Redis 如何配置读写分离架构(主从复制)?
Posted GettingReal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 如何配置读写分离架构(主从复制)?相关的知识,希望对你有一定的参考价值。
文章目录
Redis 如何配置读写分离架构(主从复制)?
如果你的 redis 实际应用场景是
读多写少,那么读写分离的架构就比较适合,能够显著的提升读的性能
什么是 Redis 主从复制?
实际上就是 Redis 对数据除持久化之外的一种数据冗余备份机制。(能够在主节点出现故障时,通过其他手段让从节点快速提升为主节点提供服务以实现故障的恢复。)在读多写少的场景下,主从复制能够做到读写分离,提高 Redis 的负载均衡能力。
如何配置主从复制架构?
以下面这张图为例,简单进行 Redis 的主从配置。
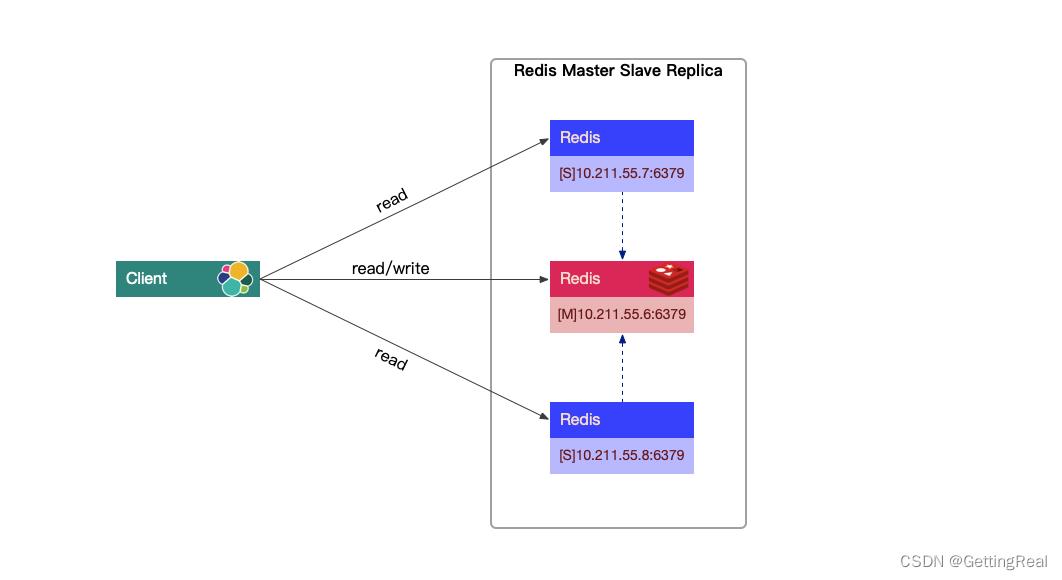
配置环境
以下配置,仅仅表示我的配置环境,读者可以根据自己的环境进行配置。
注意:需要把主机的防火墙关闭或者把 6379 端口对外放开
- 三台 Linux 主机(CentOS 7 版本),ip 分别为:10.211.55.6, 10.211.55.7, 10.211.55.8
- 在每台主机上安装 Redis(3.2.12 版本),可以使用 yum 进行安装
- 选择 10.211.55.6 主机的 Redis 作为主节点
- 选择 10.211.55.7 和 10.211.55.8 主机的 Redis 作为从节点
安装 Redis 步骤
这里只提供 yum 的安装方式
# 安装 Redis
yum install redis
# 配置外部访问
vim /etc/redis.conf
# 将 bind 127.0.0.1 修改为如下
bind 0.0.0.0
# 使用 systemctl 管理 Redis 服务
systemctl enable redis
# 启动 Redis
systemctl start redis
通过命令行配置从节点
分别在三台 CentOS 主机上面启动 Redis 服务,使用 redis-cli 进入 Redis 控制台,键入role命令,可以查看该 Redis 节点的角色情况,如下所示,第一行表示该节点的角色为 master,第二行表示数据复制的 offset,第三行表示从节点的集合。可以看到,目前三个 Redis 节点的角色都是 master。
127.0.0.1:6379> role
1) "master"
2) (integer) 0
3) (empty list or set)
执行如下命令,将两台 Redis 节点设置为 10.211.55.6 的从节点:
# 登陆 10.211.55.7 主机的 Redis 控制台
slaveof 10.211.55.6 6379
# 登陆 10.211.55.8 主机的 Redis 控制台
slaveof 10.211.55.6 6379
分别在三台主机的 Redis 控制台,执行role命令,查看各自的角色情况。从节点的状态信息如下:
127.0.0.1:6379> role
1) "slave"
2) "10.211.55.6"
3) (integer) 6379
4) "connected"
5) (integer) 1
主节点的状态信息如下:
127.0.0.1:6379> role
1) "master"
2) (integer) 29
3) 1) 1) "10.211.55.8"
2) "6379"
3) "29"
2) 1) "10.211.55.7"
2) "6379"
3) "29"
在主节点控制台进行 Redis 操作,测试从节点的数据变化,可以观察到从节点同步了主节点的数据。
# 主节点执行
set foo bar
# 从节点执行
get foo
通过配置文件配置从节点
命令行配置的从节点,在从节点 Redis 服务重启后,从节点配置会失效,使用配置文件,则能保证重启不失效。
# 编辑主机 10.211.55.7 和 10.211.55.8 的 /etc/redis.conf 配置文件添加如下配置
vim /etc/redis.conf
slaveof 10.211.55.6 6379
# 重启从节点 Redis 服务
systemctl restart redis
redis 主从复制优点
- 主从配置简单,能够做到数据冗余备份
- 负载均衡,能够做到读写分离,提高整个节点的吞吐能力
redis 主从复制缺点
- 不能自动的进行故障转移(在主节点失效时,从节点无法自动变换为主节点,需要通过其他的手段)
- 数据的同步需要一个时间窗口,可能会导致从节点数据的暂时不一致
- 在主节点发生故障时,数据还未来得及进行同步时,从节点的数据会与主节点的数据不一致
- 单个主节点还是会出现缓存数据量过大的问题
Redis主从复制(读写分离)
主从复制(读写分离):
读在从库读,写在主库写。
主从复制的好处:
避免redis单点故障
构建读写分离架构,满足读多写少的需求。
主从架构:
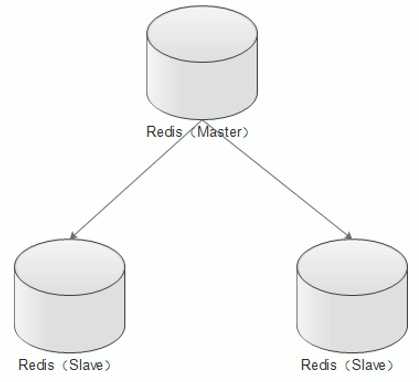
操作(启动实例,在一台机器上启动不同的实例,进行伪主从复制):
1.复制配置文件,修改配置文件,启动6379,6380,6381三个实例;

2.设置主从
在redis中设置主从有两种方式:
(1)在redis.conf中设置slaveof(永久)
(2)使用redis客户端连接到服务,执行salveod命令(临时)

3.查看主从信息,使用 INFO replication 命令。
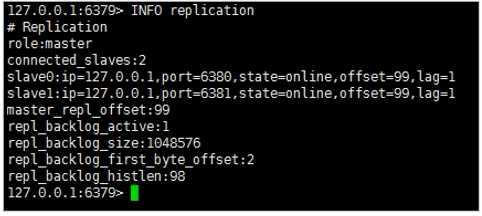
4.测试
在主库写数据:
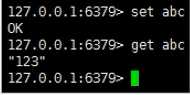
在从库读数据:
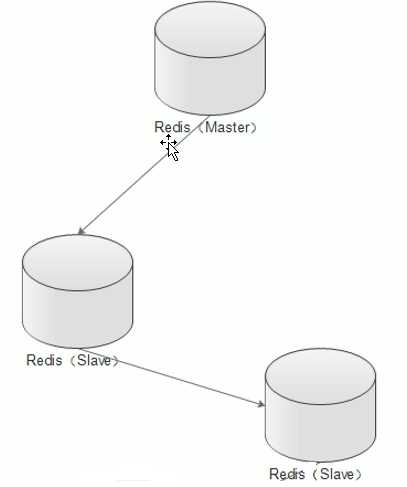
主从从架构:
操作与主从架构类似,不再写出。
从库只读:
默认情况下redis充当slave角色的只能读不能写。

可以在配置文件中开启非只读:slave-read-only no
主从复制的原理:
当从库与主库建立主从关系后,会像主库发送sync命令;
主库接收到sync命令后会在后台开始保存快照(rdb过程),并将期间接收到的写命令缓存起来;
当快照完成后,主redis会将快照文件和缓存的写命令一起发送给从redis;
从redis接收到后,会载入快照和执行收到的缓存的写命令;
之后,每当主redis接收到写命令后都会发送给从redis,从而保证数据的一致。
无磁盘复制:
如果主库所在的服务器的磁盘io能力较差的话,那么主从复制就会遇到瓶颈。的redis2.8.18版本后引入了无磁盘复制。
原理:
redis在与从库进行复制初始化的时候不再将快照保存在磁盘,而是通过网络直接发送给从库,从而避免了io性能差的问题。
开启无磁盘复制:repl-diskless-sync yes
主从架构出现宕机怎么办?
如果在主从复制架构中遇到宕机的话,一般要分情况:
1.从redis宕机
这种情况相对来说比较简单,只需将从redis重启,重启后从redis会自动加入到主从架构中,完成数据的同步。而且从redis2.8开始还实现了主从断线后恢复的情况下实现增量更新的功能。
2.主redis宕机
需要完成两步,第一步是在从redis中执行SLAVEOF NO ONE 命令,断开主从关系并且提升为主库继续提供服务;第二步是将主库重新启动,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就会更新回来。这个过程一般使用哨兵来监听。
以上是关于Redis 如何配置读写分离架构(主从复制)?的主要内容,如果未能解决你的问题,请参考以下文章