Linux一文带你探究网络世界的基石
Posted 阿亮joy.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux一文带你探究网络世界的基石相关的知识,希望对你有一定的参考价值。
🌠 作者:@阿亮joy.
🎆专栏:《学会Linux》
🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根

目录
👉计算机网络背景👈
网络发展
计算机网络的发展可以追溯到20世纪60年代,那时候最初的计算机网络只是为了让科学家们能够共享计算机资源和数据。但是在20世纪80年代,互联网的出现彻底改变了计算机网络的面貌,使得人们可以随时随地通过互联网进行信息交流和数据共享。
随着计算机技术的不断发展,网络技术也在不断创新和改进。在20世纪90年代,出现了无线网络技术,这让人们可以不受线缆限制地随时随地上网。随后,移动互联网的出现进一步推动了网络技术的发展,现在人们已经可以通过手机、平板电脑和其他移动设备随时随地访问网络。
此外,云计算和大数据技术的出现也为网络技术的发展带来了新的机遇。云计算可以让人们通过网络访问存储在远程服务器上的计算资源,而大数据技术则可以让人们更好地管理、分析和利用海量数据。
在未来,随着物联网、人工智能等新兴技术的不断发展,计算机网络技术将会更加智能化、自动化和普及化,为人们的生活和工作带来更多的便利和创新。
局域网和广域网
- 独立模式:计算机之间相互独立。

- 网络互联:多台计算机连接在一起,完成数据共享。
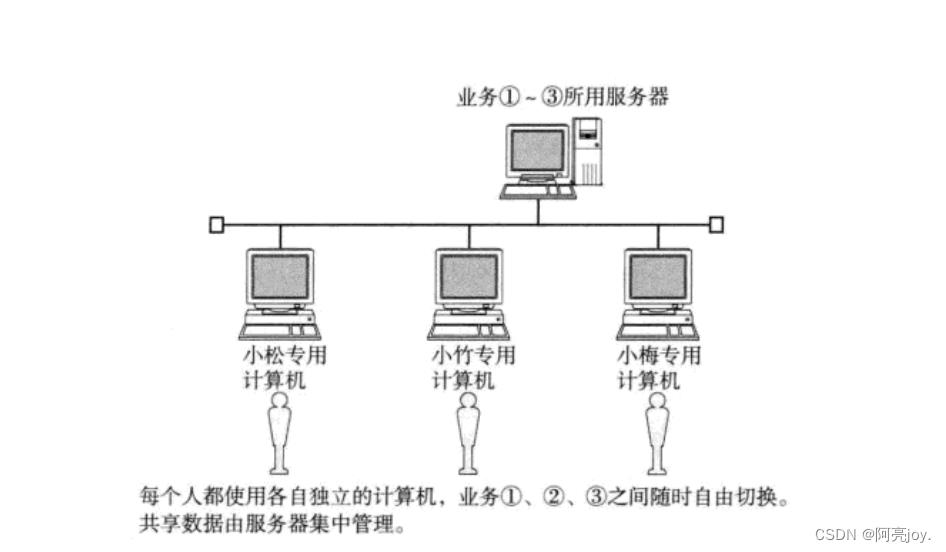
局域网(Local Area Network,LAN)和广域网(Wide Area Network,WAN)是两种常见的计算机网络类型。
局域网是一种较小范围内的网络,通常是在办公室、学校、住宅区等局部范围内使用。局域网中的计算机通常是通过同一网络设备(比如路由器或交换机)连接在一起,以便在这些计算机之间共享文件、打印机、应用程序和其他网络资源。在局域网中,通常不需要经过互联网,因为所有计算机都连接在同一网络中。
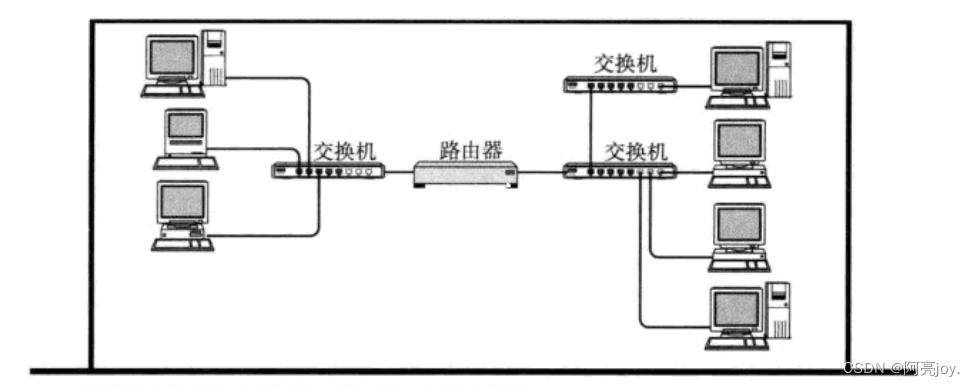
而广域网则是一种更大范围的网络,可以涵盖更广泛的地域范围。广域网通常由多个局域网和其他网络连接而成,通过广域网的互联,计算机和其他网络设备可以在全球范围内相互通信和交流。广域网通常使用互联网协议(IP)连接各种计算机和网络设备,而且通常需要使用专门的路由器、交换机、光纤和其他网络设备来连接这些不同的局域网和其他网络。
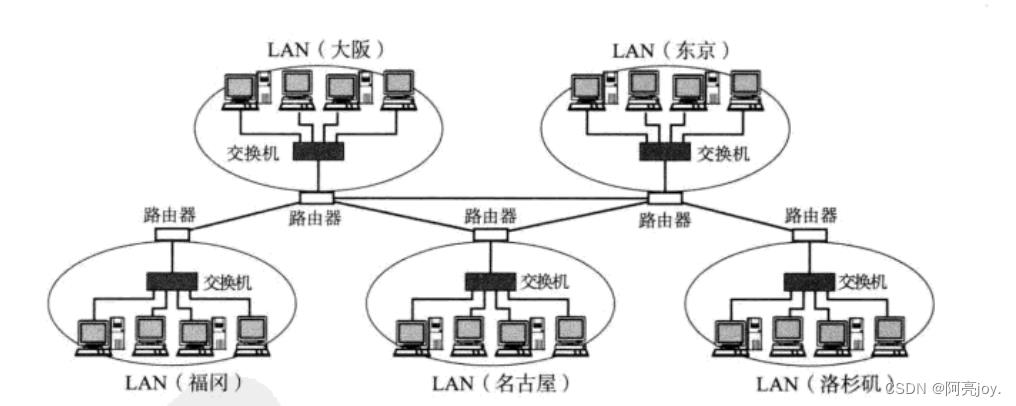
所谓局域网和广域网只是一个相对的概念,比如:我们有 “天朝特色” 的广域网,也可以看做一个比较大的局域网。总的来说,局域网主要用于小规模内部的文件共享和资源访问,而广域网则更适合大规模的远程访问和通信。
那么网络是由谁搭建起来的呢?
我们国家的网络是由多个机构和企业共同建设和维护的。中国的互联网基础设施主要由国家电信运营商中国电信、中国移动和中国联通等企业负责建设和维护。这些企业拥有全国性的网络覆盖,包括光纤、卫星、无线等多种传输方式,通过这些传输方式,连接了全国各地的用户和服务提供商。
除了这些运营商外,我们的政府也参与了互联网的建设和管理。我国的互联网管理机构包括了国家互联网信息办公室、工业和信息化部、公安部等,他们负责颁布和执行相关的互联网管理法规和政策,维护互联网安全和稳定,并监管和管理互联网的内容和使用行为。
总的来说,我国的网络是由政府、企业和其他机构共同建设和维护的。这些机构通过各自的专业领域和职责,合作构建了一个覆盖全国的互联网基础设施和服务体系。
👉网络协议初识👈
什么是协议
在计算机网络中,协议是计算机网络中各种设备之间通信的规则和标准。它们定义了不同类型的计算机、服务器、路由器、交换机等设备之间如何进行通信、交换数据和控制信息的方式。通俗来说,协议就是一种约定。协议在计算机网络中扮演着重要的角色,使得不同设备之间的通信更加高效、安全和可靠。

计算机之间的传输媒介是光信号和电信号。通过频率和强弱来表示 0 和 1 这样的信息,要想传递各种不同的信息,就需要约定好双方的数据格式。进行通信的两台主机,并不是在软件层面上约定协议就可以了。计算机硬件厂商用不同的方式来表示 0 和 1(不同的硬件标准),两台不同厂商的主机也无法进行通信,即使它们遵守同样的约定。这时候就需要一个统一的标准,这就是网络协议。
协议分层
操作系统内是存在多种协议的,那么操作系统需要通过先描述再组织的方式来管理这些协议。
协议的本质就是软件,软件是可以进行分层的。比如:Linux 下一切皆文件,将所有的设备、文件、目录以及进程等都被视为文件(struct file 对象),struct file 对象中包含函数指针,指向不同的方法,这就实现了软件分层。
那什么是协议分层呢?协议分层是指将一个复杂的通信系统划分为多个层次,每个层次都有不同的功能和责任,协议在不同的层次之间进行交互和通信。协议分层的优势就是在复杂的场景下,它可以使不同层次之间的功能独立(解耦),提高了系统的可维护性、可扩展性和可靠性,同时也为不同厂家的设备之间的通信提供了标准化的接口。所以,网络协议也是被设计成了层状结构。

在打电话这个例子中,我们的协议只有两层:但是实际的网络通信会更加复杂,需要分更多的层次。
通信场景的复杂性,是和通信的距离成正相关的,那么协议栈就要解决通行过程中的应用范畴和通信范畴中的问题。应用范畴包括应用层,通信范畴包括传输层、网络层、数据链路层和物理层。
- 应用层:应用层是最上层的协议层,负责应用程序之间的通信(如何处理数据)。在这个层次上,各种应用程序可以使用标准协议进行数据交换,如HTTP、SMTP、FTP等。
- 传输层:传输层负责数据传输的可靠性和流量控制(丢包问题)。在这个层次上,TCP和UDP是两个最常见的协议,TCP是一种可靠的面向连接的协议,而UDP则是一种无连接的协议。
- 网络层:网络层负责网络地址的定义和路由选择(定位问题)。在这个层次上,常用的协议有IP和ICMP,IP协议负责将数据包从源地址传输到目的地址,而ICMP协议则用于检测和报告网络错误。
- 数据链路层:它主要负责将物理层提供的原始比特流转换为帧(Frame),并进行传输控制和帧同步等操作。数据链路层的主要作用是将数据包分割成较小的单元进行传输,同时确保这些数据单元在链路中的可靠传输和错误检测。数据链路层的典型协议有以太网(Ethernet)和无线局域网(WiFi)等。
- 物理层是计算机网络中的最底层,它负责传输比特流,并将其转换为物理信号。物理层的主要作用是定义传输介质、传输速率、信号编码方式等,以及实现数据的传输和同步。物理层的典型协议有RS-232、V.35等,以及传输介质如光纤、电缆等。
- 数据链路层和物理层共同构成了计算机网络的物理传输层,负责将数据从一个网络节点传输到另一个节点。
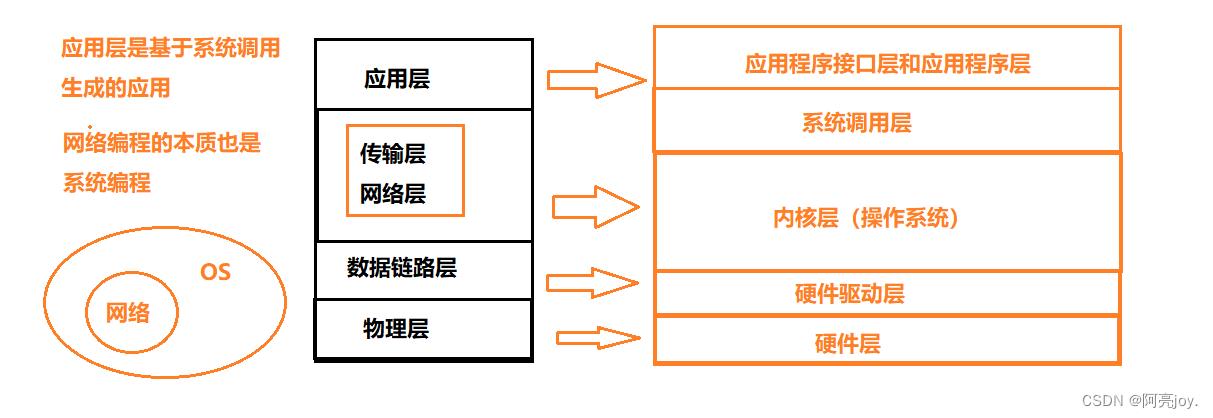



OSI七层模型
OSI七层模型(Open Systems Interconnection reference model,开放式系统互联参考模型)是一个标准的网络体系结构模型,它将网络通信分为七个抽象层,每个层都有自己的功能和特定的协议,它们一起构成了一个完整的网络协议体系结构。它的最大优点是将服务、接口和协议这三个概念明确地区分开来,概念清楚,理论也比较完整. 通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯。
下面是每个层的功能和代表的协议:
-
物理层(Physical Layer):负责在物理媒介上传输比特流(0和1)。代表的协议包括 Ethernet、Wi-Fi、USB 等。
-
数据链路层(Data Link Layer):负责在相邻节点间传输数据帧,并保证传输的数据可靠、有序、无差错。代表的协议包括 PPP、HDLC、MAC 等。
-
网络层(Network Layer):负责在多个节点之间建立逻辑连接,并将数据分组传输。代表的协议包括 IP、ICMP、ARP 等。
-
传输层(Transport Layer):负责在端到端的通信中提供可靠的数据传输和错误恢复。代表的协议包括 TCP、UDP 等。
-
会话层(Session Layer):负责建立、管理和终止会话连接。代表的协议包括 SMB、NFS 等。
-
表示层(Presentation Layer):负责对数据进行格式化和转换,确保数据在传输过程中的兼容性。代表的协议包括 JPEG、MPEG 等。
-
应用层(Application Layer):提供面向用户的应用服务,使用户可以访问网络上的各种资源。代表的协议包括 HTTP、FTP、SMTP、SSH 等。
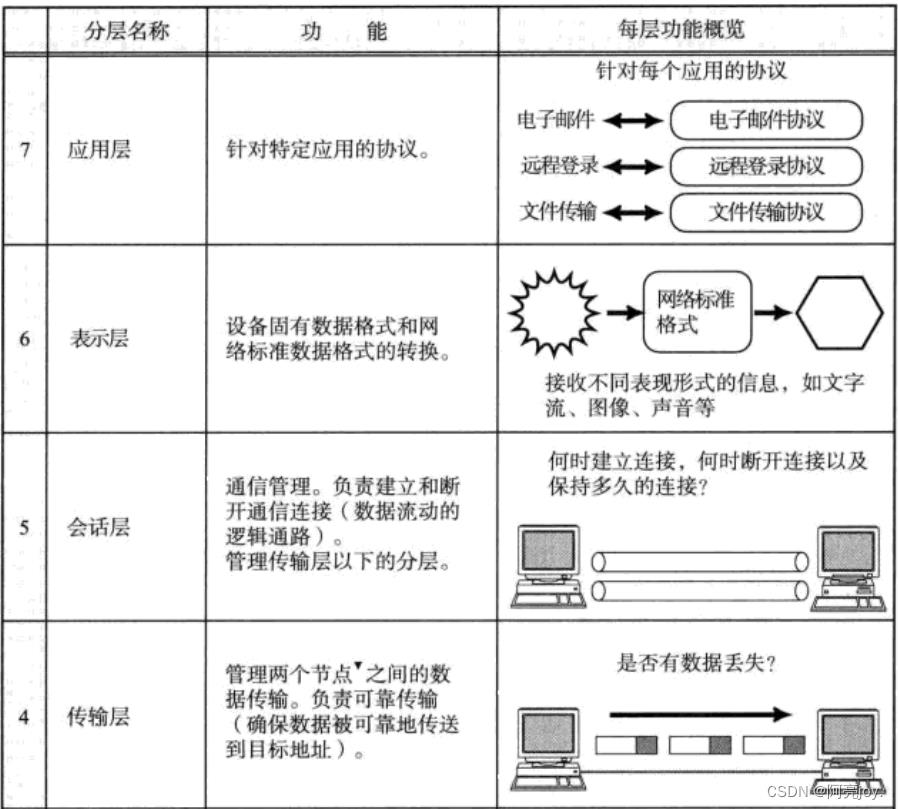
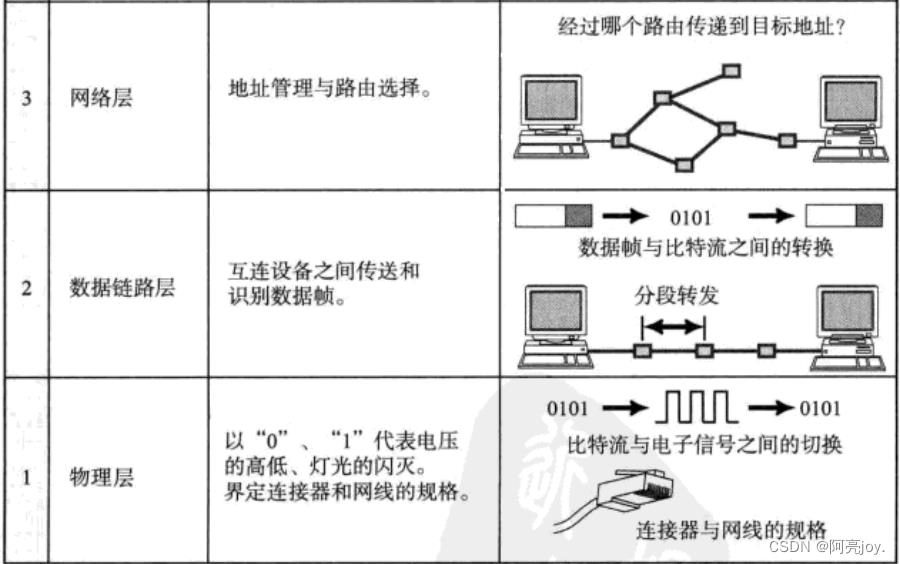
TCP / IP五层模型
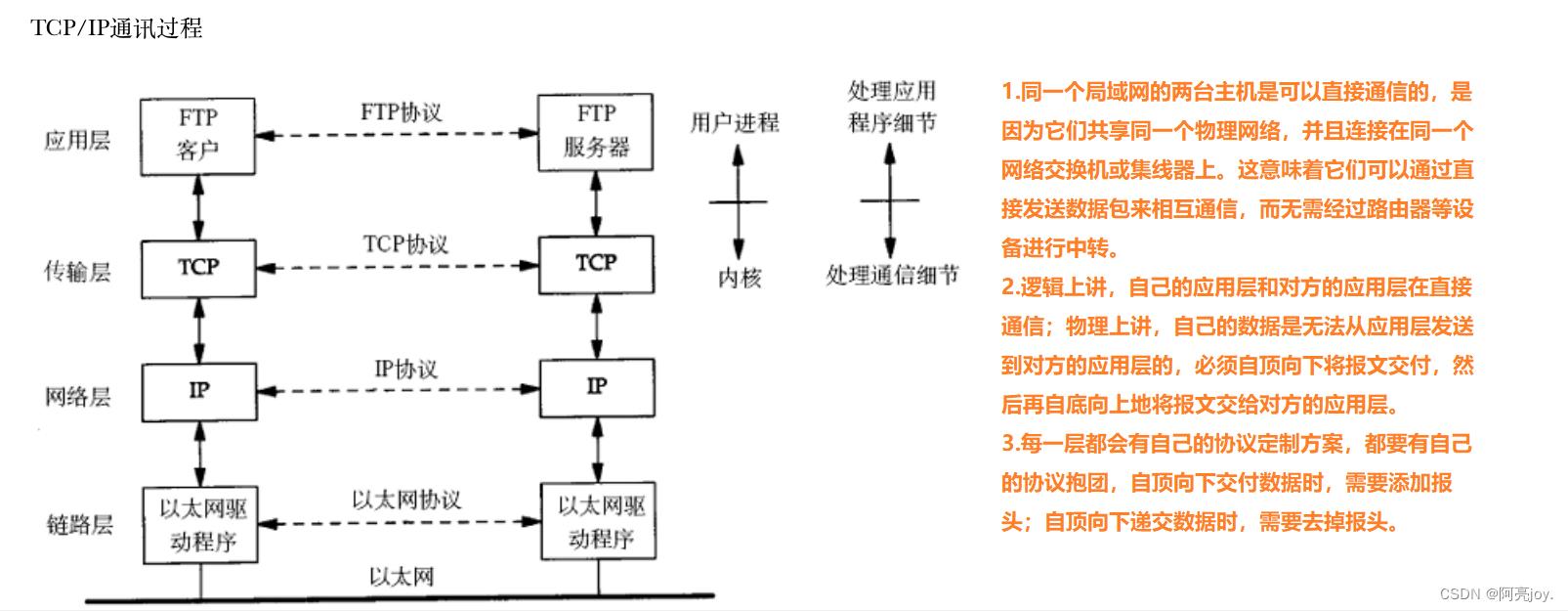
TCP / IP 是一组协议的代名词,它还包括许多协议,组成了 TCP / IP 协议族。TCP / IP 通讯协议采用了 5 层的层级结果,每一层都呼叫它的下一层所提供的网络来完成自己的需求。
- 物理层:负责光/电信号的传递方式. 比如现在以太网通用的网线(双绞线)、早期以太网采用的的同轴电缆(现在主要用于有线电视)、光纤,现在的 WIFI 无线网使用电磁波等都属于物理层的概念。物理层的能力决定了最大传输速率、传输距离、抗干扰性等。集线器(Hub)工作在物理层,它通过物理层的广播方式来转发数据包。当一个计算机需要向另一个计算机发送数据时,它会将数据包发送给集线器,集线器会将这个数据包广播到所有连接到它的端口上。这样,所有连接到集线器上的计算机都能够收到这个数据包,并根据目标 MAC 地址来判断是否接收该数据包。
- 数据链路层:负责设备之间的数据帧的传送和识别。例如网卡设备的驱动、帧同步(就是说从网线上检测到什么信号算作新帧的开始)、冲突检测(如果检测到冲突就自动发)、数据差错校验等工作,有以太网、令牌环网,无线LAN等标准。交换机(Switch)工作在数据链路层,它能够分析数据包的 MAC 地址,并根据 MAC 地址来确定数据包应该发送到哪个端口。当一个计算机需要向另一个计算机发送数据时,它会将数据包发送给交换机,交换机会根据目标 MAC 地址来确定该数据包应该发送到哪个端口。这样,只有目标计算机会接收到这个数据包,而其他计算机则不会收到。
- 网络层:负责地址管理和路由选择,例如在 IP 协议中,通过 IP 地址来标识一台主机,并通过路由表的方式规划出两台主机之间的数据传输的线路(路由),路由器(Router)工作在网路层,它能够分析数据包的 IP 地址,并根据 IP 地址来确定数据包应该转发到哪个网络中。当一个计算机需要向另一个网络中的计算机发送数据时,它会将数据包发送给路由器,路由器会根据目标IP地址来确定该数据包应该转发到哪个网络中。这样,不同网络之间的计算机就能够相互通信了。
- 传输层:负责两台主机之间的数据传输,如传输控制协议 (TCP)能够确保数据可靠的从源主机发送到目标主机。
- 应用层: 负责应用程序间沟通,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等,我们的网络编程主要就是针对应用层。

物理层我们考虑的比较少,因此 TCP / IP 五层模型很多时候也可以称为 TCP / IP 四层模型。
一般而言,对于一台主机,它的操作系统内核实现了从传输层到网络层的内容;对于一台路由器,它实现了从网络层到物理层;对于一台交换机,它实现了从数据链路层到物理层;对于集线器,它只实现了物理层。但是并不绝对. 很多交换机也实现了网络层的转发,很多路由器也实现了部分传输层的内容(比如端口转发)。
👉网络传输基本流程👈
局域网通信原理
在同一个局域网中,每个主机都有一个唯一的 MAC 地址(48 位的二进制数,通常用 16 进制表示),这是通过网卡硬件设备分配的。当一台主机要向另一台主机发送数据时,它会将数据包打上目标 MAC 地址并广播到整个网络中,所有连接在该网络上的主机都会接收到这个数据包,但只有目标 MAC 地址与自己的 MAC 地址相匹配的主机才会处理这个数据包。这样,数据包就能够直接传输到目标主机,从而实现两台主机之间的直接通信。
在局域网中,多个主机共享同一个物理网络,因此当多个主机同时发送数据时,可能会发生数据碰撞(Collision)的情况。这是因为多个主机的信号可能会同时到达同一个物理介质上,导致信号相互干扰,从而导致数据错误和丢失。
数据碰撞问题是由于共享介质的特点所导致的。在以太网中,多个主机连接在同一段电缆上,数据包被广播到整个网络中。如果两个或更多的主机同时发送数据包,它们的信号可能会在电缆上碰撞,从而导致数据包损坏或丢失。
为了解决数据碰撞的问题,以太网采用了 CSMA / CD 协议。CSMA / CD 协议意味着 “带冲突检测的载波侦听多路访问”,它规定了当主机要发送数据时,需要先侦听介质上是否有其他主机正在发送数据。如果介质上有信号,主机就会等待一段随机时间后再发送数据。如果多个主机同时发送数据,会发生碰撞,这时所有的主机都会检测到冲突,并停止发送数据。接着,每个主机会等待一段随机时间后再次尝试发送数据,直到成功为止。
除了 CSMA / CD 协议,局域网还可以采用其他方法来解决数据碰撞问题,如使用交换机或使用全双工通信等技术。
数据包封装和分用
什么是协议报头?它有什么作用?

- 不同的协议层对数据包有不同的称谓,在传输层叫做段(segment)在网络层叫做数据报(datagram),在链路层叫做帧(frame)。
- 应用层数据通过协议栈发到网络上时,每层协议都要加上一个报头(header),称为封装(Encapsulation)。
- 数据封装成帧后发到传输介质上,到达目的主机后每层协议再剥掉相应的报头,根据首部中的上层协议字段将数据交给对应的上层协议处理。
封装和解包:封装可以看做入栈,解包可以看做出栈。
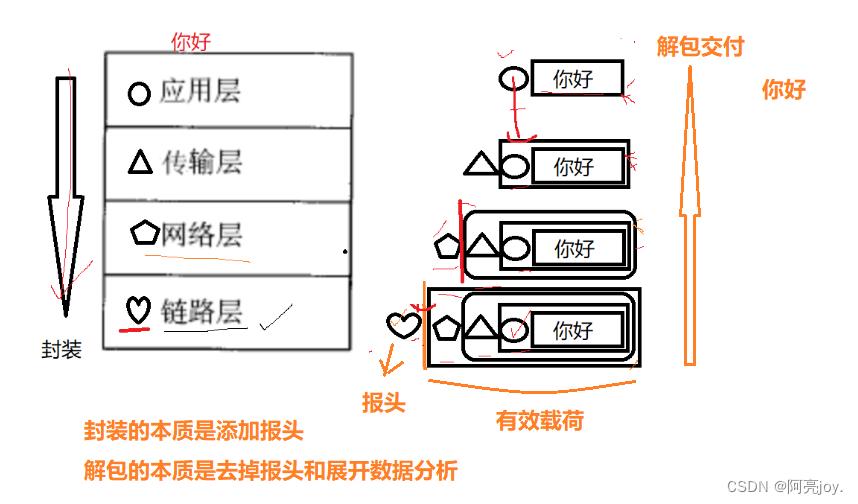
下图为数据封装的过程:

下图为数据分用的过程:
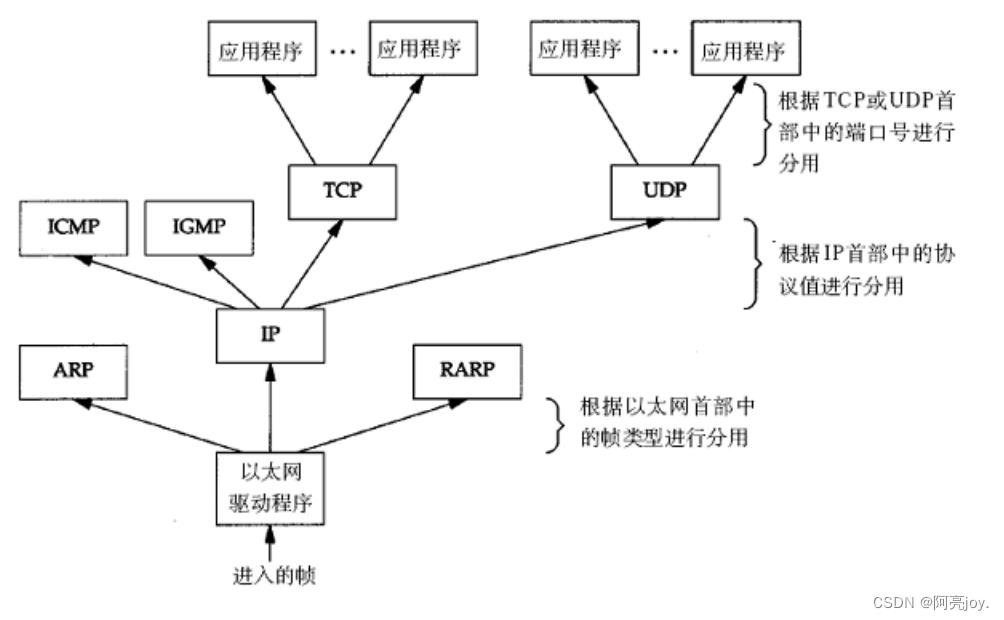
了解了封装和解包的过程,那可以很清楚地知道每个协议都需要考虑如何对数据进行解包和将有效载荷交给上层的哪一个协议的问题。
不同局域网的通信原理
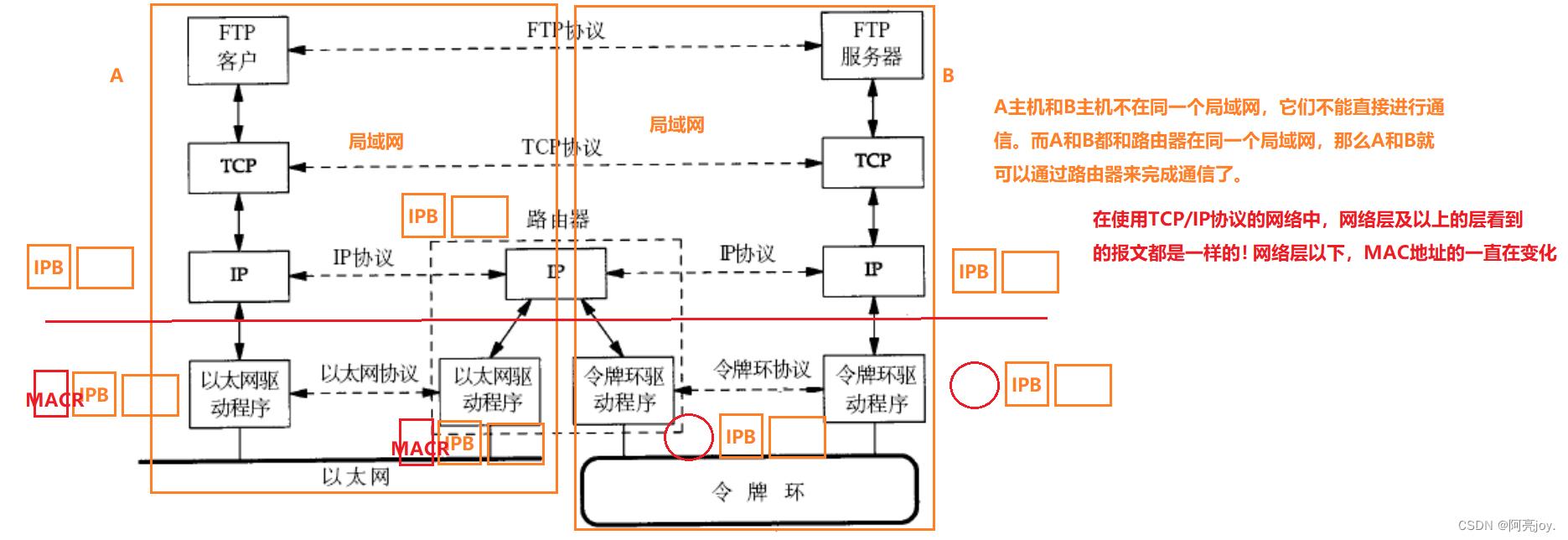
位于两个不同局域网的主机要进行通信,需要经过路由器的转发。当源主机发送数据时,数据会被封装成数据包并在数据包的首部中携带有目标主机的 IP 地址。由于源主机和目标主机不在同一个局域网中,因此数据包必须经过路由器进行转发。
当路由器接收到数据包时,它会检查目标 IP 地址并根据自己的路由表确定下一跳路由器或目标主机所在的网络。如果目标主机所在的网络不是当前路由器直接连接的网络,那么路由器就需要将数据包转发给下一个路由器。这个过程会一直持续,直到数据包到达目标主机所在的网络。
路由器之间的数据包传输可以通过不同的协议实现,例如IP路由协议、OSPF、BGP 等。这些协议会对数据包的转发过程进行控制和管理,确保数据包能够按照最佳路径进行传输。在数据包传输的过程中,数据包可能会经过多个路由器,每个路由器都会检查目标IP地址并将数据包转发给下一个路由器或目标主机。
因此,位于两个不同局域网的主机进行通信的原理是通过路由器进行转发,将数据包从源主机转发到目标主机所在的网络。这个过程需要路由器之间进行协同工作,按照最佳路径进行数据包的传输。
👉网络中的地址管理👈
认识MAC地址和IP地址
MAC 地址和 IP 地址是用于在计算机网络中识别不同设备的两种不同的地址。
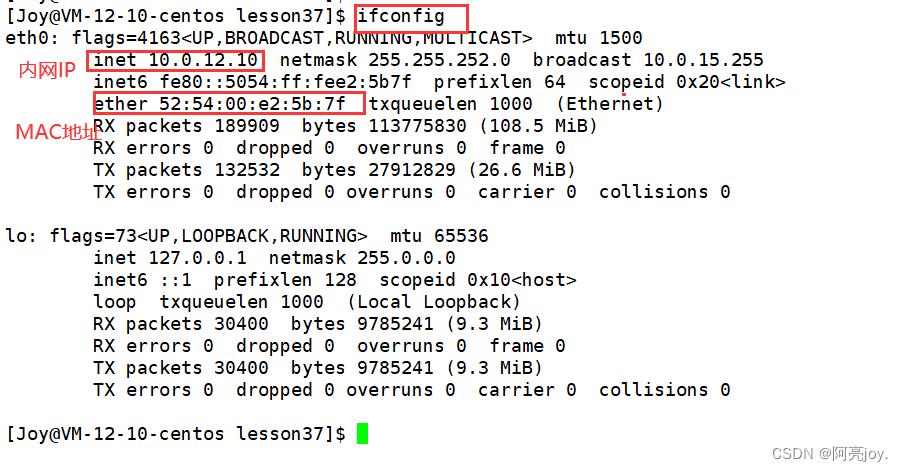
MAC 地址是由设备制造商预先设置的全球唯一的地址,通常包含 48 个比特(6个字节)。MAC 地址是用于在局域网中唯一标识一个设备的地址,是以太网技术的基础。MAC地址的格式通常是 6 组十六进制数,以冒号分隔。注:虚拟机中的 MAC 地址不是真实的 MAC 地址,可能会冲突,也有些网卡支持用户配置 MAC 地址。
IP 地址是一个 32 位的数字地址,通常分为四个 8 位组,每个组的值为 0-255。我们通常使用点分十进制的字符串表示 IP 地址, 例如:192.168.0.1,用点分割的每一个数字表示一个字节。IP地址用于在 Internet 上唯一标识一个设备。IP 地址由网络管理员分配给每个设备,以便在Internet 上进行通信。IP 地址分为 IPv4 和 IPv6 两种格式,IPv4 采用 32 位地址,而 IPv6 采用 128 位地址。注:凡是提到 IP 协议,没有特殊说明的,默认都是指 IPv4。
MAC 地址和 IP 地址之间的最大区别在于,MAC 地址是用于在局域网中唯一标识设备的地址,而 IP 地址是用于在 Internet 上唯一标识设备的地址。另外,MAC 地址是由设备制造商预先设置的,而 IP 地址是由网络管理员分配的。在网络通信过程中,计算机使用IP地址来找到其他计算机,并使用 MAC 地址来将数据帧从一个设备传输到另一个设备。
IPv4地址不足问题
IPv4 地址空间有限,只有约 42 亿个可用的 IP 地址。在当前互联网中,IP 地址已经不足以支撑日益增长的网络设备和用户。为了解决 IP 地址不足的问题,出现了一些技术,包括:
-
子网划分:将一个大的网络划分为多个子网,每个子网可以有自己的 IP 地址空间,可以更加有效地利用有限的 IP 地址。
-
NAT(Network Address Translation,网络地址转换):将内部网络中的私有 IP 地址转换为公共 IP 地址,从而使内部网络中的多个设备共享同一个公共 IP 地址,节约了 IP 地址资源。NAT 技术可以实现内网和外网之间的通信,但是不支持从外网直接访问内网中的设备。
-
IPv6:IPv6 是下一代 IP 协议,提供了更加庞大的地址空间,能够支持更多的设备和用户。IPv6 地址空间为 128位,可以提供约 340 万亿亿亿亿亿个IP地址,远远超过了 IPv4 地址空间。
这些技术在不同的场景下可以结合使用,来解决IP地址不足的问题。例如,企业内部可以使用子网划分来更好地管理内部网络,同时使用 NAT 技术将内部私有 IP 地址转换为公共 IP 地址,从而节约 IP 地址资源。在 IPv4 地址已经耗尽的情况下,也可以使用 IPv6 来为设备分配 IP 地址。
IPv6 为何推广缓慢
IPv6 推行会很缓慢的原因如下:
-
设备和软件的兼容性问题:IPv6 的协议格式和 IPv4 不兼容,需要硬件和软件都支持IPv6协议,但很多设备和软件还没有升级,无法支持IPv6协议。
-
成本问题:升级到 IPv6 需要更换硬件设备和软件,这需要巨大的成本投入。对于许多中小型企业和个人用户来说,这可能是一个巨大的负担。
-
IPv4 仍然可以工作:尽管 IPv4 地址不足,但仍然可以继续使用。目前有一些技术手段,如网络地址转换(NAT),可以在一定程度上缓解 IPv4 地址不足的问题,因此一些组织可能认为 IPv6 升级并不是非常紧急。
-
IPv6 生态系统的不成熟:IPv6 协议的生态系统尚未完全成熟,相比 IPv4,还缺少一些成熟的应用和服务支持。这可能会导致一些组织和用户观望和等待,直到 IPv6 的生态系统更加成熟和稳定。
综上,IPv6 推广的缓慢主要是由于设备和软件的兼容性问题、高成本、IPv4 仍然可以工作以及 IPv6 生态系统的不成熟等原因。
有关 IPv4 和 IPv6 的故事,大家可以看一下这个视频:【硬件科普】IP 地址是什么东西?IPV6 和 IPV4 有什么区别?公网 IP 和私有 IP 又是什么?
👉总结👈
本篇博客主要介绍了什么是局域网和广域网、什么是协议、协议分层、OSI七层模型、TCP/IP五层模型、局域网通信原理、数据包封装和分用、不同局域网的通信原理、什么是MAC地址和IP地址、MAC地址和IP地址的区别以及IPv4地址不足问题和IPv6推广缓慢问题等等。以上就是本篇博客的全部内容了,如果大家觉得有收获的话,可以点个三连支持一下!谢谢大家啦!💖💝❣️
云原生一文带你搞懂Docker容器的核心基石Cgroups
目录
大家好,本文是对 Docker 容器的核心基石Cgroups的详细讲解,讲解了Cgroups的相关概念、Cgroups的构成与作用、如何查看和使用Cgroups等,对大家后续理解容器有很大的帮助~
9.3、通过配置文件设置cgroup(/etc/cgconfig.conf)
Cgroups是Linux系统内核提供的一种机制,这种机制可以根据需求将一些列系统任务机器子任务整合或分离到按资源划分登记的不同组内,从而为系统资源管理提供一个的框架。简单地说,cgroups可以限制、记录任务组所使用的物理组员(比如CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建Docker等一些列虚拟化管理工具的基石。今天我们就来详细介绍一下cgroups相关的内容。

1、为什么要了解Cgroups
从2013年开源的Docker推出、2014年开源的 Kubernetes出现,到现在的云原生技术与生态的全面普及与火热化,容器技术已经逐步成为主流的基础云原生技术之一。使用容器技术,可以很好地实现资源层面上的限制和隔离,这都依赖于Linux系统内核所提供的Cgroups和 Namespace技术。
Cgroups 主要用来管理资源的分配、限制;
Namespace主要用来封装抽象、限制、隔离资源,使命名空间内的进程拥有它们自己的全局资源。
Linux内核提供的Cgroups和 Namespace技术,为容器实现虚拟化提供了基本保证,是构建Docker等一些列虚拟化管理工具的基石。下面我们就来详细介绍一下Cgroups相关的内容。
2、Cgroups简介
Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如CPU、Memory、IO等等)的机制。
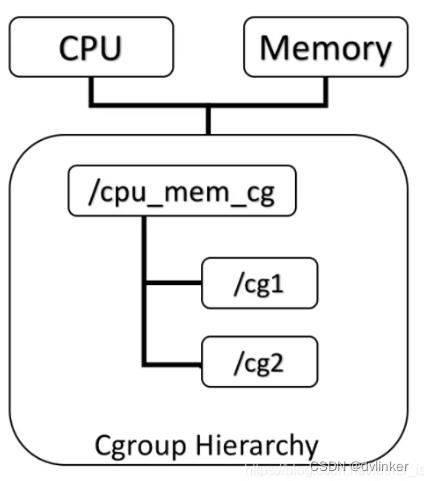
通过使用Cgroups,系统管理员在分配、排序、拒绝、管理和监控系统资源等方面,可以进行精细化控制。硬件资源可以在应用程序和用户间智能分配,从而增加整体效率。最初由google 的工程师提出,后来被整合进Linux内核。也是目前轻量级虚拟化技术 XC(Linux Container)的基础之一。
Cgroups和 Namespace类似,也是将进程进行分组,但它的目的和 Namespace不一 样,Namespace是为了隔离进程组之间的资源,而 Cgroups是为了对一组进程进行统一的资源监控和限制。
Cgroups分 v1 和 v2 两个版本,v1 实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便,v2 的出现 就是为了解决 v1 中这方面的问题,在最新的 4.5 内核中,Cgroups v2 声称已经可以用于生产环境了,但它所支持的功能还很有限,随着 v2 一起引入内核的还有 Cgroups、Namespace。v1 和 v2 可以混合使用,但是这样会更复杂,所以一般没人会这样用。
3、什么是Cgroups?
Cgroups 是 Linux 下的一种将进程按组进行管理的机制,在用户层看来,Cgroups技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个 subsystem关联,树的作用是将进程分组,而subsystem的作用就是对这些组进行操作。Cgroups的主体架构提如下:

Cgroups主要包括下面两部分:
subsystem : 一个 subsystem 就是一个内核模块,他被关联到一颗 cgroup 树之后, 就会在树的每个节点(进程组)上做具体的操作。subsystem 经常被称作 resource controller,因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准 确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使 用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等,后续会对它们 一一进行介绍。
hierarchy : 一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程 组,每棵树都会与零到多个 subsystem 关联。在一颗树里面,会包含 Linux 系统中的所有 进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗 cgroup 树,每棵树 都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程 组,只是这些进程组和不同的 subsystem 关联。
目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况(systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这 棵树关联所有的 subsystem。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着 这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定, systemd 就是一个这样的例子。
4、为什么需要Cgroups?
在 Linux 里,一直以来就有对进程进行分组的概念和需求,比如 session group, progress group 等,后来随着人们对这方面的需求越来越多,比如需要追踪一组进程的内存和 IO使用情况等,于是出现了cgroup,用来统一将进程进行分组,并在分组的基础上对进程进行监控和资源控制管理等。
举个例子,Linux系统中安装了杀毒软件ESET或者ClamAV,杀毒时占用系统资源过高,影响系统承载业务运 行,怎么办?单个虚拟机进程或者docker进程使用过高的资源,怎么办? 单个Java进行占用系统过多的内存的资源,怎么办?
cgroup就是能够控制并解决上述问题的工具,cgroup在linux内核实现、用于控制 linux系统资源。
5、Cgroups是如何实现的?
在 CentOS 7 系统中(包括 Red Hat Enterprise Linux 7),通过将 cgroup 层级系统与systemd 单位树捆绑,可以把资源管理设置从进程级别移至应用程序级别。默认情况 下,systemd 会自动创建 slice、scope 和 service 单位的层级(具体的意思稍后再解释),来为 cgroup 树提供统一结构。
可以通过 systemctl 命令创建自定义 slice 进一步修 改此结构。 如果我们将系统的资源看成一块馅饼,那么所有资源默认会被划分为 3 个 cgroup: System, User 和 Machine。每一个 cgroup 都是一个 slice,每个 slice 都可以有自己的子 slice,如下图所示:

下面我们以 CPU 资源为例,来解释一下上图中出现的一些关键词。
如上图所示,系统默认创建了 3 个顶级 slice(System, User 和 Machine),每个 slice 都会获得相同的 CPU 使用时间(仅在 CPU 繁忙时生效),如果 user.slice 想获得 100% 的 CPU 使用时间,而此时 CPU 比较空闲,那么 user.slice 就能够如愿以偿。这三种顶级 slice 的含义如下:
1)system.slice:所有系统 service 的默认位置。
2)user.slice:所有用户会话的默认位置。每个用户会话都会在该 slice 下面创建一个子 slice, 如果同一个用户多次登录该系统,仍然会使用相同的子 slice。
3)machine.slice:所有虚拟机和 Linux 容器的默认位置 控制 CPU 资源使用的其中一种方法是 shares。shares 用来设置 CPU 的相对值(你可以理解为权 重),并且是针对所有的 CPU(内核),默认值是 1024。因此在上图中,httpd, sshd, crond 和 gdm 的 CPU shares 均为 1024,System, User 和 Machine 的 CPU shares 也是 1024。
假设该系统上运行了 4 个 service,登录了两个用户,还运行了一个虚拟机。同时假设 每个进程都要求使用尽可能多的 CPU 资源(每个进程都很繁忙),则:
1)system.slice 会获得 33.333% 的 CPU 使用时间,其中每个 service 都会从 system.slice 分配的 资源中获得 1/4 的 CPU 使用时间,即 8.25% 的 CPU 使用时间。
2)user.slice 会获得 33.333% 的 CPU 使用时间,其中每个登录的用户都会获得 16.5% 的 CPU 使 用时间。假设有两个用户:tom 和 jack,如果 tom 注销登录或者杀死该用户会话下的所有进程, jack 就能够使用 33.333% 的 CPU 使用时间。
3)machine.slice 会获得 33.333% 的 CPU 使用时间,如果虚拟机被关闭或处于 idle 状态,那么 system.slice 和 user.slice 就会从这 33.333% 的 CPU 资源里分别获得 50% 的 CPU 资源,然后 均分给它们的子 slice。
6、Cgroups的作用
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization),框架图如下:
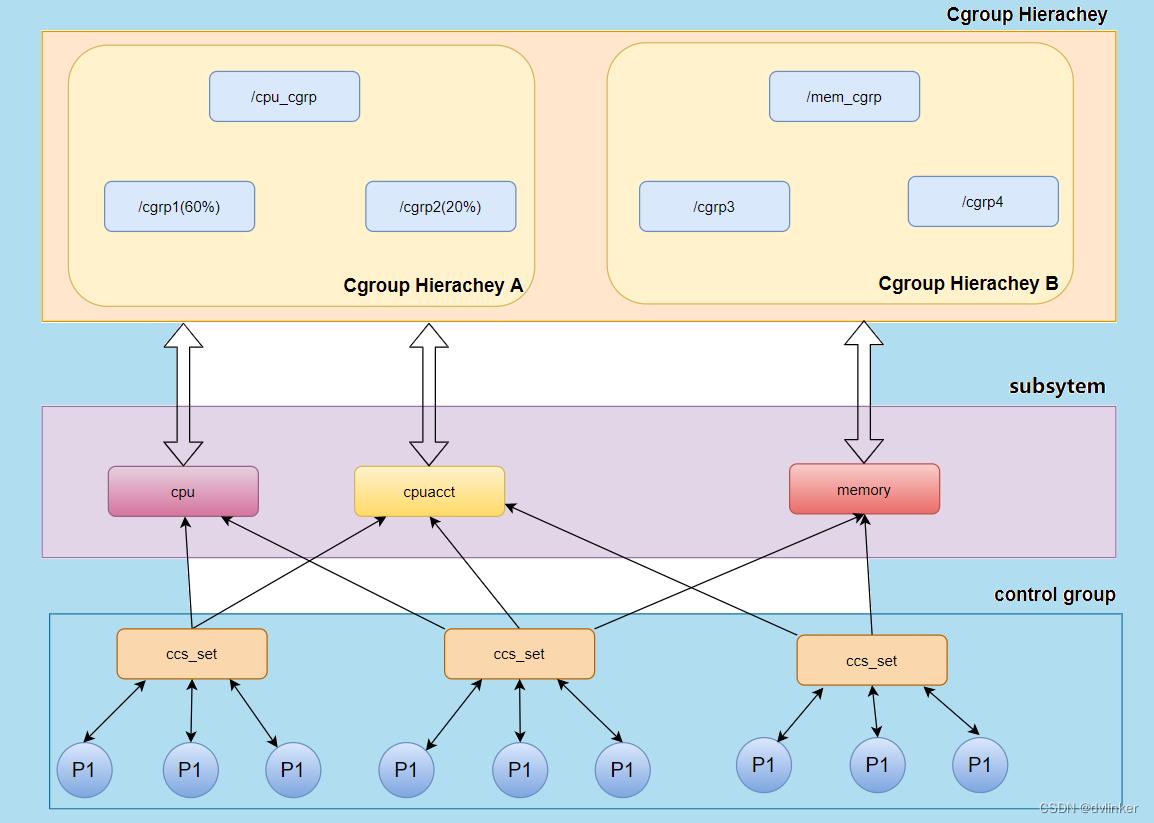
Cgroups提供了以下功能:
1)限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程 组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发 OOM(out of memory)。
2)进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定 cpu share。
3)记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程 组使用的cpu时间。
4)进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的 namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
5)进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
7、Cgroups相关概念及相互关系
7.1、相关概念
1)任务(task)
在cgroups中,任务就是系统的一个进程。
2)控制族群(control group)
控制族群就是一组按照某种标准划分的进程。Cgroups中的资 源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另 一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到 cgroups以控制族群为单位设定的限制。
3)层级(hierarchy)
控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族 群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
4)子系统(subsystem)
一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间 分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个 层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
7.2、相互关系
1)每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此cgroup在创建层级时自动创建,后面在该层级中创建的cgroup都是此cgroup 的后代)的初始成员。
2)一个子系统最多只能附加到一个层级。
3)一个层级可以附加多个子系统
4)一个任务可以是多个cgroup的成员,但是这些cgroup必须在不同的层级。
5)系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成 员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
8、Cgroups子系统介绍
可以看到,在/sys/fs/cgroup下面有很多cpu、memory这样的子目录,也就称为子系统subsystem:

它是一组资源控制模块,一般包含如下几项:
1)net_cls:将cgroup中进程产生的网络包分类,以便Linux的tc(traffic controller)可 以根据分类区分出来自某个cgroup的包并做限流或监控。这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序 (tc)识别从具体 cgroup 中生成的数据包。
2)net_prio:设置cgroup中进程产生的网络流量的优先级。
3)memory:控制cgroup中进程的内存占用。4)cpuset:在多核机器上设置cgroup中进程可以使用的cpu和内存。这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
5)freezer:挂起(suspend)和恢复(resume)cgroup中的进程。这个子系统挂起或者恢复 cgroup 中的任务。
6)blkio:设置对块设备(如硬盘)输入输出的访问控制。这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等 等)。
7)cpu:设置cgroup中进程的CPU占用。这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
8)cpuacct:统计cgroup中进程的CPU占用。这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
9)devices:控制cgroup中进程对设备的访问 16 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
8.1、如何查看当前系统支持哪些subsystem?
可以通过查看/proc/cgroups(since Linux 2.6.24)知道当前系统支持哪些subsystem,下面 是一个例子:
#subsys_name hierarchy num_cgroups enabled
cpuset 11 1 1
cpu 3 64 1
cpuacct 3 64 1
blkio 8 64 1
memory 9 104 1
devices 5 64 1
freezer 10 4 1
net_cls 6 1 1
perf_event 7 1 1
net_prio 6 1 1
hugetlb 4 1 1
pids 2 68 1每一列的说明:
1)subsys_name:subsystem的名字
2)hierarchy:subsystem所关联到的cgroup树的ID,如果多个subsystem关联到同一颗cgr oup树,那么他们的这个字段将一样,比如这里的cpu和cpuacct就一样,表示他们绑定到了同 一颗树。 如果出现下面的情况,这个字段将为0:
i)当前subsystem没有和任何cgroup树绑定
ii)当前subsystem已经和cgroup v2的树绑定
iii)当前subsystem没有被内核开启3)num_cgroups:subsystem所关联的cgroup树中进程组的个数,也即树上节点的个数
4)enabled:1表示开启,0表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制subsystem的开启).
8.2、Cgroups下的CPU子系统
cpu子系统用于控制cgroup中所有进程可以使用的cpu时间片。 cpu subsystem主要涉及5接口:cpu.cfs_period_us,cpu.cfs_quota_us,cpu.shares, cpu.rt_period_us,cpu.rt_runtime_us. cpu.
1)cfs_period_us
cfs_period_us表示一个cpu带宽,单位为微秒。系统总CPU带宽: cpu核心数 * cfs_period_us cpu.
2)cfs_quota_us
cfs_quota_us表示Cgroup可以使用的cpu的带宽,单位为微秒。cfs_quota_us为-1,表示使用的 CPU不受cgroup限制。cfs_quota_us的最小值为1ms(1000),最大值为1s。 结合cfs_period_us,就可以限制进程使用的cpu。例如配置cfs_period_us=10000,而 cfs_quota_us=2000。那么该进程就可以可以用2个cpu core。
3)cpu.shares
通过cfs_period_us和cfs_quota_us可以以绝对比例限制cgroup的cpu使用,即 cfs_quota_us/cfs_period_us 等于进程可以利用的cpu cores,不能超过这个数值。 而cpu.shares以相对比例限制cgroup的cpu。例如:在两个 cgroup 中都将 cpu.shares 设定为 1 的任务将有相同的 CPU 时间,但在 cgroup 中将 cpu.shares 设定为 2 的任务可使用的 CPU 时间 是在 cgroup 中将 cpu.shares 设定为 1 的任务可使用的 CPU 时间的两倍。
4)cpu.rt_runtime_us
以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 中的任务对 CPU 资源的最 长连续访问时间。建立这个限制是为了防止一个 cgroup 中的任务独占 CPU 时间。如果 cgroup 中的任务应该可以每 5 秒中可有 4 秒时间访问 CPU 资源,请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。
5)cpu.rt_period_us
以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 对 CPU 资源访问重新分配 的频率。如果某个 cgroup 中的任务应该每 5 秒钟有 4 秒时间可访问 CPU 资源,则请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。
注意 sched_rt_runtime_us 是实时任务的保证时间和最高占用时间,如果实时任务没有使用,可以分配给非实时任务,并且实时任务最终占用的时间不能超过这个数值,参考 Linux-85 关于 sched_rt_runtime_us 和 sched_rt_period_us 。
对 cpu.rt_period_us 参数的限制是必须小于父目录中的同名参数值。 对 cpu.rt_runtime_us 的限制是:
\\Sum_i runtime_i / global_period <= global_runtime / global_period即:
\\Sum_i runtime_i <= global_runtime 当前的实时进程调度算法可能导致部分实时进程被饿死,如下A和B是并列的,A的运行时时长正好覆盖了B的运行时间:
* group A: period=100000us, runtime=50000us
- this runs for 0.05s once every 0.1s
* group B: period= 50000us, runtime=25000us
- this runs for 0.025s twice every 0.1s (or once every 0.05 sec).Real-Time group scheduling 中提出正在开发 SCHED_EDF (Earliest Deadline First scheduling),优先调度最先结束的实时进程。
8.3、在CentOS中安装Cgroups
#若系统未安装则进行安装,若已安装则进行更新。
yum install libcgroup
#查看运行状态,并启动服务
[root@localhost ~] service cgconfig status
Stopped
[root@localhost ~] service cgconfig start
Starting cgconfig service: [ OK ]
service cgconfig status 9 Running 1011
#查看是否安装cgroup
[root@localhost ~] grep cgroup /proc/filesystems8.4、查看service服务在哪个cgroup组
systemctl status [pid] | grep CGroup 23
cat /proc/[pid]/cgroup
cd /sys/fs/ && find * ‐name "*.procs" ‐exec grep [pid] /dev/null \\; 2> /dev/null
#查看进程cgroup的最快方法是使用以下bash脚本按进程名:
#!/bin/bash
THISPID=`ps ‐eo pid,comm | grep $1 | awk 'print $1'`
cat /proc/$THISPID/cgroup9、如何使用Cgroups?
9.1、通过systemctl设置cgroup
在使用命令 systemctl set-property 时,可以使用 tab 补全:
$ systemctl set‐property user‐1000.slice
AccuracySec= CPUAccounting= Environment= LimitCPU= LimitNICE= LimitSIGPEN DING= SendSIGKILL=
BlockIOAccounting= CPUQuota= Group= LimitDATA= LimitNOFILE= LimitSTACK= U ser=
BlockIODeviceWeight= CPUShares= KillMode= LimitFSIZE= LimitNPROC= MemoryA ccounting= WakeSystem=
BlockIOReadBandwidth= DefaultDependencies= KillSignal= LimitLOCKS= LimitR SS= MemoryLimit=
BlockIOWeight= DeviceAllow= LimitAS= LimitMEMLOCK= LimitRTPRIO= Nice=
BlockIOWriteBandwidth= DevicePolicy= LimitCORE= LimitMSGQUEUE= LimitRTTIM E= SendSIGHUP=这里有很多属性可以设置,但并不是所有的属性都是用来设置 cgroup 的,我们只需要关注 Block, CPU 和 Memory。
如果你想通过配置文件来设置 cgroup,service 可以直接在 /etc/systemd/system/xxx.service.d 目录下面创建相应的配置文件,slice 可以直接在 /run/systemd/system/xxx.slice.d 目录下面创建相应的配置文件。
事实上通过 systemctl 命令行工具设置 cgroup 也会写到该目录下的配置文件中:
$ cat /run/systemd/system/user‐1000.slice.d/50‐CPUQuota.conf
[Slice]
CPUQuota=20%9.2、设置 CPU 资源的使用上限
如果想严格控制 CPU 资源,设置 CPU 资源的使用上限,即不管 CPU 是否繁忙,对 CPU 资源的使用都不能超过这个上限。可以通过以下两个参数来设置:
1)cpu.cfs_period_us = 统计CPU使用时间的周期,单位是微秒(us)
2)cpu.cfs_quota_us = 周期内允许占用的CPU时间(指单核的时间,多核则需要在设置时累加)
systemctl 可以通过 CPUQuota 参数来设置 CPU 资源的使用上限。例如,如果你想将用户 tom 的 CPU 资源使用上限设置为 20%,可以执行以下命令:
$ systemctl set‐property user‐1000.slice CPUQuota=20%9.3、通过配置文件设置cgroup(/etc/cgconfig.conf)
cgroup配置文件所在位置 /etc/cgconfig.conf,其默认配置文件内容
mount cpuset = / cgroup / cpuset ; cpu = / cgroup / cpu ; cpuacct = / cgroup / cpuacct ; memory = / cgroup / memory ; devices = / cgroup / devices ; freezer = / cgroup / freezer ; net_cls = / cgroup / net_cls ; blkio = / cgroup / blkio ;
相当于执行命令:
mkdir /cgroup/cpuset
mount ‐t cgroup ‐o cpuset red /cgroup/cpuset
……
mkdir /cgroup/blkio
[root@localhost ~] vi /etc/cgrules.conf
[root@localhost ~] echo 524288000 > /cgroup/memory/foo/memory.limit_in_b ytes 使用cgroup临时对进程进行调整,直接通过命令即可,如果要持久化对进程进行控 制,即重启后依然有效,需要写进配置文件/etc/cgconfig.conf及/etc/cgrules.conf
10、查看Cgroup
10.1、通过systemd查看cgroup
1)systemd-cgls 命令
通过 systemd-cgls 命令来查看,它会返回系统的整体 cgroup 层级,cgroup 树的最高层 由 slice 构成,如下所示:
$ systemd‐cgls ‐‐no‐page
├─1 /usr/lib/systemd/systemd ‐‐switched‐root ‐‐system ‐‐deserialize 22
├─user.slice
│ ├─user‐1000.slice
│ │ └─session‐11.scope
│ │ ├─9507 sshd: tom [priv]
│ │ ├─9509 sshd: tom@pts/3
│ │ └─9510 ‐bash
│ └─user‐0.slice
│ └─session‐1.scope
│ ├─ 6239 sshd: root@pts/0
│ ├─ 6241 ‐zsh
│ └─11537 systemd‐cgls ‐‐no‐page
└─system.slice 15 ├─rsyslog.service
│ └─5831 /usr/sbin/rsyslogd ‐n
├─sshd.service 18 │ └─5828 /usr/sbin/sshd ‐D
├─tuned.service
│ └─5827 /usr/bin/python2 ‐Es /usr/sbin/tuned ‐l ‐P 21 ├─crond.service
│ └─5546 /usr/sbin/crond ‐n可以看到系统 cgroup 层级的最高层由 user.slice 和 system.slice 组成。因为系统中没有 运行虚拟机和容器,所以没有 machine.slice,所以当 CPU 繁忙时,user.slice 和 system.slice 会各获得 50% 的 CPU 使用时间。
user.slice 下面有两个子 slice:user-1000.slice 和 user-0.slice,每个子 slice 都用 User ID (UID) 来命名,因此我们很容易识别出哪个 slice 属于哪个用户。例如:从上面的输出信 息中可以看出 user-1000.slice 属于用户 tom,user-0.slice 属于用户 root。
2)systemd-cgtop 命令
systemd-cgls 命令提供的只是 cgroup 层级的静态信息快照,要想查看 cgroup 层级的动 态信息,可以通过 systemd-cgtop 命令查看:
$ systemd‐cgtop
Path Tasks %CPU Memory Input/s Output/s
/ 161 1.2 161.0M ‐ ‐ 5 /system.slice ‐ 0.1 ‐ ‐ ‐
/system.slice/vmtoolsd.service 1 0.1 ‐ ‐ ‐
/system.slice/tuned.service 1 0.0 ‐ ‐ ‐
/system.slice/rsyslog.service 1 0.0 ‐ ‐ ‐
/system.slice/auditd.service 1 ‐ ‐ ‐ ‐
/system.slice/chronyd.service 1 ‐ ‐ ‐ ‐
/system.slice/crond.service 1 ‐ ‐ ‐ ‐
/system.slice/dbus.service 1 ‐ ‐ ‐ ‐
/system.slice/gssproxy.service 1 ‐ ‐ ‐ ‐
/system.slice/lvm2‐lvmetad.service 1 ‐ ‐ ‐ ‐
/system.slice/network.service 1 ‐ ‐ ‐ ‐
/system.slice/polkit.service 1 ‐ ‐ ‐ ‐
/system.slice/rpcbind.service 1 ‐ ‐ ‐ ‐
/system.slice/sshd.service 1 ‐ ‐ ‐ ‐
/system.slice/system‐getty.slice/getty@tty1.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐journald.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐logind.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐udevd.service 1 ‐ ‐ ‐ ‐
/system.slice/vgauthd.service 1 ‐ ‐ ‐ ‐
/user.slice 3 ‐ ‐ ‐ ‐
/user.slice/user‐0.slice/session‐1.scope 3 ‐ ‐ ‐ ‐
/user.slice/user‐1000.slice 3 ‐ ‐ ‐ ‐
/user.slice/user‐1000.slice/session‐11.scope 3 ‐ ‐ ‐ ‐
/user.slice/user‐1001.slice/session‐8.scopescope systemd-cgtop 提供的统计数据和控制选项与 top 命令类似,但该命令只显示那些开启了 资源统计功能的 service 和 slice。
如果你想开启 sshd.service 的资源统计功能,可以进行如下操作:
$ systemctl set‐property sshd.service CPUAccounting=true MemoryAccounting=true
#该命令会在 /etc/systemd/system/sshd.service.d/ 目录下创建相应的配置文件:
$ ll /etc/systemd/system/sshd.service.d/
总用量 8
4 ‐rw‐r‐‐r‐‐ 1 root root 28 5月 31 02:24 50‐CPUAccounting.conf
4 ‐rw‐r‐‐r‐‐ 1 root root 31 5月 31 02:24 50‐MemoryAccounting.conf
$ cat /etc/systemd/system/sshd.service.d/50‐CPUAccounting.conf
[Service]
CPUAccounting=yes 1415
$ cat /etc/systemd/system/sshd.service.d/50‐MemoryAccounting.conf
[Service]
MemoryAccounting=yes 1819
#配置完成之后,再重启 sshd 服务:
$ systemctl daemon‐reload 21 $ systemctl restart sshd这时再重新运行 systemd‐cgtop 命令,就能看到 sshd 的资源使用统计了。
10.2、通过proc查看cgroup
如何查看当前进程属于哪些cgroup 可以通过查看/proc/[pid]/cgroup(since Linux 2.6.24)知道指定进程属于哪些cgroup,如下:
$ cat /proc/777/cgroup
11:cpuset:/
10:freezer:/
9:memory:/system.slice/cron.service
8:blkio:/system.slice/cron.service
7:perf_event:/ 7 6:net_cls,net_prio:/
5:devices:/system.slice/cron.service
4:hugetlb:/
3:cpu,cpuacct:/system.slice/cron.service
2:pids:/system.slice/cron.service
1:name=systemd:/system.slice/cron.service每一行包含用冒号隔开的三列,他们的意思分别是:
“cgroup树的ID :和cgroup树绑定的所有subsystem :进程在cgroup树中的路径”
1)cgroup树的ID, 和/proc/cgroups文件中的ID一一对应。
2)和cgroup树绑定的所有subsystem,多个subsystem之间用逗号隔开。这里name=systemd 表示没有和任何subsystem绑定,只是给他起了个名字叫systemd。
3)进程在cgroup树中的路径,即进程所属的cgroup,这个路径是相对于挂载点的相对路径。
10.3、通过/sys查看cgroup
查看cgroup下CPU资源的使用上限:
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user‐1000.slice/cpu.cfs_perio d_us
100000
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user‐1000.slice/cpu.cfs_quota _us
20000 这表示用户 tom 在一个使用周期内(100 毫秒)可以使用 20 毫秒的 CPU 时间。不管 CPU 是否空闲,该用户使用的 CPU 资源都不会超过这个限制。
CPUQuota 的值可以超过 100%,例如:如果系统的 CPU 是多核,且 CPUQuota 的值为 200%,那么该 slice 就能够使用 2 核的 CPU 时间。
以上是关于Linux一文带你探究网络世界的基石的主要内容,如果未能解决你的问题,请参考以下文章