pytorch transforms图像增强
Posted SL1029_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch transforms图像增强相关的知识,希望对你有一定的参考价值。
一、前言
在学习自己的项目发现自己有很多基础知识不牢,对于图像处理有点不太清楚,因此写下来作为自己的笔记,主要是我想自己动手写一下每一句代码到底做了什么,而不是单纯的我看了知道了它做了什么,说白了,不想停在看,而是要真正自己敲。
本文基于的是pytorch1.7.1
二、图像处理
深度学习是由数据驱动的,而数据的数量和分布对于模型的优劣具有决定性作用,所以我们需要对数据进行一定的预处理以及数据增强,用于提升模型的泛化能力。
一般来说深度学习神经网络训练前都需要做数据增强 (Data Augmentation) 又称为数据增广、数据扩增,它是对 训练集 进行变换,使训练集更丰富,从而让模型更具 泛化能力。
下面为常见的图像变换
1.原始图片

显示图片,并读取图片大小
| 1 2 3 4 5 6 7 8 9 | from torchvision import transforms from PIL import Image # 用于读取图片 import matplotlib.pyplot as plt # 用于显示图片 image_path = './dog.jpg' image = Image.open(image_path) plt.imshow(image) print(image.size) plt.show() |

图片大小(1024, 683)
2.调整图片大小transforms.Resize
2.1.transforms.Resize(x)
主要用于调整PILImage对象的尺寸大小,图片短边缩放至x,长宽比保持不变
将图片短边缩放至x,长宽比保持不变,上述图片执行transforms.Resize(300)
| 1 2 3 4 5 6 7 8 9 10 11 | from torchvision import transforms from PIL import Image # 用于读取图片 import matplotlib.pyplot as plt # 用于显示图片 # 图片显示,打印图片大小 image_path = './dog.jpg' image = Image.open(image_path) resize = transforms.Resize(300) image1 = resize(image) plt.imshow(image1) print(image1.size) plt.show() |
图片大小(449, 300)
得到如下

2.2.transforms.Resize([x, y])
同时指定图片长宽,这样会改变长宽比例但是不是裁剪,可以恢复
| 1 2 3 4 5 6 7 8 9 10 11 | from torchvision import transforms from PIL import Image # 用于读取图片 import matplotlib.pyplot as plt # 用于显示图片 # 图片显示,打印图片大小 image_path = './dog.jpg' image = Image.open(image_path) resize = transforms.Resize([512, 300]) image1 = resize(image) plt.imshow(image1) print(image1.size) plt.show() |
图片大小(512, 300)

2.3关于图片的恢复
测试代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from torchvision import transforms from PIL import Image # 用于读取图片 import matplotlib.pyplot as plt # 用于显示图片 # 图片显示,打印图片大小 image_path = './dog.jpg' image = Image.open(image_path) w, h = image.size resize = transforms.Resize([512, 300]) image1 = resize(image) resize2 = transforms.Resize([h, w]) image2 = resize2(image1) plt.imshow(image2) print(image2.size) plt.show() |
图片大小(1024, 683)
注意这里要使用transforms.Resize([h, w])

3.图片裁剪
3.1中心裁剪transforms.CenterCrop
作用:中心裁剪图片
主要参数:size,表示需要裁剪的图片大小
代码示例:
| 1 2 3 4 5 6 7 8 9 10 11 | from torchvision import transforms from PIL import Image import matplotlib.pyplot as plt transform = transforms.CenterCrop(512) image_path= "./dog.jpg" image = Image.open(image_path) image1 = transform(image) plt.imshow(image1) print(image1.size) plt.show() image1.save('./dog_clipping.jpg') |
图片大小(512, 512)
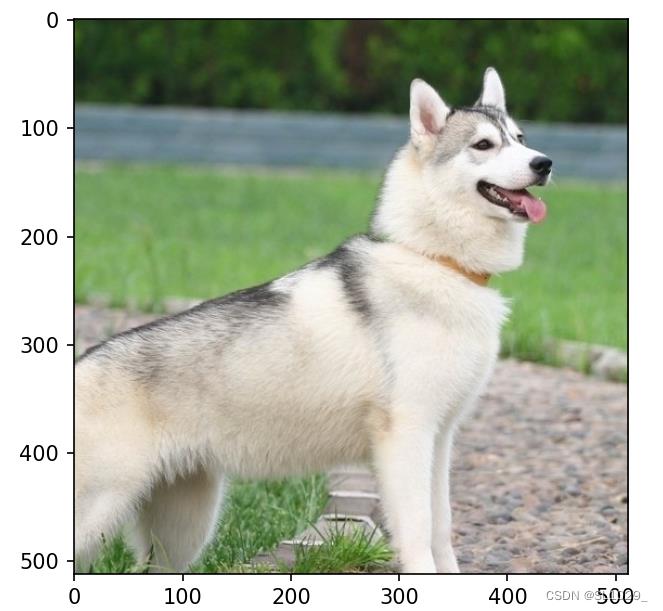
3.2随机裁剪transforms.RandomCrop(size,padding=None,pad_if_needed=False,fill=0,padding_mode='constant')
主要参数:
size:为需要裁剪的图片大小
padding:设置填充大小
大小为a:表示上下左右都填充a个元素
大小为(a, b):表示左右填充a个元素,上下填充b个元素
大小为(a, b, c, d):表示左上右下填充a, b, c, d个元素
pad_if_needed:若图像小于设定 size,则填充,此时该项需要设置为 True
padding_mode:填充模式,主要有四种
- constant:像素值由 fill 设定。
- edge:像素值由图像边缘像素决定。
- reflect:镜像填充,最后一个像素不镜像,例如 [1, 2, 3, 4] → [3, 2, 1, 2, 3, 4, 3, 2]。
- symmetric:镜像填充,最后一个像素镜像,例如 [1, 2, 3, 4] → [2, 1, 1, 2, 3, 4, 4, 3]。
fill:当填充模式为padding_mode的填充值
代码示例:
| 1 2 3 4 5 6 7 8 9 10 11 | from torchvision import transforms import matplotlib.pyplot as plt from PIL import Image transform = transforms.RandomCrop(size=(512, 512), padding=50, pad_if_needed=True, fill=0,padding_mode="constant") image_path = "./dog.jpg" image = Image.open(image_path) random_crop_image = transform(image) print(random_crop_image.size) plt.imshow(random_crop_image) plt.show() random_crop_image.save("./random_crop_image.jpg") |
图片大小(512, 512)
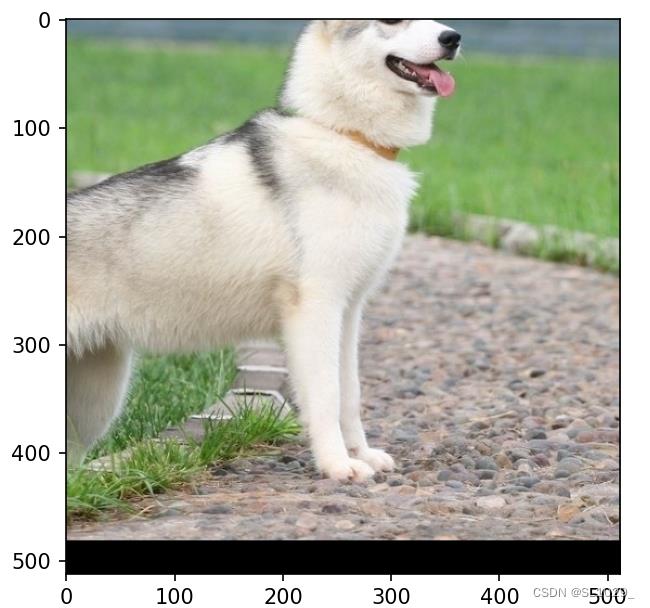
3.3transforms.RandomResizedCrop
RandomResizedCrop(size,scale=(0.08,1.0),ratio=(3/4,4/3),interpolation)
将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小;
主要参数:
size:为最终图片要resize的大小
scale:为随机采样最少要覆盖原图的比例,在resize前
ratio:为随机采样宽高的比例,也在resize前
interpolation:插值方法
代码示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from torchvision import transforms import matplotlib.pyplot as plt from PIL import Image transform = transforms.RandomResizedCrop(size=(256, 256), scale=(0.08, 1), ratio=(3/ 4, 4/3), interpolation=Image.NEAREST) image_path = "./dog.jpg" image = Image.open(image_path) random_resize_crop_image = transform(image) print(random_resize_crop_image.size) plt.imshow(random_resize_crop_image) plt.show() random_resize_crop_image.save("./dog_random_resize_crop.jpg") |
[九]深度学习Pytorch-transforms图像增强(剪裁翻转旋转)
0. 往期内容
[二]深度学习Pytorch-张量的操作:拼接、切分、索引和变换
[七]深度学习Pytorch-DataLoader与Dataset(含人民币二分类实战)
[八]深度学习Pytorch-图像预处理transforms
[九]深度学习Pytorch-transforms图像增强(剪裁、翻转、旋转)
[十]深度学习Pytorch-transforms图像操作及自定义方法
深度学习Pytorch-transforms图像增强
1. 数据增强


2. 剪裁
2.1 transforms.CenterCrop(size)
transforms.CenterCrop(size)
(1)功能:从图像中心裁剪尺寸为size的图片;
(2)参数:
size: 若为int,则尺寸为size*size; 若为(h,w),则尺寸为h*w.
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 1 CenterCrop
transforms.CenterCrop(196), # 裁剪为196*196,如果是512的话,超出244的区域填充为黑色
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
2.2 transforms.RandomCrop(size, fill=0, padding_mode=‘constant’)
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
(1)功能:对图像随机裁剪出尺寸为size的图片;
(2)参数:
size: 若为int,则尺寸为size*size; 若为(h,w),则尺寸为h*w;
padding: 设置填充大小:
I. 当padding为a时,左右上下均填充a个像素;
II. 当padding为(a,b)时,左右填充a个像素,上下填充b个像素;
III. 当padding为(a,b,c,d)时,左、上、右、下分别填充a、b、c、d;
pad_if_need:若设定的size大于原图像尺寸,则填充;
padding_mode:填充模式,有4种模式:
I. constant:像素值由fill设定;
II. edge:像素值由图像边缘的像素值决定;
III. reflect:镜像填充,最后一个像素不镜像,eg. [1,2,3,4] --> [3,2,1,2,3,4,3,2];

向左:由于1不会镜像,所以左边镜像2、3;
向右:由于4不会镜像,所以右边镜像3、2;
IV. symmetric:镜像填充,最后一个像素镜像,eg. [1,2,3,4] --> [2,1,1,2,3,4,4,3];

向左:1、2镜像;
向右:4、3镜像;
fill:当padding_mode='constant'时,用于设置填充的像素值;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 2 RandomCrop
transforms.RandomCrop(224, padding=16),
transforms.RandomCrop(224, padding=(16, 64)),
transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)), #fill=(255, 0, 0)RGB颜色
#当size大于图片尺寸,即512大于244,pad_if_needed必须设置为True,否则会报错,其他区域会填充黑色(0,0,0)
transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
transforms.RandomCrop(224, padding=64, padding_mode='edge'), #边缘
transforms.RandomCrop(224, padding=64, padding_mode='reflect'), #镜像
transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'), #镜像
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
2.3 transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3/4, 4/3), interpolation)
transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3/4, 4/3), interpolation=<InterpolationMode.BILINEAR: 'bilinear'>)
(1)功能:随机大小、随机长宽比裁剪图片;
(2)参数:
size: 裁剪图片尺寸,若为int,则尺寸为size*size; 若为(h,w),则尺寸为h*w,size是最后图片的尺寸;
scale: 随机裁剪面积比例,默认区间(0.08,1),scale默认是随机选取0.08-1之间的一个数
ratio: 随机长宽比,默认区间(3/4,4/3),ratio默认是随机选取3/4-4/3之间的一个数
interpolation: 插值方法,eg. PIL. Image. NEAREST, PIL. Image. BILINEAR, PIL. Image. BICUBIC;
(3)步骤:
随机确定scale和ratio,然后对原始图片进行选取,再将选取的片段缩放到size大小;
(4)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 3 RandomResizedCrop
transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
2.4 transforms.FiveCrop(size)
transforms.FiveCrop(size)
(1)功能:在图像的左上、右上、左下、右下、中心随机剪裁出尺寸为size的5张图片;
(2)参数:
size: 裁剪图片尺寸,若为int,则尺寸为size*size; 若为(h,w),则尺寸为h*w;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 4 FiveCrop
transforms.FiveCrop(112), #单独使用错误,直接使用transforms.FiveCrop(112)会报错,需要跟下一行一起使用
#lamda的冒号之前是函数的输入(crops),冒号之后是函数的返回值
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])), #这里进行了ToTensor(),后面不需要执行Totensor()和Normalize,第114-115行
])
使用FiveCrop时需要使用五维可视化,这是因为inputs为五维(batch_size*ncrops*chanel*图像宽*图像高),代码如下:
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data
#五维可视化
#使用FiveCrop时inputs为五维:batch_size*ncrops*chanel*图像宽*图像高,此时ncrops=5
bs, ncrops, c, h, w = inputs.shape
for n in range(ncrops):
img_tensor = inputs[0, n, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(1)
2.5 transforms.TenCrop(size, vertical_flip=False)
transforms.TenCrop(size, vertical_flip=False)
(1)功能:在图像的左上、右上、左下、右下、中心随机剪裁出尺寸为size的5张图片,然后再对这5张照片进行水平或者垂直镜像来获得总共10张图片;
(2)参数:
size: 裁剪图片尺寸,若为int,则尺寸为size*size; 若为(h,w),则尺寸为h*w;
vertical_flip: 是否垂直翻转,默认为False代表进行水平翻转;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 5 TenCrop
transforms.TenCrop(112, vertical_flip=False),
#lamda的冒号之前是函数的输入(crops),冒号之后是函数的返回值
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
])
使用TenCrop时需要使用五维可视化,这是因为inputs为五维(batch_size*ncrops*chanel*图像宽*图像高),代码如下:
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data
#五维可视化
#使用FiveCrop时inputs为五维:batch_size*ncrops*chanel*图像宽*图像高,此时ncrops=5
bs, ncrops, c, h, w = inputs.shape
for n in range(ncrops):
img_tensor = inputs[0, n, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(1)
3. 旋转
3.1 transforms.RandomHorizontalFlip(p=0.5)
transforms.RandomHorizontalFlip(p=0.5)
(1)功能:根据概率对图片进行水平(左右)翻转,每次根据概率来决定是否执行翻转;
(2)参数:
p: 反转概率;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 1 Horizontal Flip
transforms.RandomHorizontalFlip(p=1), #执行水平翻转的概率为1
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
3.2 transforms.RandomVerticalFlip(p=0.5)
transforms.RandomVerticalFlip(p=0.5)
(1)功能:根据概率对图片进行垂直(上下)翻转,每次根据概率来决定是否执行翻转;
(2)参数:
p: 反转概率;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 2 Vertical Flip
transforms.RandomVerticalFlip(p=0.5), #执行垂直翻转的概率为0.5
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
3.3 transforms.RandomRotation(degrees, expand=False, center=None, fill=0, resample=None)
transforms.RandomRotation(degrees, expand=False, center=None, fill=0, resample=None)
(1)功能:对图片旋转随机的角度;
(2)参数:
degrees: 旋转角度;
I. 当degrees为a时,在区间(-a,a)之间随机选择旋转角度;
II. 当degrees为(a,b)时,在区间(a,b)之间随机选择旋转角度;
resample: 重采样方法;
expand: 是否扩大图片以保持原图信息,因为旋转后可能有些信息被遮挡了而丢失,如果扩大尺寸则可以显示完整图片信息;
center: 旋转点设置,默认沿着中心旋转;
(3)代码示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 3 RandomRotation
transforms.RandomRotation(90),
transforms.RandomRotation((90), expand=True), #当batch_size不为1时,expand使用时,张量在第0个维度尺寸需要匹配,需要对图片缩放到统一的size
transforms.RandomRotation(30, center=(0, 0)), #左上角旋转
transforms.RandomRotation(30, center=(0, 0), expand=True), #expand只可以针对中心旋转来扩展,无法用于左上角旋转来找回丢失的信息
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
4. 完整代码示例
# -*- coding: utf-8 -*-
"""
# @file name : transforms_methods_1.py
# @author : tingsongyu
# @date : 2019-09-11 10:08:00
# @brief : transforms方法(一)
"""
import os
import numpy as np
import torch
import random
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from tools.my_dataset import RMBDataset
from PIL import Image
from matplotlib import pyplot as plt
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = "1": 0, "100": 1
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None]) #normalize是减去均值除以标准差,反操作就是乘以标准差加上均值
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C 通道变换
img_ = np.array(img_) * 255 #将0-1转换为0-255
#针对chanel是三通道还是一通道分别转换
if img_.shape[2] == 3: #RGB图像
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB') #将ndarray数据转换为image
elif img_.shape[2] == 1: #灰度图像
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got !".format(img_.shape[2]) )
return img_
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((224, 224)), #图片统一缩放到244*244
# 1 CenterCrop
# transforms.CenterCrop(196), # 裁剪为196*196,如果是512的话,超出244的区域填充为黑色
# 2 RandomCrop
# transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)), #fill=(255, 0, 0)RGB颜色
#当size大于图片尺寸,即512大于244,pad_if_needed必须设置为True,否则会报错,其他区域会填充黑色(0,0,0)
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'), #边缘
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'), #镜像
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'), #镜像
# 3 RandomResizedCrop
# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
# 4 FiveCrop
# transforms.FiveCrop(112), #单独使用错误,直接使用transforms.FiveCrop(112)会报错,需要跟下一行一起使用
#lamda的冒号之前是函数的输入(crops),冒号之后是函数的返回值
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])), #这里进行了ToTensor(),后面不需要执行Totensor()和Normalize,第114-115行
# 5 TenCrop
# transforms.TenCrop(112, vertical_flip=False),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 1 Horizontal Flip
# transforms.RandomHorizontalFlip(p=1), #执行水平翻转的概率为1
# 2 Vertical Flip
# transforms.RandomVerticalFlip(p=0.5), #执行垂直翻转的概率为0.5
# 3 RandomRotation
# transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True), #当batch_size不为1时,expand使用时,张量在第0个维度尺寸需要匹配,需要对图片缩放到统一的size
# transforms.RandomRotation(30, center=(0, 0)), #左上角旋转
# transforms.RandomRotation(30, center=(0, 0), expand=True), #expand只可以针对中心旋转来扩展,无法用于左上角旋转来找回丢失的信息
#若使用FiveCrop或TenCrop,以下两行需要注释掉
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data
#四维可视化
#input的大小为四维:batch_size*chanel*图像宽*图像高 # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform) #对transform进行逆变换,可视化图片
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
#五维可视化
#使用FiveCrop时inputs为五维:batch_size*ncrops*chanel*图像宽*图像高,此时ncrops=5
bs, ncrops, c, h, w = inputs.shape
# for n in range(ncrops):
# img_tensor = inputs[0, n, ...] # C H W
# img = transform_invert(img_tensor, train_transform)
# plt.imshow(img)
# plt.show()
# plt.pause(1)
以上是关于pytorch transforms图像增强的主要内容,如果未能解决你的问题,请参考以下文章