arcpy模块中的SearchCursor读取shp的属性表,然后怎么提取出具体的值并且赋值给别的变量呢?我提取不出来
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了arcpy模块中的SearchCursor读取shp的属性表,然后怎么提取出具体的值并且赋值给别的变量呢?我提取不出来相关的知识,希望对你有一定的参考价值。
可以,如果arcgis是10版本,可以用arcpy模块中的SearchCursor读取shp的属性表;用python读写excel需要安装pythonWin或者安装comtypes都可以,你可以上网找一下这样的资料。 参考技术A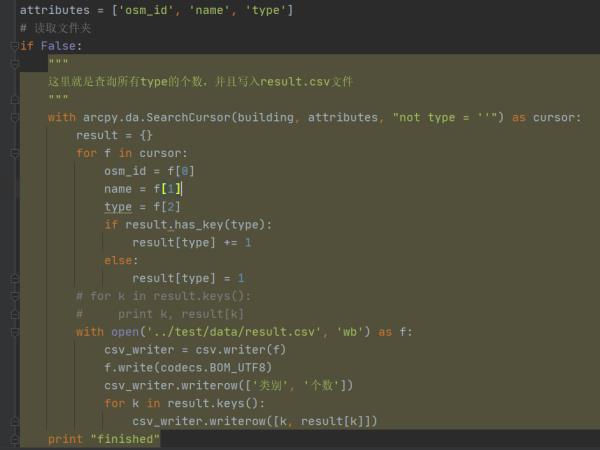
看图
参考技术B 请问你解决了吗arcpy模块下的并行计算与大规模数据处理
一个多星期的时间,忍着胃痛一直在做GIS 540: Spatial Programming的课程项目,导致其他方面均毫无进展,可惜可惜。在这个过程当中临时抱佛脚学习了很多Python相关的其他内容,并应用在这次的项目当中(虽然大部分的尝试都失败了,也有不少问题需要之后寻求解决的方法)。在此稍微总结下这几天写代码的心得。
项目背景
这次的项目主要是基于Python 2.7版本下的arcpy模块,调用其中的相关工具进行一系列的空间操作与数值计算,具体的内容则不便于在此透露。由于计算量过于庞大,因此尝试着采用了multiprocessing模块来进行多进程编程以加快计算速度。当然,主要也是为了便于调用工作站当中的多核资源。其他部分,os, sys, time模块也均有使用,用以辅助相关的路径获取和计时。工作环境为Windows 10,采用Spyder作为编辑器,ArcGIS的版本为Desktop 10.5.1。
Python多进程计算
在项目当中所遇到的一个很大的问题就是基于Table的数据计算量太过于庞大,而Python的计算速度也是惨不忍睹。(其实是想着用其他语言来做的,无奈临时抱佛脚嘛,哎)由于整个的计算过程当中有着非常多的重复的部分,故而考虑采用多进程、多线程的方法来提高计算速度。Python当中的多线程由于全局解释锁GIL(Global Intepreter Lock)的存在,其对于编程效率的提升并不是很明显,因此这里仅仅涉及使用多进程的方法对原有的计算函数进行重构。有关于进程和线程的概念在这里便不多涉及(其实我自己也得复习下操作系统了,本科大三学的都忘得差不多了)。
另外补充一点,就是对于采用多进程多线程编程必要性的判断。我记得有博客做过相应的分析,其结果是多进程对于计算密集型的任务效率提升较大,而多线程则是比较适用于I/O密集型的任务。
首先,抽象描述一个在我的项目当中较为典型的任务场景:
Table A 当中有一个Field称为NumA,对于Table A当中每个对象的NumA均不相同。现在对于A当中的每一行(对应一个空间对象),从Table B当中选取在该行对象附近一定范围内的所有行,并对Table B当中选中的行对应的Field B的值添加上A当中该对象的值。其抽象的代码表述如下:
for i in Table A:
Select rows in Table B by i
for j in rows:
j[NumB] += i[NumA]
看似是很简单的内容,但当Table A和Table B均有上万行的时候,其计算所耗费的时间便难以想象(或者按照算法当中的理论,这里的时间复杂度是O(mn),m和n分别是单个外循环任务和内循环任务所对应的时间,而且因为主要是读写任务,没法通过算法设计来对其进行改进,心酸)。而Select这个步骤因为其基于位置进行选择的特性,在arcpy当中也是颇耗费时间的一个函数,这更加增大的计算时候的开销(这将在之后进一步描述)。这里由于Select是针对于某一个表当中的各个不同的对象进行读取操作,故而我们可以考虑为这一步骤开设多个进程以提高效率。
Python 2.7当中自带的multiprocessing模块可以提供已经封装好的多进程操作对象与函数,包括Process(进程对象),Queue(进程序列),Pool(进程池)等内容。方便起见,这里我们直接使用进程池来完成多进程计算,其基本的计算框架可以按照以下的内容来进行填充:
import multiprocessing
def CalcFunc(i, j, k):
....
return ....
if __name__ == ‘__main__‘:
# 获取CPU核数
n = multiprocessing.cpu_count()
# 创建进程池
# 实际应用当中未必需要用满CPU所有核,建议大家自己选择,建设Pool时如果不加processes参数则默认为使用所有核
MyPool = multiprocessing.Pool(processes = n)
# 设置固定的函数输入变量
j = ....
k = ....
# 设置需要变化的函数输入变量,将其封装为List
List = [....]
# 设置List用来存储每个函数运行所得到的结果
Result = []
# 向进程池内装入所有需要并行执行的函数,并将结果添加到Result当中
for item in List:
u = MyPool.apply_async(CalcFunc, (item, j, k, ))
Result.append(u)
# 关闭进程池,使得进程池无法再添加新的任务
MyPool.close()
# 阻塞当前进程,并执行MyPool所定义的进程,待其执行完之后再回到当前进程
MyPool.join()
# 获取结果,此处仅打印结果
for i in Result:
print i.get()
(提及一个坑了自己的地方,有次写测试代码的时候图方便便将某个函数的定义写在了main函数当中,结果多进程运行的时候直接导致了Antimalware Service Executable进程高负荷运转并使得代码不再执行,关于产生这个错误的原因有待进一步探究,应该是和Windows Defender的保护机制有关系)
可以看到,这里使用了List来封装每个单独运行的函数所对应的参数,使用for循环分配参数并将任务一个个地添加到进程池当中。通过所创建的Pool对象当中的apply_async将所需要运行的内容非阻塞地添加到进程池当中,而后关闭进程池,并阻塞当前进程运行等待进程池当中的进程运行完毕。要注意的是通过apply_async所返回的是进程执行完毕所对应的ApplyResult对象,即使进程未能够成功执行,该对象一样能够成功返回。对于ApplyResult对象,需要使用get()函数来获取该进程当中函数运行所返回的结果。
在apply_async之外有多种办法可以实现使用进程池进行多进程计算,包括apply、map和map_async。其中apply的用法与apply_async类似,其区别仅在于apply函数的执行为非阻塞式(对于进程池当中的所有子进程按照序列执行,这样的话和单进程串行执行的区别不大,具体的区别可以参见 [1])而关于map和map_async的用法则参见以下的模板,仅需要改变向进程池添加任务的方式以及获取结果的方式。
import multiprocessing
....
if __name__ == ‘__main__‘:
....
# 将每次所要输入的参数封装在一个List当中,再将这个List添加到ParameterList内
ParameterList = []
for i in List:
ParameterList.append([i, j, k])
....
# 直接调用map或者map_async函数将所有的任务添加到进程池
Result = MyPool.map(CalcFunc, ParameterList)
....
# 获取结果不再需要调用get()函数
for i in Result:
print i
采用map或者map_async可以通过包含参数的List直接一次将所有需要执行的任务添加到进程池当中,而且map和map_async均和apply_async一样允许并发,其区别仅在于Blocking,详细的介绍可以参看[2]。
需要额外提及的两点是对于Lock和callback的使用。Lock的使用是为了保证某个被进程所占据的资源/文件在该进程运行期间不被其他的进程所改写。对于ArcGIS相关的文件,arcpy当中的函数在运行时会对于不支持共享方式访问的数据资源设置文件独占锁(有关文件独占锁的详细信息参见 [3]),但考虑到很多地理信息处理过程当中也会涉及到大量的其他文件类型的操作(比如csv或者kml文件),故而设置lock也是很有必要的。
添加lock的函数改写方式可以参看以下模板代码:
import multiprocessing
# 改写CalcFunc,使其在lock的状态下运行
def CalcFunc(i, j, k, lock):
with lock:
....
return ....
if __name__ == ‘__main__‘:
....
# 在main函数当中定义lock对象
lock = multiprocessing.Manager().Lock()
....
# 向进程池添加任务时时将lock也传入其中
for item in List:
u = MyPool.apply_async(CalcFunc, (item, j, k, lock, ))
Result.append(u)
....
而callback则是对于多进程运行的各个任务的结果的一个简单的处理方式,比如你要将所有的运行结果添加到Result这个List当中,则可以将callback设置为Result.append。在这里map和apply的区别将直接体现:map所返回的结果序列即为添加所需要执行任务的序列,而apply则是每当一个进程执行完成的时候便返回结果,其所获得的结果序列并不能够对应添加执行任务的序列。设置callback的示例如下:
MyPool.apply_async(CalcFunc, (item, j, k, lock, ), callback = Result.append)
MyPool.Map(CalcFunc, ParameterList, callback = Result.append)
使用以上的进程池方法设置可以有效地缩短计算时间。对于项目当中的某个模块,在工作站的开发环境当中进行了计算测试。在采用多进程后,总的计算时间由50分钟缩短到了4分钟,算是值得庆幸的一件事吧。(虽然这样也掩盖不了最终开发失败的事实)
arcpy大规模数据处理
以上所述的多进程计算方法能够在一定程度上提升了程序运行效率,但是对于大规模数据的读写与计算,其提升主要是在“计算”这一块,而对于“读写”则提升效果有限,因为读写(I/O)的瓶颈主要不在CPU,而在于硬盘。为了能够进一步地提升数据处理的效率,在使用多进程的同时还需要考虑一些其他的方法。
假设对于需要执行的任务,需要对于某一部分数据进行反复的读取操作,那么可以考虑使用使用ArcGIS当中的“内存工作空间”来进行优化。“内存工作空间”是一个可用于写入输出要素类和表的基于操作系统内存的工作空间 [4]。由于该部分存储于内存当中,故而对其进行读写操作的速度要显著地高于对存储于硬盘当中的文件进行读写操作的速度。当然要注意的一点是该部分的数据一定要在使用完毕后进行删除,以免在程序的运行当中占据额外的内存。
以下是对于某个batch processing使用内存工作空间进行优化的示例。
import arcpy
# 未使用内存工作空间的代码
arcpy.Buffer_analysis(‘Raw Point.shp‘, ‘Buffered Point.shp‘, ‘10 Miles‘)
arcpy.Clip_analysis(‘Polyline1.shp‘, ‘Buffered Point.shp‘, ‘Cliped Polyline1.shp‘)
arcpy.Clip_analysis(‘Polyline2.shp‘, ‘Buffered Point.shp‘, ‘Cliped Polyline2.shp‘)
# 使用内存工作空间优化后的代码,最后一步用于删除内存工作空间当中的临时文件
arcpy.Buffer_analysis(‘Raw Point.shp‘,‘in_memory/BufferedPoint‘, ‘10 Miles‘)
arcpy.Clip_analysis(‘Polyline1.shp‘, ‘in_memory/BufferedPoint‘, ‘Cliped Polyline1.shp‘)
arcpy.Clip_analysis(‘Polyline2.shp‘, ‘in_memory/BufferedPoint‘, ‘Cliped Polyline2.shp‘)
arcpy.Delete_management(‘in_memory/BufferedPoint‘)
在函数当中遇到这样类似的过程,均可以尝试对于需要反复读取的文件进行上述的处理,将其转移到内存工作空间。其他的一些方法也具有类似的思想,比如对于需要选择一个文件当中特定的几个feature的时候,相比于使用arcpy.Select_analysis生成一个新的文件,一般会更加倾向于使用arcpy.MakeFeatureLayer_management来生成一个图层,在其中的where_clause写入SQL语句以实现相同的选择效果。后者基于原始文件生成一个临时的子图层,该图层若不经保存,则在应用程序运行结束之后被清理掉。而事实上,使用图层一般还有另外一层考虑:arcpy当中用于基于位置进行选择的函数SelectLayerByLocation_management所针对的对象只能是Feature Layer。
然而ArcGIS当中一个很坑爹的问题在于其对于personal geodatabase的大小限制为2GB。这在一般情况下或许够用,但是在遇上需要储存庞大的临时文件的时候,则显得有些捉襟见肘。(在这里撞过一次坑,结果是导致了ERROR 000426: Out of memory)一个处理办法是使用ArcGIS所提供的切分工具将所需要处理的要素细分为较小的要素 [5],然后对这些细分的要素分开进行处理。在此之外,其他的处理方法不外乎将部分要素使用内存空间进行储存和及时删除不必要的临时文件。
或者再换一种思路,我们可以尝试更换存储数据的方式。以最初提到的任务场景为例,我们并不一定非要在任务序列当中将值写入到最终的文件当中,而是可以在循环之外创建一个数组,数组的index对应最终文件的FID,数组当中的值对应所要写入的值。(或者使用dictionary,可以做到更高的识别性)这样,将写入的步骤放在最后一起处理,不仅有利于多进程的执行,而且也能避免生成不必要的临时图层。
以下贴出一部分在项目当中所用的代码和改进后的代码,可以作为今后用于修改代码的参考。
改进前:
import arcpy
def CalcFunc(Route, Lines):
CountLine = int(arcpy.GetCount_management(Lines).getOutput(0))
arcpy.MakeFeatureLayer_management(Routes, ‘TempRouteLyr‘)
for i in CountLine:
arcpy.MakeFeatureLayer_management(Lines, ‘TempLineLyr‘, ‘"FID" = {0}‘.format(str(i)))
sc = arcpy.da.SearchCursor(‘TempLineLyr‘, [ ‘IMPACT‘ ]
TempImpact = sc.next()[0]
del sc
Selection = arcpy.SelectLayerByLocation_management(‘TempRouteLyr‘, ‘WITHIN_A_DISTANCE‘, ‘TempLineLyr‘, ‘10 Miles‘, ‘NEW_SELECTION‘)
uc = arcpy.da.UpdateCursor(Selection, [ ‘IMPACT_SUM‘ ])
for row in uc:
row[0] += TempImpact
uc.updateRow(row)
del uc
if __name__ == ‘__main__‘:
arcpy.env.workspace = ....
arcpy.Buffer_analysis(‘Plant.shp‘, ‘PlantBuffer.shp‘, ‘78 Miles‘)
arcpy.Clip_analysis(‘Routes.shp‘, ‘PlantBuffer.shp‘, ‘RoutesClip.shp‘)
arcpy.Select_analysis(‘RoutesClip.shp‘, ‘RoutesSelect.shp‘, ‘"CLASS" >= ‘3‘‘)
CalcFunc(‘RoutesSelect.shp‘, ‘Lines.shp‘)
改进后:
import arcpy, multiprocessing
def CalcFunc(Routes, Lines, i):
arcpy.MakeFeatureLayer_management(Routes, ‘TempRouteLyr‘)
arcpy.MakeFeatureLayer_management(Lines, ‘TempLineLyr‘, ‘"FID" = {0}‘.format(str(i)))
sc = arcpy.da.SearchCursor(‘TempLineLyr‘, [ ‘IMPACT‘ ]
TempImpact = sc.next()[0]
del sc
Selection = arcpy.SelectLayerByLocation_management(‘TempRouteLyr‘, ‘WITHIN_A_DISTANCE‘, ‘TempLineLyr‘, ‘10 Miles‘, ‘NEW_SELECTION‘)
ImpactList = [ 0.0 for item in range(int(arcpy.GetCount_management(Routes).getOutput(0))) ]
sc = arcpy.da.UpdateCursor(Selection, [ ‘FID‘ ])
for row in sc:
ImpactList[row[0]] = TempImpact
del sc
return ImpactList
if __name__ == ‘__main__‘:
arcpy.env.workspace = ....
arcpy.Buffer_analysis(‘Plant.shp‘, ‘in_memory/PlantBuffer‘, ‘78 Miles‘)
arcpy.Clip_analysis(‘Routes.shp‘, ‘in_memory/PlantBuffer‘, ‘in_memory/RouteClip‘)
arcpy.Select_analysis(‘in_memory/RouteClip‘, ‘RoutesSelect.shp‘, ‘"CLASS" >= ‘3‘‘)
arcpy.Delete_management([ ‘in_memory/PlantBuffer‘, ‘in_memory/RouteClip‘ ])
MyPool = multiprocessing.Pool(processes = 4)
CountLine = int(arcpy.GetCount_management(‘Lines.shp‘).getOutput(0))
TotalImpact = [ 0.0 for item in range(int(arcpy.GetCount_management(Routes).getOutput(0))) ]
ResultsList = []
for i in range(CountLine):
MyPool.apply_async(CalcFunc, (‘RouteSelect.shp‘, ‘Lines.shp‘, i)
ResultsList.append(u)
MyPool.close()
MyPool.join()
for resultitem in ResultsList:
for idx, i in enumerate(resultitem.get()):
TotalImpact[idx] += i
uc = arcpy.da.UpdateCursor(