面部表情识别3:Android实现表情识别(含源码,可实时检测)
Posted AI吃大瓜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面部表情识别3:Android实现表情识别(含源码,可实时检测)相关的知识,希望对你有一定的参考价值。
面部表情识别3:android实现表情识别(含源码,可实时检测)
目录
面部表情识别3:Android实现表情识别(含源码,可实时检测)
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
这是项目《面部表情识别》系列之《Android实现表情识别(含源码,可实时检测)》,主要分享将Python训练后的面部表情识别模型移植到Android平台。我们将开发一个简易的、可实时运行的面部表情识别的Android Demo。准确率还挺高的,采用轻量级mobilenet_v2模型的面部表情识别准确率也可以高达94.72%左右,基本满足业务性能需求。

项目将手把手教你将训练好的表情识别模型部署到Android平台中,包括如何转为ONNX,TNN模型,并移植到Android上进行部署,实现一个表情识别的Android Demo APP 。APP在普通Android手机上可以达到实时的检测识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/129467015
先展示一下Android版本表情识别Demo效果:

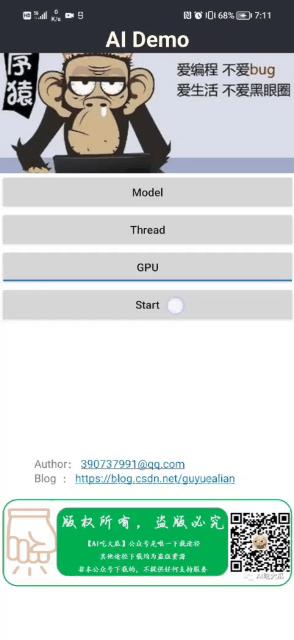
Android面部表情识别APP Demo体验:https://download.csdn.net/download/guyuealian/87575425
或者链接: https://pan.baidu.com/s/16OOi-qCENP4WbIeSzO5e9g 提取码: cs5g
更多项目《面部表情识别》系列文章请参考:
- 面部表情识别1:表情识别数据集(含下载链接):
- 面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
- 面部表情识别3:Android实现表情识别(含源码,可实时检测)
- 面部表情识别4:C++实现表情识别(含源码,可实时检测)

1.面部表情识别方法
面部表情识别方法有多种实现方案,这里采用最常规的方法:基于人脸检测+面部表情分类识别方法,即先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个面部表情分类器,完成对面部表情识别;
这样做的好处,是可以利用现有的人脸检测模型,而无需重新训练人脸检测模型,可减少人工标注成本低;而人脸数据相对而言比较容易采集,分类模型可针对性进行优化。
2.人脸检测方法
本项目人脸检测训练代码请参考:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这是一个基于SSD改进且轻量化后人脸检测模型,很slim,整个模型仅仅1.7M左右,在普通Android手机都可以实时检测。人脸检测方法在网上有一大堆现成的方法可以使用,完全可以不局限我这个方法。

关于人脸检测的方法,可以参考我的另一篇博客:
行人检测和人脸检测和人脸关键点检测(C++/Android源码)
3.面部表情识别模型训练
关于面部表情识别模型的训练方法,请参考本人另一篇博文《面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/129505205
4.面部表情识别模型Android部署
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署。部署流程可分为四步:训练模型->将模型转换ONNX模型->将ONNX模型转换为TNN模型->Android端上部署TNN模型。
(1) 将Pytorch模型转换ONNX模型
训练好Pytorch模型后,我们需要先将模型转换为ONNX模型,以便后续模型部署。
- 原始项目提供转换脚本,你只需要修改model_file为你模型路径即可
- convert_torch_to_onnx.py实现将Pytorch模型转换ONNX模型的脚本
python libs/convert/convert_torch_to_onnx.py"""
This code is used to convert the pytorch model into an onnx format model.
"""
import sys
import os
sys.path.insert(0, os.getcwd())
import torch.onnx
import onnx
from classifier.models.build_models import get_models
from basetrainer.utils import torch_tools
def build_net(model_file, net_type, input_size, num_classes, width_mult=1.0):
"""
:param model_file: 模型文件
:param net_type: 模型名称
:param input_size: 模型输入大小
:param num_classes: 类别数
:param width_mult:
:return:
"""
model = get_models(net_type, input_size, num_classes, width_mult=width_mult, is_train=False, pretrained=False)
state_dict = torch_tools.load_state_dict(model_file)
model.load_state_dict(state_dict)
return model
def convert2onnx(model_file, net_type, input_size, num_classes, width_mult=1.0, device="cpu", onnx_type="default"):
model = build_net(model_file, net_type, input_size, num_classes, width_mult=width_mult)
model = model.to(device)
model.eval()
model_name = os.path.basename(model_file)[:-len(".pth")] + ".onnx"
onnx_path = os.path.join(os.path.dirname(model_file), model_name)
# dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
dummy_input = torch.randn(1, 3, input_size[1], input_size[0]).to(device)
# torch.onnx.export(model, dummy_input, onnx_path, verbose=False,
# input_names=['input'],output_names=['scores', 'boxes'])
do_constant_folding = True
if onnx_type == "default":
torch.onnx.export(model, dummy_input, onnx_path, verbose=False, export_params=True,
do_constant_folding=do_constant_folding,
input_names=['input'],
output_names=['output'])
elif onnx_type == "det":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['scores', 'boxes', 'ldmks'])
elif onnx_type == "kp":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['output'])
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(onnx_path)
if __name__ == "__main__":
net_type = "mobilenet_v2"
width_mult = 1.0
input_size = [128, 128]
num_classes = 2
model_file = "work_space/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_022_98.1848.pth"
convert2onnx(model_file, net_type, input_size, num_classes, width_mult=width_mult)
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署
TNN转换工具:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)
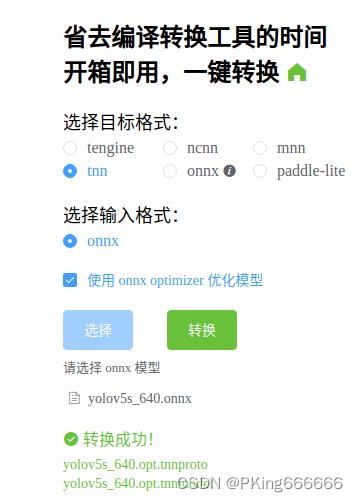
(3) Android端上部署模型
项目实现了Android版本的面部表情识别Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。项目Android源码,核心算法均采用C++实现,上层通过JNI接口调用.
如果你想在这个Android Demo部署你自己训练的分类模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。
- 这是项目Android源码JNI接口 ,Java部分
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector
static
System.loadLibrary("tnn_wrapper");
/***
* 初始化检测模型
* @param det_model: 检测模型(不含后缀名)
* @param cls_model: 识别模型(不含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:是否开启GPU进行加速
*/
public static native void init(String det_model, String cls_model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 返回检测和识别结果
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh);
- 这是Android项目源码JNI接口 ,C++部分
#include <jni.h>
#include <string>
#include <fstream>
#include "src/object_detection.h"
#include "src/classification.h"
#include "src/Types.h"
#include "debug.h"
#include "android_utils.h"
#include "opencv2/opencv.hpp"
#include "file_utils.h"
using namespace dl;
using namespace vision;
static ObjectDetection *detector = nullptr;
static Classification *classifier = nullptr;
JNIEXPORT jint JNI_OnLoad(JavaVM *vm, void *reserved)
return JNI_VERSION_1_6;
JNIEXPORT void JNI_OnUnload(JavaVM *vm, void *reserved)
extern "C"
JNIEXPORT void JNICALL
Java_com_cv_tnn_model_Detector_init(JNIEnv *env,
jclass clazz,
jstring det_model,
jstring cls_model,
jstring root,
jint model_type,
jint num_thread,
jboolean use_gpu)
if (detector != nullptr)
delete detector;
detector = nullptr;
std::string parent = env->GetStringUTFChars(root, 0);
std::string det_model_ = env->GetStringUTFChars(det_model, 0);
std::string cls_model_ = env->GetStringUTFChars(cls_model, 0);
string det_model_file = path_joint(parent, det_model_ + ".tnnmodel");
string det_proto_file = path_joint(parent, det_model_ + ".tnnproto");
string cls_model_file = path_joint(parent, cls_model_ + ".tnnmodel");
string cls_proto_file = path_joint(parent, cls_model_ + ".tnnproto");
DeviceType device = use_gpu ? GPU : CPU;
LOGW("parent : %s", parent.c_str());
LOGW("useGPU : %d", use_gpu);
LOGW("device_type: %d", device);
LOGW("model_type : %d", model_type);
LOGW("num_thread : %d", num_thread);
ObjectDetectionParam model_param = FACE_MODEL;
detector = new ObjectDetection(det_model_file,
det_proto_file,
model_param,
num_thread,
device);
//ClassificationParam ClassParam = FACE_MASK_MODEL;
ClassificationParam ClassParam = EYEGLASSES_MODEL;
classifier = new Classification(cls_model_file,
cls_proto_file,
ClassParam,
num_thread,
device);
extern "C"
JNIEXPORT jobjectArray JNICALL
Java_com_cv_tnn_model_Detector_detect(JNIEnv *env, jclass clazz, jobject bitmap,
jfloat score_thresh, jfloat iou_thresh)
cv::Mat bgr;
BitmapToMatrix(env, bitmap, bgr);
int src_h = bgr.rows;
int src_w = bgr.cols;
// 检测区域为整张图片的大小
FrameInfo resultInfo;
// 开始检测
if (detector != nullptr)
detector->detect(bgr, &resultInfo, score_thresh, iou_thresh);
else
ObjectInfo objectInfo;
objectInfo.x1 = 0;
objectInfo.y1 = 0;
objectInfo.x2 = (float)src_w;
objectInfo.y2 = (float)src_h;
objectInfo.label = 0;
resultInfo.info.push_back(objectInfo);
int nums = resultInfo.info.size();
LOGW("object nums: %d\\n", nums);
if (nums > 0)
// 开始检测
classifier->detect(bgr, &resultInfo);
// 可视化代码
printf("sitting label:%d,score:%3.5f", resultInfo.label, resultInfo.score);
//classifier->visualizeResult(bgr, &resultInfo);
//cv::cvtColor(bgr, bgr, cv::COLOR_BGR2RGB);
//MatrixToBitmap(env, bgr, dst_bitmap);
auto BoxInfo = env->FindClass("com/cv/tnn/model/FrameInfo");
auto init_id = env->GetMethodID(BoxInfo, "<init>", "()V");
auto box_id = env->GetMethodID(BoxInfo, "addBox", "(FFFFIF)V");
auto ky_id = env->GetMethodID(BoxInfo, "addKeyPoint", "(FFF)V");
jobjectArray ret = env->NewObjectArray(resultInfo.info.size(), BoxInfo, nullptr);
for (int i = 0; i < nums; ++i)
auto info = resultInfo.info[i];
env->PushLocalFrame(1);
//jobject obj = env->AllocObject(BoxInfo);
jobject obj = env->NewObject(BoxInfo, init_id);
// set bbox
//LOGW("rect:[%f,%f,%f,%f] label:%d,score:%f \\n", info.rect.x,info.rect.y, info.rect.w, info.rect.h, 0, 1.0f);
env->CallVoidMethod(obj, box_id, info.x1, info.y1, info.x2 - info.x1, info.y2 - info.y1,
info.category.label, info.category.score);
// set keypoint
for (const auto &kps : info.landmarks)
//LOGW("point:[%f,%f] score:%f \\n", lm.point.x, lm.point.y, lm.score);
env->CallVoidMethod(obj, ky_id, (float) kps.x, (float) kps.y, 1.0f);
obj = env->PopLocalFrame(obj);
env->SetObjectArrayElement(ret, i, obj);
return ret;
(4) Android测试效果
Android Demo在普通手机CPU/GPU上可以达到实时检测和识别效果;CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:
解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
Android SDK和NDK相关版本信息,请参考:
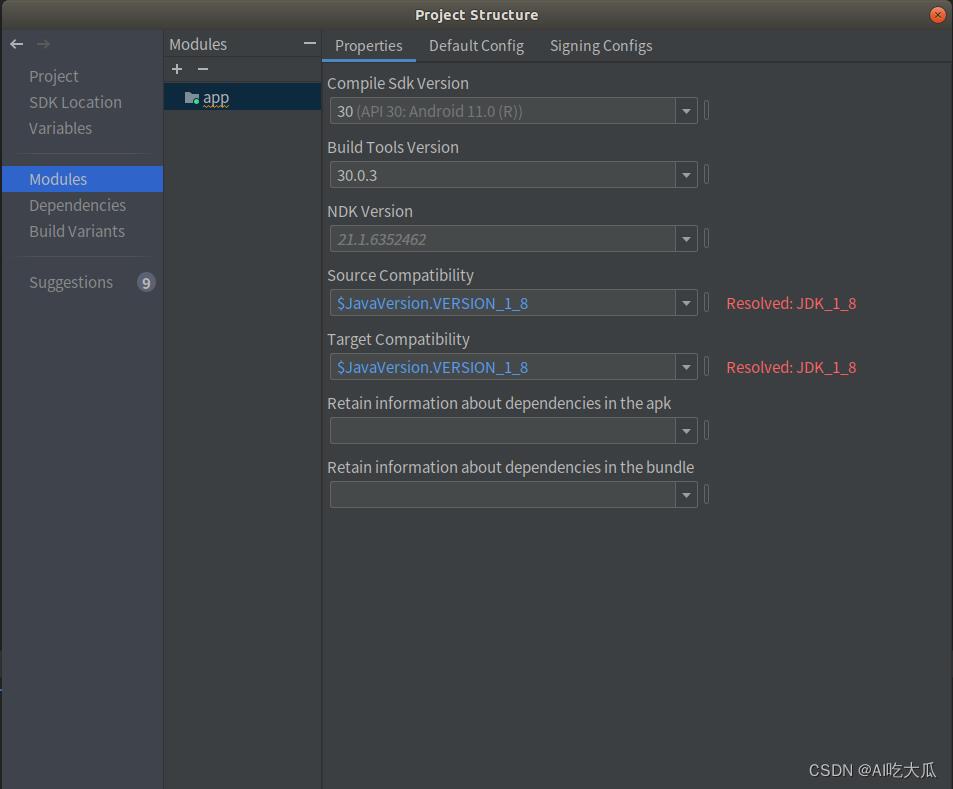
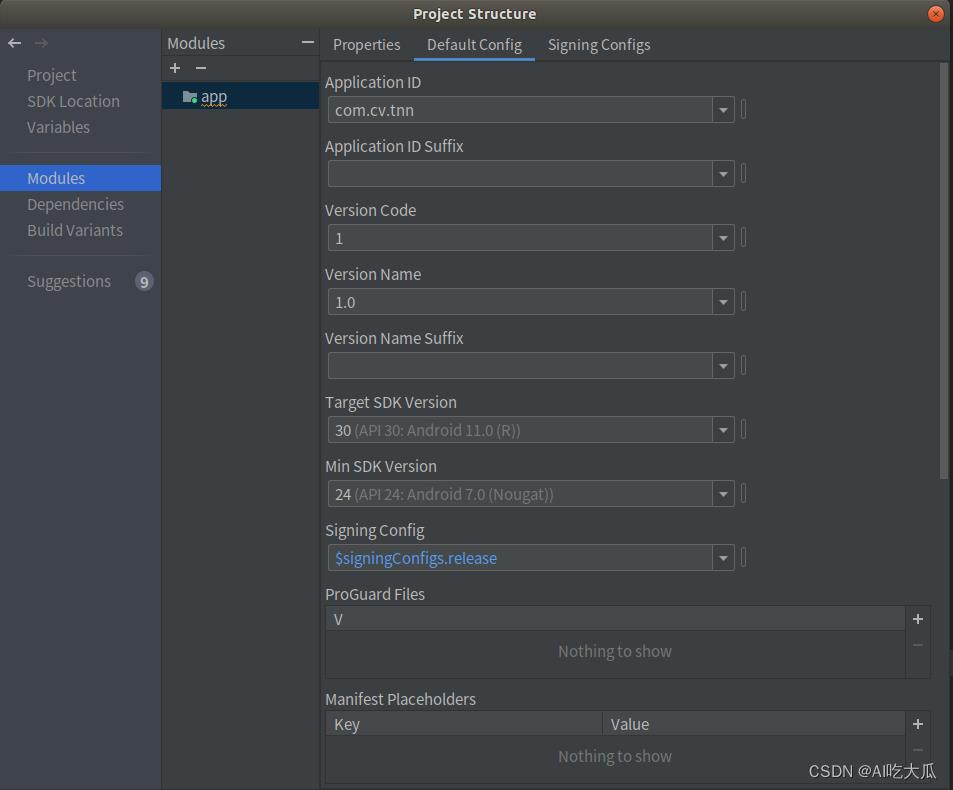
5.项目源码下载
Android项目源码下载地址:面部表情识别3:Android实现表情识别(含源码,可实时检测)
整套Android项目源码内容包含:
- 提供Android版本的人脸检测模型
- 提供面部表情识别Android Demo源码
- Android Demo在普通手机CPU/GPU上可以实时检测和识别,约30ms左右
- Android Demo支持图片,视频,摄像头测试
- 所有依赖库都已经配置好,可直接build运行,若运行出现闪退,请参考dlopen failed: library “libomp.so“ not found 解决。
Android面部表情识别APP Demo体验:https://download.csdn.net/download/guyuealian/87575425
或者链接: https://pan.baidu.com/s/16OOi-qCENP4WbIeSzO5e9g 提取码: cs5g
如果你需要面部表情识别的训练代码,请参考:《面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)》https://blog.csdn.net/guyuealian/article/details/129505205

面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
目录
面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
这是项目《面部表情识别》系列之《Pytorch实现表情识别(含表情识别数据集和训练代码)》;项目基于深度学习框架Pytorch开发一个高精度,可实时的面部表情识别算法( Facial Expression Recognition);项目源码支持模型有resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型,用户可自定义进行训练;准确率还挺高的,采用轻量级mobilenet_v2模型的面部表情识别准确率也可以高达94.72%左右,满足业务性能需求。
| 模型 | input size | Test准确率 |
| mobilenet_v2 | 112×112 | 94.72% |
| googlenet | 112×112 | 94.28% |
| resnet18 | 112×112 | 94.818% |
先展示一下,Python版本的面部表情识别Demo效果(不同表情用不同的颜色框标注了)


【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/129505205
更多项目《面部表情识别》系列文章请参考:
- 面部表情识别1:表情识别数据集(含下载链接)
- 面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
- 面部表情识别3:Android实现表情识别(含源码,可实时检测)
- 面部表情识别4:C++实现表情识别(含源码,可实时检测)
1.面部表情识别方法
面部表情识别方法有多种实现方案,这里采用最常规的方法:基于人脸检测+面部表情分类识别方法,即先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个面部表情分类器,完成对面部表情识别;
这样做的好处,是可以利用现有的人脸检测模型,而无需重新训练人脸检测模型,可减少人工标注成本低;而人脸数据相对而言比较容易采集,分类模型可针对性进行优化。
2.面部表情识别数据集
(1)表情识别数据集说明
本项目主要使用两个表情识别数据集:Emotion-Domestic国内(亚洲)表情识别数据集+MMAFEDB表情识别数据集,总共超过15万张人脸图片,数据面部表情丰富多样,包含angry(生气), disgust (厌恶), fear(害怕), happy(快乐), neutral (中性), sad(悲伤), surprise(惊奇)等多种表情。
关于表情识别数据的使用说明请参考我的一篇博客:面部表情识别1:表情识别数据集(含下载链接)

(2)自定义数据集
如果需要新增类别数据,或者需要自定数据集进行训练,可参考如下进行处理:
- 建立Train和Test数据集,要求相同类别的图片,放在同一个文件夹下;且子目录文件夹命名为类别名称,如

- 类别文件:一行一个列表:class_name.txt
(最后一行,请多回车一行)
A
B
C
D
- 修改配置文件的数据路径:config.yaml
train_data: # 可添加多个数据集
- 'data/dataset/train1'
- 'data/dataset/train2'
test_data: 'data/dataset/test'
class_name: 'data/dataset/class_name.txt'
...
...3.人脸检测模型
本项目人脸检测训练代码请参考:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这是一个基于SSD改进且轻量化后人脸检测模型,很slim,整个模型仅仅1.7M左右,在普通Android手机都可以实时检测。人脸检测方法在网上有一大堆现成的方法可以使用,完全可以不局限我这个方法。

4.面部表情识别分类模型训练
准备好表情识别数据后,接下来就可以开始训练表情识别分类模型了;项目模型支持resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型,考虑到后续我们需要将表情识别模型部署到Android平台中,因此项目选择计算量比较小的轻量化模型mobilenet_v2;如果不用端上部署,完全可以使用参数量更大的模型,如resnet50等模型。
整套工程项目基本结构如下:
.
├── classifier # 训练模型相关工具
├── configs # 训练配置文件
├── data # 训练数据
├── libs
│ ├── convert # 将模型转换为ONNX工具
│ ├── light_detector # 人脸检测
│ ├── detector.py # 人脸检测demo
│ └── README.md
├── demo.py # demo
├── README.md # 项目工程说明文档
├── requirements.txt # 项目相关依赖包
└── train.py # 训练文件(1)项目安装
项目依赖python包请参考requirements.txt,使用pip安装即可:
numpy==1.16.3
matplotlib==3.1.0
Pillow==6.0.0
easydict==1.9
opencv-contrib-python==4.5.2.52
opencv-python==4.5.1.48
pandas==1.1.5
PyYAML==5.3.1
scikit-image==0.17.2
scikit-learn==0.24.0
scipy==1.5.4
seaborn==0.11.2
tensorboard==2.5.0
tensorboardX==2.1
torch==1.7.1+cu110
torchvision==0.8.2+cu110
tqdm==4.55.1
xmltodict==0.12.0
basetrainer
pybaseutils==0.6.5项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
(2)准备数据
下载表情识别数据集:Emotion-Domestic国内(亚洲)表情识别数据集+MMAFEDB表情识别数据集,关于表情识别数据的使用说明请参考我的一篇博客:面部表情识别1:表情识别数据集(含下载链接)
(3)面部表情识别分类模型训练(Pytorch)
项目在《Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)》基础上实现了面部表情识别分类模型训练和测试,整套训练代码非常简单操作,用户只需要将相同类别的图片数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
训练框架采用Pytorch,整套训练代码支持的内容主要有:
- 目前支持的backbone有:googlenet,resnet[18,34,50], ,mobilenet_v2等, 其他backbone可以自定义添加
- 训练参数可以通过(configs/config.yaml)配置文件进行设置
训练参数说明如下:
# 训练数据集,可支持多个数据集(不要出现中文路径)
train_data:
- 'path/to/emotion/emotion-domestic/train'
- 'path/to/emotion/MMAFEDB/train'
# 测试数据集(不要出现中文路径)
test_data:
- 'path/to/motion/emotion-domestic/test'
# 类别文件
class_name: 'data/class_name.txt'
train_transform: "train" # 训练使用的数据增强方法
test_transform: "val" # 测试使用的数据增强方法
work_dir: "work_space/" # 保存输出模型的目录
net_type: "mobilenet_v2" # 骨干网络,支持:resnet18/50,mobilenet_v2,googlenet,inception_v3
width_mult: 1.0 # 模型宽度因子
input_size: [ 112,112 ] # 模型输入大小
rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.
rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.
batch_size: 128 # batch_size
lr: 0.01 # 初始学习率
optim_type: "SGD" # 选择优化器,SGD,Adam
loss_type: "CrossEntropyLoss" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothing
momentum: 0.9 # SGD momentum
num_epochs: 100 # 训练循环次数
num_warn_up: 3 # warn-up次数
num_workers: 8 # 加载数据工作进程数
weight_decay: 0.0005 # weight_decay,默认5e-4
scheduler: "multi-step" # 学习率调整策略
milestones: [ 20,50,80 ] # 下调学习率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 50 # LOG打印频率
progress: True # 是否显示进度条
pretrained: True # 是否使用pretrained模型
finetune: False # 是否进行finetune开始训练,在终端输入:
python train.py -c configs/config.yaml
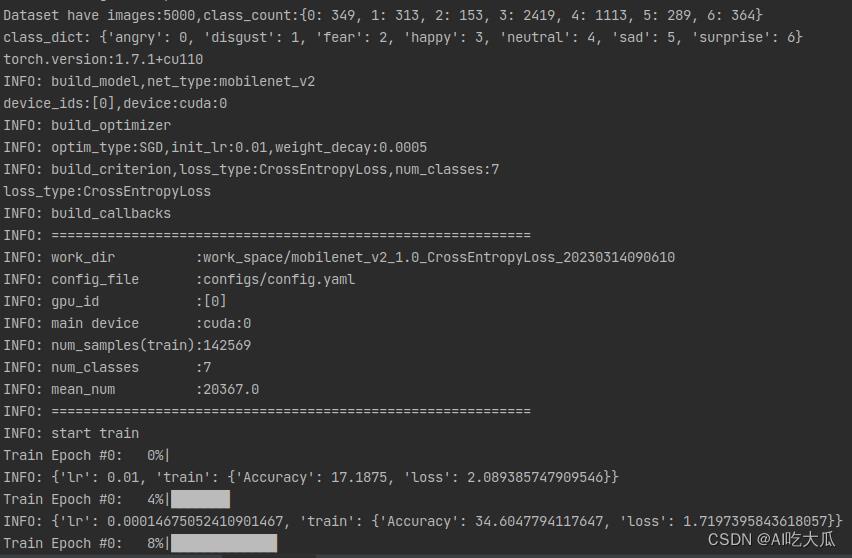
训练完成后,训练集的Accuracy在95.5%以上,测试集的Accuracy在94.5%左右
(4) 可视化训练过程
训练过程可视化工具是使用Tensorboard,在终端(Terminal)输入命令:
使用教程,请参考:项目开发使用教程和常见问题和解决方法
# 需要安装tensorboard==2.5.0和tensorboardX==2.1
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/log
可视化效果




(5) 面部表情识别效果
训练完成后,训练集的Accuracy在95.5%以上,测试集的Accuracy在94.5%左右,下表给出已经训练好的三个模型,其中mobilenet_v2的准确率可以达到94.72%,googlenet的准确率可以达到94.28%,resnet18的准确率可以达到94.81%
| 模型 | input size | Test准确率 |
| mobilenet_v2 | 112×112 | 94.72% |
| googlenet | 112×112 | 94.28% |
| resnet18 | 112×112 | 94.818% |
-
测试图片文件
# 测试图片(Linux)
image_dir='data/test_image' # 测试图片的目录
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230313090258/model/latest_model_099_94.7200.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --image_dir $image_dir --model_file $model_file --out_dir $out_dirWindows系统,请将$image_dir, $model_file ,$out_dir等变量代替为对应的变量值即可,如
# 测试图片(Windows)
python demo.py --image_dir 'data/test_image' --model_file "data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/model/latest_model_099_98.4316.pth" --out_dir "output/"
-
测试视频文件
# 测试视频文件(Linux)
video_file="data/video-test.mp4" # 测试视频文件,如*.mp4,*.avi等
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230313090258/model/latest_model_099_94.7200.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir
-
测试摄像头
# 测试摄像头(Linux)
video_file=0 # 测试摄像头ID
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230313090258/model/latest_model_099_94.7200.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir
下面是面部表情识别效果展示(其中不同表情用不同颜色表示了)



(6) 一些优化建议
如果想进一步提高模型的性能,可以尝试:
- 清洗数据集(最重要):尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。
- 增加训练的样本数据: 建议根据自己的业务场景,采集相关数据,提高模型泛化能力
- 使用参数量更大的模型: 本教程使用的是mobilenet_v2模型,属于比较轻量级的分类模型,采用更大的模型(如resnet50),理论上其精度更高,但推理速度也较慢。
- 尝试不同数据增强的组合进行训练
- 增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式
- 样本均衡: 原始数据表情识别类别数据并不均衡,类别happy和neutral的数据偏多,而disgust和fear的数据偏少,这会导致训练的模型会偏向于样本数较多的类别。建议进行样本均衡处理。
- 调超参: 比如学习率调整策略,优化器(SGD,Adam等)
- 损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数
(7) 一些运行错误处理方法
-
项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!!!!!!!!
-
cannot import name 'load_state_dict_from_url'
由于一些版本升级,会导致部分接口函数不能使用,请确保版本对应
torch==1.7.1
torchvision==0.8.2
或者将对应python文件将
from torchvision.models.resnet import model_urls, load_state_dict_from_url
修改为:
from torch.hub import load_state_dict_from_url
model_urls =
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
5.项目源码下载(Python版)
项目源码下载地址:
整套项目源码内容包含:
- 提供面部表情识别数据集:本项目主要使用两个表情识别数据集:Emotion-Domestic国内(亚洲)表情识别数据集+MMAFEDB表情识别数据集,总共超过15万张人脸图片,数据面部表情丰富多样,包含angry(生气), disgust (厌恶), fear(害怕), happy(快乐), neutral (中性), sad(悲伤), surprise(惊奇)等多种表情。
- 提供面部表情识别分类模型训练代码:train.py
- 提供面部表情识别分类模型测试代码:demo.py
- Demo支持图片,视频和摄像头测试
- 支持自定义数据集进行训练
- 项目支持模型:resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型
- 项目源码自带训练好的模型文件,可直接运行测试: python demo.py
- 在普通电脑CPU/GPU上可以实时检测和识别
6.项目源码下载(Android版)
目前已经实现Android版本的面部表情识别,详细项目请参考:面部表情识别3:Android实现面部表情识别(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/129467015
Android面部表情识别APP Demo体验:https://download.csdn.net/download/guyuealian/87575425
以上是关于面部表情识别3:Android实现表情识别(含源码,可实时检测)的主要内容,如果未能解决你的问题,请参考以下文章