Android 视频播放延时抖动那些事
Posted 六月初曲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android 视频播放延时抖动那些事相关的知识,希望对你有一定的参考价值。
一、背景
局域网模式下,android手机播放相机视频流,使用Android 自带MediaCodec解码,视频延时较大,约700ms左右。使用FFmpeg软解+转码,延时200ms左右,但是画面卡顿抖动严重。
视频帧信息
帧率:30fps
码率:1Mbps
GOP:10
size:720P
帧格式:IPPP(AUD SPS PPS)
二、排查过程
-
硬件解码
因不同芯片video code不同,加速方式也不同,验证过瑞芯微的3399硬件解码,没有视频延迟这些问题,华为P30也没有这种问题,红米手机就会出现这种问题。也查过网络资料,是由于在解码过程中,AMediaCodec会缓存一定数据帧,导致视频播放往后推迟,调用“AMediaCodec_getInputBuffer”和“AMediaCodec_dequeueOutputBuffer”,延时是非常小的,大约1~5ms以内。 -
软件解码
因无法修改AMediaCodec,所以考虑使用FFmpeg进行解码,调用“avcodec_send_packet”和“avcodec_receive_frame”接口,在调用“sws_scale”进行转码。完成一个GOP解码转码耗时在400ms左右,I帧解码需要80ms,P帧平均帧也在35ms左右。 -
网络抖动
网络抖动是音视频优化的干扰指标之一,这里我们没有做特殊数据,只在发送端加了一个pcing平缓发送机制,测试结果还是一样,延时抖动。
三、解决方法
结合上面的排查项,我们在软解解码中 “完成一个GOP解码转码耗时在400ms左右”,在背景提到,我们的视频源GOP是10,帧率30,那就1秒有三个GOP,一个GOP是333ms,但是解码转码需要400ms,这就出现问题了,解码实现赶不上接收,导致后面的接收帧根本就来不及解码,会进行主动抛帧,视频就会出现一卡一卡了。
着重排查解码和转码两个接口,去掉转码接口,抓取耗时日志,结果:一帧I帧解码耗时平均在,30~60ms左右,相比80,少了接近1半的时间,因为解码接口,我们是需要用FFmpeg的,但是转码接口,我回想起webrtc中嵌入式解码也用到libyuv,然后网上查了一下,果然有网友也出现这种问题:使用libyuv替换sws_scale,然后果断使用libyuv替换。
最后使用FFmpeg + libyuv,终于解决了Android手机播放视频卡顿问题。
出现这种情况还是和硬件有关,华为P30无论在硬解码或FFmpeg解码转码,都不会出现卡顿延时问题,软件解码极度依赖CPU处理。
关于Android性能监控Matrix那些事?你知道那些?(完)
关于Android性能监控Matrix那些事?你知道那些?(上)
关于Android性能监控Matrix那些事?你知道那些(中)?
视频也更新了:微信Matrix卡顿监控实战,函数自动埋点监控方案
今天抽空把后面的更完了,首先我们先看一下整体目录:
1.
Matrix介绍
2.内存泄漏监控及原理介绍
3.内存泄漏监控源码分析
4.Hprof文件分析
5.卡顿监控
6.卡顿监控源码解析
7.插桩
8.资源优化
9.I/O监控及原理解析
七丶插桩
7.1.Gradle插件配置
Matrix的 Gradle 插件的实现类为 MatrixPlugin,主要做了三件事:
- 添加
Extension,用于提供给用户自定义配置选项
class MatrixPlugin implements Plugin<Project>
@Override
void apply(Project project)
project.extensions.create("matrix", MatrixExtension)
project.matrix.extensions.create("trace", MatrixTraceExtension)
project.matrix.extensions.create("removeUnusedResources", MatrixDelUnusedResConfiguration)
其中 trace 可选配置如下:
public class MatrixTraceExtension
boolean enable; // 是否启用插桩功能
String baseMethodMapFile; // 自定义的方法映射文件,下面会说到
String blackListFile; // 该文件指定的方法不会被插桩
String customDexTransformName;
removeUnusedResources 可选配置如下:
class MatrixDelUnusedResConfiguration
boolean enable // 是否启用
String variant // 指定某一个构建变体启用插桩功能,如果为空,则所有的构建变体都启用
boolean needSign // 是否需要签名
boolean shrinkArsc // 是否裁剪 arsc 文件
String apksignerPath // 签名文件的路径
Set<String> unusedResources // 指定要删除的不使用的资源
Set<String> ignoreResources // 指定不需要删除的资源
读取配置,如果启用插桩,则执行 MatrixTraceTransform,统计方法并插桩
// 在编译期执行插桩任务(project.afterEvaluate 代表 build.gradle 文件执行完毕),这是因 为 proguard 操作是在该任务之前就完成的
project.afterEvaluate
android.applicationVariants.all variant ->
if (configuration.trace.enable) // 是否启用,可在 gradle 文件中配置
MatrixTraceTransform.inject(project, configuration.trace, variant.getVariantData().getScope())
... // RemoveUnusedResourcesTask
读取配置,如果启用 removeUnusedResources 功能,则执行 RemoveUnusedResourcesTask,删除不需要的资源
7.2.方法统计及插桩
7.2.1.配置 Transform
MatrixTraceTransform 的 inject 方法主要用于读取配置,代理transformClassesWithDexTask:
public class MatrixTraceTransform extends Transform
public static void inject(Project project, MatrixTraceExtension extension, VariantScope variantScope)
... // 根据参数生成 Configuration 变量 config
String[] hardTask = getTransformTaskName(extension.getCustomDexTransformName(), variant.getName());
for (Task task : project.getTasks())
for (String str : hardTask)
if (task.getName().equalsIgnoreCase(str) && task instanceof TransformTask)
Field field = TransformTask.class.getDeclaredField("transform");
field.set(task, new MatrixTraceTransform(config, task.getTransform()));
break;
// 这两个 Transform 用于把 Class 文件编译成 Dex 文件
// 因此,需要在这两个 Transform 执行之前完成插桩等工作
private static String[] getTransformTaskName(String customDexTransformName, String buildTypeSuffix)
return new String[]
"transformClassesWithDexBuilderFor" + buildTypeSuffix,
"transformClassesWithDexFor" + buildTypeSuffix,
;;
MatrixTraceTransform 的主要配置如下:
- 处理范围为整个项目(包括当前项目、子项目、依赖库等)
- 处理类型为
Class文件
public class MatrixTraceTransform extends Transform
@Override
public Set<QualifiedContent.ContentType> getInputTypes() return TransformManager.CONTENT_CLASS;
@Override
public Set<QualifiedContent.Scope> getScopes() return TransformManager.SCOPE_FULL_PROJECT;
7.2.2.执行方法统计及插桩任务
transform 主要分三步执行:
- 根据配置文件分析方法统计规则,比如混淆后的类名和原始类名之间的映射关系、不需要插桩的法黑名单等
private void doTransform(TransformInvocation transformInvocation) throws
ExecutionException, InterruptedException
// 用于分析和方法统计相关的文件,如 mapping.txt、blackMethodList.txt 等
// 并将映射规则保存到 mappingCollector、collectedMethodMap 中
futures.add(executor.submit(new ParseMappingTask(mappingCollector, collectedMethodMap, methodId)));
统计方法及其 ID,并写入到文件中
private void doTransform(TransformInvocation transformInvocation)
MethodCollector methodCollector = new MethodCollector(executor, mappingCollector, methodId, config, collectedMethodMap);
methodCollector.collect(dirInputOutMap.keySet(), jarInputOutMap.keySet());
插桩
private void doTransform(TransformInvocation transformInvocation)
MethodTracer methodTracer = new MethodTracer(executor, mappingCollector, config, methodCollector.getCollectedMethodMap(), methodCollector.getCollectedClassExtendMap());
methodTracer.trace(dirInputOutMap, jarInputOutMap);
7.2.3.分析方法统计规则
ParseMappingTask 主要用于分析方法统计相关的文件,如 mapping.txt(ProGuard 生成的)、blackMethodList.txt 等,并将映射规则保存到 HashMap 中。
mapping.txt 是 ProGuard 生成的,用于映射混淆前后的类名/方法名,内容如下:
MTT.ThirdAppInfoNew -> MTT.ThirdAppInfoNew: // oldClassName -> newClassName
java.lang.String sAppName -> sAppName // oldMethodName -> newMethodName
java.lang.String sTime -> sTime
...
blackMethodList.txt 则用于避免对特定的方法插桩,内容如下:
[package]
-keeppackage com/huluxia/logger/
-keepmethod com/example/Application attachBaseContext (Landroid/content/Context;)V
...
如果有需要,还可以指定 baseMethodMapFile,将自定义的方法及其对应的方法 id 写入到一个文件中,内容格式如下:
// 方法 id、访问标志、类名、方法名、描述
1,1,eu.chainfire.libsuperuser.Application$1 run ()V
2,9,eu.chainfire.libsuperuser.Application toast
(Landroid.content.Context;Ljava.lang.String;)V
上述选项可在 gradle 文件配置,示例如下:
matrix
trace
enable = true
baseMethodMapFile = "projectDir.absolutePath/baseMethodMapFile.txt"
blackListFile = "projectDir.absolutePath/blackMethodList.txt"
7.2.4.方法统计
顾名思义,MethodCollector 用于收集方法,它首先会把方法封装为 TraceMethod,并分配方法 id,再保存到 HashMap,最后写入到文件中。为此,首先需要获取所有 class 文件:
public void collect(Set<File> srcFolderList, Set<File> dependencyJarList) throws
ExecutionException, InterruptedException
for (File srcFile : srcFolderList)
...
for (File classFile : classFileList)
futures.add(executor.submit(new CollectSrcTask(classFile)));
for (File jarFile : dependencyJarList)
futures.add(executor.submit(new CollectJarTask(jarFile)));
接着,借助 ASM 访问每一个 Class 文件:
class CollectSrcTask implements Runnable
@Override
public void run()
InputStream is = new FileInputStream(classFile);
ClassReader classReader = new ClassReader(is);
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_MAXS);
ClassVisitor visitor = new TraceClassAdapter(Opcodes.ASM5, classWriter);
classReader.accept(visitor, 0);
及 Class 文件中的方法:
private class TraceClassAdapter extends ClassVisitor
@Override
public MethodVisitor visitMethod(int access, String name, String desc,
String signature, String[] exceptions)
if (isABSClass) // 抽象类或接口不需要统计
return super.visitMethod(access, name, desc, signature, exceptions);
else
return new CollectMethodNode(className, access, name, desc, signature, exceptions);
最后,记录方法数据,并保存到 HashMap 中:
private class CollectMethodNode extends MethodNode
@Override
public void visitEnd()
super.visitEnd();
// 将方法数据封装为 TraceMethod
TraceMethod traceMethod = TraceMethod.create(0, access, className, name, desc);
// 是否需要插桩,blackMethodList.txt 中指定的方法不会被插桩
boolean isNeedTrace = isNeedTrace(configuration, traceMethod.className, mappingCollector);
// 过滤空方法、get & set 方法等简单方法
if ((isEmptyMethod() || isGetSetMethod() || isSingleMethod()) && isNeedTrace)
return;
// 保存到 HashMap 中
if (isNeedTrace && !collectedMethodMap.containsKey(traceMethod.getMethodName()))
traceMethod.id = methodId.incrementAndGet();
collectedMethodMap.put(traceMethod.getMethodName(), traceMethod);
incrementCount.incrementAndGet();
else if (!isNeedTrace && !collectedIgnoreMethodMap.containsKey(traceMethod.className))
... // 记录不需要插桩的方法
统计完毕后,将上述方法及其 ID 写入到一个文件中——因为之后上报问题只会上报 method id,因此需要根据该文件来解析具体的方法名及其耗时。
虽然上面的代码很长,但作用实际很简单:访问所有 Class 文件中的方法,记录方法 ID,并写入到文件中。
需要注意的细节有:
- 统计的方法包括应用自身的、
JAR依赖包中的,以及额外添加的 ID 固定的dispatchMessage方法 - 抽象类或接口类不需要统计
- 空方法、
get & set方法等简单方法不需要统计 blackMethodList.txt中指定的方法不需要统计
7.2.5.插桩
和方法统计一样,插桩也是基于 ASM 实现的,首先同样要找到所有 Class 文件,再针对文件中的每一个方法进行处理。
处理流程主要包含四步:
- 进入方法时执行 ·AppMethodBeat.i·,传入方法 ID,记录时间戳
public final static String MATRIX_TRACE_CLASS =
"com/tencent/matrix/trace/core/AppMethodBeat";
private class TraceMethodAdapter extends AdviceAdapter
@Override
protected void onMethodEnter()
TraceMethod traceMethod = collectedMethodMap.get(methodName);
if (traceMethod != null) // 省略空方法、set & get 等简单方法
mv.visitLdcInsn(traceMethod.id);
mv.visitMethodInsn(INVOKESTATIC,
TraceBuildConstants.MATRIX_TRACE_CLASS, "i", "(I)V", false);
2.退出方法时执行 AppMethodBeat.o,传入方法 ID,记录时间戳
private class TraceMethodAdapter extends AdviceAdapter
@Override
protected void onMethodExit(int opcode) \\
TraceMethod traceMethod = collectedMethodMap.get(methodName);
if (traceMethod != null)
... // 跟踪 onWindowFocusChanged 方法,计算启动耗时
mv.visitLdcInsn(traceMethod.id);
mv.visitMethodInsn(INVOKESTATIC,
TraceBuildConstants.MATRIX_TRACE_CLASS, "o", "(I)V", false);
3.如果是 Activity,并且没有 onWindowFocusChanged 方法,则插入该方法
private class TraceClassAdapter extends ClassVisitor
@Override
public void visitEnd()
// 如果是 Activity,并且不存在 onWindowFocusChanged 方法,则插入该方法,用于统计 Activity 启动时间
if (!hasWindowFocusMethod && isActivityOrSubClass && isNeedTrace)
insertWindowFocusChangeMethod(cv, className);
super.visitEnd();
4.跟踪 onWindowFocusChanged 方法,退出时执行 AppMethodBeat.at,计算启动耗时
public final static String MATRIX_TRACE_CLASS = "com/tencent/matrix/trace/core/AppMethodBeat";
private void traceWindowFocusChangeMethod(MethodVisitor mv, String classname)
mv.visitMethodInsn(Opcodes.INVOKESTATIC, TraceBuildConstants.MATRIX_TRACE_CLASS, "at", "(Landroid/app/Activity;Z)V", false);
public class AppMethodBeat implements BeatLifecycle
public static void at(Activity activity, boolean isFocus)
for (IAppMethodBeatListener listener : listeners)
listener.onActivityFocused(activityName);
StartupTracer 就是 IAppMethodBeatListener 的实现类。
7.2.6.总结
Matrix 的 Gradle 插件的实现类为 MatrixPlugin,主要做了三件事:
- 添加
Extension,用于提供给用户自定义配置选项 - 读取
extension配置,如果启用trace功能,则执行MatrixTraceTransform,统计方法并插桩 - 读取
extension配置,如果启用removeUnusedResources功能,则执行RemoveUnusedResourcesTask,删除不需要的资源
需要注意的是,插桩任务是在编译期执行的,这是为了避免对混淆操作产生影响。因为 proguard 操作是在该任务之前就完成的,意味着插桩时的 class 文件已经被混淆过的。而选择 proguard 之后去插桩,是因为如果提前插桩会造成部分方法不符合内联规则,没法在 proguard 时进行优化,最终导致程序方法数无法减少,从而引发方法数过大问题transform 主要分三步执行:
- 根据配置文件(
mapping.txt、blackMethodList.txt、baseMethodMapFile)分析方法统计规则,比如混淆后的类名和原始类名之间的映射关系、不需要插桩的方法黑名单等 - 借助 ASM 访问所有
Class文件的方法,记录其 ID,并写入到文件中(methodMapping.txt) - 插桩
插桩处理流程主要包含四步:
- 进入方法时执行
AppMethodBeat.i,传入方法 ID,记录时间戳 - 退出方法时执行
AppMethodBeat.o,传入方法 ID,记录时间戳 - 如果是
Activity,并且没有onWindowFocusChanged方法,则插入该方法 - 跟踪
onWindowFocusChanged方法,退出时执行AppMethodBeat.at,计算启动耗时
值得注意的细节有:
- 统计的方法包括应用自身的、JAR 依赖包中的,以及额外添加的 ID 固定的
dispatchMessage方法 - 抽象类或接口类不需要统计
- 空方法、
get & set方法等简单方法不需要统计 blackMethodList.txt中指定的方法不需要统计
八丶资源优化
除了插桩之外,Matrix 还会根据用户配置选择是否执行资源优化的功能,以删除不必要的资源文件。
8.1.arsc 文件格式
Matrix 资源优化的其中一个功能是裁剪 resources.arsc,分析该功能之前,先简单了解一下 arsc 的文件格式。
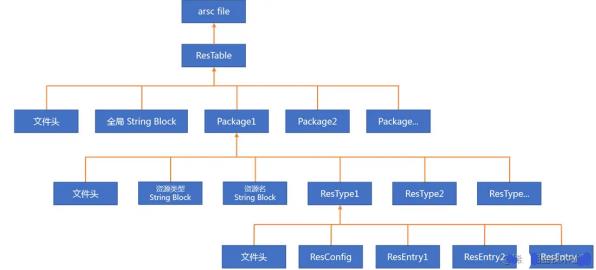
首先介绍一下 arsc 文件中的几个概念:
Chunk,指一个数据块,下面介绍的Table、Package、StringBlock、Type的都是Chunk,都有文件头、类型、size、对齐填充等信息Resource Table,一个arsc文件对应一个Resource TablePackage,用于描述一个包,一个Table对应多个Package,而packageID即是资源resID的最高八位,一般来说系统 android 的是 1(0x01),普通的例如com.tencent.mm会是 127(0x7f),剩下的是从 2 开始起步,也可以在aapt中指定。String Block,一个Table有一个全局的字符串资源池,一个Package有一个存储资源类型的字串资源池,一个储存资源名的字符串资源池Resource Type,资源类型,比如attr、drawable、layout、id、color、anim等,一个Package对应多个TypeConfig,用于描述资源的维度,例如横竖屏,屏幕密度,语言等,一个Type对应一个ConfigEntry,一个Type对应多个Entry,例如drawable-mdpi中有icon1.png、icon2.png两个drawable,那在mdpi这个Type中就存在两个entry
文件结构如下图所示:
8.2.删除未使用的资源
下面开始分析 Matrix 是怎么执行资源优化的。
Matrix 首先会获取 apk 文件、R 文件、签名配置文件等文件信息:
String unsignedApkPath = output.outputFile.getAbsolutePath();
removeUnusedResources(unsignedApkPath,
project.getBuildDir().getAbsolutePath() +
"/intermediates/symbols/$variant.name/R.txt",
variant.variantData.variantConfiguration.signingConfig);
接着,确定需要删除的资源信息,包括资源名及其 ID:
// 根据配置获取需要删除的资源
Set<String> ignoreRes = project.extensions.matrix.removeUnusedResources.ignoreResources;
Set<String> unusedResources = project.extensions.matrix.removeUnusedResources.unusedResources;
Iterator<String> iterator = unusedResources.iterator();
String res = null;
while (iterator.hasNext())
res = iterator.next();
if (ignoreResource(res)) // 指定忽略的资源不需要删除
iterator.remove();
// 读取 R 文件,保存资源名及对应的 ID 到 resourceMap 中
Map<String, Integer> resourceMap = new HashMap();
Map<String, Pair<String, Integer>[]> styleableMap = new HashMap();
File resTxtFile = new File(rTxtFile);
readResourceTxtFile(resTxtFile, resourceMap, styleableMap); // 读取 R 文件
// 将 unusedResources 中的资源放到 removeResources 中
Map<String, Integer> removeResources = new HashMap<>();
for (String resName : unusedResources)
if (!ignoreResource(resName))
// 如果资源会被删除,那么将它从 resourceMap 中移除
removeResources.put(resName, resourceMap.remove(resName));
之后就可以删除指定的资源了,删除方法是创建一个新的 apk 文件,并且忽略不需要的资源:
for (ZipEntry zipEntry : zipInputFile.entries())
if (zipEntry.name.startsWith("res/"))
String resourceName = entryToResouceName(zipEntry.name);
if (removeResources.containsKey(resourceName)) // 需要删除的资源不会写入到 新文件中
continue;
else // 将正常的资源信息写入到新的 apk 文件中
addZipEntry(zipOutputStream, zipEntry, zipInputFile);
如果启用了 shrinkArsc 功能,那么,还需要修改 arsc 文件,移除掉已删除的资源信息:
if (shrinkArsc && zipEntry.name.equalsIgnoreCase("resources.arsc") && unusedResources.size() > 0)
File srcArscFile = new File(inputFile.getParentFile().getAbsolutePath() + "/resources.arsc");
File destArscFile = new File(inputFile.getParentFile().getAbsolutePath() + "/resources_shrinked.arsc");
// 从 arsc 文件中读取资源信息
ArscReader reader = new ArscReader(srcArscFile.getAbsolutePath());
ResTable resTable = reader.readResourceTable();
// 遍历需要删除的资源列表,将对应的资源信息从 arsc 文件中移除
for (String resName : removeResources.keySet())
ArscUtil.removeResource(resTable, removeResources.get(resName), resName);
// 将裁剪后的 ResTable 写入到新的 arsc 文件中
ArscWriter writer = new ArscWriter(destArscFile.getAbsolutePath());
writer.writeResTable(resTable);
// 将裁剪后的 arsc 文件写入到新的 apk 中
addZipEntry(zipOutputStream, zipEntry, destArscFile);
移除的方法是将其 Entry 置为 null:
public static void removeResource(ResTable resTable, int resourceId, String resourceName) throws IOException
ResPackage resPackage = findResPackage(resTable, getPackageId(resourceId)); // 找到该 resId 对应的 package
if (resPackage != null)
List<ResType> resTypeList = findResType(resPackage, resourceId);
for (ResType resType : resTypeList) // 遍历 package 中的 ResType,找到对 应类型
int entryId = getResourceEntryId(resourceId); // 再找到对应的 entry
resType.getEntryTable().set(entryId, null); // 设置为 null
resType.getEntryOffsets().set(entryId, ArscConstants.NO_ENTRY_INDEX);
resType.refresh();
resPackage.refresh();
resTable.refresh();
以上,移除不必要的资源后的新的 apk 文件就写入完毕了。
8.3.总结
arsc 文件结构:
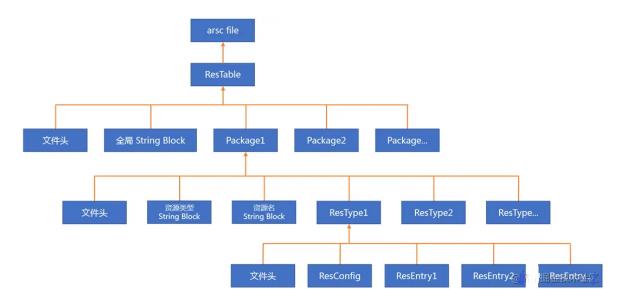
RemoveUnusedResourcesTask 执行步骤如下:
- 获取
apk文件、R 文件、签名配置文件等文件信息 - 根据用户提供的
unusedResource文件及 R 文件确定需要删除的资源信息,包括资源名及其 ID - 删除指定的资源,删除方法是在写入新的 apk 文件时,忽略该资源
- 如果启用了
shrinkArsc功能,那么,修改arsc文件,移除掉已删除的资源信息,移除方法是将其Entry置为null - 其它数据原封不动地写入到新的 apk 文件中
九丶I/O 监控及原理解析
9.1.使用
Matrix 中用于 I/O 监控的模块是 IOCanary,它是一个在开发、测试或者灰度阶段辅助发现 I/O 问题的
工具,目前主要包括文件 I/O 监控和 Closeable Leak 监控两部分。
具体的问题类型有 4 种:
- 在主线程执行了 IO 操作
- 缓冲区太小
- 重复读同一文件
- 资源泄漏
IOCanary 采用 hook(ELF hook) 的方案收集 IO 信息,代码无侵入,从而使得开发者可以无感知接入。
配置并启动 IOCanaryPlugin 即可:
IOCanaryPlugin ioCanaryPlugin = new IOCanaryPlugin(new IOConfig.Builder()
.dynamicConfig(dynamicConfig)
.build());
builder.plugin(ioCanaryPlugin);
与 IO 相关的配置选项有:
enum ExptEnum
// 监测在主线程执行 IO 操作的问题
clicfg_matrix_io_file_io_main_thread_enable,
clicfg_matrix_io_main_thread_enable_threshold, // 读写耗时
// 监测缓冲区过小的问题
clicfg_matrix_io_small_buffer_enable,
clicfg_matrix_io_small_buffer_threshold, // 最小 buffer size
clicfg_matrix_io_small_buffer_operator_times, // 读写次数
// 监测重复读同一文件的问题
clicfg_matrix_io_repeated_read_enable,
clicfg_matrix_io_repeated_read_threshold, // 重复读次数
// 监测内存泄漏问题
clicfg_matrix_io_closeable_leak_enable,
出现资源泄漏(比如未关闭读写流)时,报告信息示例如下:
"tag": "io",
"type": 4,
"process": "sample.tencent.matrix",
"time": 1590410170122,
"stack":
"sample.tencent.matrix.io.TestIOActivity.leakSth(TestIOActivity.java:190)\\nsampl e.tencent.matrix.io.TestIOActivity.onClick(TestIOActivity.java:103)\\njava.lang.r eflect.Method.invoke(Native
Method)\\nandroid.view.View$DeclaredOnClickListener.onClick(View.java:4461)\\nandroid.view.View.performClick(View.java:5212)\\nandroid.view.View$PerformClick.run(View.java:21214)\\nandroid.app.ActivityThread.main(ActivityThread.java:5619)\\njava .lang.reflect.Method.invoke(Native
Method)\\ncom.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:853)\\ncom.android.internal.os.ZygoteInit.main(ZygoteInit.java:737)\\n",
写入太多、缓冲区太小的报告示例如下:
"tag": "io",
"type": 2, // 问题类型
"process": "sample.tencent.matrix",
"time": 1590409786187,
"path": "/sdcard/a_long.txt", // 文件路径
"size": 40960000, // 文件大小
"op": 80000, // 读写次数
"buffer": 512, // 缓冲区大小
"cost": 1453, // 耗时
"opType": 2, // 1 读 2 写
"opSize": 40960000, // 读写总内存
"thread": "main",
"stack":
"sample.tencent.matrix.io.TestIOActivity.writeLongSth(TestIOActivity.java:129)\\nsample.tencent.matrix.io.TestIOActivity.onClick(TestIOActivity.java:99)\\njava.la ng.reflect.Method.invoke(Native
Method)\\nandroid.view.View$DeclaredOnClickListener.onClick(View.java:4461)\\nandroid.view.View.performClick(View.java:5212)\\nandroid.view.View$PerformClick.run(View.java:21214)\\nandroid.app.ActivityThread.main(ActivityThread.java:5619)\\njava .lang.reflect.Method.invoke(Native
Method)\\ncom.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:853)\\ncom.android.internal.os.ZygoteInit.main(ZygoteInit.java:737)\\n", "repeat": 0 // 重复读次数
需要注意的是,字段 repeat 在主线程 IO 事件中有不同的含义:“1” 表示单次读写耗时过长;“2” 表示连续读写耗时过长(大于配置指定值);“3” 表示前面两个问题都存在。
9.2.原理介绍
IOCanary 将收集应用的所有文件 I/O 信息并进行相关统计,再依据一定的算法规则进行检测,发现问题后再上报到 Matrix 后台进行分析展示。流程图如下
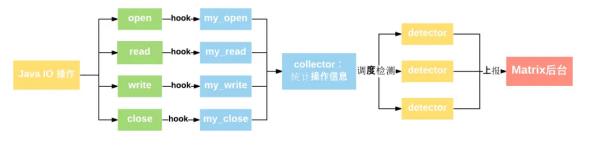
IOCanary 基于 xHook 收集 IO 信息,主要 hook 了 os posix 的四个关键的文件操作接口:
int open(const char *pathname, int flags, mode_t mode); // 成功时返回值就是 fd
ssize_t read(int fd, void *buf, size_t size);
ssize_t write(int fd, const void *buf, size_t size);
int close(int fd);
以 open 为例,追根溯源,可以发现 open 函数最终是 libjavacore.so 执行的,因此 hooklibjavacore.so 即可,找到 hook 目标 so 的目的是把 hook 的影响范围尽可能地降到最小。不同的Android 版本可能会有些不同,目前兼容到 Android P。
另外,不同于其它 IO 事件,对于资源泄漏监控,Android 本身就支持了该功能,这是基于工具类dalvik.system.CloseGuard 来实现的,因此在 Java 层通过反射 hook 相关 API 即可实现资源泄漏监控。
9.3.Hook介绍
想要了解 hook 技术,首先需要了解动态链接,了解动态链接之前,又需要从静态链接说起。
静态链接可以让开发者们相对独立地开发自己的程序模块,最后再链接到一起,但静态链接也存在浪费内存和磁盘更新、更新困难等问题。比如 program1 和 program2 都依赖 Lib.o 模块,那么,最终链接到可执行文件中的 Lib.o 模块将会有两份,极大地浪费了内存空间。同时,一旦程序中有任何模块更新,整个程序就要重新链接、发布给用户。
因此,要解决空间浪费和更新困难这两个问题,最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不再将它们静态地链接在一起。也就是说,要在程序运行时进行链接,这就是动态链接的基本思想。
虽然动态链接带来了很多优化,但也带来了一个新的问题:共享对象在装载时,如何确定它在进程虚拟地址空间中的位置?
解决思路是把指令中那些需要修改的部分分离出来,和数据部分放在一起。对于模块内部的数据访问、函数调用,因为它们之间的相对位置是固定的,因此这些指令不需要重定位。
对于模块外部的数据访问、函数调用,基本思想就是把地址相关的部分放到数据段里面,建立一个指向这些变量的指针数组,这个数据也被称为全局偏移表(Global Offset Table,GOT)。链接器在装载模块的时候会查找每个变量所在的地址,然后填充 GOT 中的各个项,以确保每个指针指向的地址正确。
但 GOT 也带来了新的问题——性能损失,动态链接比静态链接慢的主要原因就是动态链接对于全局和静态的数据访问都要进行复杂的 GOT 定位,然后间接寻址。对于这个问题,在一个程序运行过程中,可能很多函数直到程序执行完毕都不会被用到,比如一些错误处理函数等,如果一开始就把所有函数都链接好实际上是一种浪费,所以 ELF 采用了延迟绑定的方法,
基本思想是当函数第一次被用到时才由动态链接器来进行绑定(符号查找、重定位等)。延迟绑定对应的就是 PLT(Procedure Linkage Table) 段。也就是说,ELF 在 GOT 之上又增加了一层间接跳转。
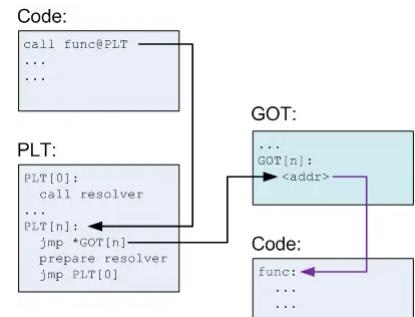
因此,所谓 hook 技术,实际上就是修改 PLT/GOT 表中的内容。
9.4.源码解析
IOCanary 的源码结构是很清晰的,流程大致如下:
hook目标so文件的open、read、write、close函数- 在执行文件
IO时记录IO耗时、操作次数、缓冲区大小等信息,使用结构体IOInfo保存 - 在
IO执行完毕,调用close方法时,将IOInfo插入到一个队列 - 后台线程循环从队列获取
IOInfo,并交给Detector检查 - 如果
Detector认为有问题,则上报
9.4.1.hook
IOCanary 的 hook 目标 so 文件包括 libopenjdkjvm.so、libjavacore.so、libopenjdk.so,每个 so 文
件的 open 和 close 函数都会被 hook,如果是 libjavacore.so,read 和 write 函数也会被 hook。源码如下所示,
const static char* TARGET_MODULES[] =
"libopenjdkjvm.so",
"libjavacore.so",
"libopenjdk.so"
;
const static size_t TARGET_MODULE_COUNT = sizeof(TARGET_MODULES) / sizeof(char*);
JNIEXPORT jboolean JNICALL
Java_com_tencent_matrix_iocanary_core_IOCanaryJniBridge_doHook(JNIEnv *env, jclass type)
for (int i = 0; i < TARGET_MODULE_COUNT; ++i)
const char* so_name = TARGET_MODULES[i];
void* soinfo = xhook_elf_open(so_name);
// 将目标函数替换为自己的实现
xhook_hook_symbol(soinfo, "open", (void*)ProxyOpen, (void**)&original_open);
xhook_hook_symbol(soinfo, "open64", (void*)ProxyOpen64, (void**)&original_open64);
bool is_libjavacore = (strstr(so_name, "libjavacore.so") != nullptr);
if (is_libjavacore)
xhook_hook_symbol(soinfo, "read", (void*)ProxyRead, (void**)&original_read);
xhook_hook_symbol(soinfo, "__read_chk", (void*)ProxyReadChk, (void**)&original_read_chk);
xhook_hook_symbol(soinfo, "write", (void*)ProxyWrite, (void**)&original_write);
xhook_hook_symbol(soinfo, "__write_chk", (void*)ProxyWriteChk, (void**)&original_write_chk);
xhook_hook_symbol(soinfo, "close", (void*)ProxyClose, (void**)&original_close);
xhook_elf_close(soinfo);
9.4.2.统计IO操作
为了分析是否出现主线程 IO、缓冲区过小、重复读同一文件等问题,首先需要对每一次的 IO 操作进行统计,记录 IO 耗时、操作次数、缓冲区大小等信息。
这些信息最终都会由 Collector 保存,为此,在执行 open 操作时,需要创建一个 IOInfo,并保存到map 里面,key 为文件句柄:
int ProxyOpen(const char *pathname, int flags, mode_t mode)
int ret = original_open(pathname, flags, mode);
if (ret != -1)
DoProxyOpenLogic(pathname, flags, mode, ret);
return ret;
static void DoProxyOpenLogic(const char *pathname, int flags, mode_t mode, int ret)
... // 通过 Java 层的 IOCanaryJniBridge 获取 JavaContext
iocanary::IOCanary::Get().OnOpen(pathname, flags, mode, ret, java_context);
void IOCanary::OnOpen(...)
collector_.OnOpen(pathname, flags, mode, open_ret, java_context);
void IOInfoCollector::OnOpen(...)
std::shared_ptr<IOInfo> info = std::make_shared<IOInfo>(pathname, java_context);
info_map_.insert(std::make_pair(open_ret, info));
接着,在执行 read/write 操作时,更新 IOInfo 的信息:
void IOInfoCollector::OnWrite(...)
CountRWInfo(fd, FileOpType::kWrite, size, write_cost);
void IOInfoCollector::CountRWInfo(int fd, const FileOpType &fileOpType, long op_size, long rw_cost)
info_map_[fd]->op_cnt_ ++;
info_map_[fd]->op_size_ += op_size;
info_map_[fd]->rw_cost_us_ += rw_cost;
...
最后,在执行 close 操作时,将 IOInfo 插入到队列中:
void IOCanary::OnClose(int fd, int close_ret)
std::shared_ptr<IOInfo> info = collector_.OnClose(fd, close_ret);
OfferFileIOInfo(info);
void IOCanary::OfferFileIOInfo(std::shared_ptr<IOInfo> file_io_info)
std::unique_lock<std::mutex> lock(queue_mutex_);
queue_.push_back(file_io_info); // 将数据保存到队列中
queue_cv_.notify_one(); // 唤醒后台线程,队列有新的数据了
lock.unlock();
9.4.3.检测IO事件
后台线程被唤醒后,首先会从队列中获取一个IOInfo:
int IOCanary::TakeFileIOInfo(std::shared_ptr<IOInfo> &file_io_info)
std::unique_lock<std::mutex> lock(queue_mutex_);
while (queue_.empty())
queue_cv_.wait(lock);
file_io_info = queue_.front();
queue_.pop_front();
return 0;
接着,将 IOInfo 传给所有已注册的 Detector,Detector 返回 Issue 后再回调上层 Java 接口,上报问题:
void IOCanary::Detect()
std::vector<Issue> published_issues;
std::shared_ptr<IOInfo> file_io_info;
while (true)
published_issues.clear();
int ret = TakeFileIOInfo(file_io_info);
for (auto detector : detectors_)
detector->Detect(env_, *file_io_info, published_issues); // 检查该 IO 事件是否存在问题
if (issued_callback_ && !published_issues.empty()) // 如果存在问题
issued_callback_(published_issues); // 回调上层 Java 接口并上报
以 small_buffer_detector 为例,如果 IOInfo 的 buffer_size_ 字段大于选项给定的值就上报问题:
void FileIOSmallBufferDetector::Detect(...)
if (file_io_info.op_cnt_ > env.kSmallBufferOpTimesThreshold // 连续读写次数
&& (file_io_info.op_size_ / file_io_info.op_cnt_) < env.GetSmallBufferThreshold() // buffer size
&& file_io_info.max_continual_rw_cost_time_μs_ >= env.kPossibleNegativeThreshold) /* 连续读写耗时 */
PublishIssue(Issue(kType, file_io_info), issues);
9.4.4.资源泄漏监控
Android framework 已实现了资源泄漏监控的功能,它是基于工具类 dalvik.system.CloseGuard 来实现的。以 FileInputStream 为例,在 GC 准备回收 FileInputStream 时,会调用 guard.warnIfOpen 来检测是否关闭了 IO 流:
public class FileInputStream extends InputStream
private final CloseGuard guard = CloseGuard.get();
public FileInputStream(File file)
...
guard.open("close");
public void close()
guard.close();
protected void finalize() throws IOException
if (guard != null)
guard.warnIfOpen();
CloseGuard 的部分源码如下:
final class CloseGuard
public void warnIfOpen()
REPORTER.report(message, allocationSite);
可以看到,执行 warnIfOpen 时如果未关闭 IO 流,就调用 REPORTER 的 report 方法。因此,利用反射把 REPORTER 换成自己的就行了:
public final class CloseGuardHooker
private boolean tryHook()
Class<?> closeGuardCls = Class.forName("dalvik.system.CloseGuard");
Class<?> closeGuardReporterCls = Class.forName("dalvik.system.CloseGuard$Reporter"); Method
methodGetReporter = closeGuardCls.getDeclaredMethod("getReporter"); Method
methodSetReporter = closeGuardCls.getDeclaredMethod("setReporter", closeGuardReporterCls);
Method methodSetEnabled = closeGuardCls.getDeclaredMethod("setEnabled", boolean.class);
sOriginalReporter = methodGetReporter.invoke(null);
methodSetEnabled.invoke(null, true);
ClassLoader classLoader = closeGuardReporterCls.getClassLoader();
methodSetReporter.invoke(null, Proxy.newProxyInstance(classLoader,
new Class<?>[]closeGuardReporterCls,
new IOCloseLeakDetector(issueListener, sOriginalReporter)));
framework 很多代码都用了 CloseGuard ,因此,诸如文件资源没 close、Cursor 没有 close 等问题都能通过它来检测。
9.5.总结
IOCanary 是一个在开发、测试或者灰度阶段辅助发现 I/O 问题的工具,目前主要包括文件 I/O 监控和Closeable Leak 监控两部分。具体的问题类型有 4 种:
- 在主线程执行了 IO 操作
- 缓冲区太小
- 重复读同一文件
- 资源泄漏
基于 xHook,IOCanary 将收集应用的所有文件 I/O 信息并进行相关统计,再依据一定的算法规则进行检测,发现问题后再上报到 Matrix 后台进行分析展示。
流程如下:
hook目标so文件的open、read、write、close函数- 在执行文件 IO 时记录 IO 耗时、操作次数、缓冲区大小等信息,使用结构体
IOInfo保存 - 在 IO 执行完毕,调用
close方法时,将IOInfo插入到一个队列 - 后台线程循环从队列获取
IOInfo,并交给Detector检查 - 如果
Detector认为有问题,则上报不同于其它 IO 事件,对于资源泄漏监控,Android 本身就支持了该功能,这是基于工具类dalvik.system.CloseGuard来实现的,因此在 Java 层通过反射hook CloseGuard即可实现资源泄漏监控。因为 Android 框架层很多代码都用了CloseGuard,因此,诸如文件资源没close、Cursor没有close等问题都能通过它来检测。
到此,关于Android性能监控框架
Matrix正式算讲完了,附加文档文件查看。

以上是关于Android 视频播放延时抖动那些事的主要内容,如果未能解决你的问题,请参考以下文章
iOS不能播放Mp4视频和tableView刷新抖动问题全解
Android Studio 用NodeMedia播放RTSP视频