什么是mlm模型?
Posted irrationality
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是mlm模型?相关的知识,希望对你有一定的参考价值。
对于文本分类模型中取名为 “mlm” 的原因,我不确定。但从机器学习和自然语言处理领域的角度来看,“MLM” 通常指的是 “Masked Language Model”,即遮蔽语言模型。在这种模型中,输入文本的一部分会被随机遮蔽掉,模型需要通过上下文来预测被遮蔽的词或字符。在 BERT 模型中就包含了 MLM 部分。
因此,在您提供的文本分类模型中也可能包含有遮蔽语言模型的部分,且该模型以此命名。但具体原因需要进一步澄清。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 的双向编码器模型,它能够生成高质量的上下文相关字向量,被广泛应用于各种自然语言处理任务中。在 BERT 模型中,包含了 Masked Language Model(MLM)部分,用于预训练模型。
在 MLM 中,输入文本的一部分会被随机遮蔽掉,模型需要通过上下文来预测被遮蔽的词或字符。在 BERT 模型中,被遮蔽的部分由两种符号组成:80% 的部分会被替换成特殊标记 [MASK],10% 的部分会被替换成其他随机的单词,而剩下的 10% 部分则不做任何处理。
具体来说,在 BERT 模型的预训练过程中,模型输入是包含两个句子的序列,其中句子之间以 [SEP] 符号分隔。模型的输出将分别预测每个位置的单词或字符是否为特殊标记 [MASK] 的代表的单词,同时也会预测该位置的单词或字符是否与其它随机选取的单词或字符匹配。
这种预训练方式可以使得 BERT 模型学习到更加丰富、上下文相关的语言表示,从而提升在各种下游自然语言处理任务中的性能表现。因此,在 BERT 模型的架构中包含了 MLM 部分。
正在为您搜索:利用prompt进行文本分类
这两段知识来源是在介绍利用 Prompt 进行文本分类的方法和相关实现。根据第一段知识来源[1],Prompt 是一种新兴的预训练语言模型方法,可以帮助解决文本分类中一些常见问题,如标签不完整或不规范、样本数量不足、OoD(Out of Distribution)问题等。而该方法的基本思想是通过在文本序列中插入特定的 Prompt 向量,来指导模型学习与任务相关的表示。
在第二段知识来源[2] 中,也提到了利用 Prompt Learning 进行文本分类任务的方法,即将文本分类任务转化为 MLM(Masked Language Modeling)任务。该方法会在文本中随机加入 [MASK] 符号来提示模型,使其能够更好地理解上下文,并通过预测 [MASK] 位置的输出来判断文章的类别。因此,该方法也是一种基于 Prompt 的文本分类方法,与第一段中提到的方法类似。
因此,以上两段知识来源介绍的都是利用 Prompt 这种预训练语言模型的思想来进行文本分类的方法,具有相似的实现方式和目的。
TransCoder代码详解:MLM的训练过程
前言
在上一篇blog里,ATP分析了TransCoder模型最顶层的main函数,理清了它的训练过程是怎么循环的。
这次ATP本来想要看一下它的模型具体是什么样子的。但ATP发现,pretrain过程(只有encoder)和后续的过程(同时有encoder和decoder)它模型的结构与训练过程还是差别很大的。
为了避免ATP的blog写得太乱七八糟,ATP决定这次先有针对性地去看一下MLM的训练过程,也就是只有encoder的时候它是怎么操作的。
建立模型build_model
只考虑MLM的过程的话,build_model这块内容非常简单,就是建立了一个Transformer的encoder。基本结构整理出来就像下面这样:
def build_model(params, dico):
"""
Build model.
"""
if params.encoder_only:
# build
model = TransformerModel(
params, dico, is_encoder=True, with_output=True)
# reload pretrained word embeddings
if params.reload_emb != ‘‘:
......
# reload a pretrained model
if params.reload_model != ‘‘:
......
......
return [model.cuda()]
在用MLM进行pretrain的时候,参数里面的“reload_emb”和“reload_model”都是空串,意思是既不需要载入已有的embedding,也不需要载入已有的model(因为MLM过程是训练的第一个过程,不需要从别的地方载入什么东西)。
而通过对比可以发现,在进行DAE/BT的训练时,reload_model这个参数有值,指向的是用MLM训练好的model。这也进一步印证了该模型的训练过程是先MLM,再DAE/BT。
Transformer内部的细节ATP没有仔细看。ATP倾向于认为它就是一个普通的transformer。
训练过程:trainer和mlm_step
在main函数中,模型建立完成后,又定义了一个trainer。这个类的定义位于XLM/src/trainer.py中,作用是执行训练的步骤。
例如在主循环中,mlm_step这个函数就是trainer类的一个成员函数,作用是执行一次MLM的训练。
# generate batch / select words to predict
x, lengths, positions, langs, _ = self.generate_batch(lang1, lang2, ‘pred‘)
x, lengths, positions, langs, _ = self.round_batch(x, lengths, positions, langs)
x, y, pred_mask = self.mask_out(x, lengths)
mlm_step函数首先通过generate_batch这个函数生成一批数据。虽然这个函数返回很多个值,但在MLM过程中我们只需要关注x(返回的数据)和lengths(数据的长度)。
round_batch是与fp16有关的。mask_out是给数据打mask的,返回的x,y,pred_mask三个参数分别是打过mask的数据、原始数据,以及一个布尔数组表示哪里打了mask。
接下来,将得到的数据推送到显存上后,就可以开始训练了。mlm_step的核心语句是这几句:
# forward / loss
tensor = model(‘fwd‘, x=x, lengths=lengths, positions=positions, langs=langs, causal=False)
_, loss = model(‘predict‘, tensor=tensor, pred_mask=pred_mask, y=y, get_scores=False)
self.stats[(‘MLM-%s‘ % lang1) if lang2 is None else (‘MLM-%s-%s‘ % (lang1, lang2))].append(loss.item())
loss = lambda_coeff * loss
这段语句的前两行是在调用transformer类的成员函数。它们的作用光看字面意思就能猜个大概,就是把数据送入transformer,过了encoder以后再预测mask的内容,然后与真实的数据(y)算出loss进行优化。
其中,fwd函数返回的是输入数据过了encoder与一个额外的全连接层(FFN)后的输出,而predict函数利用这个输出来进行预测并计算loss。
原理和这个图是一样的:
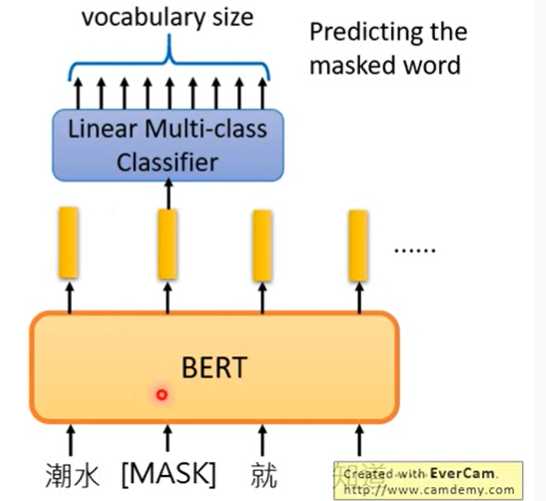
这个图是从李宏毅的讲BERT的课程视频里截出来的。关于这个训练过程他的解释是,因为线性分类器是相对比较弱的一种分类器,所以分类的效果更多地取决于encoder所作出的embedding是不是准确。所以这个MLM的训练过程能有效地训练模型的embedding能力。
另外,TransCoder的原论文中提到,模型能work的关键是它找到了不同语言之间的anchor point,也就是具有相同表示的token。ATP其实对这个地方的理解一直比较模糊。它现在认为这个anchor point应该指的是在embedding之后位置相近(或相同)的token,也就是说不同语言中上下文语境相似的token。
以上是关于什么是mlm模型?的主要内容,如果未能解决你的问题,请参考以下文章