中国大数据六大技术变迁记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中国大数据六大技术变迁记相关的知识,希望对你有一定的参考价值。
中国大数据六大技术变迁记_数据分析师考试 集“Hadoop中国云计算大会”与“CSDN大数据技术大会”精华之大成, 历届的中国大数据技术大会
参考技术A中国大数据六大技术变迁记_数据分析师考试
集“Hadoop中国云计算大会”与“CSDN大数据技术大会”精华之大成, 历届的中国大数据技术大会(BDTC) 已发展成为国内事实上的行业顶尖技术盛会。从2008年的60人Hadoop沙龙到当下的数千人技术盛宴,作为业内极具实战价值的专业交流平台,每一届的中国大数据技术大会都忠实地描绘了大数据领域内的技术热点,沉淀了行业实战经验,见证了整个大数据生态圈技术的发展与演变。
2014年12月12-14日,由中国计算机学会(CCF)主办,CCF大数据专家委员会协办,中科院计算所与CSDN共同承办的 2014中国大数据技术大会(Big Data Technology Conference 2014,BDTC 2014) 将在北京新云南皇冠假日酒店拉开帷幕。大会为期三天,以推进行业应用中的大数据技术发展为主旨,拟设立“大数据基础设施”、“大数据生态系统”、“大数据技术”、“大数据应用”、“大数据互联网金融技术”、“智能信息处理”等多场主题论坛与行业峰会。由中国计算机学会主办,CCF大数据专家委员会承办,南京大学与复旦大学协办的“2014年第二届CCF大数据学术会议”也将同时召开,并与技术大会共享主题报告。
本次大会将邀请近100位国外大数据技术领域顶尖专家与一线实践者,深入讨论Hadoop、YARN、Spark、Tez、 HBase、Kafka、OceanBase等开源软件的最新进展,NoSQL/NewSQL、内存计算、流计算和图计算技术的发展趋势,OpenStack生态系统对于大数据计算需求的思考,以及大数据下的可视化、机器学习/深度学习、商业智能、数据分析等的最新业界应用,分享实际生产系统中的技术特色和实践经验。
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望:
追本溯源,悉大数据六大技术变迁
伴随着大数据技术大会的发展,我们亲历了中国大数据技术与应用时代的到来,也见证了整个大数据生态圈技术的发展与衍变:
1. 计算资源的分布化——从网格计算到云计算。 回顾历届BDTC大会,我们不难发现,自2009年,资源的组织和调度方式已逐渐从跨域分布的网格计算向本地分布的云计算转变。而时至今日,云计算已成为大数据资源保障的不二平台。
2. 数据存储变更——HDFS、NoSQL应运而生。 随着数据格式越来越多样化,传统关系型存储已然无法满足新时代的应用程序需求,HDFS、NoSQL等新技术应运而生,并成为当下许多大型应用架构不可或缺的一环,也带动了定制计算机/服务器的发展,同时也成为大数据生态圈中最热门的技术之一。
3. 计算模式改变——Hadoop计算框成主流。 为了更好和更廉价地支撑其搜索服务,Google创建了Map/Reduce和GFS。而在Google论文的启发下,原雅虎工程师Doug Cutting开创了与高性能计算模式迥异的,计算向数据靠拢的Hadoop软件生态系统。Hadoop天生高贵,时至今日已成为Apache基金会最“Hot”的开源项目,更被公认为大数据处理的事实标准。Hadoop以低廉的成本在分布式环境下提供了海量数据的处理能力。因此,Hadoop技术研讨与实践分享也一直是历届中国大数据技术大会最亮眼的特色之一。
4. 流计算技术引入——满足应用的低延迟数据处理需求。 随着业务需求扩展,大数据逐渐走出离线批处理的范畴,Storm、Kafka等将实时性、扩展性、容错性和灵活性发挥得淋漓尽致的流处理框架,使得旧有消息中间件技术得以重生。成为历届BDTC上一道亮丽的风景线。
5. 内存计算初露端倪——新贵Spark敢与老将叫板。 Spark发源于美国加州大学伯克利分校AMPLab的集群计算平台,它立足于内存计算,从多迭代批量处理出发,兼容并蓄数据仓库、流处理和图计算等多种计算范式,是罕见的全能选手。在短短4年,Spark已发展为Apache软件基金会的顶级项目,拥有30个Committers,其用户更包括IBM、Amazon、Yahoo!、Sohu、百度、阿里、腾讯等多家知名公司,还包括了Spark SQL、Spark Streaming、MLlib、GraphX等多个相关项目。毫无疑问,Spark已站稳脚跟。
6. 关系数据库技术进化—NewSQL改写数据库历史。 关系数据库系统的研发并没有停下脚步,在横向扩展、高可用和高性能方面也在不断进步。实际应用对面向联机分析处理(OLAP)的MPP(Massively Parallel Processing)数据库的需求最迫切,包括MPP数据库学习和采用大数据领域的新技术,如多副本技术、列存储技术等。而面向联机事务处理(OLTP)的数据库则向着高性能演进,其目标是高吞吐率、低延迟,技术发展趋势包括全内存化、无锁化等。
立足扬帆,看2014大数据生态圈发展
时光荏苒,转眼间第2014中国大数据技术大会将如期举行。在技术日新月异的当下,2014年的BDTC上又可以洞察些什么?这里我们不妨着眼当下技术发展趋势:
1. MapReduce已成颓势,YARN/Tez是否可以再创辉煌? 对于Hadoop来说,2014是欢欣鼓舞的一年——EMC、Microsoft、Intel、Teradata、Cisco等众多巨头都加大了Hadoop方面的投入。然而对于众多机构来说,这一年却并不轻松:基于MapReduce的实时性短板以及机构对更通用大数据处理平台的需求,Hadoop 2.0转型已势在必行。那么,在转型中,机构究竟会遭遇什么样的挑战?各个机构如何才能更好地利用YARN所带来的新特性?Hadoop未来的发展又会有什么重大变化?为此,BDTC 2014特邀请了Apache Hadoop committer,Apache Hadoop Project Management Committee(PMC)成员Uma Maheswara Rao G,Apache Hadoop committer Yi Liu,Bikas Saha(PMC member of the Apache Hadoop and Tez)等国际顶尖Hadoop专家,我们不妨当面探讨。
2. 时过境迁,Storm、Kafka等流计算框架前途未卜。 如果说MapReduce的缓慢给众多流计算框架带来了可乘之机,那么当Hadoop生态圈组件越发成熟,Spark更加易用,迎接这些流计算框架的又是什么?这里我们不妨根据BDTC 2014近百场的实践分享进行一个侧面的了解,亦或是与专家们当面交流。
3. Spark,是颠覆还是补充? 与Hadoop生态圈的兼容,让Spark的发展日新月异。然而根据近日Sort Benchmark公布的排序结果,在海量(100TB)离线数据排序上,对比上届冠军Hadoop,Spark以不到十分之一的机器,只使用三分之一的时间就完成了同样数据量的排序。毫无疑问,当下Spark已不止步于实时计算,目标直指通用大数据处理平台,而终止Shark,开启Spark SQL或许已经初见端倪。那么,当Spark愈加成熟,更加原生的支持离线计算后,开源大数据标准处理平台这个荣誉又将花落谁家?这里我们一起期待。
4. 基础设施层,用什么来提升我们的网络? 时至今日,网络已成为众多大数据处理平台的攻坚对象。比如,为了克服网络瓶颈,Spark使用新的基于Netty的网络模块取代了原有的NIO网络模块,从而提高了对网络带宽的利用。那么,在基础设施层我们又该如何克服网络这个瓶颈?直接使用更高效的网络设备,比如Infiniband能够带来多少性能提升?建立一个更智能网络,通过计算的每个阶段,自适应来调整拆分/合并阶段中的数据传输要求,不仅提高了速度,也提高了利用率。在BDTC 2014上,我们可以从Infiniband/RDMA技术及应用演讲,以及数场SDN实战上吸取宝贵的经验。
5. 数据挖掘的灵魂——机器学习。 近年来,机器学习领域的人才抢夺已进入白热化,类似Google、IBM、微软、百度、阿里、腾讯对机器学习领域的投入也是愈来愈高,囊括了芯片设计、系统结构(异构计算)、软件系统、模型算法和深度应用各个方面。大数据标志一个新时代的到来,PB数据让人们坐拥金山,然而缺少了智能算法,机器学习这个灵魂,价值的提取无疑变得镜花水月。而在本届会议上,我们同样为大家准备了数场机器学习相关分享,静候诸位参与。
而在技术分享之外,2014年第二届CCF大数据学术会议也将同时召开,并与技术大会共享主题报告。届时,我们同样可以斩获许多来自学术领域的最新科研成果。
以上是小编为大家分享的关于中国大数据六大技术变迁记的相关内容,更多信息可以关注环球青藤分享更多干货
一文看懂阿里京东滴滴大数据架构变迁
相关阅读:2T架构师学习资料干货分享
大数据的概念从上世纪90年代被提出,03-06年Google的3篇经典论文(GFS、MapReduce、Bigtable)作为奠基,Hadoop等优秀系统的出现使之繁荣,经历了十余年的时间。
从Gartner Hype Cycle这一行业技术发展的趋势图看,大数据从2011年进入该图谱,2014年被标记为进入衰退期,2015年开始不再标注,确实反映了这一概念经历了从不切实际的幻想期,到泡沫期,到衰退和成熟期的整个过程。目前来看,这一领域的技术已经相对稳定和成熟,各类应用已确实产生价值,使其成为了一种普惠性质的技术。
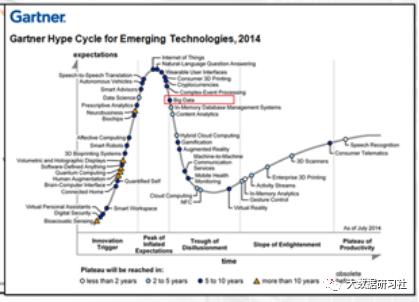
1、数据规模会继续扩大,数据价值会进一步挖掘
随着IOT技术的发展和成熟,5G的逐步推广,上游产生的数据量仍会快速增长,海量数据的采集、存储、处理技术仍有提升空间。
对于下游产业应用,则会进一步挖掘数据的价值,目前还有很多金矿没有开采。
2、数据实时性需求将进一步增加
3、底层技术集中化,上层应用全面开花
从前面的大数据技术栈图可以看到,大数据领域各种组件和技术繁多,更新也非常快。但近几年包括头部互联网企业也都将底层技术进行集中,如批处理领域的Spark,消息队列领域的Kafka几乎成为事实的标准,我们预计每一个细分领域的组件都会集中到1-2个上来。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
与此相反,上层应用层面则百花齐放,大互联网公司几乎所有产品都包含大数据元素,某些垂直领域也出现了专业性公司,如专门做BI的、专门做AI产品的。可以预见今后的创新主要都将集中在应用层面。
4、公有云和私有云并存
在国外,公有云上的大数据服务已经基本普及。但在国内,由于各企业所在领域不同,对数据安全性标准不同,并且互联网行业存在恶性竞争情况,短期内大多数企业仍倾向于以本地机房方式来部署大数据的基础设施。无论采用哪种方式,未来的大数据技术栈都会朝着容器化、存储计算分离、跨机房跨地域部署的方向发展。
飞天大数据平台始于2009年阿里巴巴的“登月”计划,目前已经在阿里云内部实际运行和服务了十年之久(大家过去更为熟悉的 MaxCompute 是飞天系统的三大件之一,也是如今飞天大数据平台的核心)。如今飞天大数据平台在阿里巴巴经济体中支撑99%的数据存储和99%的计算力,单日数据处理量超过600PB,也是阿里AI技术最重要的基础设施之一。
历史
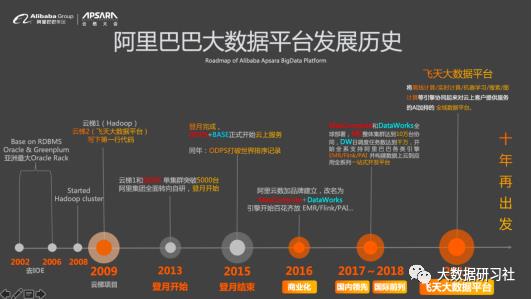
2009 年,阿里启动“云梯”计划,当时有两条技术路线同步进行,分别是开源的Hadoop和自研的ODPS(也就是今天的MaxCompute)。当时阿里已经下定决心要开始去IOE并构建自己的大数据平台,但还没有决定好是走开源路线还是自研路线,因此就有了云梯1(Hadoop)和云梯2(ODPS)的并行。2013年,两个平台先后突破单集群5000台服务器。最终从深度技术把控力和极致性能优化的角度,决定采用云梯2。同年,“登月”项目正式启动。
在“登月”项目进行过程中,自研数据综合治理平台DataWorks(原来叫作BASE)也同步开始构建。到了2015年,“登月”项目完成,ODPS+BASE开始在阿里云上对外提供服务,这也标志着阿里第一套数据中台体系构建完成。同年,ODPS打破了SortBenchmark的4项世界纪录,100TB数据排序仅耗时不到7分钟。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
目前的飞天大数据平台,是一个能够将离线计算、实时计算、机器学习、搜索、图计算等引擎协同起来对云上客户提供服务、且有AI加持的全域数据平台。下图是其完整架构。
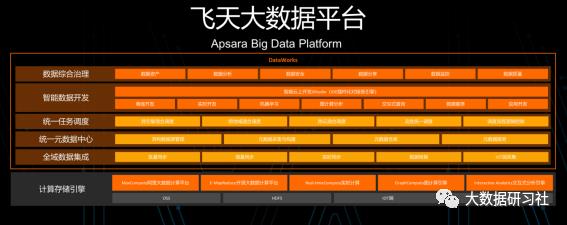
与传统大数据平台相比,该平台具备以下特色:
下图是其核心能力。

2010年,京东集团启动了在大数据领域的研发和应用探索工作,正式组建京东大数据部,并确立了数据集中式的数据服务模式,成为企业大数据最早的实践者之一。
目前已拥有集群规模40000+服务器,单集群规模达到7000+台,数据规模 800PB+,日增数据1P+,日运行JOB数100万+,业务表900万+张。每日的离线数据日处理30PB+,实时计算每天消费的行数近万亿条。
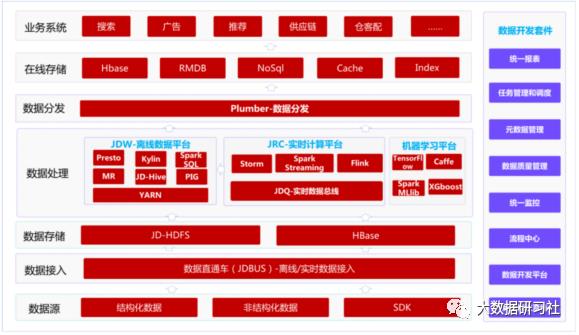
京东的大数据体系可以看作是基于Hadoop的大数据体系的优化和应用,因此对除阿里以外的企业来说更有借鉴意义。以下是其各主要模块所使用的技术栈。
1、数据采集和预处理
搭建了标准化的数据采集系统:数据直通车(框架自研,组件有使用开源技术),具备离线和实时两种数据采集方式。
离线采集主要类型:MySQL、SQLServer、Oracle、MongoDB、HBase、ElasticSearch、离线文件。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
实时采集主要类型:MySQL、日志、HTTP API、JMQ等。
2、流量数据采集
主要采集PC端、移动端应用、移动端H5页面、微信手Q内嵌入口、小程序等流量入口的埋点数据。这部分难点在于,各流量入口实现原理不同,数据采集的诉求也不同,甚至有可能不同来源的数据需要做连接,因此需要较多的数据标识工作。
3、数据存储
包括JDHDFS存储(开源HDFS的改进版)、JDHBase(开源HBase的改进版)、冷热数据管理等。对开源组件的改进点主要在容灾、元数据、多租户等方面,对核心代码逻辑没有做大的改动。
4、离线计算
包括JDHive计算引擎(开源Hive的改进版)、JDSpark计算引擎(开源Spark的改进版)、Adhoc查询服务(封装了Presto和Kylin)等,底层仍使用YARN作为资源调度器。另外还支持使用Alluxio作为缓存层,加速线上业务的数据查询速度。
5、实时计算
6、机器学习
京东机器学习平台由基础架构层、工具层、任务调度层、算法层以及API层组成。京东没有公开其具体实现技术,但可以推测,其完全依赖大数据平台的数据采集、计算、存储能力,在工具层、算法层、API层做定制开发。
7、任务管理和调度
自研了京东分布式调度平台,包括管理节点、工作节点、Web管理端和日志收集器几个组件。其中管理节点支持高可用。
8、资源监控和运维
京东大数据平台监控实现了对调度系统、集群任务管理、集群存储资源、机房网络专线、全集群服务器资源的统一监控体系,在开源的Premetheus上进行二次开发。另外还有CMDB、自动部署系统等其他系统的支持。
滴滴大数据到目前为止经历了三个阶段,第一阶段是业务方自建小集群;第二阶段是集中式大集群、平台化;第三阶段是SQL化。
滴滴的离线大数据平台是基于Hadoop2(HDFS、Yarn、MapReduce)和Spark以及Hive构建,在此基础上开发了自己的调度系统和开发系统。调度系统负责调度大数据作业的优先级和执行顺序。开发平台是一个可视化的SQL编辑器,可以方便地查询表结构、开发SQL,并发布到大数据集群上。
离线计算平台架构如下:
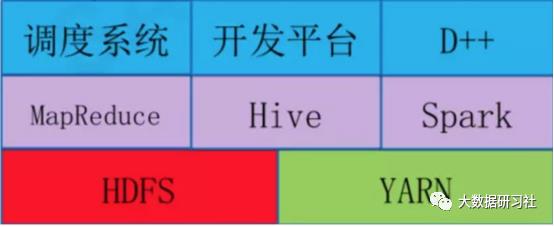
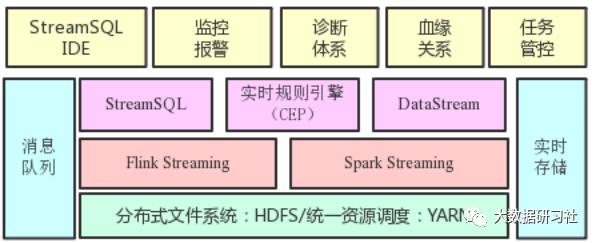
此外,滴滴还对HBase重度使用,并对相关产品(HBase、Phoenix)做了一些自定义的开发,维护着一个较大的HBase平台。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
来自于实时计算平台和离线计算平台的计算结果被保存到HBase中,然后应用程序通过Phoenix访问HBase。而Phoenix是一个构建在HBase上的SQL引擎,可以通过SQL方式访问HBase上的数据。
05
中小企业大数据平台技术栈选型
5.1 中等规模企业
指研发团队规模在千人左右,专职大数据团队规模在百人左右的企业。类似京东、滴滴。
这样的企业可以首先以开源Hadoop为基准搭建大数据平台。当在技术上有一定沉淀以后,可以在开源Hadoop社区各组件的版本上叠加自己的一些特性,使得能够更好地适配自身的业务形态,或减少运维的压力。在发展模式上,建议从一开始就建立统一的大数据平台,向公司内各部门统一输出能力,而不要各部门分散建设,避免后续的整合、迁移成本。在大数据平台形成完备的体系后,进一步建设公司层面的大数据中台。
具体的组件选型也比较容易确定。
1、数据采集
开源的数据采集组件如Flume、StreamSets等都经过了较长时间的生产检验,优势劣势都很明确,可以优先采用。如果定制型的采集需求很多,或者需要对数据做较多的on fly处理,也可以自研采集组件,但通常来说效率都没有开源的好。
还有一些比较新的开源采集工具,例如Apache Nifi,可以适当关注,不建议在生产中大规模使用。
2、数据存储
HDFS和HBase几乎是大数据存储领域实时上的标准。所有需求都应该优先往这两种存储上靠,其中HDFS对应离线数据的存储,HBase对应实时数据的存储。
Kudu是一种比较新的存储引擎,在某些互联网企业中被用来构建实时数仓,其实时性介于HDFS和HBase之间。目前也比较稳定,有实时数仓需求时可以引入。
另外,传统的RDBMS也是一种可靠的存储,在大数据领域可以用于报表、BI类服务,但使用时需要注意其数据量。
其余还有一些可用于缓存层的存储,如Redis,Alluxio等,严格来说不属于Hadoop生态体系,可以按需使用。
3、离线计算
MapReduce程序不应该再使用,这包括Hive on MapReduce的方案。如果一定需要Hive,可以跑在Spark上。
Spark一定需要,可以将Spark SQL作为构建离线数仓的主力工具。
如果有较多的BI类应用,可以考虑引入Impala或Kylin,这取决于是要事实计算数据立方,还是离线把数据立方准备好。
离线计算的资源管理可以继续使用YARN。
4、实时计算
消息队列领域,Kafka是必选方案。如果没有特别的理由,不要选用阿里开源出来的RocketMQ。
5、机器学习
Spark的MLlib可以解决一部分的机器学习需求。对于另一些比较复杂、偏门的算法,如果有明确需求需要使用,可以自己实现。
另一个问题是机器学习任务的开发环境。开源产品中只有Cloudera的CDSW比较好用,但它强依赖于CDH。中等规模互联网公司一般都自己开发这样的环境。
6、任务管理和调度
Hadoop生态下的开源调度系统有Oozie、Azkaban等,但功能都太简单,一般不会被这个规模的企业所采用。国内厂商贡献给社区的DolphinScheduler可以尝试。也可以自研。
7、其他
还有一些比较成熟的开源项目,如果有需求,完全可以在生产中使用。例如用于文档存储和搜索的ElasticSearch。这些可以根据企业所在的领域和自身技术积累来决策。
5.2 小规模企业
指研发团队规模在百人左右,专职大数据团队规模在几人到小几十人的企业。
这样的企业在构建大数据平台时,应该以现成的稳定产品为主,不要自研或者少量自研,因为老板肯定不愿意把有限的研发资源投入到组件的研究上。
首先要考虑的是使用公有云上的大数据服务,还是自建大数据集群。两者各有优劣,公有云出成果较快,自建集群掌控力较强,但成本投入相差不大。
一旦确定要自建集群,推荐使用成熟的Hadoop发行版,例如CDH、FusionInsight等。开源社区版本由于缺乏很多运维管理上的集成,不推荐小企业使用。所使用的技术栈仍可按照我们前面介绍的Hadoop core + Hive + HBase + Spark/Flink + Kafka的组合来选择。
来源:大数据研习社
以上是关于中国大数据六大技术变迁记的主要内容,如果未能解决你的问题,请参考以下文章