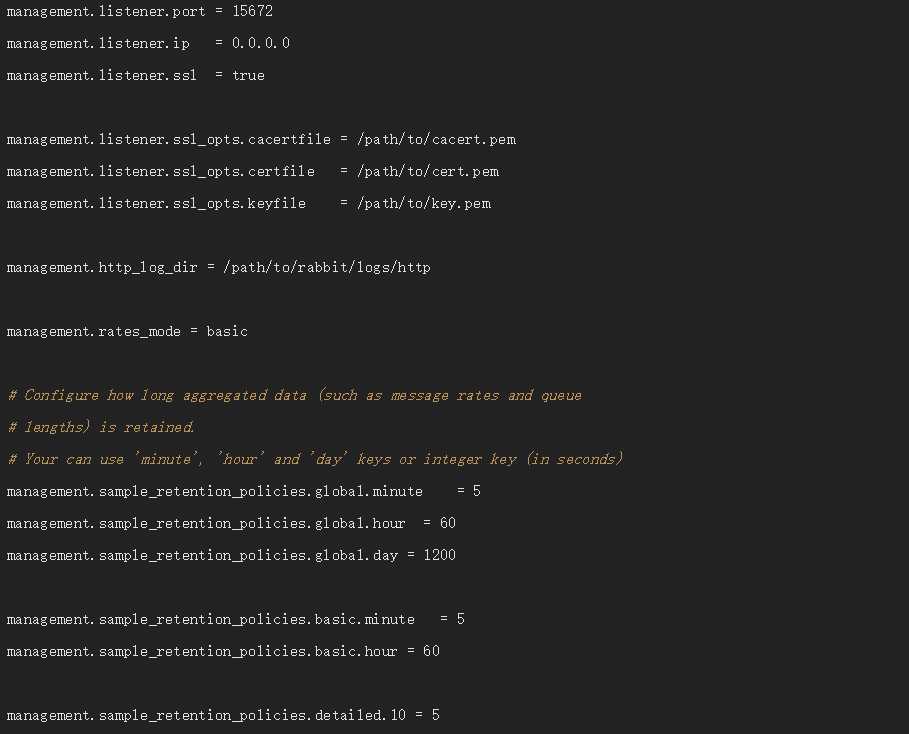
其他配置选项,根据配置文件酌情修改如下:
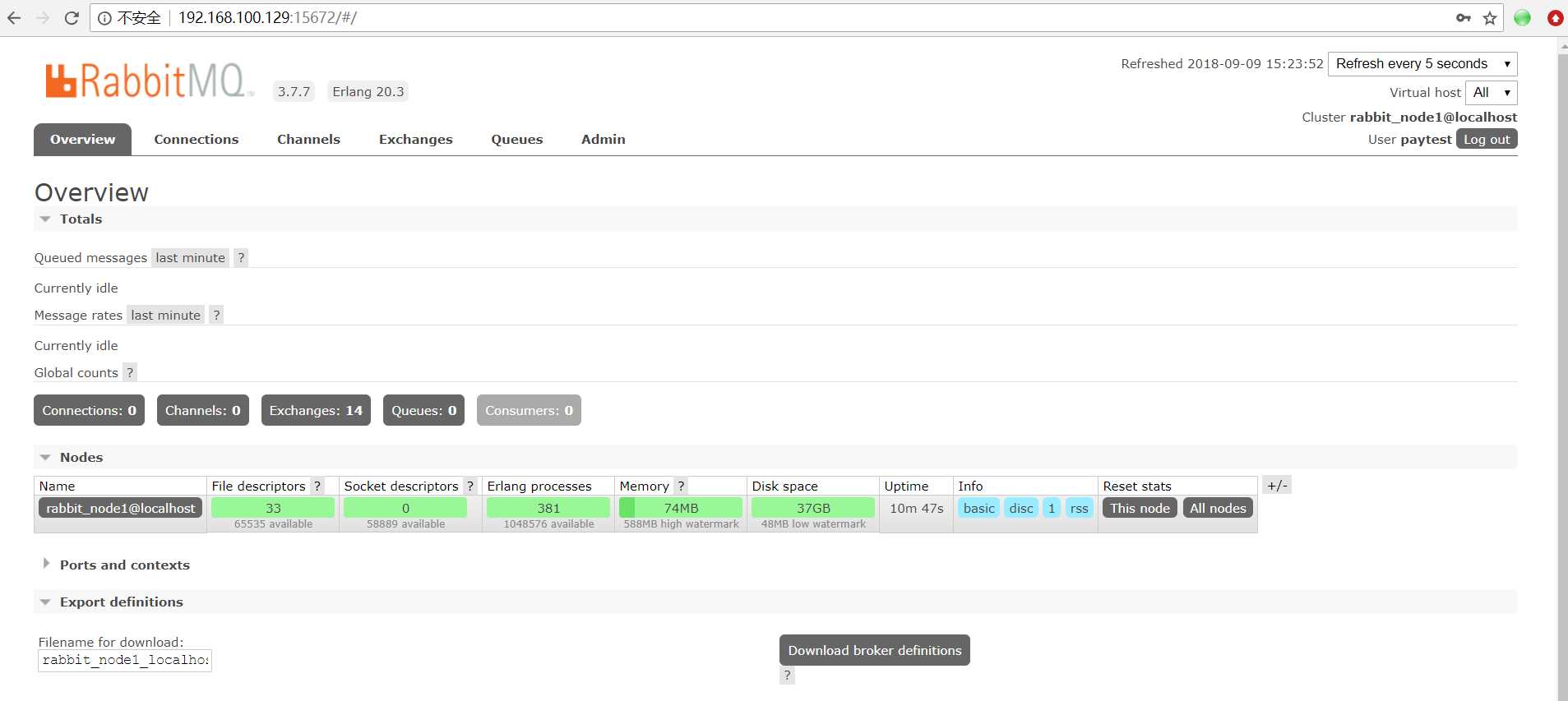
登录
6、配置文件中文说明
##相关文档指南:http://rabbitmq.com/configure.html。看到
## http://rabbitmq.com/documentation.html文档ToC。
## 网络设置
## ====================
##
##相关文档指南:http://rabbitmq.com/networking.html。
##
##默认情况下,RabbitMQ将使用侦听所有接口
##标准(保留)AMQP 0-9-1和1.0端口。
##
#listeners.tcp.default = 5672
##要监听特定的接口,请提供带有端口的IP地址。
##例如,只在本地主机上侦听IPv4和IPv6:
##
#IPv4
#listeners.tcp.local = 127.0.0.1:5672
#IPv6
#listeners.tcp.local_v6 = :: 1:5672
##您可以使用侦听器名称定义多个侦听器
#listeners.tcp.other_port = 5673
#listeners.tcp.other_ip = 10.10.10.10:5672
## TLS监听器的配置方式与TCP监听器相同,
##包括控制界面选择的选项。
##
#listeners.ssl.default = 5671
##将接受TCP连接的Erlang进程的数量
##和TLS监听器。
##
#num_acceptors.tcp = 10
#num_acceptors.ssl = 1
## AMQP 0-8 / 0-9 / 0-9-1握手的最大时间(套接字连接后)
##和TLS握手),以毫秒为单位。
##
#handshake_timeout = 10000
##设置为‘true‘在接受a时执行反向DNS查询
##连接。主机名将被显示,而不是IP地址
在rabbitmqctl中的##和管理插件。
##
#reverse_dns_lookups = true
##
##安全,访问控制
## ==============
##
##相关文档指南:http://rabbitmq.com/access-control.html。
##默认的“访客”用户只能访问服务器
##通过一个回送接口(例如本地主机)。
## {loopback_users,[<<“guest”>>]},
##
#loopback_users.guest = true
##如果您想允许访问,请取消注释以下行
##来宾用户从网络上的任何地方。
#loopback_users.guest = false
## TLS配置。
##
##相关文档指南:http://rabbitmq.com/ssl.html。
##
#ssl_options.verify = verify_peer
#ssl_options.fail_if_no_peer_cert = false
#ssl_options.cacertfile = /path/to/cacert.pem
#ssl_options.certfile = /path/to/cert.pem
#ssl_options.keyfile = /path/to/key.pem
##选择要使用的认证/授权后端。
##
##备用后端由插件提供,例如rabbitmq-auth-backend-ldap。
##
##注意:这些设置需要启用某些插件。
##
##相关文档指南:
##
## * http://rabbitmq.com/plugins.html
## * http://rabbitmq.com/access-control.html
##
#auth_backends.1 = rabbit_auth_backend_internal
##使用单独的后端进行身份验证和授权,
## 见下文。
#auth_backends.1.authn = rabbit_auth_backend_ldap
#auth_backends.1.authz = rabbit_auth_backend_internal
## rabbitmq_auth_backend_ldap插件允许经纪人
##通过推迟到一个执行认证和授权
##外部LDAP服务器。
##
##相关文档指南:
##
## * http://rabbitmq.com/ldap.html
## * http://rabbitmq.com/access-control.html
##
##使用LDAP进行身份验证和授权
#auth_backends.1 = rabbit_auth_backend_ldap
##使用HTTP服务进行身份验证和
##授权
#auth_backends.1 = rabbit_auth_backend_http
##在链中使用两个后端:首先是HTTP,然后是内部
#auth_backends.1 = rabbit_auth_backend_http
#auth_backends.2 = rabbit_auth_backend_internal
##认证
##内置的机制是“普通”,
##‘AMQPLAIN‘和‘EXTERNAL‘可以通过添加其他机制
##插件。
##
##相关文档指南:http://rabbitmq.com/authentication.html。
##
#auth_mechanisms.1 = PLAIN
#auth_mechanisms.2 = AMQPLAIN
## rabbitmq-auth-mechanism-ssl插件使得它成为可能
##根据客户端的x509(TLS)证书对用户进行身份验证。
##相关文档指南:http://rabbitmq.com/authentication.html。
##
##要使用auth-mechanism-ssl,EXTERNAL机制应该
##被启用:
##
#auth_mechanisms.1 = PLAIN
#auth_mechanisms.2 = AMQPLAIN
#auth_mechanisms.3 = EXTERNAL
##要强制所有客户端上基于x509证书的身份验证,
##排除所有其他机制(注意:这将禁用基于密码的
##认证甚至管理用户界面!):
##
#auth_mechanisms.1 = EXTERNAL
##这涉及rabbitmq-auth-mechanism-ssl插件和
## STOMP ssl_cert_login配置。查看RabbitMQ STOMP插件
稍后在此文件和README中的##配置部分
## https://github.com/rabbitmq/rabbitmq-auth-mechanism-ssl进一步
## 细节。
##
##使用TLS证书的CN而不是DN作为用户名
##
#ssl_cert_login_from = common_name
## TLS握手超时,以毫秒为单位。
##
#ssl_handshake_timeout = 5000
##密码散列实现。只会影响新的
##创建用户。重新计算现有用户的散列值
##有必要更新她的密码。
##
##要使用SHA-512,请设置为rabbit_password_hashing_sha512。
##
#password_hashing_module = rabbit_password_hashing_sha256
##导入从早期版本导出的定义
##比3.6.0,有可能回到MD5(只做这个
##作为临时措施!)通过将其设置为rabbit_password_hashing_md5。
##
#password_hashing_module = rabbit_password_hashing_md5
##
##默认用户/ VHost
## ====================
##
##首先启动RabbitMQ将创建一个虚拟主机和一个用户。这些
## config items控制创建的内容。
##相关文档指南:http://rabbitmq.com/access-control.html
##
#default_vhost = /
#default_user = guest
#default_pass = guest
#default_permissions.configure =.*
#default_permissions.read =.*
#default_permissions.write =.*
##默认用户的标签
##
##有关标签的更多详细信息,请参阅文档
##管理插件在http://rabbitmq.com/management.html。
##
#default_user_tags.administrator = true
##定义这样的其他标签:
#default_user_tags.management = true
#default_user_tags.custom_tag = true
##
##其他网络和协议相关的配置
## ================================================ =====
##
##设置默认的AMQP 0-9-1心跳间隔(以秒为单位)。
##相关文档指南:
##
## * http://rabbitmq.com/heartbeats.html
## * http://rabbitmq.com/networking.html
##
#心跳= 600
##设置AMQP帧的最大允许大小(以字节为单位)。
##
#frame_max = 131072
##设置连接前服务器将接受的最大帧大小
##调整发生
##
#initial_frame_max = 4096
##设置每个连接的最大允许通道数量。
## 0的意思是“没有限制”。
##
#channel_max = 128
##自定义TCP监听器(套接字)配置。
##
##相关文档指南:
##
## * http://rabbitmq.com/networking.html
## * http://www.erlang.org/doc/man/inet.html#setopts-2
##
#tcp_listen_options.backlog = 128
#tcp_listen_options.nodelay = true
#tcp_listen_options.exit_on_close = false
##
##资源限制和流量控制
## ==============================
##
##相关文档指南:http://rabbitmq.com/memory.html。
##基于内存的流量控制阈值。
##
#vm_memory_high_watermark.relative = 0.4
##或者,我们可以设置节点使用的RAM的限制(以字节为单位)。
##
#vm_memory_high_watermark.absolute = 1073741824
##或者您可以使用内存单位设置绝对值(使用RabbitMQ 3.6.0+)。
如果相对定义,绝对水印将被忽略!
##
#vm_memory_high_watermark.absolute = 2GB
##
##支持的单位后缀:
##
## kb,KB:kibibytes(2 ^ 10个字节)
## mb,MB:mebibytes(2 ^ 20)
GB gb,GB:gibibytes(2 ^ 30)
##队列开始的高水印限制的分数
##寻呼消息到光盘为了释放内存。
##例如,当vm_memory_high_watermark被设置为0.4并且该值被设置为0.5时,
##分页可以在节点使用总可用RAM的20%时开始。
##
##大于1.0的值可能是危险的,应谨慎使用。
##
##一个替代方案是使用持久队列和发布消息
##作为永久(交付模式= 2)。有了这个组合队列将
##将消息更快地移动到磁盘。
##
##另一种选择是配置队列来寻呼所有消息(都是
##持久性和瞬态)到磁盘
##尽可能参见http://rabbitmq.com/lazy-queues.html。
##
#vm_memory_high_watermark_paging_ratio = 0.5
##选择Erlang VM内存消耗计算策略。可以是“分配”,“rss”或“legacy”(别名为“erlang”),
##在3.6.11中介绍。“rss”是3.6.12的默认值。
##查看https://github.com/rabbitmq/rabbitmq-server/issues/1223和rabbitmq / rabbitmq-common#224获取背景信息。
#vm_memory_calculation_strategy = rss
##我们执行内存检查的间隔(以毫秒为单位)
##水平对水印。
##
#memory_monitor_interval = 2500
##可用的总内存可以从OS资源中计算出来
## - 默认选项 - 或作为配置参数提供。
#total_memory_available_override_value = 2GB
##设置磁盘空闲限制(以字节为单位)。一旦可用磁盘空间达到此目的
##下限,磁盘报警将被设置 - 请参阅文档
##上面列出了更多的细节。
##
如果相对定义,绝对水印将被忽略!
#disk_free_limit.absolute = 50000
##或者你可以使用内存单元(与vm_memory_high_watermark相同)
##与RabbitMQ 3.6.0+。
#disk_free_limit.absolute = 500KB
#disk_free_limit.absolute = 50mb
#disk_free_limit.absolute = 5GB
##或者,我们可以设置一个相对于可用RAM总量的限制。
##
##低于1.0的值可能是危险的,应谨慎使用。
#disk_free_limit.relative = 2.0
##
##聚类
## =====================
##
#cluster_partition_handling =忽略
## pause_if_all_down策略需要额外的配置
#cluster_partition_handling = pause_if_all_down
##恢复策略。可以是“autoheal”或“忽略”
#cluster_partition_handling.pause_if_all_down.recover =忽略
##节点名称检查
#cluster_partition_handling.pause_if_all_down.nodes.1 = rabbit @ localhost
#cluster_partition_handling.pause_if_all_down.nodes.2 = hare @ localhost
##在消息中镜像同步批量大小。增加这将加快速度
##同步,但批量总大小(以字节为单位)不得超过2 GiB。
##在RabbitMQ 3.6.0或更高版本中可用。
##
#mirroring_sync_batch_size = 4096
##在启动时自动进行聚类。仅适用
##到第一次刚复位或启动的节点。
##
##相关文档指南:http://rabbitmq.com//cluster-formation.html
##
#autocluster.peer_discovery_backend = rabbit_peer_discovery_classic_config
#
#autocluster.classic_config.nodes.node1 = rabbit1 @ hostname
#autocluster.classic_config.nodes.node2 = rabbit2 @ hostname
#autocluster.classic_config.nodes.node3 = rabbit3 @ hostname
#autocluster.classic_config.nodes.node4 = rabbit4 @ hostname
##基于DNS的对等发现。这后端将列出A记录
配置的主机名##并执行反向查找
##返回的地址。
#autocluster.peer_discovery_backend = rabbit_peer_discovery_dns
#autocluster.dns.hostname = rabbitmq.discovery.mycompany.local
##此节点的类型可以配置。如果你不确定
##使用什么节点类型,总是使用“光盘”。
#autocluster.node_type =光盘
##发送Keepalive消息的间隔(以毫秒为单位)
##给其他集群成员。请注意,这不是一回事
## as net_ticktime; 遗漏的keepalive消息不会导致节点
##被认为是失望的。
##
#cluster_keepalive_interval = 10000
##
##统计收集
## =====================
##
##设置(内部)统计信息收集粒度。
##
##可以不是,粗或细
#collect_statistics =无
#collect_statistics =粗略
##统计信息收集间隔(以毫秒为单位)。增加
##这将减少管理数据库的负载。
##
#collect_statistics_interval = 5000
##
##其他/高级选项
## =====================
##
##注意:只有在你明白自己在做什么的情况下才能改变这些!
##
##显式启用/禁用hipe编译。
##
#hipe_compile = false
##在等待群集中的Mnesia表时使用的超时
##变得可用。
##
#mnesia_table_loading_retry_timeout = 30000
##在群集启动中等待Mnesia表时重试。注意
##此设置不适用于Mnesia升级或节点删除。
##
#mnesia_table_loading_retry_limit = 10
##以字节为单位的大小,低于该大小将消息嵌入到队列索引中。
##相关文档指南:http://rabbitmq.com/persistence-conf.html
##
#queue_index_embed_msgs_below = 4096
##你也可以用内存单位来设置这个大小
##
#queue_index_embed_msgs_below = 4kb
##是否启用所有的后台定期GC
## Erlang处于“等待”状态。
##
##禁用后台GC可以减少客户端操作的延迟,
##保持启用可能会减少RAM的使用量。
##
#background_gc_enabled = false
##运行背景GC的目标(期望)间隔(以毫秒为单位)。
##实际时间间隔取决于执行时间的长短
##操作(可高于此间隔)。值小于
##不建议使用30000毫秒。
##
#background_gc_target_interval = 60000
##是否启用代理协议支持。
##一旦启用,客户端不能直接连接到代理
##了。他们必须通过一个负载均衡器连接发送
##代理协议头在连接时间给代理。
##此设置仅适用于AMQP客户端,其他协议
像MQTT或STOMP这样的##有自己的设置来启用代理协议。
##请参阅插件文档以获取更多信息。
##
#proxy_protocol = false
## ------------------------------------------------ ----------------------------
##高级的Erlang网络/集群选项。
##
##相关文档指南:http://rabbitmq.com/clustering.html
## ------------------------------------------------ ----------------------------
#======================================
#内核部分
#======================================
#kernel.net_ticktime = 60
## ------------------------------------------------ ----------------------------
## RabbitMQ管理插件
##
##相关文档指南:http://rabbitmq.com/management.html。
## ------------------------------------------------ ----------------------------
#=======================================
#管理部分
#=======================================
##从以下JSON文件中预载模式定义。
##相关文档指南:http://rabbitmq.com/management.html#load-definitions。
##
#management.load_definitions = /path/to/exported/definitions.json
##将所有对管理HTTP API的请求记录到一个文件中。
##
#management.http_log_dir = /path/to/access.log
##更改HTTP侦听器侦听的端口,
##指定Web服务器绑定的接口。
##还要将侦听器设置为使用TLS并提供TLS选项。
##
#management.listener.port = 15672
#management.listener.ip = 127.0.0.1
#management.listener.ssl = true
#management.listener.ssl_opts.cacertfile = /path/to/cacert.pem
#management.listener.ssl_opts.certfile = /path/to/cert.pem
#management.listener.ssl_opts.keyfile = /path/to/key.pem
##“基本”,“详细”或“无”之一。看到
## http://rabbitmq.com/management.html#fine-stats了解更多详情。
#management.rates_mode =基本
##配置聚合数据的长度(如消息速率和队列
##长度)被保留。请阅读插件的文档
## http://rabbitmq.com/management.html#configuration更多
## 细节。
##您可以使用“分钟”,“小时”和“日”键或整数键(以秒为单位)
#management.sample_retention_policies.global.minute = 5
#management.sample_retention_policies.global.hour = 60
#management.sample_retention_policies.global.day = 1200
#management.sample_retention_policies.basic.minute = 5
#management.sample_retention_policies.basic.hour = 60
#management.sample_retention_policies.detailed.10 = 5
## ------------------------------------------------ ----------------------------
## RabbitMQ铲子插件
##
##相关文档指南:http://rabbitmq.com/shovel.html
## ------------------------------------------------ ----------------------------
## Shovel插件配置示例在additional.config文件中定义
## ------------------------------------------------ ----------------------------
## RabbitMQ STOMP插件
##
##相关文档指南:http://rabbitmq.com/stomp.html
## ------------------------------------------------ ----------------------------
#=======================================
#STOMP部分
#=======================================
##网络配置。格式通常与核心代理相同。
##
#stomp.listeners.tcp.default = 61613
##与ssl监听器相同
##
#stomp.listeners.ssl.default = 61614
##将接受TCP连接的Erlang进程的数量
##和TLS监听器。
##
#stomp.num_acceptors.tcp = 10
#stomp.num_acceptors.ssl = 1
##其他TLS选项
##使用TLS时,从客户端证书中提取名称。
##
#stomp.ssl_cert_login = true
##设置默认的用户名和密码。这被用作默认登录
##每当CONNECT框架省略登录名和密码头。
##
##请注意,设置这将允许客户端连接没有
##验证!
##
#stomp.default_user = guest
#stomp.default_pass = guest
##如果配置了默认用户,或者您已配置使用TLS客户端
##证书为基础的身份验证,您可以选择允许客户端
##完全忽略CONNECT帧。如果设置为true,则客户端是
##自动连接为默认用户或用户提供的
每当在一个会话上发送的第一帧不是一个## TLS证书
##连接框架。
##
#stomp.implicit_connect = true
##是否启用代理协议支持。
##一旦启用,客户端不能直接连接到代理
##了。他们必须通过一个负载均衡器连接发送
##代理协议头在连接时间给代理。
##此设置仅适用于STOMP客户端,其他协议
像MQTT或AMQP这样的##有自己的设置来启用代理协议。
##请参阅插件或代理文档以获取更多信息。
##
#stomp.proxy_protocol = false
## ------------------------------------------------ ----------------------------
## RabbitMQ MQTT适配器
##
##见https://github.com/rabbitmq/rabbitmq-mqtt/blob/stable/README.md
##的细节
## ------------------------------------------------ ----------------------------
#=======================================
#MQTT部分
#=======================================
##设置默认的用户名和密码。将被用作默认登录
##如果连接客户端没有提供其他登录信息。
##
##请注意,设置这将允许客户端连接没有
##验证!
##
#mqtt.default_user = guest
#mqtt.default_pass = guest
##启用匿名访问。如果这被设置为false,客户端必须提供
##登录信息才能连接。请参阅default_user / default_pass
##配置元素管理登录没有身份验证。
##
#mqtt.allow_anonymous = true
##如果你有多个chosts,指定哪个
##适配器连接。
##
#mqtt.vhost = /
##指定发布来自MQTT客户端的消息的交换。
##
#mqtt.exchange = amq.topic
##指定TTL(生存时间)来控制非干净会话的生命周期。
##
#mqtt.subscription_ttl = 1800000
##设置预取计数(控制未确认的最大数量
##消息将被交付)。
##
#mqtt.prefetch = 10
## TCP / SSL配置(按照代理配置)。
##
#mqtt.listeners.tcp.default = 1883
##与ssl监听器相同
##
#mqtt.listeners.ssl.default = 1884
##将接受TCP连接的Erlang进程的数量
##和TLS监听器。
##
#mqtt.num_acceptors.tcp = 10
#mqtt.num_acceptors.ssl = 1
## TCP侦听器选项(按照代理配置)。
##
#mqtt.tcp_listen_options.backlog = 128
#mqtt.tcp_listen_options.nodelay = true
##是否启用代理协议支持。
##一旦启用,客户端不能直接连接到代理
##了。他们必须通过一个负载均衡器连接发送
##代理协议头在连接时间给代理。
##此设置仅适用于STOMP客户端,其他协议
##像STOMP或AMQP有自己的设置来启用代理协议。
##请参阅插件或代理文档以获取更多信息。
##
#mqtt.proxy_protocol = false
## ------------------------------------------------ ----------------------------
## RabbitMQ AMQP 1.0支持
##
##见https://github.com/rabbitmq/rabbitmq-amqp1.0/blob/stable/README.md。
## ------------------------------------------------ ----------------------------
#=======================================
#AMQP 1.0部分
#=======================================
##未通过SASL认证的连接将以此连接
##帐户。请参阅自述文件以获取更多信息。
##
##请注意,设置这将允许客户端连接没有
##验证!
##
#amqp1_0.default_user = guest
##启用协议严格模式。请参阅自述文件以获取更多信息。
##
#amqp1_0.protocol_strict_mode = false
## Lager控制记录。
##请参阅https://github.com/basho/lager获取更多文档
##
## Log direcrory,默认情况下取自RABBITMQ_LOG_BASE env变量。
##
#log.dir = / var / log / rabbitmq
##记录到控制台(可以为true或false)
##
#log.console = false
## Loglevel登录到控制台
##
#log.console.level = info
##记录到文件。可以是假的或文件名。
##默认:
#log.file = rabbit.log
## 把关掉:
#log.file = false
## Loglevel记录到文件
##
#log.file.level = info
##文件旋转配置。没有旋转的defualt。
##不要将旋转日期设置为“”。如果需要“”值,请保持不变
#log.file.rotation.date = $ D0
#log.file.rotation.size = 0
## QA:配置系统日志记录
#log.syslog = false
#log.syslog.identity = rabbitmq
#log.syslog.level = info
#log.syslog.facility =守护进程
## ------------------------------------------------ ----------------------------
## RabbitMQ LDAP插件
##
##相关文档指南:http://rabbitmq.com/ldap.html。
##
## ------------------------------------------------ ----------------------------
#=======================================
#LDAP部分
#=======================================
##
##连接到LDAP服务器
## ================================
##
##指定要绑定的服务器。你*必须*设置为了插件
##正常工作。
##
#auth_ldap.servers.1 =你的服务器名称在这里
##您可以定义多个服务器
#auth_ldap.servers.2 =你的其他服务器
##使用TLS连接到LDAP服务器
##
#auth_ldap.use_ssl = false
##指定要连接的LDAP端口
##
#auth_ldap.port = 389
## LDAP连接超时,以毫秒或“无限”
##
#auth_ldap.timeout =无限
##或号码
#auth_ldap.timeout = 500
##启用LDAP查询的记录。
##其中之一
## - false(不记录)
## - true(详细记录插件使用的逻辑)
## - 网络(如同,但另外记录LDAP网络流量)
##
##默认为false。
##
#auth_ldap.log = false
##也可以是真实的或网络
#auth_ldap.log = true
#auth_ldap.log =网络
##
##认证
## ==============
##
##模式将通过AMQP给出的用户名转换为DN
## 捆绑
##
#auth_ldap.user_dn_pattern = cn = $ {username},ou = People,dc = example,dc = com
##或者,您可以将用户名转换为Distinguished
##绑定后通过LDAP查找命名。请参阅文档
##全部细节。
##通过查找将用户名转换为dn时,将其设置为
##表示用户名的属性的名称,而
查找查询的## base DN。
##
#auth_ldap.dn_lookup_attribute = userPrincipalName
#auth_ldap.dn_lookup_base = DC = gopivotal,DC = com
##控制如何绑定授权查询,也可以
##检索登录用户的详细信息,而不显示一个
##密码(例如,SASL EXTERNAL)。
##其中之一
## - as_user(作为认证用户进行绑定 - 需要密码)
## - 匿名(匿名绑定)
## - {UserDN,Password}(用指定的用户名和密码绑定)
##
##默认为‘as_user‘。
##
#auth_ldap.other_bind = as_user
##或者可以更复杂:
#auth_ldap.other_bind.user_dn =用户
#auth_ldap.other_bind.password =密码
##如果user_dn和密码定义 - 其他选项被忽略。
#-----------------------------
#太复杂的LDAP部分
#-----------------------------
##
##授权
## =============
##
## LDAP插件可以针对您的应用程序执行各种查询
## LDAP服务器来确定授权的问题。
##
##相关文档指南:http://rabbitmq.com/ldap.html#authorisation。
##以下配置应该在additional.config文件中定义
##不要处理这条线!
##将查询设置为在确定访问虚拟主机时使用
##
## {vhost_access_query,{in_group,
##“ou = $ {vhost} -users,ou = vhosts,dc = example,dc = com”}}
##设置查询以在确定资源(例如,队列)访问时使用
##
## {resource_access_query,{constant,true}},
##设置查询来确定用户拥有哪些标签
##
## {tag_queries,[]}
#]},
#-----------------------------
以上是关于RabbitMQ消息过滤的一个思路的主要内容,如果未能解决你的问题,请参考以下文章