Java程序访问不了HDFS下的文件,报缺失块的异常,请高手解决一下
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java程序访问不了HDFS下的文件,报缺失块的异常,请高手解决一下相关的知识,希望对你有一定的参考价值。
Exception in thread "main" org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1871874645-127.0.0.1-1532849044065:blk_1073741825_1001 file=/user/hadoop/file1.txt
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:976)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:632)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:874)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:926)
at java.io.DataInputStream.read(DataInputStream.java:149)
at com.fengrd.hadoop.merge.Merge.doMerge(Merge.java:42)
at com.fengrd.hadoop.merge.Merge.main(Merge.java:54)
在Hadoop 1.x以后的版本中引入了一个新的文件系统接口叫FileContext,一个FileContext实例可以处理多种文件系统,而且接口更加清晰和统一。
ha环境下重新格式化hdfs报错
datanode启动不成功,如下所示,我的136,137.138都是datanode,都启动不了。
查看datanode日志文件发现报错:
一个报错Incompatible clusterIDs in /home/hadoop/data/datanode,需要删除core-site.xml中配置的hadoop.tmp.dir临时目录下的东西。
第二个报错需要删除hdfs-site.xml中配置dfs.datanode.data.dir对应的目录下的东西。
然后重新格式化hdfs后,重启hdfs就可以了。
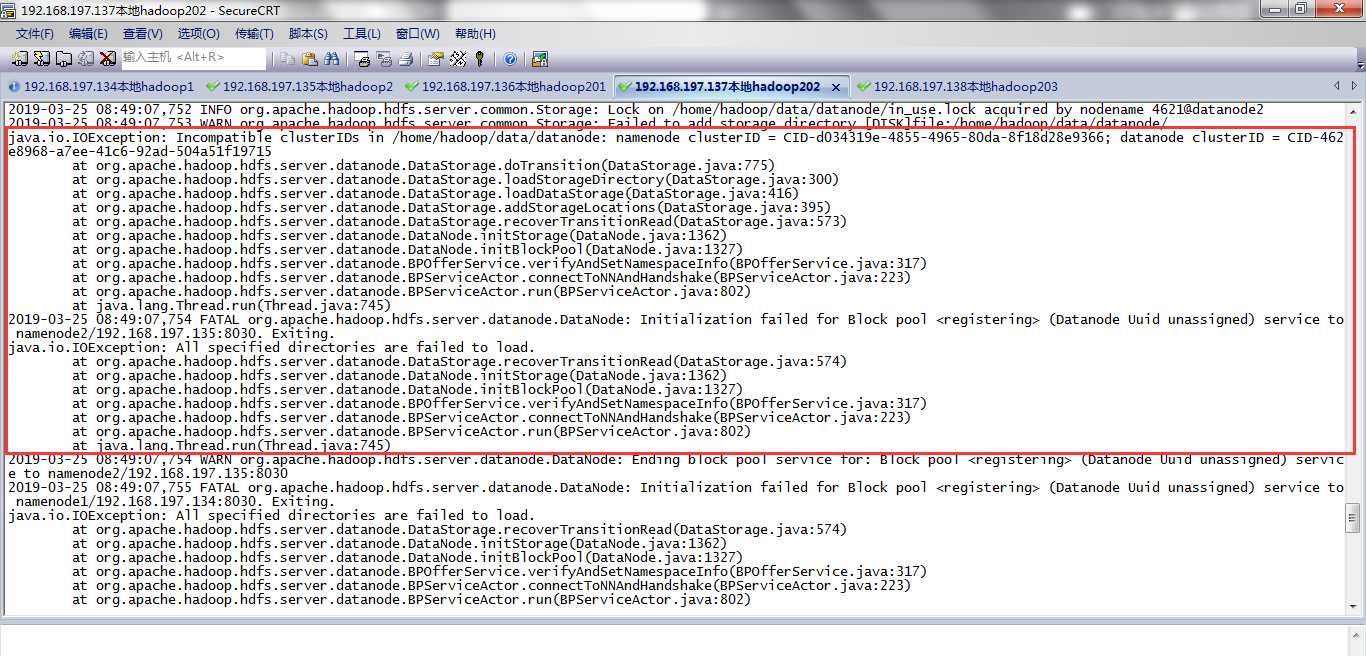
2019-03-25 08:49:07,753 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/hadoop/data/datanode/
java.io.IOException: Incompatible clusterIDs in /home/hadoop/data/datanode: namenode clusterID = CID-d034319e-4855-4965-80da-8f18d28e9366; datanode clusterID = CID-462e8968-a7ee-41c6-92ad-504a51f19715
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:775)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
2019-03-25 08:49:07,754 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to namenode2/192.168.197.135:8030. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:574)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
以上是关于Java程序访问不了HDFS下的文件,报缺失块的异常,请高手解决一下的主要内容,如果未能解决你的问题,请参考以下文章