row_number 和 cte 使用实例:考场监考安排
Posted 文盲老顾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了row_number 和 cte 使用实例:考场监考安排相关的知识,希望对你有一定的参考价值。
row_number 和 cte 使用实例:考场监考安排
考场监考安排
问题出自问答区 python 频道的一个问答,原问答地址:https://ask.csdn.net/questions/7901104。
题主对提问的方式不太熟悉,他其实已经提了一系列关于监考安排这个问题的问答了,每次都略有遗漏,所以老顾把完整的需求从新描述一下。
有若干场不同科目的考试,每个科目的考试时长不同;有若干位不同科目的老师去监考,每个考试需要1名监考老师,监考老师不得监考同科目的考试。
请尽量安排老师所用的总监考时长为最平均的接近值。
题主这里给出了29位不同科目的老师,还有77场不同科目的考试。老顾用 python 通过编程的方式已经实现了这个需求,平均每位老师监考总时长在200至250之间。
但是,这个题目老顾觉得用数据库查询的方式也可以做,于是就拿来练练手。
使用 cte 模拟两个表的原始数据
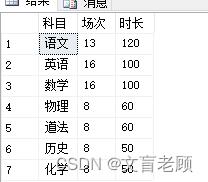
with 考试 as (
select '语文' 科目,13 场次,120 时长
union all select '英语',16,100
union all select '数学',16,100
union all select '物理',8,60
union all select '道法',8,60
union all select '历史',8,50
union all select '化学',8,50
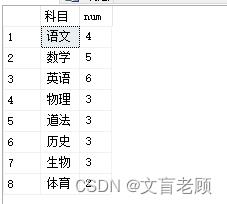
),老师 as (
select '语文' 科目,4 num
union all select '数学',5
union all select '英语',6
union all select '物理',3
union all select '道法',3
union all select '历史',3
union all select '生物',3
union all select '体育',2
)
select * from 考试
使用 master…spt_values 进行数据填充
因为题主给的数据就是这样的,所以,咱也不知道具体每个老师叫啥,每个科目啥时候举行,有没有时间冲突,咱就当他没有好了。但是,这样的汇总数据是无法进行计算的,我们需要把所有的汇总数据展开成单项。这里使用了mssql系统库中自带的一个数据表:master…spt_values,使用这个表可以很方便的扩展成单项,进行数据补全。相信看过我以前 sql 文章的小伙伴对这个已经很熟悉了。
with ... -- 前边的 with 不再重复
,teacher as (
select 科目,number
from 老师
cross apply (
select number from master..spt_values
where type='p' and number between 1 and num
) b
)
select * from teacher
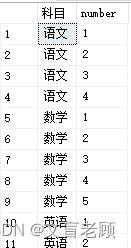
很容易就得到了单个老师的排列及科目了。
在这里,不得不说,cross/outer apply 很好用,可以直接引用前边查询表中的列,而 mysql 则未提供这种方式,写个关联查询为了引用前边的列,也很费劲。
优先安排时长较长的考试
这个是一个朴素的想法,先把废时间的安排出去,然后,谁的总时长少,谁就多安排一点,这样的话,平均时长就差不多了,所以我们对考试场次按时长做个倒序分配序号,来确定分配优先级,并作为 cte 递归的依据。
with ...
,exam as (
select *,row_number() over(order by 时长 desc) sn
from 考试
)
select * from exam
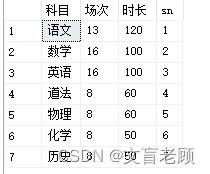
使用 cte 安排第一个需要安排的科目
第一个需要岸炮的科目自然是语文了,根据 sn 得出的结论嘛。
我们需要安排13个非语文科目的老师进行语文考试的监考,为了每次安排不那么一样,还要用 newid() 函数协助一下随机排序,那么大概得指令就是这样了。
with ...
,sc as (
select b.*,a.科目 as 监考,时长,a.sn
from exam a
cross apply (
select *,row_number() over(order by newid()) nid
from teacher
where 科目<>a.科目
) b
where sn = 1 and nid<=场次
)
select * from sc
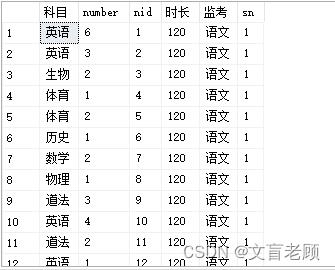
第一个科目很容易就安排出去了,现在准备攻坚了,递归之后的科目。
统计老师已有的监考时长
在递归之前,我们先考虑一下,对之后的安排我们需要做两件事:
1、对所有老师的已安排监考的时长进行统计,选择时长最短的老师进行下一场监考安排
2、递归数据需要排重,不能粗暴的直接用 sn = a.sn + 1 这样的方式了,因为我们已经有了13场 sn 等于1的安排了
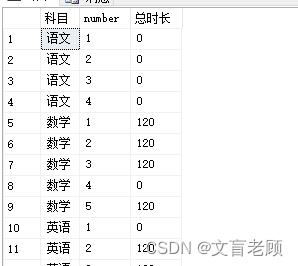
先按老师的时长统计进行一下计算,我们修改下 select * from sc 的内容,看看这29位老师每个人的第一场考试后的时长。
select a.*,isnull(总时长,0) 总时长
from teacher a
left join (
select 科目,number,sum(时长) 总时长
from sc
group by 科目,number
) b on a.科目=b.科目 and a.number=b.number
尝试使用 cte 递归,进行下一场考试安排(尝试了三个方向才成功)

由于在 cte 递归中,无法使用 top 或 offset 之类的运算,所以可以看到,我们刚才实现第一场的内容时,都是用的 row_number 做的变动,这里,我们同样使用 row_number 变通一下

变动过程中是各种报错啊。。。。嘿嘿
第一个尝试,使用考试科目递归,失败
,sc as (
select convert(nvarchar(max),b.科目) 科目,number,时长,a.科目 as 监考,a.sn
from exam a
cross apply (
select *,row_number() over(order by newid()) nid
from teacher
where 科目<>a.科目
) b
where sn = 1 and nid<=场次
union all
select convert(nvarchar(max),'下一场'),0,场次,e.科目,e.sn
from (
select *,row_number() over(order by sn desc) rid from sc
) a
inner join exam e on a.sn+1=e.sn
where rid=1
)
select * from sc
order by sn
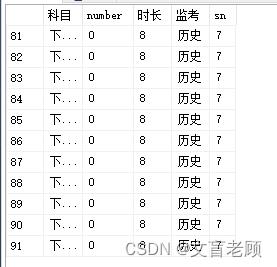
不出预料的,每个下一场都是13场,和语文一样的场次,老顾是没办法解决这个问题了,只好换个思路。
第二个尝试,使用老师数据及考试批次递归,失败
with ...
,sc as (
select 科目,number
,(case when nid<=场次 then 用时+时长 else 用时 end) 用时
,(case when nid<=场次 then 监考 else null end) 监考,批次,场次
,nid
from (
select t.*,时长,e.科目 监考,1 批次,场次
,row_number() over(order by 场次 desc,newid()) nid
from teacher t
left join exam e on t.科目<>e.科目 and e.sn=1
) a
union all
select 科目,number
,(case when nid<=场次 then 用时+时长 else 用时 end) 用时
,(case when nid<=场次 then 监考 else null end) 监考,批次,场次
,row_number() over(order by @@rowcount)
from (
select s.科目,number,用时,e.科目 监考,批次 + 1 批次,e.场次,时长
,row_number() over(order by (case when s.科目=e.科目 then 1 else 0 end),用时,newid()) nid
from sc s,exam e
where s.批次+1 = e.sn
) a
)
select * from sc
order by 批次,nid
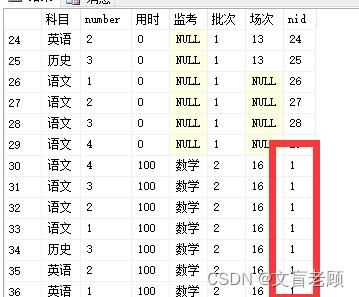
结果发现。。。。cte 递归,原来是一行数据一行数据的递归下来的,不是整个表一起递归的,难怪不让用 join 之类的指令。由于是一行一行递归的,所以这里的 row_number 得不到1之外的序号了,如果再次引入 teacher 表,则无法继承考试用时了,只好再换个思路。
第三次尝试,用 for xml 继承数据
,sc as (
select *
from exam a
cross apply (
select convert(nvarchar(max),stuff((select ';' + 科目 + ':' + convert(varchar,number) + ':' + convert(varchar,(case when nid<=场次 then 时长 else 0 end))
from (
select t.*,时长,e.科目 监考,1 批次,场次
,row_number() over(order by 场次 desc,newid()) nid
from teacher t
left join exam e on t.科目<>e.科目 and e.sn=a.sn
) a
--where nid <= 场次
for xml path('')),1,1,'')) z
) b
where a.sn=1
union all
select b.*,convert(nvarchar(max),'')
from sc a,exam b
where a.sn + 1 = b.sn
)
select * from sc
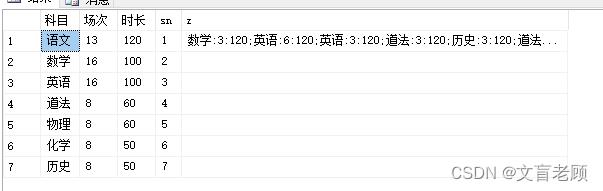
可以看到,我们可以把所有老师的用时都放到组合数据了,然后用切割字符串方式再回复成表数据进行计算,这样就可以继续尝试了。
这里老顾就直接用正则了,毕竟切割的话还是比较麻烦的,需要好几次列转行,我用正则可以省略一次。。。。如果有小伙伴想在 mssql 里使用正则,可以看老顾以前的文章,或者直接下载老顾准备好的 clr 指令《mssql正则clr及函数,追加Group分组支持》,然后直接运行里边的指令就可以使用老顾下边的正则指令了。

竟然还有这么多不让用的,pivot 也不能用就有点麻烦了,好在老顾的正则不错,可以单独提取数据,不用 pivot 也可以。
with ...
,sc as (
select *
from exam a
cross apply (
select convert(nvarchar(max),stuff((select ';' + 科目 + ':' + convert(varchar,number) + ':' + convert(varchar,时长)
from (
select t.*,时长,e.科目 监考,1 批次,场次
,row_number() over(order by 场次 desc,newid()) nid
from teacher t
left join exam e on t.科目<>e.科目 and e.sn=a.sn
) a
where nid <= 场次
for xml path('')),1,1,'')) curr
) b
cross apply (
select convert(nvarchar(max),stuff((select ';' + 科目 + ':' + convert(varchar,number) + ':' + convert(varchar,(case when nid<= 场次 then 时长 else 0 end))
from (
select t.*,时长,e.科目 监考,1 批次,场次
,row_number() over(order by 场次 desc,newid()) nid
from teacher t
left join exam e on t.科目<>e.科目 and e.sn=a.sn
) a
for xml path('')),1,1,'')) sc
) c
where a.sn=1
union all
select 科目,场次,时长,sn,c,z
from (
select b.*,a.sc
from sc a,exam b
where a.sn + 1 = b.sn
) a
cross apply (
select stuff((
select ';' + tn + ':' + tsn + ':' + convert(varchar,(case when nid<=场次 then 用时+时长 else 用时 end))
from (
select *,row_number() over(order by 用时,newid()) nid
from (
select master.dbo.RegexMatch(match,'[^:]+') tn
,master.dbo.RegexMatch(match,'(?<=:)\\d+(?=:)') tsn
,convert(int,master.dbo.RegexMatch(match,'(?<=:)\\d+(?=$)')) 用时
from master.dbo.RegexMatches(sc,'([^;:]+):(\\d+):(\\d+)')
) a
) a
for xml path('')
),1,1,'') z
) b
cross apply (
select stuff((
select ';' + tn + ':' + tsn + ':' + convert(varchar,用时)
from (
select *,row_number() over(order by 用时,newid()) nid
from (
select master.dbo.RegexMatch(match,'[^:]+') tn
,master.dbo.RegexMatch(match,'(?<=:)\\d+(?=:)') tsn
,convert(int,master.dbo.RegexMatch(match,'(?<=:)\\d+(?=$)')) 用时
from master.dbo.RegexMatches(sc,'([^;:]+):(\\d+):(\\d+)')
) a
) a
where nid<=场次
for xml path('')
),1,1,'') c
) c
)
select * from sc

嗯,最后一行 sc 是所有老师的用时情况,每一行的 curr 是该科目考试所安排的老师,我们先看看总用时情况:
历史:1:230;生物:3:230;数学:4:250;道法:3:250;语文:3:250;数学:2:250;生物:1:250;数学:1:250;体育:1:200;道法:2:200;语文:1:200;物理:3:200;英语:2:200;历史:2:200;语文:4:200;语文:2:200;英语:3:200;物理:1:200;英语:4:230;英语:5:230;英语:1:230;体育:2:230;历史:3:230;数学:5:230;物理:2:230;数学:3:230;英语:6:240;道法:1:240;生物:2:240
一共 29 个老师,每个老师200到250的用时,结果验证正确,真不容易,为了绕过限制,这次的指令写的很复杂,如果有小伙伴想了解详细内容,可以在评论区扣我。
最后用字符串切割和列转行,排出监考排班表
with 考试 as (
select '语文' 科目,13 场次,120 时长
union all select '英语',16,100
union all select '数学',16,100
union all select '物理',8,60
union all select '道法',8,60
union all select '历史',8,50
union all select '化学',8,50
),老师 as (
select '语文' 科目,4 num
union all select '数学',5
union all select '英语',6
union all select '物理',3
union all select '道法',3
union all select '历史',3
union all select '生物',3
union all select '体育',2
),teacher as (
select 科目,number
from 老师
cross apply (
select number from master..spt_values
where type='p' and number between 1 and num
) b
),exam as (
select *,row_number() over(order by 时长 desc) sn
from 考试
),sc as (
select *
from exam a
cross apply (
select convert(nvarchar(max),stuff((select ';' + 科目 + ':' + convert(varchar,number) + ':' + convert(varchar,时长)
from (
select t.*,时长,e.科目 监考,1 批次,场次
,row_number() over(order by 场次 desc,t.科目,number) nid
from teacher t
left join exam e on t.科目<>e.科目 and e.sn=a.sn
) a
where nid <= 场次
for xml path('')),1,1,'')) curr
) b
cross apply (
select convert(nvarchar(max),stuff((select ';' + 科目 + ':' + convert(varchar,number) + ':' + convert(varchar,(case when nid<= 场次 then 时长 else 0 end))
from (
select t.*,时长,e.科目 监考,CTE、ROW_NUMBER 和 ROWCOUNT
【中文标题】CTE、ROW_NUMBER 和 ROWCOUNT【英文标题】:CTE, ROW_NUMBER and ROWCOUNT
【发布时间】:2011-11-18 04:49:01
【问题描述】:
我正在尝试在一个存储过程中返回一页数据以及所有数据的行数,如下所示:
WITH Props AS
(
SELECT *,
ROW_NUMBER() OVER (ORDER BY PropertyID) AS RowNumber
FROM Property
WHERE PropertyType = @PropertyType AND ...
)
SELECT * FROM Props
WHERE RowNumber BETWEEN ((@PageNumber - 1) * @PageSize) + 1 AND (@PageNumber * @PageSize);
我无法返回行数(最高行数)。
我知道这已经被讨论过(我见过这个:
Efficient way of getting @@rowcount from a query using row_number) 但是当我在 CTE 中添加 COUNT(x) OVER(PARTITION BY 1) 时,性能会下降,并且上面的查询通常不需要时间来执行。我认为这是因为计数是针对每一行计算的?我似乎无法在另一个查询中重用 CTE。 Table Props 有 100k 条记录,CTE 返回 5k 条记录。
【问题讨论】:
应该重新标记为 SQL Server 问题。我会为你做的,但你只能使用 5 个标签,而且我不知道你要删除哪个标签。
【参考方案1】:
我遇到了同样的问题,想分享返回页面和总行数的代码。 临时表解决了这个问题。这是存储过程的主体:
DECLARE @personsPageTable TABLE(
RowNumber INT,
PersonId INT,
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
BirthDate DATE,
TotalCount INT);
;WITH PersonPage AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY persons.Id) RowNumber,
Id,
FirstName,
LastName,
BirthDate
FROM Persons
WHERE BirthDate >= @BirthDateFrom AND BirthDate <= @BirthDateTo
), TotalCount AS( SELECT COUNT(*) AS [Count] FROM PersonPage)
INSERT INTO @personsPageTable
SELECT *, (select * from TotalCount) TotalCount FROM PersonPage
ORDER BY PersonPage.RowNumber ASC
OFFSET ((@pageNumber - 1) * @pageSize) ROWS
FETCH NEXT @pageSize ROWS ONLY
SELECT TOP 1 TotalCount FROM @personsPageTable
SELECT
PersonId,
FirstName,
LastName,
BirthDate
FROM @personsPageTable
如您所见,我将 CTE 结果和总行数 放入临时表并选择两个查询。第一次返回总计数,第二次返回带数据的页面。
【讨论】:
【参考方案2】:
在 T-SQL 中应该是
;WITH Props AS
(
SELECT *,
ROW_NUMBER() OVER (ORDER BY PropertyID) AS RowNumber
FROM Property
WHERE PropertyType = @PropertyType AND ...
)
, Props2 AS
(
SELECT COUNT(*) CNT FROM Props
)
-- Now you can use even Props2.CNT
SELECT * FROM Props, Props2
WHERE RowNumber BETWEEN ((@PageNumber - 1) * @PageSize) + 1 AND (@PageNumber * @PageSize);
现在你在每一行都有 CNT……或者你想要一些不同的东西?您想要第二个只有计数的结果集?那就去做吧!
-- This could be the second result-set of your query.
SELECT COUNT(*) CNT
FROM Property
WHERE PropertyType = @PropertyType AND ...
注意:已重新编辑,David 现在引用的查询 1 已被回收,查询 2 现在是查询 1。
【讨论】:
1.不起作用,因为您必须在其中包含一个 group by 子句。 2. 效果很好,我最喜欢它。谢谢。
在我的版本中,我在第一个 cte 中添加了 COUNT(1),导致工作台上的 800000 次读取。使用第二个 cte(就像您在此处所做的那样)跳过了所有这些读取,从而产生了极快的查询。【参考方案3】:
您想要整个结果集的计数吗?
这能快速工作吗?
SELECT *,(select MAX(RowNumber) from Props) as MaxRow
FROM Props
WHERE RowNumber BETWEEN ((@PageNumber - 1) * @PageSize) + 1
AND (@PageNumber * @PageSize);
【讨论】:
以上是关于row_number 和 cte 使用实例:考场监考安排的主要内容,如果未能解决你的问题,请参考以下文章