Hive(10):Hive分桶表
Posted 不死鸟.亚历山大.狼崽子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive(10):Hive分桶表相关的知识,希望对你有一定的参考价值。
1 分桶表的概念
分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于优化查询而设计的表类型。该功能可以让数据分解为若干个部分易于管理。
在分桶时,我们要指定根据哪个字段将数据分为几桶(几个部分)。
2 规则
默认规则是:
Bucket number = hash_function(bucketing_column) mod num_buckets
分桶编号 = 哈希方法(分桶字段) 取模 分桶个数
可以发现桶编号相同的数据会被分到同一个桶当中。hash_function取决于分桶字段bucketing_column的类型:
- 如果是int类型,hash_function(int) == int;
- 如果是其他类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。

3 语法

--分桶表建表语句
CREATE [EXTERNAL] TABLE [db_name.]table_name
[(col_name data_type, ...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;- CLUSTERED BY (col_name)表示根据哪个字段进行分;
- INTO N BUCKETS表示分为几桶(也就是几个部分)。
- 需要注意的是,分桶的字段必须是表中已经存在的字段。
3 分桶表的创建
现有美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
2021-01-28,Juneau City and Borough,Alaska,02110,1108,3
2021-01-28,Kenai Peninsula Borough,Alaska,02122,3866,18
2021-01-28,Ketchikan Gateway Borough,Alaska,02130,272,1
2021-01-28,Kodiak Island Borough,Alaska,02150,1021,5
2021-01-28,Kusilvak Census Area,Alaska,02158,1099,3
2021-01-28,Lake and Peninsula Borough,Alaska,02164,5,0
2021-01-28,Matanuska-Susitna Borough,Alaska,02170,7406,27
2021-01-28,Nome Census Area,Alaska,02180,307,0
2021-01-28,North Slope Borough,Alaska,02185,973,3
2021-01-28,Northwest Arctic Borough,Alaska,02188,567,1
2021-01-28,Petersburg Borough,Alaska,02195,43,0字段含义如下:count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)。
根据state州把数据分为5桶,建表语句如下
CREATE TABLE itcast.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
CLUSTERED BY(state) INTO 5 BUCKETS;在创建分桶表时,还可以指定分桶内的数据排序规则
--根据state州分为5桶 每个桶内根据cases确诊病例数倒序排序
CREATE TABLE itcast.t_usa_covid19_bucket_sort(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;4 分桶表的数据加载
--step1:开启分桶的功能 从Hive2.0开始不再需要设置
set hive.enforce.bucketing=true;
--step2:把源数据加载到普通hive表中
CREATE TABLE itcast.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
--将源数据上传到HDFS,t_usa_covid19表对应的路径下
hadoop fs -put us-covid19-counties.dat /user/hive/warehouse/itcast.db/t_usa_covid19
--step3:使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket select * from t_usa_covid19;到HDFS上查看t_usa_covid19_bucket底层数据结构可以发现,数据被分为了5个部分。
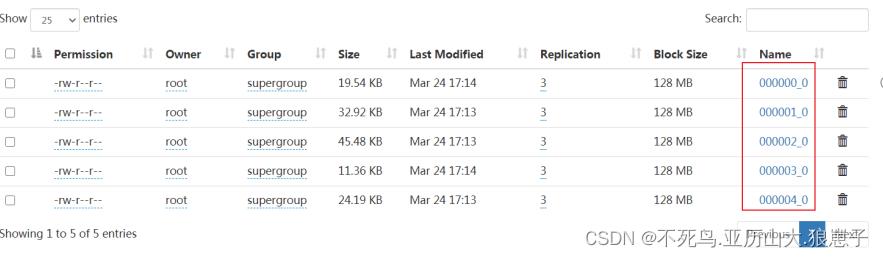
并且从结果可以发现,只要hash_function(bucketing_column)一样的,就一定被分到同一个桶中。
5 分桶表的使用好处
和非分桶表相比,分桶表的使用好处有以下几点:
5.1 基于分桶字段查询时,减少全表扫描
--基于分桶字段state查询来自于New York州的数据
--不再需要进行全表扫描过滤
--根据分桶的规则hash_function(New York) mod 5计算出分桶编号
--查询指定分桶里面的数据 就可以找出结果 此时是分桶扫描而不是全表扫描
select * from t_usa_covid19_bucket where state="New York";5.2 JOIN时可以提高MR程序效率,减少笛卡尔积数量
对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
5.3 分桶表数据进行抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
Hive 教程-分区表与分桶表
在 hive 中分区表是很常用的,分桶表可能没那么常用,本文主讲分区表。
概念
分区表
在 hive 中,表是可以分区的,hive 表的每个区其实是对应 hdfs 上的一个文件夹;
可以通过多层文件夹的方式创建多层分区;
通过文件夹把数据分开
分桶表
分桶表中的每个桶对应 hdfs 上的一个文件;
通过文件把数据分开
在查询时可以通过 where 指定分区(分桶),提高查询效率
分区表基本操作
1. 创建分区表
partitoned by 指定分区,后面加 分区字段 和 分区字段类型,可以加多个字段,前面是父路径,后面是子路径
create table student_p(id int,name string,sexex string,age int,dept string) partitioned by(part string) row format delimited fields terminated by ‘,‘ stored as textfile;
分区表相当于给 表 加了一个字段,然后给这个字段赋予不同的 value,每个 value 对应一个分区,这个 value 对应 hdfs 上文件夹的名字
2. 写入数据
1, zhangsan, f, 30, a,
2, lisi, f, 39, b,
3, wangwu, m, 26, c,
写入两次,每次设置不同的分区
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student_p partition(part=321);
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student_p partition(part=456);
3. 写入数据后看看长啥样
hive> select * from student_p;
OK
1 zhangsan f 20 henan 321
2 lisi f 30 shanghai 321
3 wangwu m 40 beijing 321
1 zhangsan f 20 henan 456
2 lisi f 30 shanghai 456
3 wangwu m 40 beijing 456
Time taken: 0.287 seconds, Fetched: 6 row(s)
4. hdfs 上看看长啥样
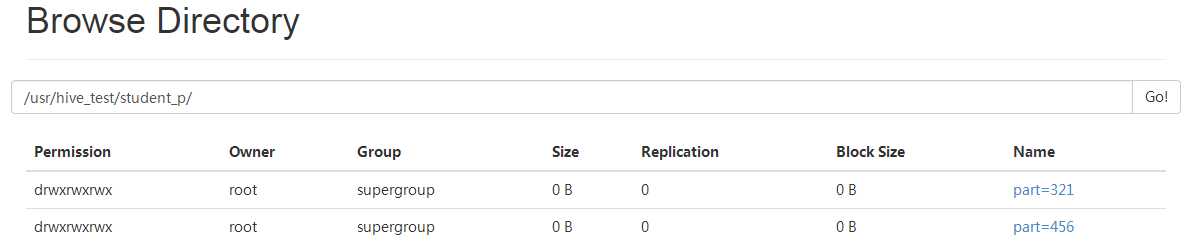
5. 查看某个分区
hive> select * from student_p where part=321;
6. 数据库里看看元数据信息
分区信息保存在 PARTITIONS 表中
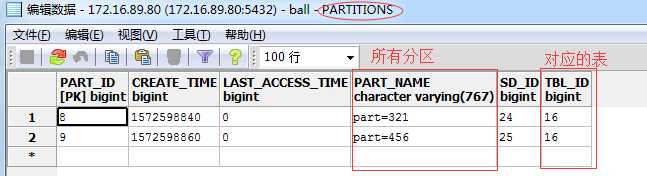
还有其他与 PARTITIONS 相关的表,自己可以看看
小结:每个分区对应一个文件夹,而且这个文件夹必须存储到元数据中;
也就是说,如果这个文件不在元数据中,那么即使他存在,也不是分区表中的一个分区,通过表查询不到
增加分区
加载数据时会自动增加分区,也可以不加载数据,单独创建分区
增加一个分区
hive> alter table student_p add partition(part=999);
增加多个分区
hive> alter table student_p add partition(part=555) partition(part=666);

删除分区
删除一个分区
hive> alter table student_p drop partition(part=555); Dropped the partition part=555 OK Time taken: 0.675 seconds
删除多个分区
hive> alter table student_p drop partition(part=666), partition(part=999); Dropped the partition part=666 Dropped the partition part=999 OK Time taken: 0.464 seconds
查看分区数
hive> show partitions student_p; OK part=321 part=456 Time taken: 0.28 seconds, Fetched: 2 row(s)
查看分区表结构
hive> desc formatted student_p; OK # col_name data_type comment id int name string sexex string age int dept string # Partition Information # col_name data_type comment part string # Detailed Table Information Database: hive1101 Owner: root CreateTime: Fri Nov 01 02:00:25 PDT 2019 LastAccessTime: UNKNOWN Retention: 0 Location: hdfs://hadoop10:9000/usr/hive_test/student_p Table Type: MANAGED_TABLE
表与数据关联
之前我们讲到如果一个文件夹在表目录下,但是不在元数据中,那么通过表是查不到这个数据的。
那如何把这种数据通过表读出来?必须把他们关联起来,有三种方式
上传数据后修复
1. 直接上传数据到 hdfs
hive> dfs -mkdir -p /usr/hive_test/student_p/part=888; hive> dfs -put /usr/lib/hive2.3.6/2.csv /usr/hive_test/student_p/part=888;
在 hdfs 上直接建了一个目录,并且这个目录在 表目录下,然后给这个目录上传一个文件
2. 查询该分区数据,无果
3. 修复表
hive> msck repair table student_p; OK Partitions not in metastore: student_p:part=888 Repair: Added partition to metastore student_p:part=888 Time taken: 0.502 seconds, Fetched: 2 row(s)
就是把分区添加到元数据
4. 查询可查到数据
上传数据后添加分区
首先执行上面的 1 2 步;
然后给表添加分区,把新建的文件夹添加给表做分区
hive> alter table student_p add partition(part=888);
创建文件夹后 load 数据到分区
我们知道 load 是会自动创建分区的,所以这样肯定可以
创建二级分区
二级分区,也就是多层分区,也就是多层路径
创建多级分区表
create table student1102(id int,name string,sexex string,age int,dept string) partitioned by(month string, day int) row format delimited fields terminated by ‘,‘ stored as textfile;
month 一级,day 是month 下一级
load 数据
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student1102 partition(month=‘11‘, day=2);
在 hdfs 一看就知道怎么回事了

查询数据
hive> select * from student1102 where month=11 and day=2;
加个 and 就可以了
加载数据
load data inpath ‘/user/tuoming/test/test‘ into table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘); 追加 load data inpath ‘/user/tuoming/test/test‘ overwrite into table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘); 覆盖 insert overwrite table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘) select * from part_test_temp; 覆盖 insert into part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘) select * from part_test_temp; 追加
动态分区
参考下面的参考资料
参考资料:
https://blog.csdn.net/afafawfaf/article/details/80249974
以上是关于Hive(10):Hive分桶表的主要内容,如果未能解决你的问题,请参考以下文章