C++源码剖析——unordered_map和unordered_set
Posted 落樱弥城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++源码剖析——unordered_map和unordered_set相关的知识,希望对你有一定的参考价值。
前言:之前看过侯老师的《STL源码剖析》但是那已经是多年以前的,现在工作中有时候查问题和崩溃都需要了解实际工作中使用到的STL的实现。因此计划把STL的源码再过一遍。
摘要:本文描述了llvm中libcxx的unordered_map和unordered_set的实现。
关键字:__hash_table,unordered_map和unordered_set
其他:参考代码LLVM-libcxx
unordered_map和unordered_set是是STL提供的无序的容器,二者都是通过哈希表实现的。
1 哈希表
1.1 __hash_table
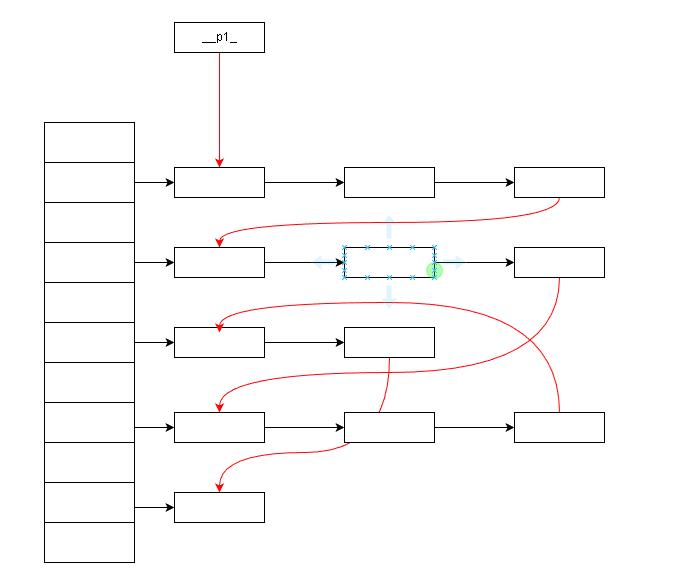
STL中的哈希表实现是通过链式实现的,表中有一个数组,数组的每个成员是一个单链表的节点,一个hash值对应一个链表。
__bucket_list_就是一个链表数组,数组的成员是__hash_node_base的指针。__p1_存储第一个元素的指针和分配器(__p1_就是一个完整链表的头结点,哈希表可以通过__p1_访问到每一个元素),__p2__为哈希表中元素的数量和哈希函数,__p3__为当前哈希表数据的紧缩程度(默认1.0),插入元素时会根据这个值决定是否需要对当前表记性rehash。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
class __hash_table
typedef _Tp value_type;
typedef _Hash hasher;
typedef typename _NodeTypes::__next_pointer __next_pointer;
typedef typename _NodeTypes::__node_base_type __first_node;
typedef unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
// --- Member data begin ---
__bucket_list __bucket_list_;
__compressed_pair<__first_node, __node_allocator> __p1_;
__compressed_pair<size_type, hasher> __p2_;
__compressed_pair<float, key_equal> __p3_;
;
__hash_node_base
和STL中其他节点的实现相同,哈希表的节点的索引和值域被拆分了开来,分别为__hash_node_base和__hash_node。__bucket_list_就是一个__hash_node_base的数组。
template <class _NodePtr>
struct __hash_node_base
typedef __hash_node_base __first_node;
typedef __rebind_pointer_t<_NodePtr, __first_node> __node_base_pointer;
typedef _NodePtr __node_pointer;
#if defined(_LIBCPP_ABI_FIX_UNORDERED_NODE_POINTER_UB)
typedef __node_base_pointer __next_pointer;
#else
typedef __conditional_t<is_pointer<__node_pointer>::value, __node_base_pointer, __node_pointer> __next_pointer;
#endif
__next_pointer __next_;
;
template <class _Tp, class _VoidPtr>
struct _LIBCPP_STANDALONE_DEBUG __hash_node: public __hash_node_base<__rebind_pointer_t<_VoidPtr, __hash_node<_Tp, _VoidPtr> >>
typedef _Tp __node_value_type;
size_t __hash_;
__node_value_type __value_;
;
__bucket_list
我们从__bucket_list的声明中能够看出其就是一个智能指针,其大小保存在自身的销毁器__bucket_list_deallocator中。
typedef unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
template <class _Alloc>
class __bucket_list_deallocator
typedef _Alloc allocator_type;
typedef allocator_traits<allocator_type> __alloc_traits;
typedef typename __alloc_traits::size_type size_type;
__compressed_pair<size_type, allocator_type> __data_;
;
1.2 插入元素
__node_insert_unique
插入节点时先调用哈希函数计算当前节点值的哈希值,然后调用__node_insert_unique_prepare在哈希表中查找是否有对应的节点。没有的话再根据hash值插入节点。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
pair<typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::iterator, bool>
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique(__node_pointer __nd)
__nd->__hash_ = hash_function()(__nd->__value_);
__next_pointer __existing_node =
__node_insert_unique_prepare(__nd->__hash(), __nd->__value_);
// Insert the node, unless it already exists in the container.
bool __inserted = false;
if (__existing_node == nullptr)
__node_insert_unique_perform(__nd);
__existing_node = __nd->__ptr();
__inserted = true;
return pair<iterator, bool>(iterator(__existing_node, this), __inserted);
__node_insert_unique_prepare
__node_insert_unique_prepare的基本流程是先利用__constrain_hash计算对应元素在哈希表中的节点。
__constrain_hash计算的方式比较简单就是,如果__bc比较大等于size_t::max就会按照__bc```对__hash```进行截断,否则就是根据二者大小选择是否取余。
size_t __constrain_hash(size_t __h, size_t __bc)
return !(__bc & (__bc - 1)) ? __h & (__bc - 1) :
(__h < __bc ? __h : __h % __bc);
拿到头结点后就是遍历每个链表寻找是否有对应的元素。最后根据当前哈希表的元素数量和实际大小选择是否进行rehash。如果进行rehash,rehash后的大小是当前bucket大小的2倍和元素数量/factor的最大值。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
_LIBCPP_INLINE_VISIBILITY
typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::__next_pointer
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique_prepare(
size_t __hash, value_type& __value)
size_type __bc = bucket_count();
if (__bc != 0)
size_t __chash = std::__constrain_hash(__hash, __bc);
__next_pointer __ndptr = __bucket_list_[__chash];
if (__ndptr != nullptr)
for (__ndptr = __ndptr->__next_; __ndptr != nullptr &&
std::__constrain_hash(__ndptr->__hash(), __bc) == __chash;
__ndptr = __ndptr->__next_)
if (key_eq()(__ndptr->__upcast()->__value_, __value))
return __ndptr;
if (size()+1 > __bc * max_load_factor() || __bc == 0)
__rehash_unique(_VSTD::max<size_type>(2 * __bc + !std::__is_hash_power2(__bc),
size_type(std::ceil(float(size() + 1) / max_load_factor()))));
return nullptr;
__rehash
在进行rehash前还会再次计算实际需要的大小,最后调用__do_rehash做实际上的rehash,__do_rehash只会重新分配__bucket_list然后将之前元素的节点连接到__buck_list上。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
template <bool _UniqueKeys>
void
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__rehash(size_type __n)
_LIBCPP_DISABLE_UBSAN_UNSIGNED_INTEGER_CHECK
if (__n == 1)
__n = 2;
else if (__n & (__n - 1))
__n = std::__next_prime(__n);
size_type __bc = bucket_count();
if (__n > __bc)
__do_rehash<_UniqueKeys>(__n);
else if (__n < __bc)
__n = _VSTD::max<size_type>
(
__n,
std::__is_hash_power2(__bc) ? std::__next_hash_pow2(size_t(std::ceil(float(size()) / max_load_factor()))) :
std::__next_prime(size_t(std::ceil(float(size()) / max_load_factor())))
);
if (__n < __bc)
__do_rehash<_UniqueKeys>(__n);
从__node_insert_unique_perform的实现中能够看出这里采取的是头插入。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
_LIBCPP_INLINE_VISIBILITY
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_insert_unique_perform(
__node_pointer __nd) _NOEXCEPT
size_type __bc = bucket_count();
size_t __chash = std::__constrain_hash(__nd->__hash(), __bc);
// insert_after __bucket_list_[__chash], or __first_node if bucket is null
__next_pointer __pn = __bucket_list_[__chash];
if (__pn == nullptr)
__pn =__p1_.first().__ptr();
__nd->__next_ = __pn->__next_;
__pn->__next_ = __nd->__ptr();
// fix up __bucket_list_
__bucket_list_[__chash] = __pn;
if (__nd->__next_ != nullptr)
__bucket_list_[std::__constrain_hash(__nd->__next_->__hash(), __bc)] = __nd->__ptr();
else
__nd->__next_ = __pn->__next_;
__pn->__next_ = __nd->__ptr();
++size();
1.3 删除元素
删除元素比较简单就是改变链表的指向,不会改变哈希表的大体结构。
template <class _Tp, class _Hash, class _Equal, class _Alloc>
typename __hash_table<_Tp, _Hash, _Equal, _Alloc>::__node_holder
__hash_table<_Tp, _Hash, _Equal, _Alloc>::remove(const_iterator __p) _NOEXCEPT
// current node
__next_pointer __cn = __p.__node_;
size_type __bc = bucket_count();
size_t __chash = std::__constrain_hash(__cn->__hash(), __bc);
// find previous node
__next_pointer __pn = __bucket_list_[__chash];
for (; __pn->__next_ != __cn; __pn = __pn->__next_)
;
// Fix up __bucket_list_
// if __pn is not in same bucket (before begin is not in same bucket) &&
// if __cn->__next_ is not in same bucket (nullptr is not in same bucket)
if (__pn == __p1_.first().__ptr()
|| std::__constrain_hash(__pn->__hash(), __bc) != __chash)
if (__cn->__next_ == nullptr
|| std::__constrain_hash(__cn->__next_->__hash(), __bc) != __chash)
__bucket_list_[__chash] = nullptr;
// if __cn->__next_ is not in same bucket (nullptr is in same bucket)
if (__cn->__next_ != nullptr)
size_t __nhash = std::__constrain_hash(__cn->__next_->__hash(), __bc);
if (__nhash != __chash)
__bucket_list_[__nhash] = __pn;
// remove __cn
__pn->__next_ = __cn->__next_;
__cn->__next_ = nullptr;
--size();
return __node_holder(__cn->__upcast(), _Dp(__node_alloc(), true));
clear
template <class _Tp, class _Hash, class _Equal, class _Alloc>
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::clear() _NOEXCEPT
if (size() > 0)
__deallocate_node(__p1_.first().__next_);
__p1_.first().__next_ = nullptr;
size_type __bc = bucket_count();
for (size_type __i = 0; __i < __bc; ++__i)
__bucket_list_[__i] = nullptr;
size() = 0;
template <class _Tp, class _Hash, class _Equal, class _Alloc>
void __hash_table<_Tp, _Hash, _Equal, _Alloc>::__deallocate_node(__next_pointer __np) _NOEXCEPT
__node_allocator& __na = __node_alloc();
while (__np != nullptr)
__next_pointer __next = __np->__next_;
__node_pointer __real_np = __np->__upcast();
__node_traits::destroy(__na, _NodeTypes::__get_ptr(__real_np->__value_));
__node_traits::deallocate(__na, __real_np, 1);
__np = __next;
2 unordered_map
unordered_map中存储的元素是键值对。
template <class _Key, class _Tp, class _Hash = hash<_Key>, class _Pred = equal_to<_Key>,
class _Alloc = allocator<pair<const _Key, _Tp> > >
class _LIBCPP_TEMPLATE_VIS unordered_map
public:
// types
typedef _Key key_type;
typedef _Tp mapped_type;
typedef __type_identity_t<_Hash> hasher;
typedef __type_identity_t<_Pred> key_equal;
typedef __type_identity_t<_Alloc> allocator_type;
typedef pair<const key_type, mapped_type> value_type;
typedef value_type& reference;
typedef const value_type& const_reference;
static_assert((is_same<value_type, typename allocator_type::value_type>::value),
"Allocator::value_type must be same type as value_type");
private:
typedef __hash_value_type<key_type, mapped_type> __value_type;
typedef __unordered_map_hasher<key_type, __value_type, hasher, key_equal> __hasher;
typedef __unordered_map_equal<key_type, __value_type, key_equal, hasher> __key_equal;
typedef __rebind_alloc<allocator_traits<allocator_type>, __value_type> __allocator_type;
typedef __hash_table<__value_type, __hasher,
__key_equal, __allocator_type> __table;
__table __table_;
3 unordered_set
unordered_set中存储的元素是键值。
template <class _Value, class _Hash = hash<_Value>, class _Pred = equal_to<_Value>,
class _Alloc = allocator<_Value> >
class _LIBCPP_TEMPLATE_VIS unordered_set
public:
// types
typedef _Value key_type;
typedef key_type value_type;
typedef __type_identity_t<_Hash> hasher;
typedef __type_identity_t<_Pred> key_equal;
typedef __type_identity_t<_Alloc> allocator_type;
typedef value_type& reference;
typedef const value_type& const_reference;
static_assert((is_same<value_type, typename allocator_type::value_type>::value),
"Allocator::value_type must be same type as value_type");
static_assert(is_same<allocator_type, __rebind_alloc<allocator_traits<allocator_type>, value_type> >::value,
"[allocator.requirements] states that rebinding an allocator to the same type should result in the "
"original allocator");
private:
typedef __hash_table<value_type, hasher, key_equal, allocator_type> __table;
__table __table_;
C++源码剖析——list
前言:之前看过侯老师的《STL源码剖析》但是那已经是多年以前的,现在工作中有时候查问题和崩溃都需要了解实际工作中使用到的STL的实现。因此计划把STL的源码再过一遍。
摘要:本文描述了llvm中libcxx的list的实现。
关键字:list
其他:参考代码LLVM-libcxx
注意:参考代码时llvm的实现,与gnu和msvc的实现都有区别。
list是STL提供的双向链表,可以在头和尾部操作元素。

1 节点
和forward_list一样,list针对索引和节点进行了区分,索引只包含对应访问节点的指针,而节点同时包含链接的指针和数据成员。
template <class _Tp, class _VoidPtr>
struct __list_node_base
typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits;
typedef typename _NodeTraits::__link_pointer __link_pointer;
__link_pointer __prev_; //前向指针
__link_pointer __next_; //后向指针
;
template <class _Tp, class _VoidPtr>
struct _LIBCPP_STANDALONE_DEBUG __list_node : public __list_node_base<_Tp, _VoidPtr>
_Tp __value_;
;
2 迭代器
list的迭代器就是一个list_node的指针,其自增和自减的操作实现也比较简单就是访问node的前向和后向连接的指针。
template <class _Tp, class _VoidPtr>
class _LIBCPP_TEMPLATE_VIS __list_iterator
typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits;
typedef typename _NodeTraits::__link_pointer __link_pointer;
__link_pointer __ptr_;
__list_iterator& operator++()
_LIBCPP_DEBUG_ASSERT(__get_const_db()->__dereferenceable(this),
"Attempted to increment a non-incrementable list::iterator");
__ptr_ = __ptr_->__next_;
return *this;
__list_iterator& operator--()
_LIBCPP_DEBUG_ASSERT(__get_const_db()->__decrementable(this),
"Attempted to decrement a non-decrementable list::iterator");
__ptr_ = __ptr_->__prev_;
return *this;
;
3 list实现
list的内存布局由__list_impl描述,成员__end_作为索引节点描述当前链表的头尾。__end_的next和prev两个指针分别指向链表的头和尾节点,__size_alloc_则保存了当前链表的长度。
template <class _Tp, class _Alloc>
class __list_imp
__node_base __end_;
__compressed_pair<size_type, __node_allocator> __size_alloc_;
iterator begin() _NOEXCEPT
return iterator(__end_.__next_, this);
iterator end() _NOEXCEPT
return iterator(__end_as_link(), this);
;
而节点的操作就是比较典型的双链表的操作,没什么好说的。clear操作时通过for-loop来遍历每个节点并销毁对应的节点对象以及内存来实现的。
template <class _Tp, class _Alloc>
void __list_imp<_Tp, _Alloc>::clear() _NOEXCEPT
if (!empty())
__node_allocator& __na = __node_alloc();
__link_pointer __f = __end_.__next_;
__link_pointer __l = __end_as_link();
__unlink_nodes(__f, __l->__prev_);
__sz() = 0;
while (__f != __l)
__node_pointer __np = __f->__as_node();
__f = __f->__next_;
__node_alloc_traits::destroy(__na, _VSTD::addressof(__np->__value_));
__node_alloc_traits::deallocate(__na, __np, 1);
std::__debug_db_invalidate_all(this);
list就是在__list_impl的基础上封装了常见的链表操作。
template <class _Tp, class _Alloc /*= allocator<_Tp>*/>
class _LIBCPP_TEMPLATE_VIS list : private __list_imp<_Tp, _Alloc>;
我们就简单看下push_back和pop_back咋实现的(其实就是简单的链表节点的插入)。
push_back首先创建内存在对应的内存上构造输入的对象,然后将节点插入到尾部,节点插入也比较简单就是一般的双链表节点操作,不详述。
template <class _Tp, class _Alloc>
void list<_Tp, _Alloc>::push_back(const value_type& __x)
__node_allocator& __na = base::__node_alloc();
__hold_pointer __hold = __allocate_node(__na);
__node_alloc_traits::construct(__na, _VSTD::addressof(__hold->__value_), __x);
__link_nodes_at_back(__hold.get()->__as_link(), __hold.get()->__as_link());
++base::__sz();
__hold.release();
template <class _Tp, class _Alloc>
inline void list<_Tp, _Alloc>::__link_nodes_at_back(__link_pointer __f, __link_pointer __l)
__l->__next_ = base::__end_as_link();
__f->__prev_ = base::__end_.__prev_;
__f->__prev_->__next_ = __f;
base::__end_.__prev_ = __l;
pop_front的实现也比较简单直观,不详细描述。
template <class _Tp, class _Alloc>
void list<_Tp, _Alloc>::pop_front()
_LIBCPP_ASSERT(!empty(), "list::pop_front() called with empty list");
__node_allocator& __na = base::__node_alloc();
__link_pointer __n = base::__end_.__next_;
base::__unlink_nodes(__n, __n);
--base::__sz();
__node_pointer __np = __n->__as_node();
__node_alloc_traits::destroy(__na, _VSTD::addressof(__np->__value_));
__node_alloc_traits::deallocate(__na, __np, 1);
template <class _Tp, class _Alloc>
inline void __list_imp<_Tp, _Alloc>::__unlink_nodes(__link_pointer __f, __link_pointer __l)_NOEXCEPT
__f->__prev_->__next_ = __l->__next_;
__l->__next_->__prev_ = __f->__prev_;
以上是关于C++源码剖析——unordered_map和unordered_set的主要内容,如果未能解决你的问题,请参考以下文章