

一. 箭头函数
箭头函数是ES6语法中加入的新特性,而它也是许多开发者对ES6仅有的了解,每当面试里被问到关于“ES6里添加了哪些新特性?”这种问题的时候,几乎总是会拿箭头函数来应付。箭头函数,=>,没有自己的this , arguments , super , new.target ,“书写简便,没有this”在很长一段时间内涵盖了大多数开发者对于箭头函数的全部认知(当然也包括我自己),如果只是为了简化书写,把=>按照function关键字来解析就好了,何必要弄出一个跟普通函数特性不一样的符号呢?答案就是:函数式编程(Functional Programming)。
如果你了解javascript这门语言就知道,它是没有类这个东西的,ES6新加入的Class关键字,也不过是语法糖而已,我们不断被要求使用面向对象编程的思想来使用javascript,定义很多类,用复杂的原型链机制去模拟类,是因为更多的开发者能够习惯这种描述客观世界的方式,《你不知道的javascript》中就明确指出原型链的机制其实只是实现了一种功能委托机制,即便不使用面向对象中的概念去描述它,这也是一种合乎逻辑的语言设计方案,并不会造成巨大的认知障碍。但需要明确的是,面向对象并不是javascript唯一的使用方式。
当然我也是接触到【函数式编程】的思想后才意识到,我并不是说【函数式编程】优于【面向对象】,每一种编程思想都有其适用的范围,但它的确向我展示了另一种对编程的认知方式,而且在流程控制的清晰度上,它的确比面向对象更棒,它甚至让我开始觉得,这才是javascript该有的打开方式。
如果你也曾以为【函数式编程】就是“用箭头函数把函数写的精简一些”,如果你也被各种复杂的this绑定弄的晕头转向,那么就一起来看看这个胖箭头指向的新世界——Functional Programming吧!
二. 更贴近本能的思维方式
假如有这样一个题目:
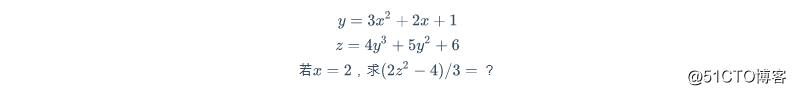
在传统编程中,你的编码过程大约是这样:
let resolveYX = (x) => 3*x*x + 2*x + 1;
let resolveZY = (y) => 4*y*y*y + 5*y*y + 6;
let resolveRZ = (z) => (2*z*z - 4)/3;
let y = resolveYX(2);
let z = resolveZY(y);
let result = resolveRZ(z);
我们大多时候采用的方式是把程序的执行细节用程序语言描述出来。但是如果你把这道题拿给一个不懂编程的学生来做,就会发现大多数时候他们的做法会是下面的样子:
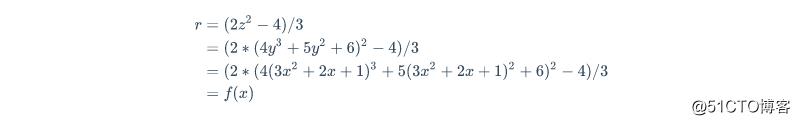
先对方程进行合并和简化,最后再代入数值进行计算得到结果就可以了。有没有发现事实上你自己在不写代码的时候也是这样做的,因为你很清楚那些中间变量对于得到正确的结果来说没有什么意义,而这样解题效率更高,尤其是当前面的环节和后面的环节可以抵消掉某些互逆的运算时,这样合并的好处可想而知。
而今天的主角【函数式编程】,可以看做是这种思维方式在程序设计中的应用,我并不建议非数学专业的作者从范畴论的角度去解释函数式编程,因为术语运用的准确性会造成难以评估的影响,很可能达不到技术交流的目的,反而最终误人子弟。
三. 函数式编程
假如对某个需求的实现,需要传入x,然后经历3个步骤后得到一个答案y,你会怎样来实现呢?
3.1 传统代码的实现
这样一个需求在传统编程中最容易想到的就是链式调用:
function Task(value){
this.value = value;
}
Task.prototype.step = function(fn){
let _newValue = fn(this.value);
return new Task(_newValue);
}
y = (new Task(x)).step(fn1).step(fn2).step(fn3);
你或许在jQuery中经常见到这样的用法,或者你已经意识到上面的函数实际上就是Promise的简化原型(关于Promise相关的知识可以看《javascript基础修炼(7)——Promise,异步,可靠性》这篇文章),只不过我们把每一步骤包裹在了Task这个容器里,每个动作执行完以后返回一个新的Task容器,里面装着上一个步骤返回的结果。
3.2 函数式代码推演
在【函数式编程】,我们不再采用程序语言按照步骤来复现一个业务逻辑,而是换一个更为抽象的角度,用数学的眼光看待所发生的事情。那么上面的代码实际上所做的事情就是:
通过一系列变换操作,讲一个数据集
x变成了数据集y。
有没有一点似曾相识的感觉?没错,这就是我们熟知的【方程】,或者【映射】:
$$
y=f(x)
$$
我们将原来的代码换个样子,就更容易看出来了:
function prepare(){
return function (x){
return (new Task(x)).step(fn1).step(fn2).step(fn3);
}
}
let f = prepare();
let y = f(x);
上面的例子中,通过高阶函数prepare( )将原来的函数改变为一个延迟执行的,等待接收一个参数x并启动一系列处理流程的新函数。再继续进行代码转换,再来看一下f(x)执行到即将结束时的暂态状况:
//fn2Result是XX.step(fn2)执行完后返回的结果(值和方法都包含在Task容器中)
fn2Result.step(fn3);
上面的语句中,实际上变量只有fn2Result,step()方法和fn10都是提前定义好的,那么用函数化的思想来进行类比,这里也是实现了一个数据集x1到数据集y1的映射,所以它也可以被抽象为y = f ( x )的模式:
//先生成一个用于生成新函数的高阶函数,来实现局部调用
let goStep = function(fn){
return function(params){
let value = fn(params.value);
return new Task(value);
}
}
//fn2Result.step(fn3)这一句将被转换为如下形式
let requireFn2Result = goStep(fn3);
此处的requireFn2Result( )方法,只接受一个由前置步骤执行结束后得到的暂态结果,然后将其关键属性value传入fn3进行运算并传回一个支持继续链式调用的容器。我们来对代码进行一下转换:
function prepare(){
return function (x){
let fn2Result = (new Task(x)).step(fn1).step(fn2);
return requireFn2Result(fn2Result);
}
}
同理继续来简化前置步骤:
//暂时先忽略函数声明的位置
let requireFn2Result = goStep(fn3);
let requireFn1Result = goStep(fn2);
let requireInitResult = goStep(fn1);
function prepare(){
return function (x){
let InitResult = new Task(x);
return requireFn2Result(requireFn1Result(requireInitResult(InitResult)));
}
}
既然已经这样了,索性再向前一步,把new Task(x)也函数化好了:
let createTask = function(x){
return new Task(x);
};
3.3 函数化的代码
或许你已经被上面的一系列转化弄得晕头转向,我们暂停一下,来看看函数化后的代码变成了什么样子:
function prepare(){
return function (x){
return requireFn2Result(requireFn1Result(requireInitResult(createTask(x))));
}
}
let f = prepare();
let y = f(x);
这样的编码模式将核心业务逻辑在空间上放在一起,而把具体的实现封装起来,让开发者更容易看到一个需求实现过程的全貌。
3.4 休息一下
不知道你是否有注意到,在中间环节的组装过程中,其实并没有任何真实的数据出现,我们只使用了暂态的抽象数据来帮助我们写出映射方法f的细节,而随后暂态的数据又被新的函数取代,逐级迭代,直到暂态数据最终指向了最外层函数的形参,你可以重新审视一下上面的推演过程来体会函数式编程带来的变化,这个点是非常重要的。
3.5 进一步抽象
3.3节中函数化的代码中,存在一个很长的嵌套调用,如果业务逻辑步骤过多,那么这行代码会变得很长,同时也很难阅读,我们需要通过一些手段将这些中间环节的函数展开为一种扁平化的写法。
/**
*定义一个工具函数compose,接受两个函数作为参数,返回一个新函数
*新函数接受一个x作为入参,然后实现函数的迭代调用。
*/
var compose = function (f, g) {
return function (x) {
return f(g(x));
}
};
/**
*升级版本的compose函数,接受一组函数,实现左侧函数包裹右侧函数的形态
*/
let composeEx = function (...args) {
return (x)=>args.reduceRight((pre,cur)=>cur(pre),x);
}
看不懂的同学需要补补基础课了,需要注意的是工具函数返回的仍然是一个函数,我们使用上面的工具函数来重写一下3.3小节中的代码:
let pipeline = composeEx(requireFn2Result,requireFn1Result,requireInitResult,createTask);
function prepare(){
return function (x){
return pipeline(x);
}
}
let f = prepare();
let y = f(x);
还要继续?必须的,希望你还没有抓狂。代码中我们先执行prepare( )方法来得到一个新函数f,f执行时接收一个参数x,然后把x传入pipeline方法,并返回pipeline(x)。我们来进行一下对比:
//prepare执行后得到的新函数
let f = x => pipeline(x);
或许你已经发现了问题所在,这里的f函数相当于pipeline方法的代理,但这个代理什么额外的动作都没有做,相当于只是在函数调用栈中凭空增加了一层,但是执行了相同的动作。如果你能够理解这一点,就可以得出下面的转化结果:
let f = pipeline;
是不是很神奇?顺便提一下,它的术语叫做point free,当你深入学习【函数式编程】时就会接触到。
3.6 完整的转换代码
我们再进行一些简易的抽象和整理,然后得到完整的流程:
let composeEx = (...args) => (x) => args.reduceRight((pre,cur) =>cur(pre),x);
let getValue = (obj) => obj.value;
let createTask = (x) => new Task(x);
/*goStep执行后得到的函数也满足前面提到的“let f=(x)=>g(x)”的形式,可以将其pointfree化.
let goStep = (fn)=>(params)=>composeEx(createTask, fn, getValue)(params);
let requireFn2Result = goStep(fn3);
*/
let requireFn2Result = composeEx(createTask,fn3,getValue);
let requireFn1Result = composeEx(createTask,fn2,getValue);
let requireInitResult = composeEx(createTask,fn1,getValue);
let pipeline = composeEx(requireFn2Result,requireFn1Result,requireInitResult,createTask);
let f = pipeline;
let y = f(x);
可以看到我们定义完方法后,像搭积木一样把它们组合在一起,就得到了一个可以实现目标功能的函数。
3.7 为什么它看起来变得更复杂了
如果只看上面的示例,的确是这样的,上面的示例只是为了展示函数式编程让代码向着怎样一个方向去变化而已,而并没有展示出函数式编程的优势,这种转变和一个jQuery开发者刚开始使用诸如angular,vue,React框架时感受到的强烈不适感是很相似的,毕竟思想的转变是非常困难的。
面向对象编程写出的代码看起来就像是一个巨大的关系网和逻辑流程图,比如连续读其中10行代码,你或许能够很清晰地看到某个步骤执行前和执行后程序的状态,但是却很难看清整体的业务逻辑流程;而函数式编程正好是相反的,你可以在短短的10行代码中看到整个业务流程,当你想去深究某个具体步骤时,再继续展开,另一方面,关注数据和函数组合可以将你从复杂的this和对象的关系网中解放出来。
四. 两个主角
数据和函数是【函数式编程】中的两大核心概念,它为我们提供了用数学的眼光看世界的独特视角,同时它也更程序员该有的思维模式——设计程序,而不是仅仅是复现业务逻辑:
程序设计 = 数据结构 + 算法 Vs 函数式编程 = 数据 + 函数
但为了更加安全有效地使用,它们和传统编程中的同名概念相比多了一些限制。
函数Vs纯函数
函数式编程中所传递和使用的函数,被要求为【纯函数】。纯函数需要满足如下两个条件:
- 只依赖自己的参数
- 执行过程没有副作用
为什么纯函数只能依赖自己的参数?因为只有这样,我们才不必在对函数进行传递和组合的时候小心翼翼,生怕在某个环节弄丢了this的指向,如果this直接报错还好,如果指向了错误的数据,程序本身在运行时也不会报错,这种情况的调试是非常令人头疼的,除了逐行运行并检查对应数据的状态,几乎没什么高效的方法。面向对象的编程中,我们不得不使用很多bind函数来绑定一个函数的this指向,而纯函数就不存在这样的问题。来看这样两个函数:
var a = 1;
function inc(x){
return a + x;
}
function pureInc(x){
let a = 1;
return x + a;
}
对于inc这个函数来说,改变外部条件a的值就会造成inc函数对于同样的入参得到不同的结果的情况,换言之在入参确定为3的前提下,每次执行inc(3)得到的结果是不确定的,所以它是不纯的。而pureInc函数就不依赖于外界条件的变化,pureInc(3)无论执行多少次,无论外界参数如何变化,其输出结果都是确定的。
在面向对象的编程中,我们写的函数通常都不是纯函数,因为编程中或多或少都需要在不同的函数中共享一些标记状态的变量,我们更倾向与将其放在更高层的作用域里,通过标识符的右查询会沿作用域链寻找的机制来实现数据共享。
什么是函数的副作用呢?一个函数执行过程对产生了外部可观察的变化那么就说这个函数是有副作用的。最常见的情况就是函数接受一个对象作为参数,但是在函数内部对其进行了修改,javascript中函数在传递对象参数时会将其地址传入调用的函数,所以函数内部所做的修改也会同步反应到函数外部,这种副作用会在函数组合时造成最终数据的不可预测性,因为有关某个对象的函数都有可能得到不确定的输出。
数据Vs不可变数据
javascript中的对象很强大也很灵活,可并不是所有的场景中我们都需要这种灵活性。来看这样一个例子:
let a = {
name:\'tony\'
}
let b = a;
modify(b);
console.log(a.name);
我们无法确定上面的输出结果,因为a和b这两个标识符指向了堆中的相同的地址,可外界无法知道在modify函数中是否对b的属性做出了修改。有些场景中为了使得逻辑过程更加可靠,我们不希望后续的操作和处理对最原始的数据造成影响,这个时候我们很确定需要拿到一个数据集的复制(比如拿到表格的总数据,在实现某些过滤功能的时候,通常需要留存一个表格数据的备份,以便取消过滤时可以恢复原貌),这就引出了老生常谈的深拷贝和浅拷贝的话题。
【深拷贝】是一种典型的防御性编程,因为在浅拷贝的机制下,修改对象属性的时候会影响到所有指向它的标识符,从而造成不可预测的结果。
在javascript中,常见的深拷贝都是通过递归来实现的,然后利用语言特性做出一些代码层面的优化,例如各个第三方库中的extend( )方法或者deepClone( )。可是当一个结构很深或者复杂度很高时,深拷贝的耗时就会大幅增加,有的时候我们关注的可能只是数据结构中的一部分,也就是说新老对象中很大一部分数据是一致的,可以共享的,但深拷贝过程中忽视了这种情况而简单粗暴地对整个对象进行递归遍历和克隆。
事实上【深拷贝】并不是防御性编程的唯一方法,Facebook的Immutable.js就用不可变数据的思路来解决这个问题,它将对象这种引用值变得更像原始值(javascript中的原始值创建后是不能修改的)。
//Immutable.js官网示例
var map1 = Immutable.Map({ a: 1, b: 2, c: 3 });
var map2 = map1.set(\'b\', 50);
map1.get(\'b\'); // 2
map2.get(\'b\'); // 50
你可以查看【Immutable.js官方文档】来了解如何使用它,通常它是结合React全家桶一起使用的。如果你对其实现原理感兴趣,可以查看《深入探究Immutable.js的实现机制》一文或者查看其他资料,来了解一下Hash树和Trie树是如何作为Immutable的算法基础而被应用的。
当标识符指向不变的数据,当函数没有副作用,就可以大胆广泛地使用函数式编程了。
四. 前端的学习路线
-
javascript基础
如果你能够很清楚
高阶函数,柯里化,反柯里化这些关键词的含义和一般用途,并且至少了解Array的map和reduce方法做了什么事情,那么就可以进行下一步。否则就需要好好复习一下javascript的基础知识。在javascript中进行函数式编程会反复涉及到这些基本技术的运用。 -
《javascript函数式编程指南》
地址:https://llh911001.gitbooks.io/mostly-adequate-guide-chinese/content/
这是一本来自于gitbook的翻译版的非常棒的开源电子书,这本书很棒,但是如果将函数式编程的相关知识分为初中高级的话,这本书似乎只涵盖了初级和高级,而省略了中级的部分,当内容涉及到范畴论和代数结构的时候,理解难度会突然一下变得很大。当你读不懂的时候可以先停下来,用下一个资料进行过渡,然后回过头来再继续阅读后续的部分。
同时提一句,翻译者@胡子大哈也是之前提及的那本著名的《React小书》的主要作者。
-
Ramda.js官网博文集
Ramda.js为javascript提供了一系列函数式编程的工具函数,但官网的《Thinking In Ramda》系列教程,是非常好的中级教程,结合Ramda的API进行讲解,让开发者更容易理解函数式编程,它正好弥补了前一个资料中没有中级教程的问题。 -
Ramda.js的API
不得不说很多前端开发者都是从API开始学习函数式编程的,但很快就会发现学了和没学差不多,因为没有理论基础,你很难知道该去使用它。就好像给了你最顶尖的工具,你也没法一次性就做出好吃的牛排,因为你不会做。
-
Rx.js和Immutable.js
事实上笔者自己也还没有进行到这个阶段的学习,
Rx.js是隶属于Angular全家桶的,Immutable.js是隶属于React全家桶的,即使在自己目前的工作中没有直接使用到,你也应该了解它们。 -
代数结构的理论基础
地址:https://github.com/fantasyland/fantasy-land
当你具备了基本的使用能力,想要更上一层楼的时候,就需要重新整合函数式编程的理论体系。这个项目用于解释函数式编程的理论基础中各类术语及相关用途。
五. 小结
【函数式编程】为我们展现了javascript语言的另一种灵活性。
开发人员会发现自己可以从更宏观地角度来观察整个业务流程,而不是往返于业务逻辑和实现细节之间。
测试人员会发现它很容易进行单元测试,不仅因为它的纯函数特性,也因为数据和动作被分离了。
游戏玩家会发现它和自己在《我的世界》里用方块来搭建世界就是这样子的。
工程师会发现它和对照零件图纸编写整个加工流水线的工艺流程时就是这样做的。
数学家会说用数学的思维是可以描述世界的(如果你接触过数学建模应该会更容易明白)。
【函数式编程】让开发者理解程序设计这件事本质是是一种设计,是一种创造行为,和其他通过组合功能单元而得到更强大的功能单元的行为没有本质区别。