力扣:串联所有单词的子串(滑动窗口+哈希)
Posted 大便上的牙印
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了力扣:串联所有单词的子串(滑动窗口+哈希)相关的知识,希望对你有一定的参考价值。
首先,用
n
\\rm n
n 表示
S
\\rm S
S 串的长度,用
m
\\rm m
m 表示
w
o
r
d
s
\\rm words
words 的长度即words中单词的数量,用
w
\\rm w
w 表示
w
o
r
d
s
\\rm words
words 中每个单词的长度。
①对于
S
\\rm S
S 串以
w
\\rm w
w 为长度进行分割,则每一个
w
\\rm w
w 独立存在(可看成一个元素)。
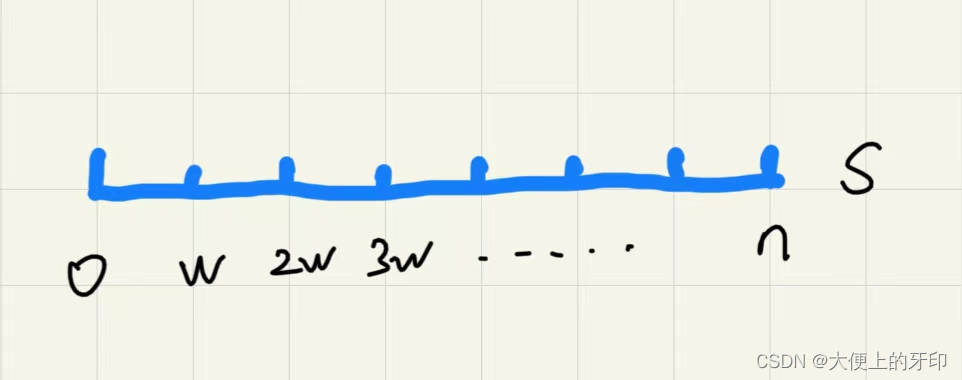
②则有以
i
=
0
,
1
,
…
,
w
−
1
i = 0,1,\\dots,w-1
i=0,1,…,w−1 的
w
\\rm w
w 起点,看作
w
\\rm w
w 个组。
③在该串上,对每一个长度为
w
\\rm w
w 看作独立存在的元素,维护一个长度为
m
\\rm m
m 的滑动窗口,
j
\\rm j
j 作为滑动窗口的结尾,用来维护长度。
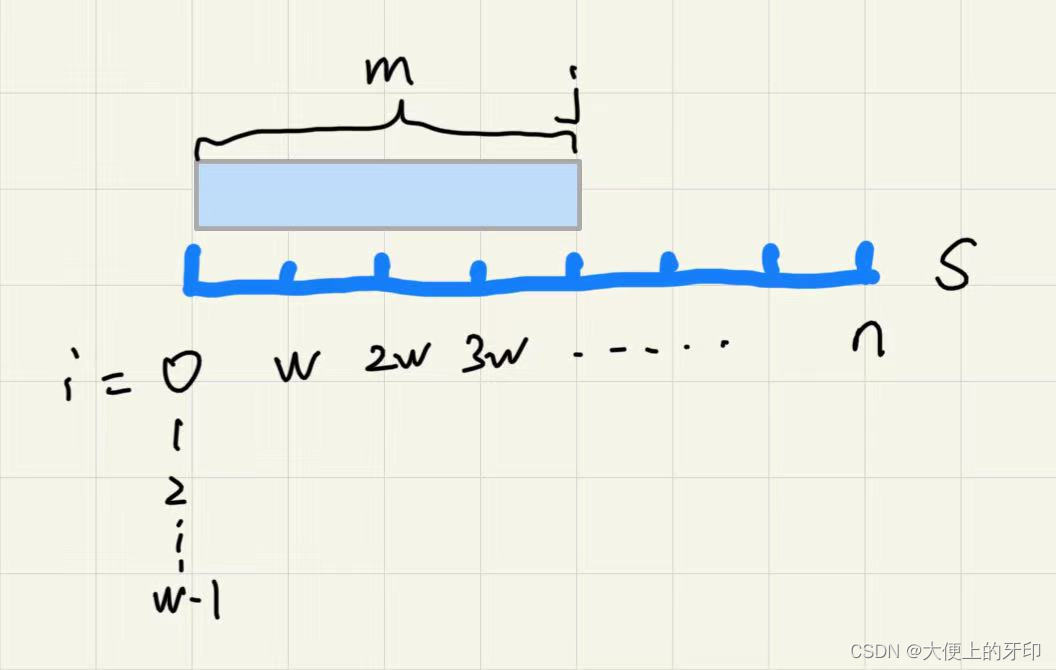
④设
m
a
p
\\rm map
map 类型的
t
o
t
\\rm tot
tot ,用来维护
w
o
r
d
s
words
words 里面的单词所对应的数量。
在每一个组中,设
m
a
p
\\rm map
map 类型的
w
d
\\rm wd
wd ,用来维护窗口内每个单词所对应的数量。
c
n
t
\\rm cnt
cnt 表示两个集合中同时存在的单词的数量
时间复杂度:
对每个视作独立元素做滑动窗口,
n
w
\\rm \\fracnw
wn 次滑动窗口移动,每次移动加一个元素,减一个元素,一共有
w
\\rm w
w 组,时间复杂度为
O
(
n
)
O(n)
O(n).
c++:
class Solution
public:
vector<int> findSubstring(string s, vector<string>& words)
vector<int> res;
if(words.empty()) return res;
int n = s.size(),m = words.size(),w = words[0].size();
unordered_map<string,int> tot;
for(auto& word : words) tot[word] ++;
for(int i = 0;i < w;i++)
int cnt = 0;
unordered_map<string,int> wd;
for(int j = i;j + w <= n;j += w)
if(j >= i + m * w)//若超出滑动窗口的长度,则将以j结尾的窗口的前一个单词排出
auto word = s.substr(j - m * w,w);
wd[word]--;
//剔除的该单词在滑动窗口集合的数量小于words里面单词的数量,说明匹配的数量减少了
if(wd[word] < tot[word]) cnt--;
auto word = s.substr(j,w);
wd[word]++;
//增加的单词在滑动窗口集合的数量增加之后依然没有超过words里单词的数量,说明满足条件的匹配的数量增加了
if(wd[word] <= tot[word]) cnt++;
if(cnt == m) res.push_back(j - (m - 1) * w);//当相应单词匹配的数量为m时,即匹配了words里所有的单词,则将滑动窗口起点加入答案。
return res;
;
算法leetcode|30. 串联所有单词的子串(rust重拳出击)
文章目录
30. 串联所有单词的子串:
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。
返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
样例 1:
输入:
s = "barfoothefoobarman", words = ["foo","bar"]
输出:
[0,9]
解释:
因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。
样例 2:
输入:
s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:
[]
解释:
因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
样例 3:
输入:
s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
输出:
[6,9,12]
解释:
因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。
子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。
子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。
提示:
- 1 <= s.length <= 104
- 1 <= words.length <= 5000
- 1 <= words[i].length <= 30
- words[i] 和 s 由小写英文字母组成
分析:
- 面对这道算法题目,二当家的陷入了沉思。
- 由于题干里罗列了所有单词可能的串联出的子串,所以可能理所当然的考虑罗列所有子串,然后再去字符串中查看是否存在,但是这样太慢了,肯定是不对的。
- 由于题干中说所有字符串 长度相同,考虑用单词计数,滑动窗口解决。
- 需要注意的一些点是,首先窗口滑动的大小应该是单词的长度才对,另外,由于窗口的大小是单词的长度,那么起始下标就需要考虑偏移。
题解:
rust
impl Solution
pub fn find_substring(s: String, words: Vec<String>) -> Vec<i32>
let mut ans = Vec::new();
let (m, n, ls) = (words.len(), words[0].len(), s.len());
for i in 0..n
if i + m * n > ls
break;
let mut differ = std::collections::HashMap::new();
for j in 0..m
let word = &s[i + j * n..i + (j + 1) * n];
*differ.entry(word).or_insert(0) += 1;
for word in words.iter()
let count = differ.entry(word).or_insert(0);
if *count == 1
differ.remove(word as &str);
else
*count -= 1;
for start in (i..ls - m * n + 1).step_by(n)
if start != i
let mut word = &s[start + (m - 1) * n..start + m * n];
let mut count = differ.entry(word).or_insert(0);
if *count == -1
differ.remove(word);
else
*count += 1;
word = &s[start - n..start];
count = differ.entry(word).or_insert(0);
if *count == 1
differ.remove(word);
else
*count -= 1;
if differ.is_empty()
ans.push(start as i32);
return ans;
go
func findSubstring(s string, words []string) (ans []int)
m, n, ls := len(words), len(words[0]), len(s)
for i := 0; i < n && i+m*n <= ls; i++
differ := map[string]int
for j := 0; j < m; j++
differ[s[i+j*n:i+(j+1)*n]]++
for _, word := range words
if differ[word] == 1
delete(differ, word)
else
differ[word]--
for start := i; start < ls-m*n+1; start += n
if start != i
word := s[start+(m-1)*n : start+m*n]
if differ[word] == -1
delete(differ, word)
else
differ[word]++
word = s[start-n : start]
if differ[word] == 1
delete(differ, word)
else
differ[word]--
if len(differ) == 0
ans = append(ans, start)
return
c++
class Solution
public:
vector<int> findSubstring(string s, vector<string>& words)
vector<int> ans;
int m = words.size(), n = words[0].size(), ls = s.size();
for (int i = 0; i < n && i + m * n <= ls; ++i)
unordered_map<string, int> differ;
for (int j = 0; j < m; ++j)
++differ[s.substr(i + j * n, n)];
for (string &word: words)
if (--differ[word] == 0)
differ.erase(word);
for (int start = i; start < ls - m * n + 1; start += n)
if (start != i)
string word = s.substr(start + (m - 1) * n, n);
if (++differ[word] == 0)
differ.erase(word);
word = s.substr(start - n, n);
if (--differ[word] == 0)
differ.erase(word);
if (differ.empty())
ans.emplace_back(start);
return ans;
;
python
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
ans = []
m, n, ls = len(words), len(words[0]), len(s)
for i in range(n):
if i + m * n > ls:
break
differ = Counter()
for j in range(m):
word = s[i + j * n: i + (j + 1) * n]
differ[word] += 1
for word in words:
if differ[word] == 1:
del differ[word]
else:
differ[word] -= 1
for start in range(i, ls - m * n + 1, n):
if start != i:
word = s[start + (m - 1) * n: start + m * n]
if differ[word] == -1:
del differ[word]
else:
differ[word] += 1
word = s[start - n: start]
if differ[word] == 1:
del differ[word]
else:
differ[word] -= 1
if len(differ) == 0:
ans.append(start)
return ans
java
class Solution
public List<Integer> findSubstring(String s, String[] words)
List<Integer> ans = new ArrayList<Integer>();
int m = words.length, n = words[0].length(), ls = s.length();
for (int i = 0; i < n && i + m * n <= ls; ++i)
Map<String, Integer> differ = new HashMap<String, Integer>();
for (int j = 0; j < m; ++j)
String word = s.substring(i + j * n, i + (j + 1) * n);
differ.put(word, differ.getOrDefault(word, 0) + 1);
for (String word : words)
differ.put(word, differ.getOrDefault(word, 0) - 1);
if (differ.get(word) == 0)
differ.remove(word);
for (int start = i; start < ls - m * n + 1; start += n)
if (start != i)
String word = s.substring(start + (m - 1) * n, start + m * n);
differ.put(word, differ.getOrDefault(word, 0) + 1);
if (differ.get(word) == 0)
differ.remove(word);
word = s.substring(start - n, start);
differ.put(word, differ.getOrDefault(word, 0) - 1);
if (differ.get(word) == 0)
differ.remove(word);
if (differ.isEmpty())
ans.add(start);
return ans;
非常感谢你阅读本文~
欢迎【点赞】【收藏】【评论】~
放弃不难,但坚持一定很酷~
希望我们大家都能每天进步一点点~
本文由 二当家的白帽子:https://le-yi.blog.csdn.net/ 博客原创~
以上是关于力扣:串联所有单词的子串(滑动窗口+哈希)的主要内容,如果未能解决你的问题,请参考以下文章