短视频封面抽取和标题自动化生成
Posted 远洋之帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了短视频封面抽取和标题自动化生成相关的知识,希望对你有一定的参考价值。
思路
1.对人像直播视频抽取关键帧
2.对关键帧做质量打分排序
3.利用语音和视频字幕抽取内容文本
4.利用文本做文章标题自动生成
5.基于模版合成视频封面
人像抽取部分
0.视频字幕去除
# 安装 AgentOCR
!pip install agentocr
# 安装 CPU 版本 ONNXRuntime
!pip install onnxruntime
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
def image_remove_word(img_path = 'images/frame.177000000.jpg'):
mask_threth = 50
# 设置测试图片路径
img_path = img_path
img = cv2.imread(img_path) #自己qq截图一张图片就行,要大于下面的坐标点
# 通过 config 参数来进行模型配置,内置多国语言的配置文件
ocr = OCRSystem(config='ch')
# 调用 OCR API 进行全流程识别
result = ocr.ocr(img_path)
coordinates = []
# 打印结果
for line in result:
coordinate1 = []
a0 = line[0][0][0]-5
a1 = line[0][0][1]-5
b0 = line[0][1][0]+5
c1 = line[0][2][1]+5
coordinate1.append([[a0,a1],[b0,a1],[b0,c1],[a0,c1]])
coordinate1 = np.array(coordinate1, np.int32)
coordinates.append(coordinate1)
#print(line[0])
# binary mask
mask = np.zeros(img.shape[:2], dtype=np.int8)
mask = cv2.fillPoly(mask, coordinates,255)
cv2.imwrite('images/mask1.png', mask)
mask = cv2.imread('images/mask1.png',0)
dst = cv2.inpaint(img,mask,3,cv2.INPAINT_TELEA)
cv2.imwrite(img_path,dst)
#img_path = 'images/frame.177000000.jpg'
#image_remove_word(img_path)
def getFrame(video_name, save_path):#将视频逐帧保存为图片
video = cv2.VideoCapture(video_name)
# 获取视频帧率
fps = video.get(cv2.CAP_PROP_FPS)
print(fps)
# 获取画面大小
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (width, height)
# 获取帧数
frame_num = str(video.get(7))
name = int(math.pow(10, len(frame_num)))
ret, frame = video.read()
#ocr = OCRSystem(config='ch')
while ret:
cv2.imwrite(save_path + str(name) + '.jpg', frame)
#imagepath = save_path + str(name) + '.jpg'
#image_remove_word(imagepath,ocr)
ret, frame = video.read()
name += 1
video.release()
return fps, size, frame_num
def writeVideo(humanseg, fps, size):# 写入视频
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter('./movies/green.mp4', fourcc, fps, size)
# 为每一帧设置背景
files = os.listdir(humanseg)
#将文件名按编号顺序排序
file_num_sort = []
for file in files:
file_num_sort.append(int(file.split('.')[0]))
file_num_sort.sort()
#print(file_num_sort)
file_sort = []
for file_num in file_num_sort:
file_sort.append('./frames/'+str(file_num)+'.jpg')
#print(file_sort)
ocr = OCRSystem(config='ch')
for file in file_sort:
print('将'+file+'写入视频')
#imagepath = save_path + str(name) + '.jpg'
image_remove_word(file,ocr)
im_array = cv.imread(file)#setImageBg(file, bg_im)
out.write(im_array)
out.release()
def getMusic(video_name):#获取音频
video = VideoFileClip(video_name)
return video.audio
def addMusic(video_name, audio):#给video_name添加音频
video = VideoFileClip(video_name)#读取
video = video.set_audio(audio)#设置
video.write_videofile(output_video)#保存
!pip install moviepy
import os
import math
#将视频按帧保存为图片
frame_path = "./frames/"
if not os.path.exists(frame_path):
os.makedirs(frame_path)
video_name = './movies/whitebottle.mp4'
fps, size, frame_number = getFrame(video_name, frame_path)
print(fps, size, frame_number)
from moviepy.editor import *
import cv2 as cv
# 最终视频的保存路径
output_video = './movies/result.mp4'
humanseg_path = 'frames'
writeVideo(humanseg_path, fps, size)
addMusic('./movies/green.mp4', getMusic(video_name))
#https://aistudio.baidu.com/aistudio/projectdetail/3919465?forkThirdPart=11.视频背景去除
!pip install --quiet av pims
import torch
model = torch.hub.load("PeterL1n/RobustVideoMatting", "mobilenetv3").cuda() # or "resnet50"
convert_video = torch.hub.load("PeterL1n/RobustVideoMatting", "converter")
convert_video(
model, # The loaded model, can be on any device (cpu or cuda).
input_source='input.mp4', # A video file or an image sequence directory.
downsample_ratio=None, # [Optional] If None, make downsampled max size be 512px.
output_type='video', # Choose "video" or "png_sequence"
output_composition='com.mp4', # File path if video; directory path if png sequence.
output_alpha="pha.mp4", # [Optional] Output the raw alpha prediction.
output_foreground="fgr.mp4", # [Optional] Output the raw foreground prediction.
output_video_mbps=4, # Output video mbps. Not needed for png sequence.
seq_chunk=12, # Process n frames at once for better parallelism.
num_workers=1, # Only for image sequence input. Reader threads.
progress=True # Print conversion progress.
)2.视频关键帧提取
!pip install av
import av
import os
import shutil
# 视频提取关键帧工具类(支持批量视频)
class PyAvUtils:
def __init__(self, video_dir, keyframe_dir):
self.video_dir = video_dir
self.keyframe_dir = keyframe_dir
# 提取关键帧并保存
def do_video2image(self):
for video_name in os.listdir(self.video_dir):
if not video_name.endswith('.mp4'):
continue
print(video_name)
video_keyframe_dir = os.path.join(self.keyframe_dir, video_name)
if not os.path.exists(video_keyframe_dir):
os.makedirs(video_keyframe_dir)
print("已自动创建:", video_keyframe_dir)
else:
print("目录已存在")
# 提取关键帧
self.extract_video(video_name)
# 定义提取视频关键帧的函数
def extract_video(self, filename):
cur_video_path = os.path.join(self.video_dir, filename)
cur_video_keyframe_dir = os.path.join(self.keyframe_dir, filename)
container = av.open(cur_video_path)
# Signal that we only want to look at keyframes.
stream = container.streams.video[0]
stream.codec_context.skip_frame = 'NONKEY'
for frame in container.decode(stream):
frame.to_image().save(cur_video_keyframe_dir + '/' + 'frame.:04d.jpg'.format(frame.pts),
quality=90)
pa = PyAvUtils('/Users/qian-lwq/Downloads/whitebottle', '/Users/qian-lwq/Downloads/whitebottle/image')
pa.do_video2image()3.视频中人五官定位,面部关键点抽取
3.1是否闭眼判断
3.2是否正脸、是否侧脸
3.3是否有眼镜
3.4是否露嘴
3.5是否标准脸
3.6计算脸长宽比
PaddleHub实战——人像美颜 - 飞桨AI Studio
4.视频人形态关键点抽取
PaddleHub实战——人像美颜 - 飞桨AI Studio
5.计算视频中人像打分
import cv2 as cv
import mediapipe as mp
import numpy as np
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
# 定义可视化图像函数
def look_img(img):
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
# 读取图像
#img=cv.imread("images/frame.177000000.jpg")
# width=img1.shape[1]
# height=img1.shape[0]
# img=cv.resize(img1,(width*10,height*10))
# look_img(img)
def face_metric(image_path = 'images/frame.177000000.jpg' ):
# 导入可视化函数和可视化样式
mp_drawing=mp.solutions.drawing_utils
# mp_drawing_styles=mp.solutions.drawing_styles
draw_spec=mp_drawing.DrawingSpec(thickness=2,circle_radius=1,color=[223,155,6])
# 导入三维人脸关键点检测模型
mp_face_mesh=mp.solutions.face_mesh
# help(mp_face_mesh.FaceMesh)
model=mp_face_mesh.FaceMesh(
static_image_mode=True,#TRUE:静态图片/False:摄像头实时读取
refine_landmarks=True,#使用Attention Mesh模型
max_num_faces=40,
min_detection_confidence=0.2, #置信度阈值,越接近1越准
min_tracking_confidence=0.5,#追踪阈值
)
img=cv.imread(image_path)
# 将图像模型输入,获取预测结果
# BGR转RGB
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results=model.process(img_RGB)
radius=12
lw=2
scaler=1
h,w=img.shape[0],img.shape[1]
# 将RGB图像输入模型,获取预测结果
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=draw_spec,
connection_drawing_spec=draw_spec
)
for idx, coord in enumerate(face_landmarks.landmark):
cx = int(coord.x * w)
cy = int(coord.y * h)
img = cv.putText(img, ' FACE DELECTED', (25, 50), cv.FONT_HERSHEY_SIMPLEX, 0.1,
(218, 112, 214), 1, 1)
img = cv.putText(img, str(idx), (cx, cy), cv.FONT_HERSHEY_SIMPLEX, 0.3,
(218, 112, 214), 1, 1)
else:
img = cv.putText(img, 'NO FACE DELECTED', (25, 50), cv.FONT_HERSHEY_SIMPLEX, 1.25,
(218, 112, 214), 1, 8)
#look_img(img)
# 连轮廓最左侧点
FL=results.multi_face_landmarks[0].landmark[234];
FL_X,FL_Y=int(FL.x*w),int(FL.y*h);FL_Color=(234,0,255)
img=cv.circle(img,(FL_X,FL_Y),radius,FL_Color,-1)
#look_img(img)
# 脸上侧边缘
FT=results.multi_face_landmarks[0].landmark[10];# 10 坐标为上图中标注的点的序号
FT_X,FT_Y=int(FT.x*w),int(FT.y*h);FT_Color=(231,141,181)
img=cv.circle(img,(FT_X,FT_Y),radius,FT_Color,-1)
#look_img(img)
# 下侧边缘
FB=results.multi_face_landmarks[0].landmark[152];# 152 坐标为上图中标注的点的序号
FB_X,FB_Y=int(FB.x*w),int(FB.y*h);FB_Color=(231,141,181)
img=cv.circle(img,(FB_X,FB_Y),radius,FB_Color,-1)
#look_img(img)
# 右侧
FR=results.multi_face_landmarks[0].landmark[454];# 454 坐标为上图中标注的点的序号
FR_X,FR_Y=int(FR.x*w),int(FR.y*h);FR_Color=(0,255,0)
img=cv.circle(img,(FR_X,FR_Y),radius,FR_Color,-1)
#look_img(img)
# 左眼左眼角
ELL=results.multi_face_landmarks[0].landmark[33];# 33坐标为上图中标注的点的序号
ELL_X,ELL_Y=int(ELL.x*w),int(ELL.y*h);ELL_Color=(0,255,0)
img=cv.circle(img,(ELL_X,ELL_Y),radius,ELL_Color,-1)
#look_img(img)
#左眼右眼角
ELR=results.multi_face_landmarks[0].landmark[133];# 133坐标为上图中标注的点的序号
ELR_X,ELR_Y=int(ELR.x*w),int(ELR.y*h);ELR_Color=(0,255,0)
img=cv.circle(img,(ELR_X,ELR_Y),radius,ELR_Color,-1)
#look_img(img)
# 右眼左眼角362
ERL=results.multi_face_landmarks[0].landmark[362];# 133坐标为上图中标注的点的序号
ERL_X,ERL_Y=int(ERL.x*w),int(ERL.y*h);ERL_Color=(233,255,128)
img=cv.circle(img,(ERL_X,ERL_Y),radius,ERL_Color,-1)
#look_img(img)
# 右眼右眼角263
ERR=results.multi_face_landmarks[0].landmark[263];# 133坐标为上图中标注的点的序号
ERR_X,ERR_Y=int(ERR.x*w),int(ERR.y*h);ERR_Color=(23,255,128)
img=cv.circle(img,(ERR_X,ERR_Y),radius,ERR_Color,-1)
#look_img(img)
# 从左往右六个点的横坐标
Six_X=np.array([FL_X,ELL_X,ELR_X,ERL_X,ERR_X,FR_X])
# 从最左到最右的距离
Left_Right=FR_X-FL_X
# 从左向右六个点的间隔的五个距离一并划归
Five_Distance=100*np.diff(Six_X)/Left_Right
# 两眼宽度的平均值
Eye_Width_Mean=np.mean((Five_Distance[1],Five_Distance[3]))
# 五个距离分别与两眼宽度均值的差
Five_Eye_Diff=Five_Distance-Eye_Width_Mean
# 求L2范数,作为颜值的指标
Five_Eye_Metrics=np.linalg.norm(Five_Eye_Diff)
# 三庭
# 眉心
MX=results.multi_face_landmarks[0].landmark[9];# 9 坐标为上图中标注的点的序号
MX_X,MX_Y=int(MX.x*w),int(MX.y*h);MX_Color=(29,123,234)
img=cv.circle(img,(MX_X,MX_Y),radius,MX_Color,-1)
look_img(img)
# 鼻翼下缘 2
NB=results.multi_face_landmarks[0].landmark[2];# 2 坐标为上图中标注的点的序号
NB_X,NB_Y=int(NB.x*w),int(NB.y*h);NB_Color=(180,187,28)
img=cv.circle(img,(NB_X,NB_Y),radius,NB_Color,-1)
#look_img(img)
# 嘴唇中心 13
LC=results.multi_face_landmarks[0].landmark[13];# 17 坐标为上图中标注的点的序号
LC_X,LC_Y=int(LC.x*w),int(LC.y*h);LC_Color=(0,0,258)
img=cv.circle(img,(LC_X,LC_Y),radius,LC_Color,-1)
#look_img(img)
# 嘴唇下缘 17
LB=results.multi_face_landmarks[0].landmark[17];# 17 坐标为上图中标注的点的序号
LB_X,LB_Y=int(LB.x*w),int(LB.y*h);LB_Color=(139,0,0)
img=cv.circle(img,(LB_X,LB_Y),radius,LB_Color,-1)
#look_img(img)
Six_Y=np.array([FT_Y,MX_Y,NB_Y,LC_Y,LB_Y,FB_Y])
Top_Down=FB_Y-FT_Y
Three_Section_Distance =100*np.diff(Six_Y)/Top_Down
Three_Section_Mrtric_A=np.abs(Three_Section_Distance[1]-sum(Three_Section_Distance[2:]))
# 鼻下到唇心距离 占第三庭的三分之一
Three_Section_Mrtric_B=np.abs(Three_Section_Distance[2]-sum(Three_Section_Distance[2:])/3)
#唇心到下巴尖距离 占 第三庭的二分之一
Three_Section_Mrtric_C=np.abs(sum(Three_Section_Distance[3:])-sum(Three_Section_Distance[2:])/2)
# 达芬奇
# 嘴唇左角 61
LL=results.multi_face_landmarks[0].landmark[61];# 61 坐标为上图中标注的点的序号
LL_X,LL_Y=int(LL.x*w),int(LL.y*h);LL_Color=(255,255,255)
img=cv.circle(img,(LL_X,LL_Y),radius,LL_Color,-1)
#look_img(img)
# 嘴唇右角 291
LR=results.multi_face_landmarks[0].landmark[291];# 291 坐标为上图中标注的点的序号
LR_X,LR_Y=int(LR.x*w),int(LR.y*h);LR_Color=(255,255,255)
img=cv.circle(img,(LR_X,LR_Y),radius,LR_Color,-1)
#look_img(img)
# 鼻子左缘 129
NL=results.multi_face_landmarks[0].landmark[129];# 291 坐标为上图中标注的点的序号
NL_X,NL_Y=int(NL.x*w),int(NL.y*h);NL_Color=(255,255,255)
img=cv.circle(img,(NL_X,NL_Y),radius,NL_Color,-1)
#look_img(img)
# 鼻子右缘 358
NR=results.multi_face_landmarks[0].landmark[358];# 358 坐标为上图中标注的点的序号
NR_X,NR_Y=int(NR.x*w),int(NR.y*h);NR_Color=(255,255,255)
img=cv.circle(img,(NR_X,NR_Y),radius,NR_Color,-1)
#look_img(img)
# 嘴宽为鼻宽的1.5/1.6倍
Da_Vinci=(LR.x-LL.x)/(NR.x-NL.x)
# 眉毛
# 左眉毛左眉角 46
EBLL=results.multi_face_landmarks[0].landmark[46];# 46 坐标为上图中标注的点的序号
EBLL_X,EBLL_Y=int(EBLL.x*w),int(EBLL.y*h);EBLL_Color=(255,355,155)
img=cv.circle(img,(EBLL_X,EBLL_Y),radius,EBLL_Color,-1)
#look_img(img)
# 左眉毛眉峰 105
EBLT=results.multi_face_landmarks[0].landmark[105];# 105 坐标为上图中标注的点的序号
EBLT_X,EBLT_Y=int(EBLT.x*w),int(EBLT.y*h);EBLT_Color=(255,355,155)
img=cv.circle(img,(EBLT_X,EBLT_Y),radius,EBLT_Color,-1)
#look_img(img)
#左眉毛右角 107
EBLR=results.multi_face_landmarks[0].landmark[107];# 107 坐标为上图中标注的点的序号
EBLR_X,EBLR_Y=int(EBLR.x*w),int(EBLR.y*h);EBLR_Color=(255,355,155)
img=cv.circle(img,(EBLR_X,EBLR_Y),radius,EBLR_Color,-1)
#look_img(img)
# 右眉毛左角 336
EBRL=results.multi_face_landmarks[0].landmark[336];# 336 坐标为上图中标注的点的序号
EBRL_X,EBRL_Y=int(EBRL.x*w),int(EBRL.y*h);EBRL_Color=(295,355,105)
img=cv.circle(img,(EBRL_X,EBRL_Y),radius,EBRL_Color,-1)
#look_img(img)
# 右眉毛眉峰 334
EBRT=results.multi_face_landmarks[0].landmark[334];# 334 坐标为上图中标注的点的序号
EBRT_X,EBRT_Y=int(EBRT.x*w),int(EBRT.y*h);EBRT_Color=( 355,155,155)
img=cv.circle(img,(EBRT_X,EBRT_Y),radius,EBRT_Color,-1)
#look_img(img)
# 右眉毛右角 276
EBRR=results.multi_face_landmarks[0].landmark[276];# 107 坐标为上图中标注的点的序号
EBRR_X,EBRR_Y=int(EBRR.x*w),int(EBRR.y*h);EBRR_Color=(155,305,195)
img=cv.circle(img,(EBRR_X,EBRR_Y),radius,EBRR_Color,-1)
#look_img(img)
# 眉头是否在眼角的正上方
EB_Metric_A=(EBLR_X-ELR_X)/Left_Right
EB_Metric_B=(EBRL_X-ERL_X)/Left_Right
EB_Metric_C=(EBLT_X-ELL_X)/Left_Right
EB_Metric_D=(EBRT_X-ERR_X)/Left_Right
EB_Metric_E=0.5*np.linalg.det([[EBLL_X,EBLL_Y,1],[ELL_X,ELL_Y,1],[NL_X,NL_Y,1]])/(Left_Right)**2
EB_Metric_F=0.5*np.linalg.det([[EBRR_X,EBRR_Y,1],[ERR_X,ERR_Y,1],[NR_X,NR_Y,1]])/(Left_Right)**2
cv.line(img,(EBLL_X,EBLL_Y),(ELL_X,ELL_Y),EBLL_Color,lw)
cv.line(img,(ELL_X,ELL_Y),(NL_X,NL_Y),EBLL_Color,lw)
cv.line(img,(EBLL_X,EBLL_Y),(NL_X,NL_Y),EBLL_Color,lw)
cv.line(img,(EBRR_X,EBRR_Y),(ERR_X,ERR_Y),EBLL_Color,lw)
cv.line(img,(EBRR_X,EBRR_Y),(NR_X,NR_Y),EBLL_Color,lw)
cv.line(img,(EBRR_X,EBRR_Y),(NR_X,NR_Y),EBLL_Color,lw)
#look_img(img)
#左内眼角上点 157
ELRT=results.multi_face_landmarks[0].landmark[157];# 157 坐标为上图中标注的点的序号
ELRT_X,ELRT_Y=int(ELRT.x*w),int(ELRT.y*h);ELRT_Color=(155,305,195)
img=cv.circle(img,(ELRT_X,ELRT_Y),radius,ELRT_Color,-1)
#look_img(img)
#左内眼角下点 154
ELRB=results.multi_face_landmarks[0].landmark[154];# 154 坐标为上图中标注的点的序号
ELRB_X,ELRB_Y=int(ELRB.x*w),int(ELRB.y*h);ELRB_Color=(155,305,195)
img=cv.circle(img,(ELRB_X,ELRB_Y),radius,ELRB_Color,-1)
#look_img(img)
#右内眼角上点 384
ERLT=results.multi_face_landmarks[0].landmark[384];# 384 坐标为上图中标注的点的序号
ERLT_X,ERLT_Y=int(ERLT.x*w),int(ERLT.y*h);ERLT_Color=(155,305,195)
img=cv.circle(img,(ERLT_X,ERLT_Y),radius,ERLT_Color,-1)
#look_img(img)
# 右内眼角下点 381
ERRB=results.multi_face_landmarks[0].landmark[381];# 384 坐标为上图中标注的点的序号
ERRB_X,ERRB_Y=int(ERRB.x*w),int(ERRB.y*h);ERRB_Color=(155,305,195)
img=cv.circle(img,(ERRB_X,ERRB_Y),radius,ERRB_Color,-1)
#look_img(img)
# 角度
vector_a=np.array([ELRT_X-ELR_X,ELRT_Y-ELR_Y])
vector_b=np.array([ELRB_X-ELR_X,ELRB_Y-ELR_Y])
cos=vector_a.dot(vector_b)/(np.linalg.norm(vector_a)*np.linalg.norm(vector_b))
EB_Metric_G=np.degrees(np.arccos(cos))
vector_a=np.array([ERLT_X-ERL_X,ERLT_Y-ERL_Y])
vector_b=np.array([ERRB_X-ERL_X,ERRB_Y-ERL_Y])
cos=vector_a.dot(vector_b)/(np.linalg.norm(vector_a)*np.linalg.norm(vector_b))
EB_Metric_H=np.degrees(np.arccos(cos))
# 可视化
cv.line(img,(FL_X,FT_Y),(FL_X,FB_Y),FL_Color,3)
cv.line(img,(ELL_X,FT_Y),(ELL_X,FB_Y),ELL_Color,3)
cv.line(img,(ELR_X,FT_Y),(ELR_X,FB_Y),ELR_Color,3)
cv.line(img,(ERL_X,FT_Y),(ERL_X,FB_Y),ERL_Color,3)
cv.line(img,(ERR_X,FT_Y),(ERR_X,FB_Y),ERR_Color,3)
cv.line(img,(FR_X,FT_Y),(FR_X,FB_Y),FR_Color,3)
cv.line(img,(FL_X,FT_Y),(FR_X,FT_Y),FT_Color,3)
cv.line(img,(FL_X,FB_Y),(FR_X,FB_Y),FB_Color,3)
cv.line(img,(FL_X,MX_Y),(FR_X,MX_Y),MX_Color,lw)
cv.line(img,(FL_X,NB_Y),(FR_X,NB_Y),NB_Color,lw)
cv.line(img,(FL_X,LC_Y),(FR_X,LC_Y),LC_Color,lw)
cv.line(img,(FL_X,LB_Y),(FR_X,LB_Y),LB_Color,lw)
scaler=1
img = cv.putText(img, 'Five Eye Metrics:.2f'.format(Five_Eye_Metrics), (25, 50), cv.FONT_HERSHEY_SIMPLEX, 1,
(218, 112, 214), 3, 10)
img = cv.putText(img, 'A:.2f'.format(Five_Eye_Diff[0]), (25, 100), cv.FONT_HERSHEY_SIMPLEX, 1,
(218, 112, 214), 3, 10)
img = cv.putText(img, 'B:.2f'.format(Five_Eye_Diff[2]), (25, 150), cv.FONT_HERSHEY_SIMPLEX, 1,
(218, 112, 214), 3, 10)
img = cv.putText(img, 'C:.2f'.format(Five_Eye_Diff[4]), (25, 200), cv.FONT_HERSHEY_SIMPLEX,1,
(218, 112, 214), 3, 10)
img = cv.putText(img, 'Three Scetion:.2f'.format(Three_Section_Mrtric_A), (25, 300), cv.FONT_HERSHEY_SIMPLEX,1,
(218, 112, 214), 3, 10)
img = cv.putText(img, '1/3:.2f'.format(Three_Section_Mrtric_B), (25, 400), cv.FONT_HERSHEY_SIMPLEX,1,
(218, 112, 214), 3, 10)
img = cv.putText(img, '1/2:.2f'.format(Three_Section_Mrtric_C), (25, 500), cv.FONT_HERSHEY_SIMPLEX,1,
(218, 112, 214), 3, 10)
img = cv.putText(img, 'Da Vinci:.2f'.format(Da_Vinci), (25, 600), cv.FONT_HERSHEY_SIMPLEX,1,
(218, 112, 214), 3, 10)
look_img(img)
cv.imwrite('images/01.png',img)
return Five_Eye_Metrics,Three_Section_Mrtric_A,Da_Vinci
#image_path ='images/frame.179000000.jpg'
#face_metric(image_path)
import os
#import cv2
def getFileList(dir, Filelist, ext=None):
"""
获取文件夹及其子文件夹中文件列表
输入 dir:文件夹根目录
输入 ext: 扩展名
返回: 文件路径列表
"""
newDir = dir
if os.path.isfile(dir):
if ext is None:
Filelist.append(dir)
else:
if ext in dir[-3:]: #jpg为-3/py为-2
Filelist.append(dir)
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir = os.path.join(dir, s)
getFileList(newDir, Filelist, ext)
return Filelist
org_img_folder = r'images/com'
# 检索文件
imglist = getFileList(org_img_folder, [], 'jpg')
face_dict = dict()
for image_path in imglist:
if image_path not in face_dict:
#face_dict['image'] = image_path
Five_Eye_Metrics,Three_Section_Mrtric_A,Da_Vinci=face_metric(image_path)
face_dict[image_path] = Five_Eye_Metrics#+Three_Section_Mrtric_A+Da_Vinci#[ Five_Eye_Metrics,Three_Section_Mrtric_A,Da_Vinci]
d_order=sorted(face_dict.items(),key=lambda x:x[1],reverse=True)6.人像美颜、人体美颜
PaddleHub实战——人像美颜 - 飞桨AI Studio
6.1瘦脸
6.2美白
6.3大眼
6.4姿态调整
6.5身宽比调整
import cv2
import paddlehub as hub
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
import math
src_img = cv2.imread('images/com/frame.384000.jpg')
module = hub.Module(name="face_landmark_localization")
result = module.keypoint_detection(images=[src_img])
tmp_img = src_img.copy()
for index, point in enumerate(result[0]['data'][0]):
# print(point)
# cv2.putText(img, str(index), (int(point[0]), int(point[1])), cv2.FONT_HERSHEY_COMPLEX, 3, (0,0,255), -1)
cv2.circle(tmp_img, (int(point[0]), int(point[1])), 2, (0, 0, 255), -1)
res_img_path = 'images/face_landmark.jpg'
cv2.imwrite(res_img_path, tmp_img)
img = mpimg.imread(res_img_path)
# 展示预测68个关键点结果
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
def whitening(img, face_landmark):
"""
美白
"""
# 简单估计额头所在区域
# 根据0号、16号点画出额头(以0号、16号点所在线段为直径的半圆)
radius=(np.linalg.norm(face_landmark[0] - face_landmark[16]) / 2).astype('int32')
center_abs=tuple(((face_landmark[0] + face_landmark[16]) / 2).astype('int32'))
angle=np.degrees(np.arctan((lambda l:l[1]/l[0])(face_landmark[16]-face_landmark[0]))).astype('int32')
face = np.zeros_like(img)
cv2.ellipse(face,center_abs,(radius,radius),angle,180,360,(255,255,255),2)
points=face_landmark[0:17]
hull = cv2.convexHull(points)
cv2.polylines(face, [hull], True, (255,255,255), 2)
index = face >0
face[index] = img[index]
dst = np.zeros_like(face)
# v1:磨皮程度
v1 = 3
# v2: 细节程度
v2 = 2
tmp1 = cv2.bilateralFilter(face, v1 * 5, v1 * 12.5, v1 * 12.5)
tmp1 = cv2.subtract(tmp1,face)
tmp1 = cv2.add(tmp1,(10,10,10,128))
tmp1 = cv2.GaussianBlur(tmp1,(2*v2 - 1,2*v2-1),0)
tmp1 = cv2.add(img,tmp1)
dst = cv2.addWeighted(img, 0.1, tmp1, 0.9, 0.0)
dst = cv2.add(dst,(10, 10, 10,255))
index = dst>0
img[index] = dst[index]
return img
# 美白
src_img = whitening(src_img, face_landmark)
cv2.imwrite(res_img_path, src_img)
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
res_img_path = 'images/res.jpg'
cv2.imwrite(res_img_path, src_img)7.抽取封面人像&模版生成封面图像
标题生成
1.视频转语音
from moviepy.video.io.VideoFileClip import VideoFileClip
# 将mp4文件转为mp3音频文件并返回其文件路径,生成路径仍在原路径中(需要先下载moviepy库)
def mp4_to_mp3(path):
try:
video = VideoFileClip(path)
audio = video.audio
# 设置生成的mp3文件路径
newPath = 'movies/whitebottle.wav'#path.replace('mp4', 'mp3')
audio.write_audiofile(newPath)
return newPath
except Exception as e:
print(e)
return None
mp4_to_mp3('movies/whitebottle.mp4')
#人声分离
!pip install spleeter
!spleeter separate -p spleeter:2stems -o data/ ./movies/whitebottle.wav2语音转文字
#!/usr/bin/env python3
!pip3 install vosk
!git clone https://github.com/alphacep/vosk-api
%cd vosk-api/python/example
!wget https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip
!unzip vosk-model-small-cn-0.22.zip
!mv vosk-model-small-cn-0.22 model
#然后在输入以下代码
from vosk import Model, KaldiRecognizer, SetLogLevel
#import sys
import os
import wave
import subprocess
import json
SetLogLevel(0)
if not os.path.exists("model"):
print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit (1)
sample_rate=16000
model = Model("model")
rec = KaldiRecognizer(model, sample_rate)
process = subprocess.Popen(['ffmpeg', '-loglevel', 'quiet', '-i',
'/content/vacals.wav',#sys.argv[1],
'-ar', str(sample_rate) , '-ac', '1', '-f', 's16le', '-'],
stdout=subprocess.PIPE)
f = open("result.txt", "w+")
while True:
data = process.stdout.read(10000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
re = rec.Result()
print(re)
re = json.loads(re)
f.write(re['text'] + '\\n')
else:
print(rec.PartialResult())
f.close()
抽取的结果,通用域asr在域用还是有识别错误地方
只最金的投感货家号我是安阳机日项于欢迎来到我频道,那今天我们聊一下曾经哇歪电s的这个白酒,那这个白酒呢在二嗷年似乎啊就是不太厉害了那整一个这个跌幅也是比较大的,那白酒板块近期的一个基本面怎么样以及在二年是否说会有机会呢我们今天来看一看白酒版块呢在三月二十八号啊有一个相对的一个见底近期的话是相段说反复升荡呢那白土的资本面是怎么样的呢首先来看一下就是区域次高端龙头是表现尝试一季度业绩有望出现开门红,但二二年的白酒龙头春节动销啊这个表现是相对合预期的,但我们从价格大来看一下二一年的春节的需求是受到了经济疲软的影响,终端的这个动销是出现比较大一分化的纳各价格带消费是像龙头区集中,但其中像区域次高端龙头它表现是非常出色的,那第二点就是从去来看呢受一级音销较小以及人口流入较大的这个省份最收欲的像灰酒和苏九龙头它的终端动销是比旺盛它第三个是从实际回款的情况来看各龙头基本完成了旺季回款一个任务那此外三四月份为白酒的相对冻销率一个淡机,但疫情对九起的短期业绩影响是相对有限的,那综的考虑忘记了一个表现以及回快里完成度疫情影响等等因素,那预计龙头九起一季度的业绩是有望啊这个出现而不错的一个情不错的那目前向贵州茅台经市元山西汾酒酒归九等分别公布了二零二二年的一季度业绩预告或者是一到二月份的一个经营数据预告但公告的数据也念制的这个一季度业绩的确是不错那白酒基本面在整个消费中还是最对占优的而高端白酒在整个白酒的这个业绩呢有失区联性比高的那不过就是短期受到这个疫情的一个反复和这个居民收入低理一的影响消费板块啊在市场风格上也不受这个市场的代见那本轮疫擎对经济的冲击啊非常大那当下经济这个增长压力仍然是这个市场中最主要的矛盾这使的近期的一个市场主线基本是什么地产股之类的阿庆的台词就是大家认为经济很差啊所以这里面啊就是短期来输的话啊这个消费板块可能还会出现一定的回调但是我们可以看到啊就是近两年的市场是非常常类卷的比方说在四月一号啊就是旅游板块出现大脑就是尽管当下一起并没有什么出现什么拐点但是已经有资金开始就是强跑一期反转的逻辑而白酒作为消费中基本面最强劲的一个板块的话落后续市场开始关注这个疫情反转的方向也有望取这个提前去关注那短期的话来说而不。确定是比较大的但是中期这个白酒的基本面啊是非常好的所以这里面看长的朋友啊这面是可以慢慢徐续图之如果说看断的朋友还需要观。望我是按想镜的小于直甲最近的囤货关注不明哦
3.文字抽取关键主题(lda)
3.1抽取式提取(textrank、graphpoint、fastsum、lda)
3.2生成式提取(bert)
4.封面标题生成
4.1基于模版生成
4.2文本直接生成标题(gpt2、)
GitHub - liucongg/GPT2-NewsTitle: Chinese NewsTitle Generation Project by GPT2.带有超级详细注释的中文GPT2新闻标题生成项目。
短视频运营短视频剪辑 ③ ( 添加字幕 | 智能识别字幕 | 修改字幕 | 字幕预设 | 字幕换行 | 使用字幕作为封面主题 )
文章目录
一、添加字幕 ( 智能识别字幕 )
在 素材 面板中 , 选择 " 文本 " 选项卡 , " 智能字幕 " , 然后选择 " 识别字幕 " , 即可设置字幕 ;

点击开始识别后 , 会将视频中的人声 , 自动转为字幕 ;

如果视频中没有人声 , 会提示 , 该视频没有人声 , 未识别到字幕 ;
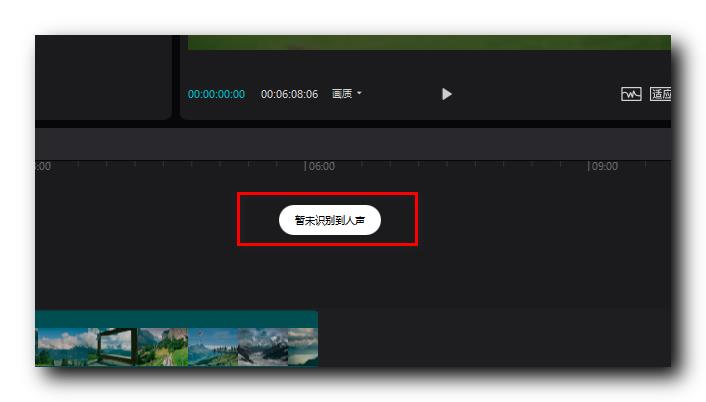
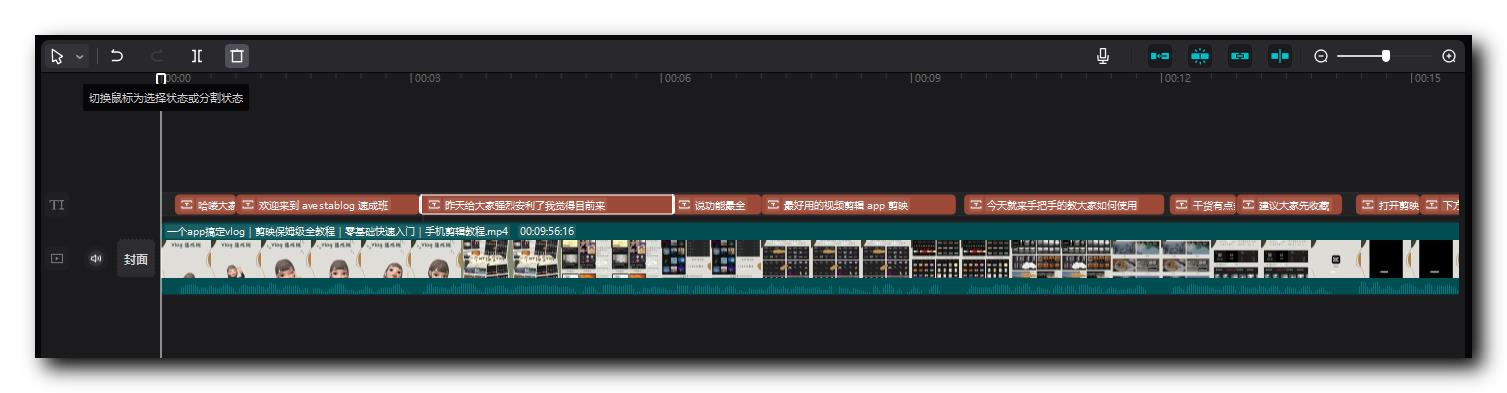
如果成功识别出字幕 , 会显示如下内容 , 在时间轴视频的上方 , 会出现 TI 字幕对应的时间轴 ;
二、修改字幕 ( 字幕预设 | 字幕换行 )
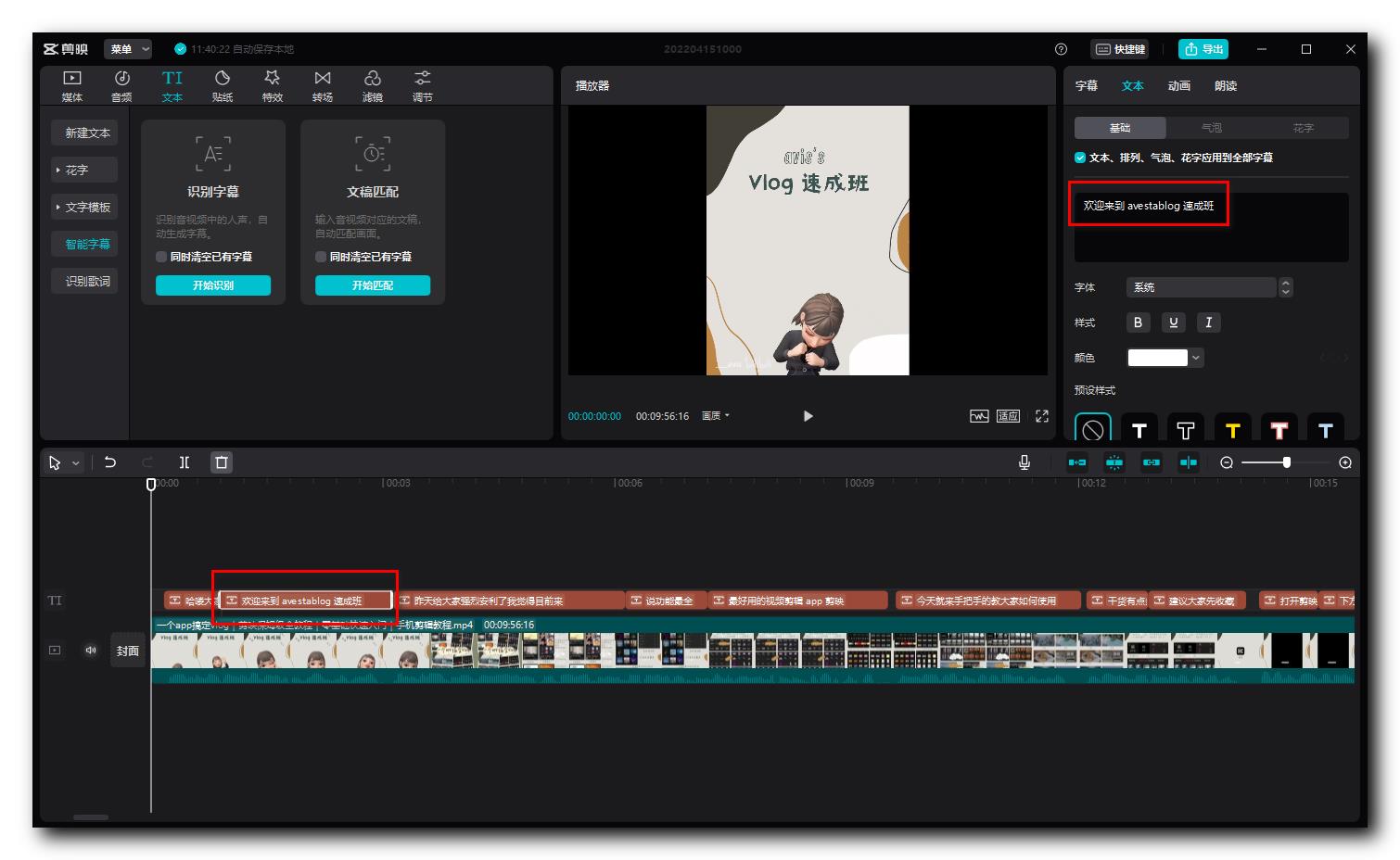
在 " 时间轴 " 上 , 选择 智能识别 的字幕 , 可以在右上角的 " 文本 " 面板 , 修改字幕的文字 , 字体 , 样式 , 颜色 , 预设 等属性 ;
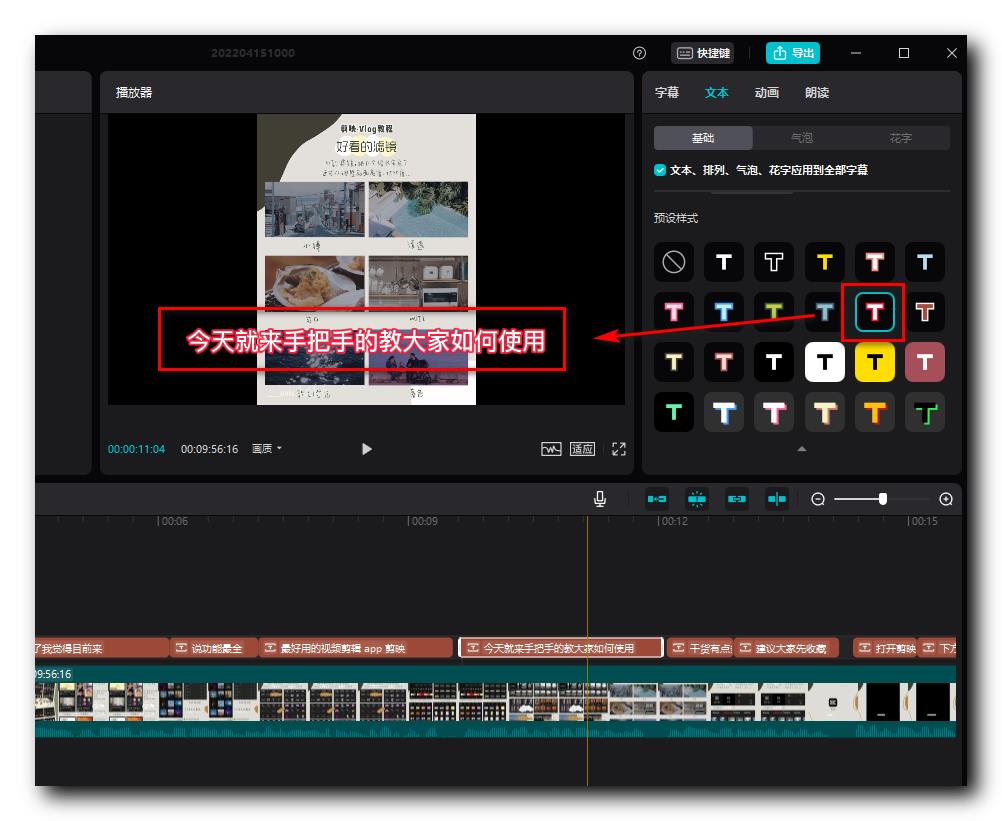
选择  预设样式 , 字幕就会变成如下样式 :
预设样式 , 字幕就会变成如下样式 :
如果觉得文本太长 , 可以在 文本 中 , 进行换行操作 ;
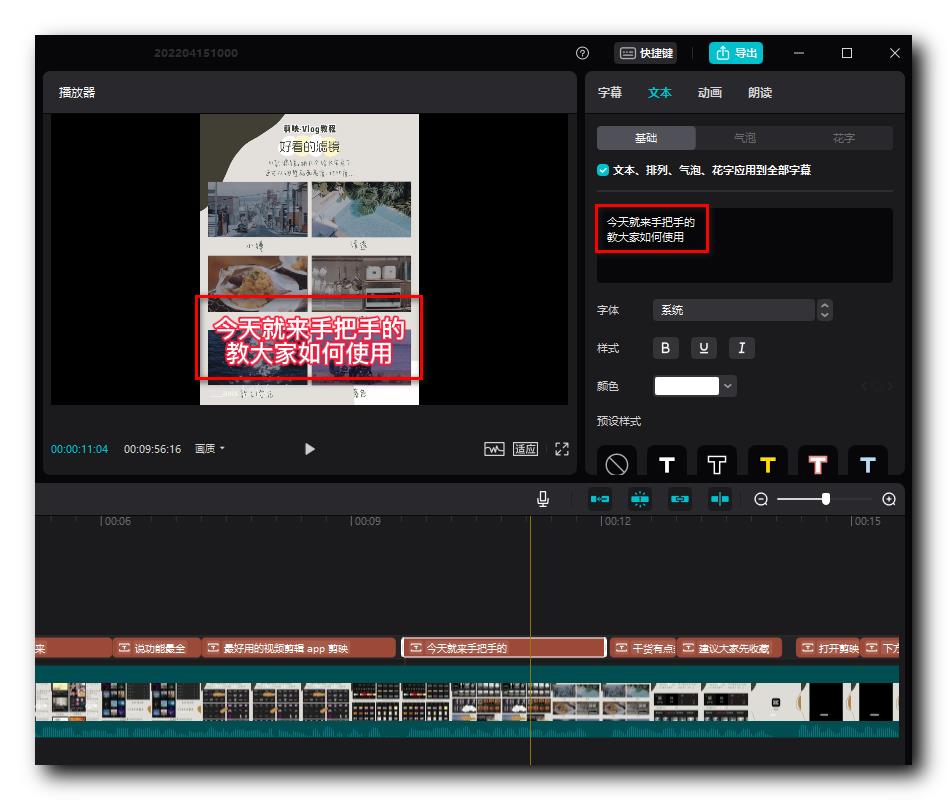
三、使用字幕作为封面主题
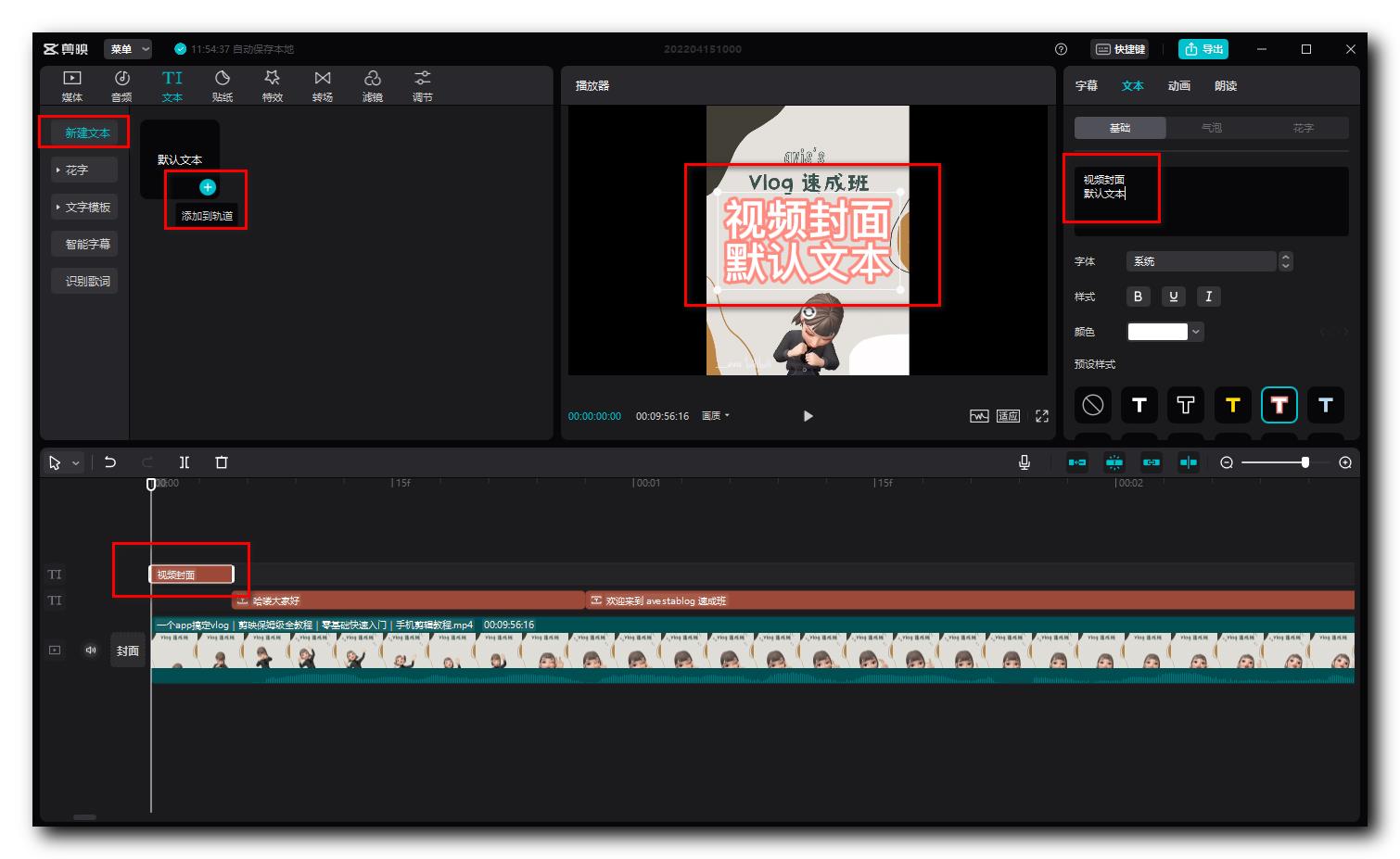
在 左上角 素材库中 文本 选项卡 中 , 选择 " 新建文本 " , 然后选择 " 默认文本 " , 点击默认文本 右下角的 加号 按钮 , 将其添加到轨道中 , 然后拖动该字幕位于视频的位置 ;
右上角的 面板中 , 编辑该字幕内容 , 为字幕选择样式 , 最终在 播放器 中查看该 视频标题 字幕的样式 ;
以上是关于短视频封面抽取和标题自动化生成的主要内容,如果未能解决你的问题,请参考以下文章
Python+selenium 实现自动投稿自动发布哔哩哔哩B站短视频实例演示
Python+selenium 实现自动投稿自动发布哔哩哔哩B站短视频实例演示
短视频运营短视频剪辑 ③ ( 添加字幕 | 智能识别字幕 | 修改字幕 | 字幕预设 | 字幕换行 | 使用字幕作为封面主题 )