如何利用Python抓取PDF中的某些内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用Python抓取PDF中的某些内容相关的知识,希望对你有一定的参考价值。
可以转换成TXT再抓取
from cStringIO import StringIO
from pdfminer.pdfinterp
import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParamsfrom pdfminer.pdfpage
import PDFPage
def convert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec=\'utf-8\', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, \'rb\') as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()
return text 参考技术A 你的问题事实上包含几部分:
将 PDF 转化为纯文本格式
抽取其中部分内容
格式化写入到 excel 中
转换 PDF 有很多库可以完成,如下是通过 pdfminer 的示例:
from cStringIO import StringIO
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
def convert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, 'rb') as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()
return text
需要指出的是,pdfminer 不但可以将 PDF 转换为 text 文本,还可以转换为 html 等带有标签的文本。上面只是最简单的示例,如果每页有很独特的标志,你还可以按页单独处理。 参考技术B
学生每天要学习,工作者每天要工作,家庭主妇每天也都要做家务。不论做什么,都有着相应的操作流程,同样就会有操作技巧。学生运用技巧学习才不会累,学得还会更快更多;工作者掌握技巧进行工作,才能有好的工作效率;家庭主妇把握做家务的技巧,才能够更快的完成家务活。因此说明了,做任何事学会了技巧,才可更轻松更好的完成。
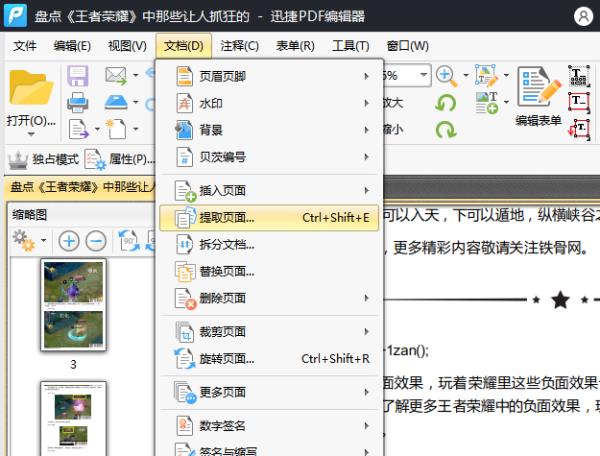
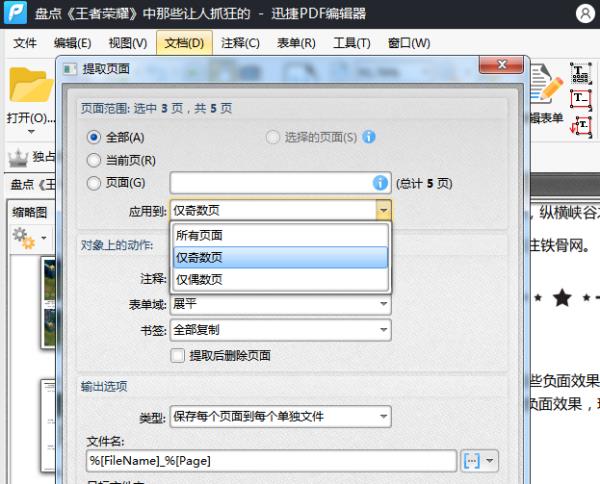
小编原来做事就因为不懂得学习技巧,掌握技巧,导致浪费了时间,结果做出来还差强人意。因此后来小编每当要面临新的任务,新的挑战都会认真审查,想出解决技巧,再去进行实际操作。小编这不刚刚接到任务,让小编给PDF提取页面,这次小编要运用技巧,顺利的解决这个问题。
如何利用python读取网页中变量的内容
参考技术A 正常情况下都是能抓取的,有可能是你抓取时环境不一样所致。比如你在某页面输入好了之后用Python抓取,py会发出请求,这时候你输入的东西是不可能被抓到的。
相当于你重新打开页面没有任何输入时在浏览器点击网页另存为一样。
或者补充下你的问题,才能有具体的解决方案! 参考技术B # encoding: UTF-8
import urllib2
import re
import json
content = urllib2.urlopen('http://yinyue.kuwo.cn/cinfo/24149/12_422038408_45/70后.htm').read()
pattern = re.compile(r'var\s+jsonm[=\s]+((?:(?!stortData[=\s]+)[\s\S])*);[\s\S]*stortData')
result = pattern.findall(content)
result = result[0]
print result
s = json.loads(result)
print s
print s.keys()
print s["musiclist"][0]["name"]
以上是关于如何利用Python抓取PDF中的某些内容的主要内容,如果未能解决你的问题,请参考以下文章