2023-Python实现有道翻译接口加密解密
Posted 抄代码抄错的小牛马
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023-Python实现有道翻译接口加密解密相关的知识,希望对你有一定的参考价值。
文章目录
学习记录:2023–有道翻译接口
sign 等参数的加密 及
返回的密文数据解密实现。
👉1、目标网址
有道翻译的官网:有道翻译
👉2、寻找翻译结果接口并分析
输入中文:快乐 要求翻译成:英文
全局搜索:快乐 或 happy,结果没有发现什么
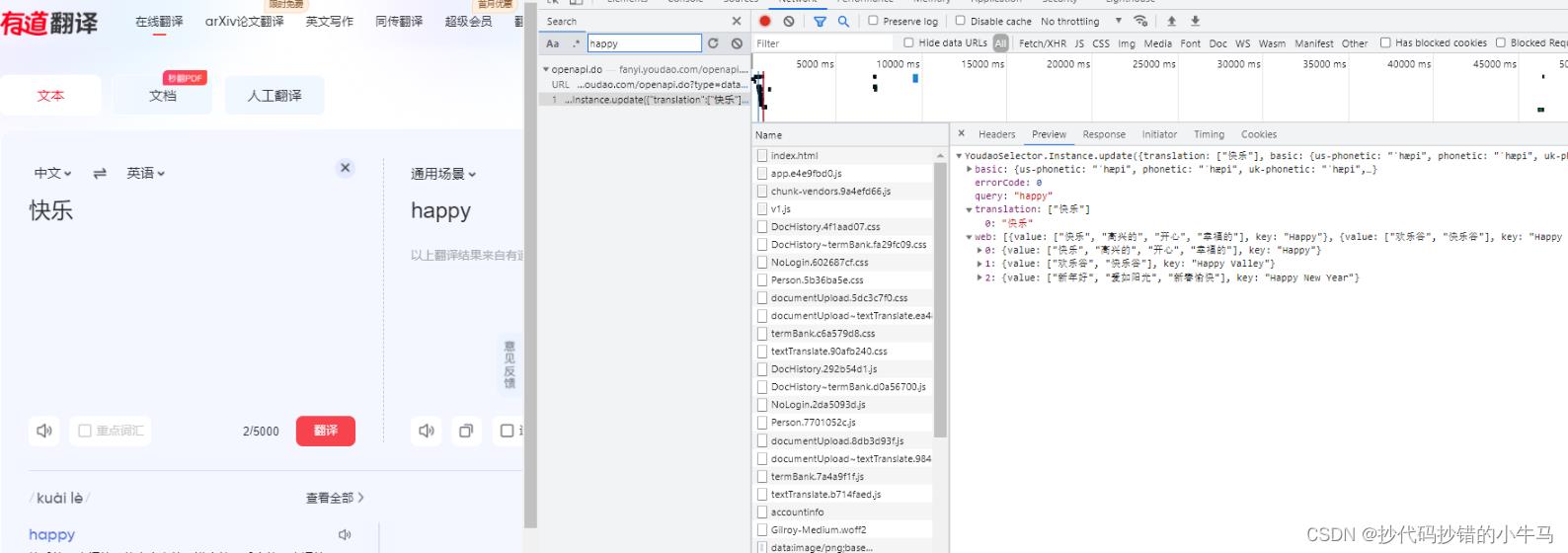
切换 Fetch/XHR 进行搜索筛选后,找到了下面的一个接口,点击进行查看: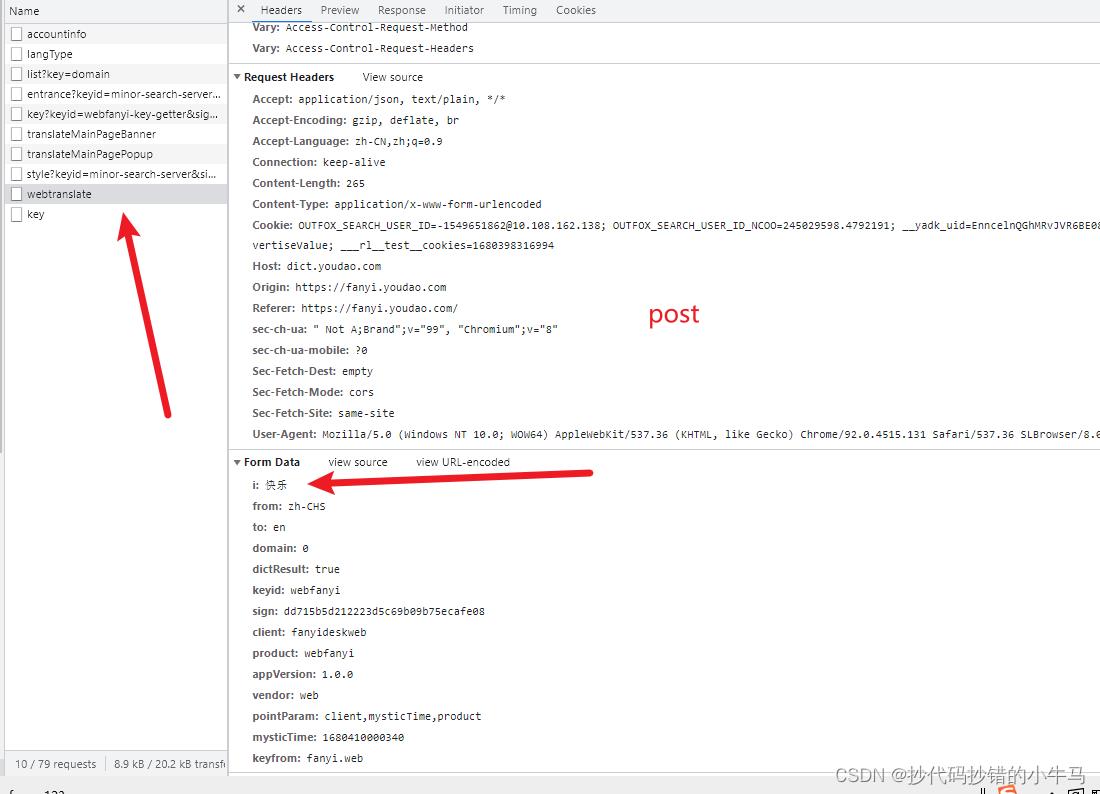
初看:post请求,携带的参数有我们输入的中文:快乐,再看返回数据:多试试结果翻译结果发现它是变化的,对于这样我们只有去多找找了。
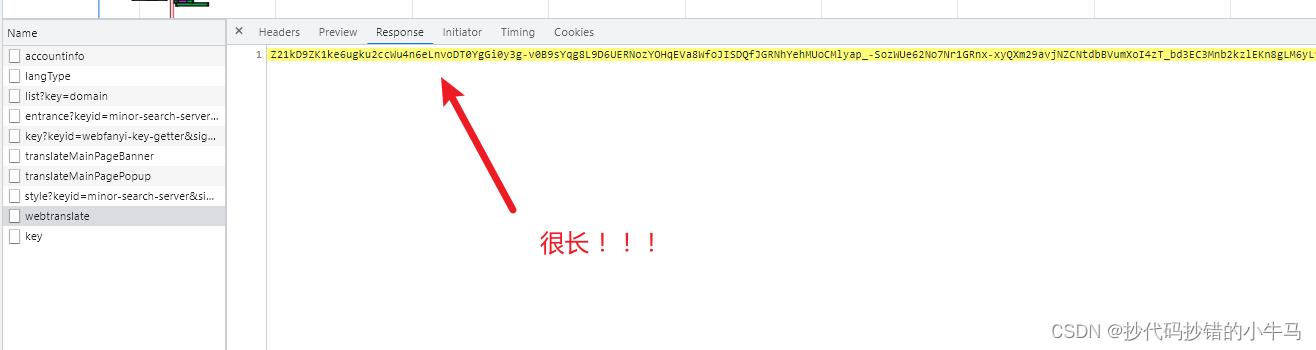
但我在调试时 ==> 对有道网页一顿乱点后找到了新接口:
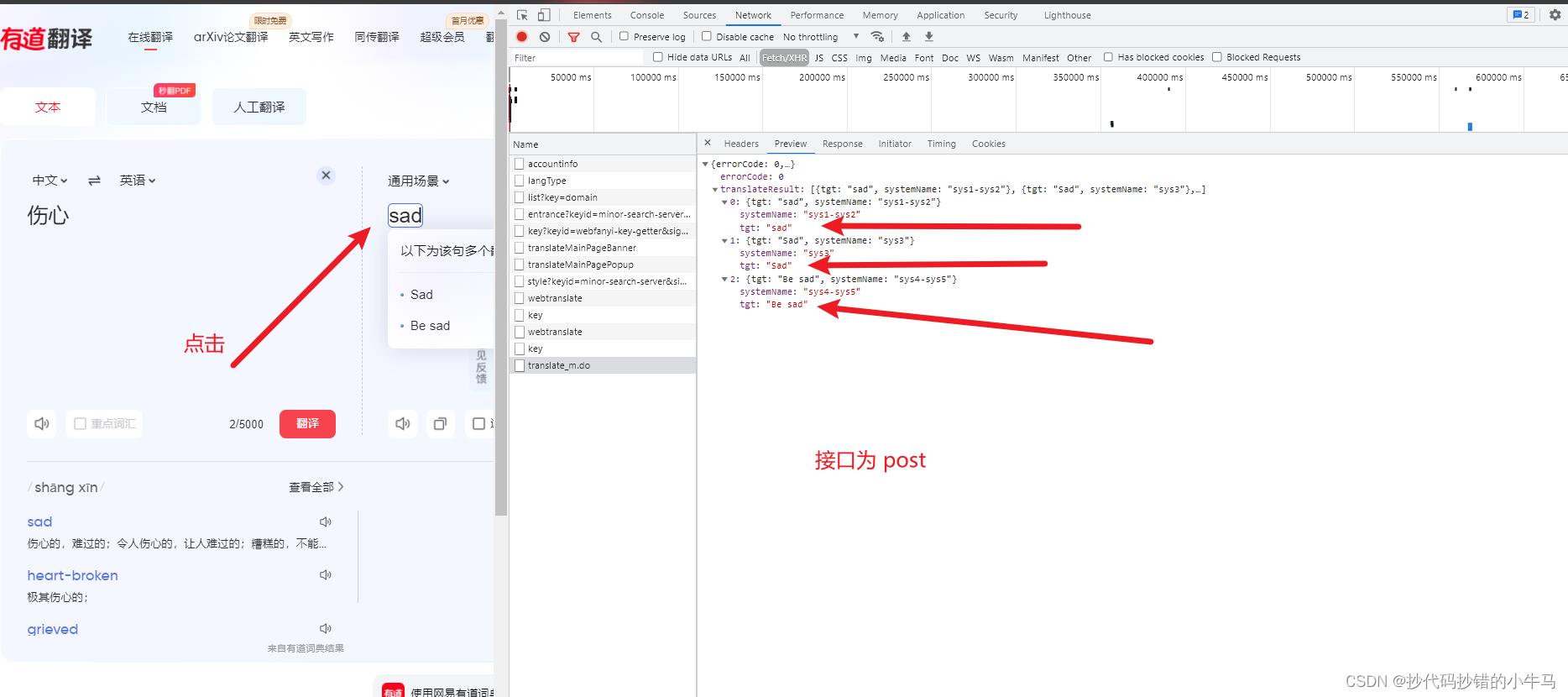
在这个接口中,它有我们想要的返回数据,且是能直接看懂的数据!!!那就抛弃之前的接口,就对这个接口分析:
参数:
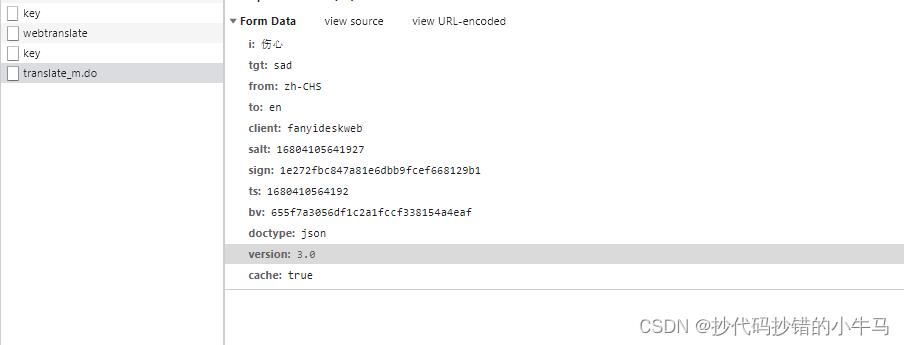
初看 sign 发现它是动态变化的,ts 与 salt 可能是时间戳,bv 不知道是啥,但请求几次后发现它不变。
好,全局搜素 sign 进行查看:在如下 js 找到:
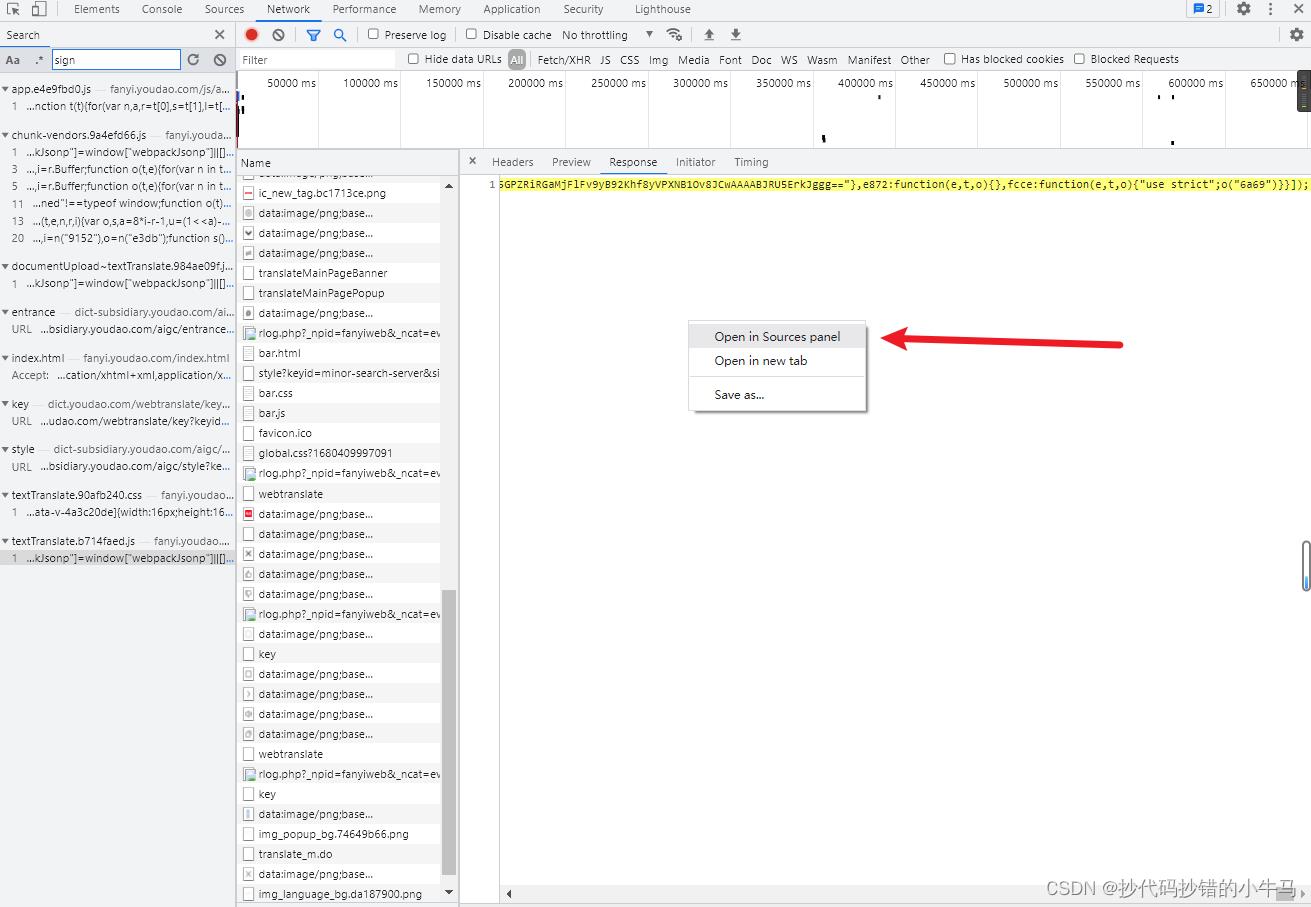
进入 搜索 sign :发现
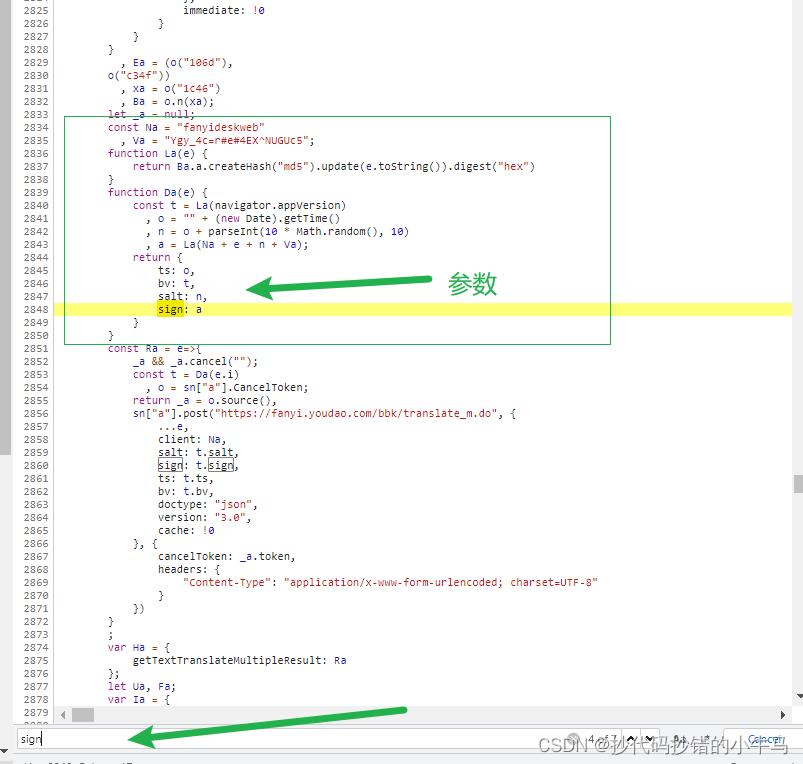
找到这里就断点调试看看:我所找到的:
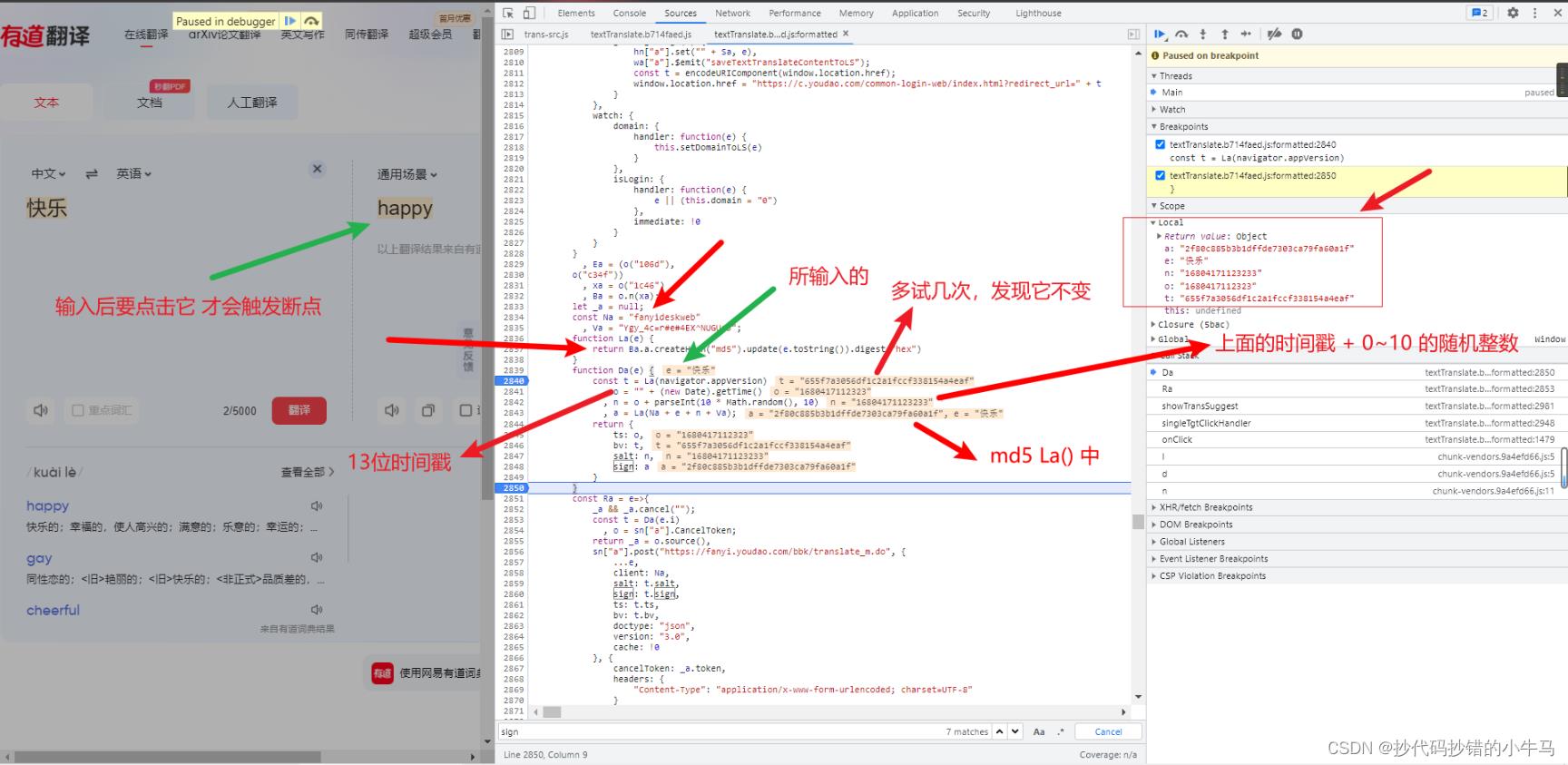
所以:
ts:1680404913064, ==> 13位 当前时间戳salt:16804049130648, ==> 13位 当前时间戳 + [0,9] 的一个随机整数sign:e9c74c82dbb3ca3f1d25f0a743647a8d, ==> md5 La(Na + e + n + Va)
Na => “fanyideskweb” e => 用户输入的字符 n => salt Va => “Ygy_4c=r#e#4EX^NUGUc5”
对应 Python 代码:
ts = str(int(time.time() * 1000))
salt = ts + str(random.randrange(0, 10))
# md5 -> 编码 -> 转16进制 数据字符串
sign = hashlib.md5(("fanyideskweb" + translation_words + salt + "Ygy_4c=r#e#4EX^NUGUc5").encode('utf-8')).hexdigest()
好! 关键参数解决了,下面进行Python代码实现
👉3、Python 实现有道翻译接口调用
""""
CSDN:抄代码抄错的小牛马
"""
import hashlib
import time
import random
import requests
url = 'https://fanyi.youdao.com/bbk/translate_m.do'
headers =
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'fanyi.youdao.com',
'Origin': 'https://fanyi.youdao.com',
'Referer': 'https://fanyi.youdao.com/index.html',
'Cookie': '复制你那里的cookie',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="8"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/25',
translation_words = '周末愉快'
# 'ts': '1680404913064', ==> 13位 当前时间戳
# 'salt': '16804049130648', ==> 13位 当前时间戳 + [0,9] 的一个随机整数
# 'sign': 'e9c74c82dbb3ca3f1d25f0a743647a8d', ==> md5 La(Na + e + n + Va);
# Na -> "fanyideskweb"
# e -> translation_words
# n -> salt
# Va -> "Ygy_4c=r#e#4EX^NUGUc5"
ts = str(int(time.time() * 1000))
salt = ts + str(random.randrange(0, 10))
# md5 -> 编码 -> 转16进制 数据字符串
sign = hashlib.md5(("fanyideskweb" + translation_words + salt + "Ygy_4c=r#e#4EX^NUGUc5").encode('utf-8')).hexdigest()
print(sign)
form_data =
'i': translation_words,
'from': 'zh-CHS',
'to': 'en',
'client': 'fanyideskweb',
'bv': '655f7a3056df1c2a1fccf338154a4eaf',
'doctype': 'json',
'version': '3.0',
'cache': 'true',
'ts': ts,
'salt': salt,
'sign': sign,
res = requests.post(url=url, headers=headers, data=form_data).json()
resp = [i['tgt'] for i in res['translateResult']]
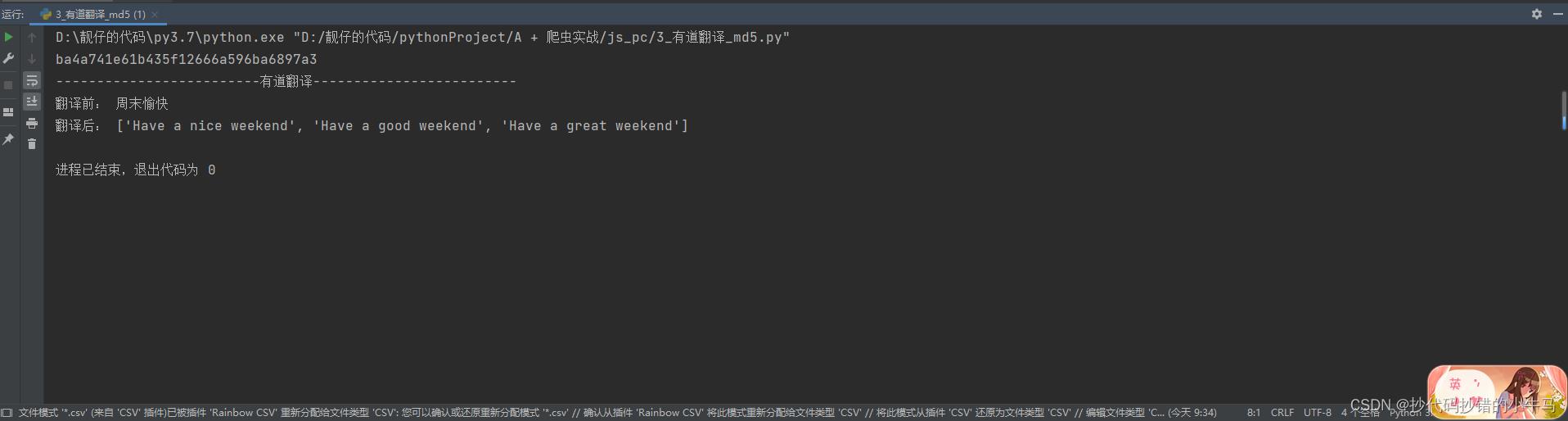
print('-------------------------有道翻译-------------------------')
print('翻译前:', translation_words)
print('翻译后:', resp)
运行:
tgt 参数: 可省略
from: en == >翻译前的语言
to: zh-CHS == >翻译成什么语言
这里就不太行,设置 auto 报错,虽然可以把所有的语言参数弄进去,让用户选择
👉4、最理想的接口分析
但这样有个缺点:上面那个接口不能自动识别翻译前的语言。又去找了一会儿,发现最符合我们理想的接口,就是最初找的那个接口,虽然上面我们解决的参数,但是这个返回的数据是加密的。只有去找js看了。
捣鼓一会儿:

在控制台它打印出来了数据:多试几次后发现它就是接口返回的加密数据解密后的状态。因为它翻译后返回的数据是加密过后的,那他是怎么加密返回给我们的呢?它又是在哪里解密返回的呢?
测试发现可以搜素解密后的接口数据 或 translateResult找到加密解密JS:命中目标 !!!
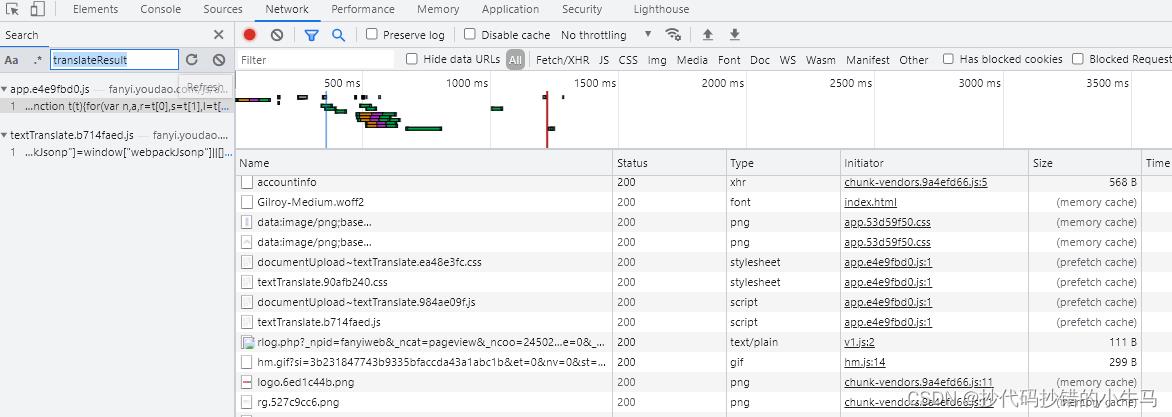
断点调试:
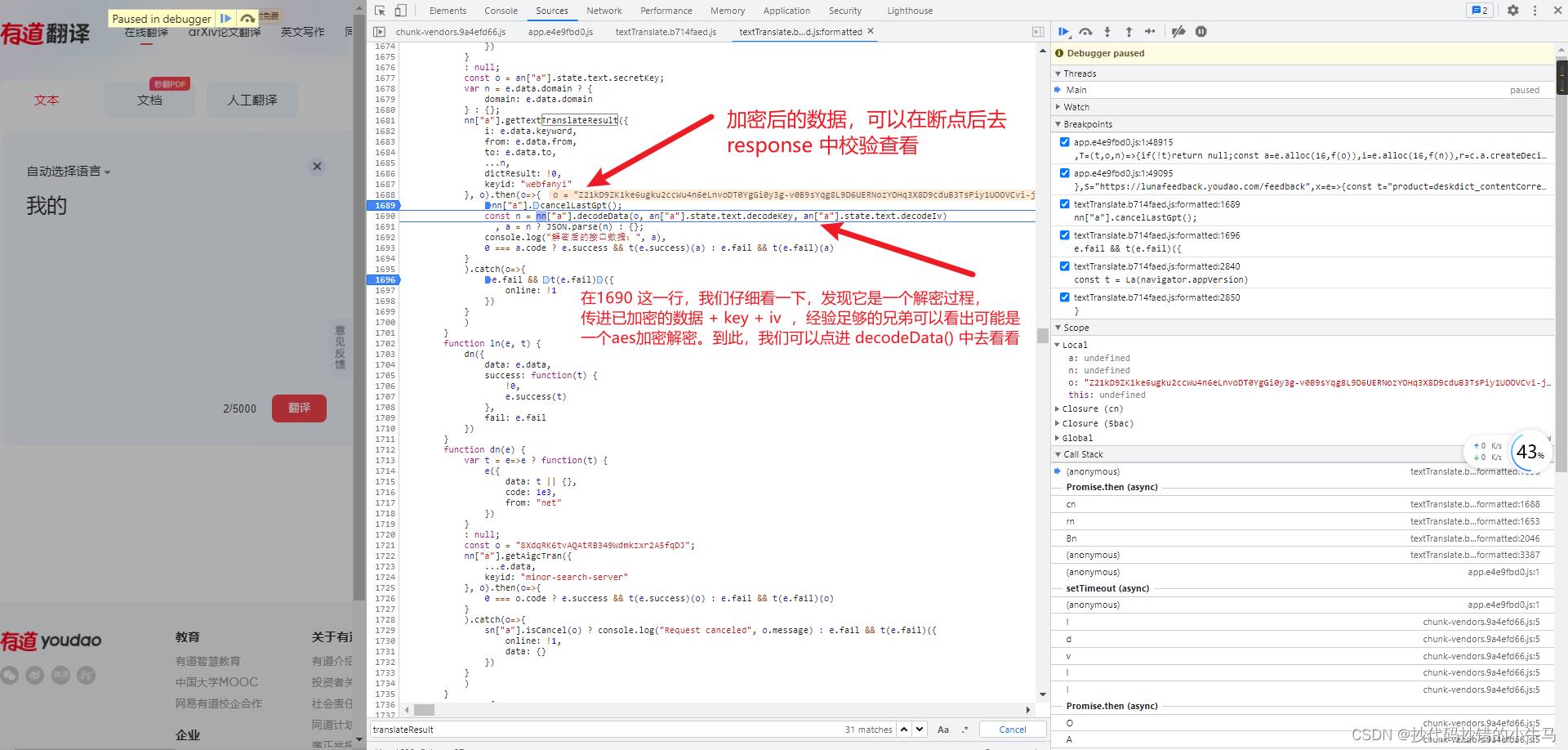
在1690 这一行,我们仔细看一下,发现它是一个解密过程,传进已加密的数据 + key + iv ,经验足够的兄弟可以看出可能是一个aes加密解密。到此,我们可以点进 decodeData() 中去看看

进入后如下:
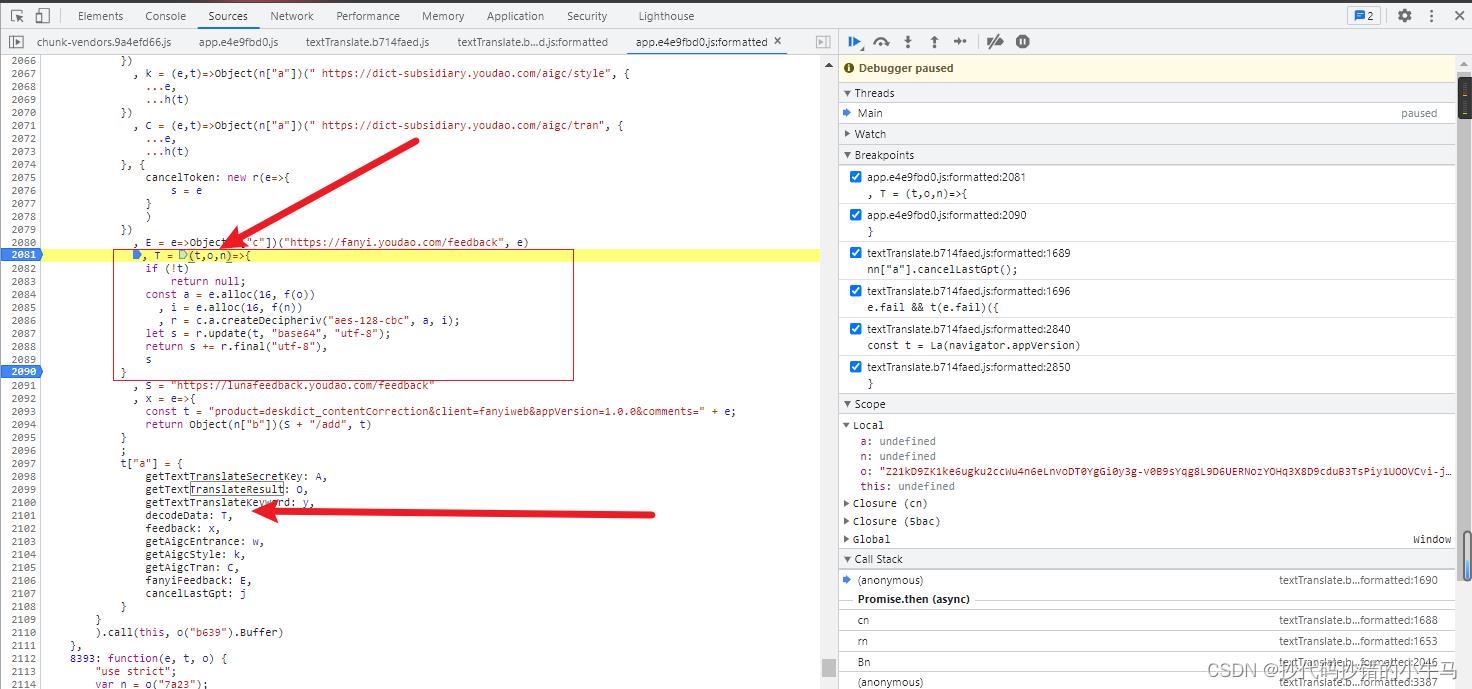
网页js:
T = (t,o,n)=>
if (!t)
return null;
const a = e.alloc(16, f(o))
, i = e.alloc(16, f(n))
, r = c.a.createDecipheriv("aes-128-cbc", a, i);
let s = r.update(t, "base64", "utf-8");
return s += r.final("utf-8"),
s
断点一步一步:
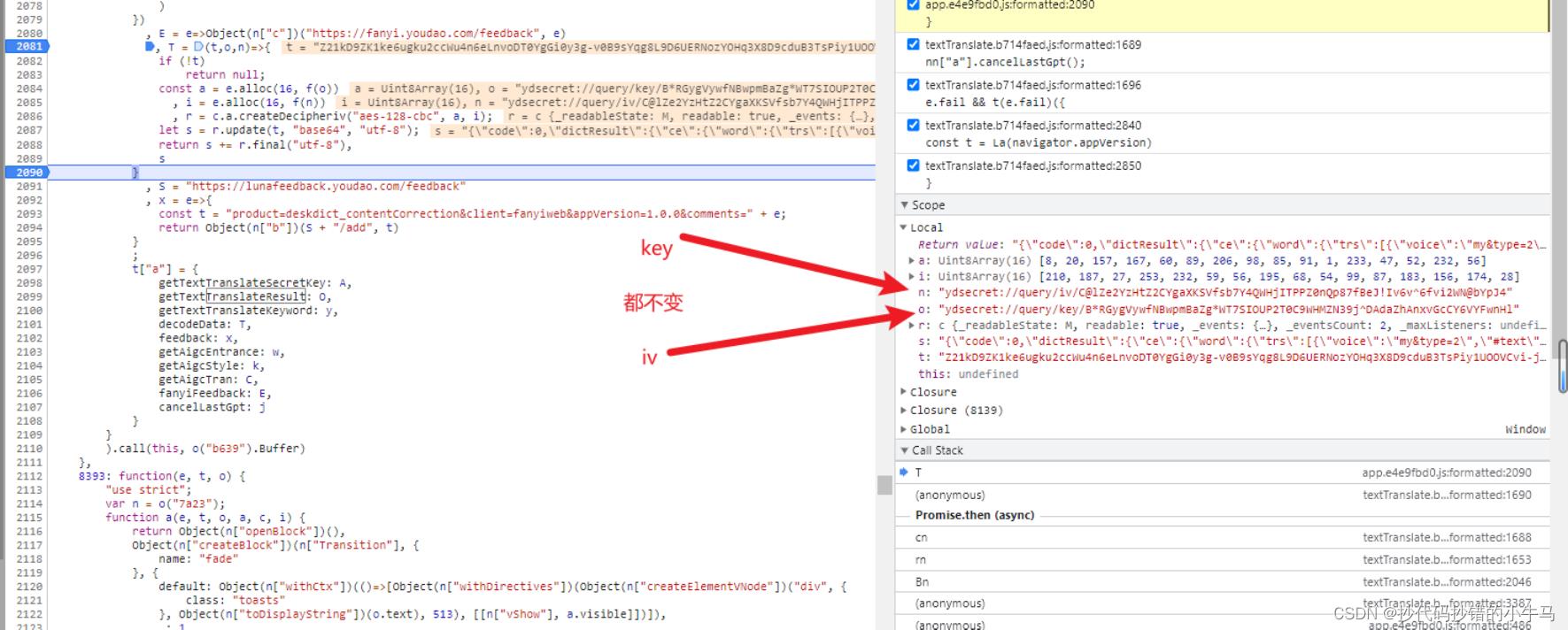
试了几次发现:key 和 iv 没有变
# o --> key = 'ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl'
# n --> iv = 'ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4'
再跟着调试下去:
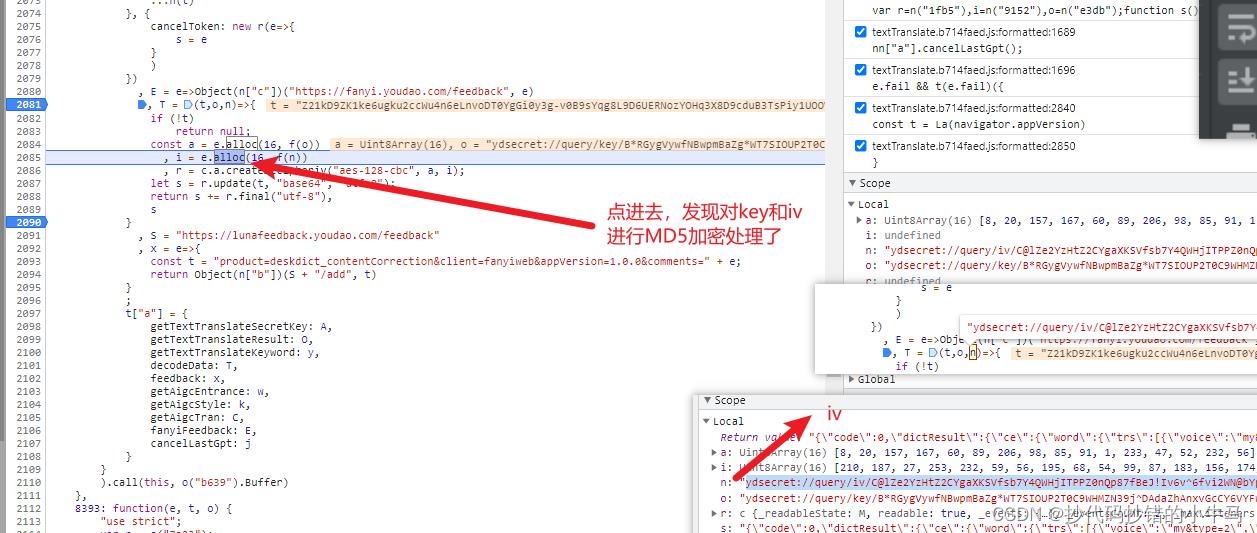
如下:
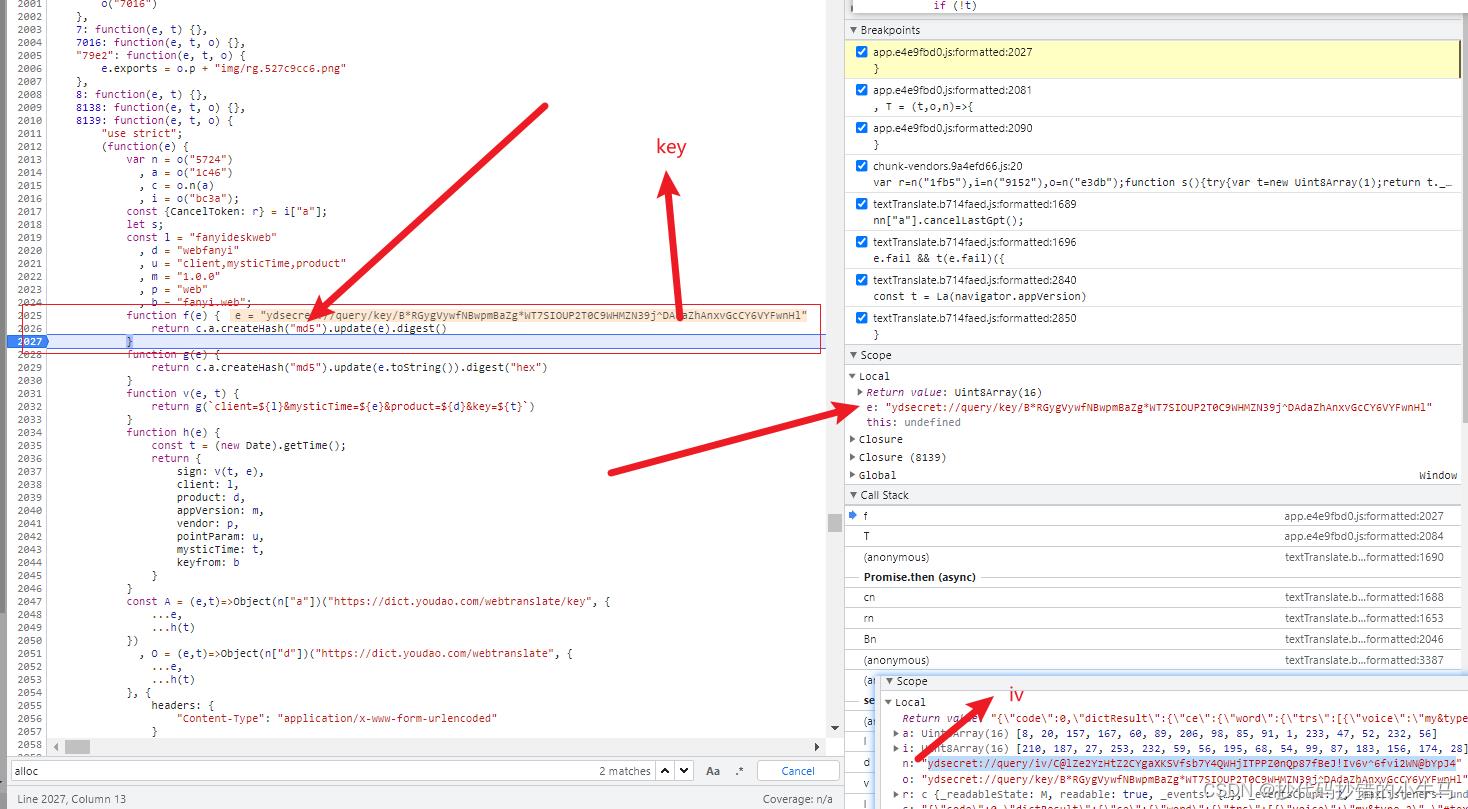
好! 找到规律了,因为发现 key 和 iv 是没变的,所以先将他们 MD5处理了:
""""
CSDN:抄代码抄错的小牛马
"""
import hashlib
# o --> key = 'ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl'
# n --> iv = 'ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4'
key_md5 = hashlib.md5(('ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl').encode('utf-8')).digest()
iv_md5 = hashlib.md5(('ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4').encode('utf-8')).digest()
print(len(key_md5))
print(key_md5)
print(len(iv_md5))
print(iv_md5)
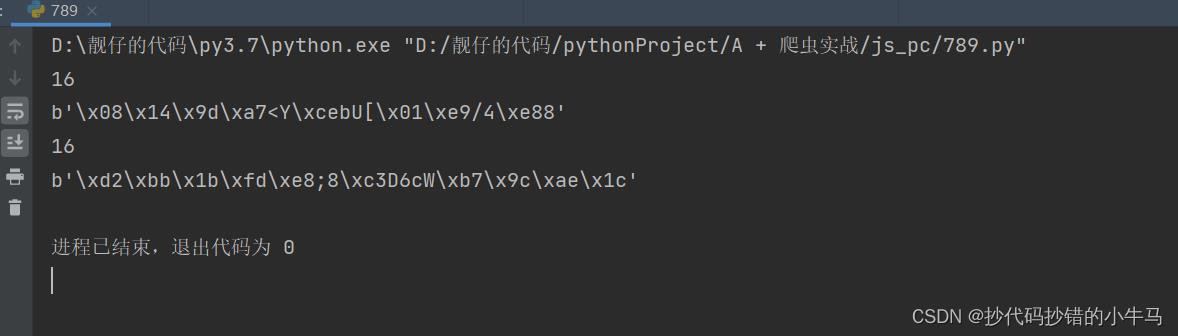
aes解密:
JS:

PY:
from Crypto.Cipher import AES
import hashlib
import base64
from Crypto.Util.Padding import unpad
import time
import requests
import json
def decrypt(decrypt_str):
key = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
iv = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
key_md5 = hashlib.md5((key).encode('utf-8')).digest()
iv_md5 = hashlib.md5((iv).encode('utf-8')).digest()
print('key_md5:', key_md5)
print('iv_md5:', iv_md5)
print()
aes = AES.new(key=key_md5, mode=AES.MODE_CBC, iv=iv_md5)
code = aes.decrypt(base64.urlsafe_b64decode(decrypt_str))
return unpad(code, AES.block_size).decode('utf8')
好!完工~~
👉5、最终实现的密文解密
直接贴代码:
from Crypto.Cipher import AES
import hashlib
import base64
from Crypto.Util.Padding import unpad
import time
import requests
import json
def decrypt(decrypt_str):
key = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
iv = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
key_md5 = hashlib.md5((key).encode('utf-8')).digest()
iv_md5 = hashlib.md5((iv).encode('utf-8')).digest()
print('key_md5:', key_md5)
print('iv_md5:', iv_md5)
print()
aes = AES.new(key=key_md5, mode=AES.MODE_CBC, iv=iv_md5)
code = aes.decrypt(base64.urlsafe_b64decode(decrypt_str))
return unpad(code, AES.block_size).decode('utf8')
def get_data(translation_words):
url = 'https://dict.youdao.com/webtranslate'
headers =
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=379056539.64209586; OUTFOX_SEARCH_USER_ID=-380628258@222.182.116.19',
'Host': 'dict.youdao.com',
'Origin': 'https://fanyi.youdao.com',
'Referer': 'https://fanyi.youdao.com/',
'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
# 'ts': '1680404913064', ==> 13位 当前时间戳
# fsdsogkndfokasodnaso 固定值
ts = str(int(time.time() * 1000))
str_sign = f"client=fanyideskweb&mysticTime=ts&product=webfanyi&key=fsdsogkndfokasodnaso"
sign = hashlib.md5((str_sign).encode('utf-8')).hexdigest()
print('------------------------sign------------------------')
print('sign为:', sign, end='\\n\\n')
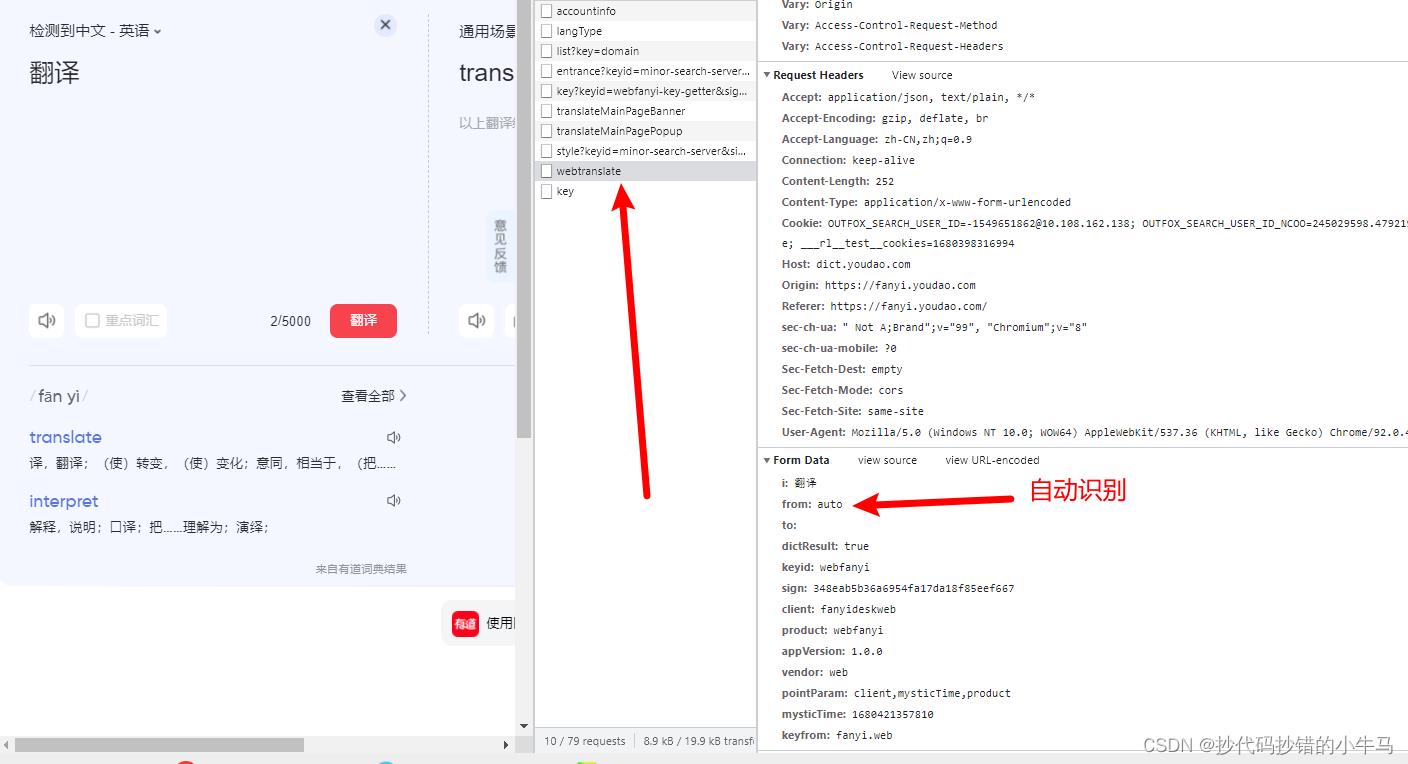
form_data =
'i': translation_words,
'from': 'auto',
'to': '',
'sign': sign,
'dictResult': 'true',
'keyid': 'webfanyi',
'client': 'fanyideskweb',
'product': 'webfanyi',
'appVersion': '1.0.0',
'vendor': 'web',
'pointParam': 'client,mysticTime,product',
'mysticTime': ts,
'keyfrom': 'fanyi.web',
res = requests.post(url=url, headers=headers, data=form_data).text
print('------------------------返回的数据密文------------------------')
print(res, end='\\n\\n')
return res
if __name__ == "__main__":
translation_words = '周末愉快'
# translation_words = input("请输入要翻译的:")
decrypt_str = get_data(translation_words)
end_code = decrypt(decrypt_str)
print('------------------------解密后的数据密文------------------------')
print(end_code, end='\\n\\n')
json_data = json.loads(end_code)
print('-------------------------有道翻译-------------------------')
print('翻译前:', translation_words)
print('翻译后:', json_data['translateResult'])
运行结果:
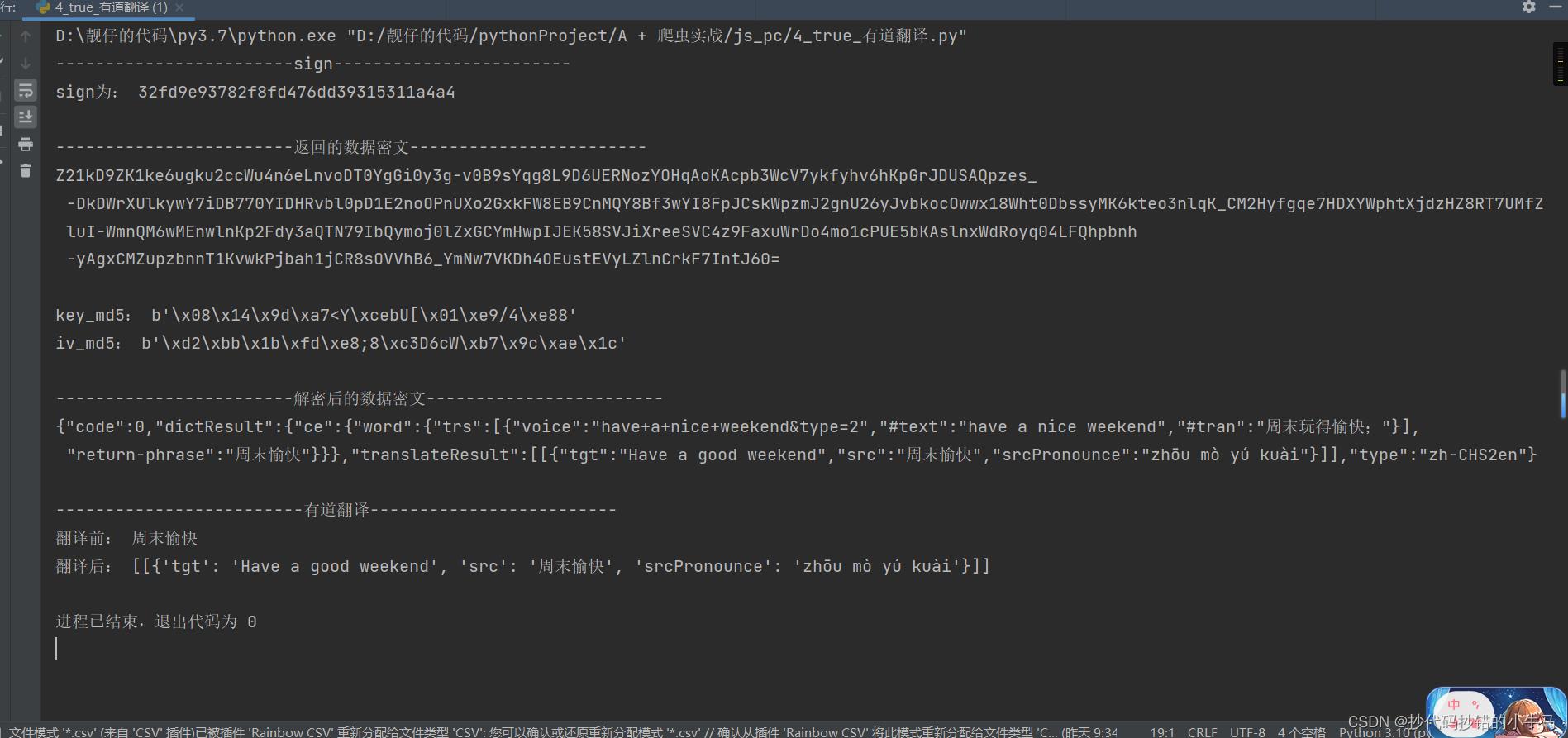
拜~~~
我们下次再见 ^ _ ^
Python 爬虫篇 - 调用有道翻译api接口翻译外文网站的整篇西班牙文实战演示。爬取西班牙语文章调用有道翻译接口进行整篇翻译
Python 调用有道翻译 api 接口翻译整篇西班牙文实战演示
第一章:翻译效果展示
① 翻译文章示例一【阿尔卡拉门的无海摩纳哥:“不到4万欧元,你就不能在这里租任何东西。”】
文章: 阿尔卡拉门的无海摩纳哥:“不到4万欧元,你就不能在这里租任何东西。”
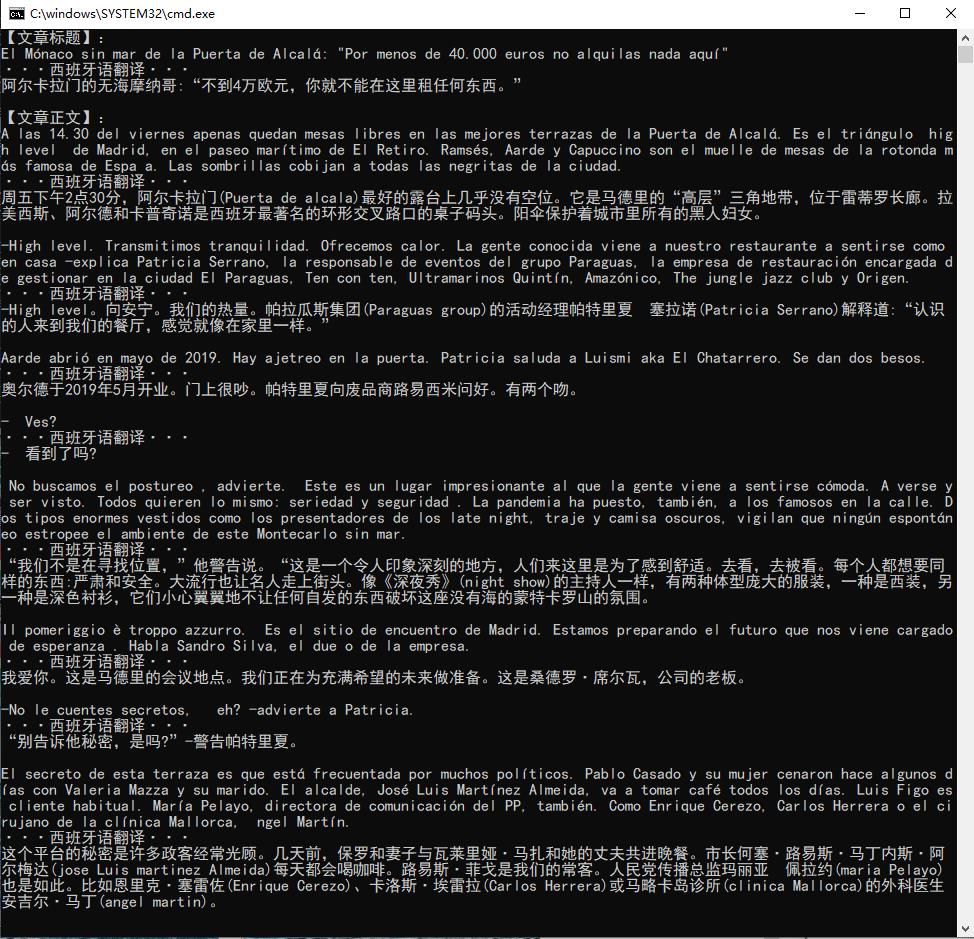
翻译后的效果:
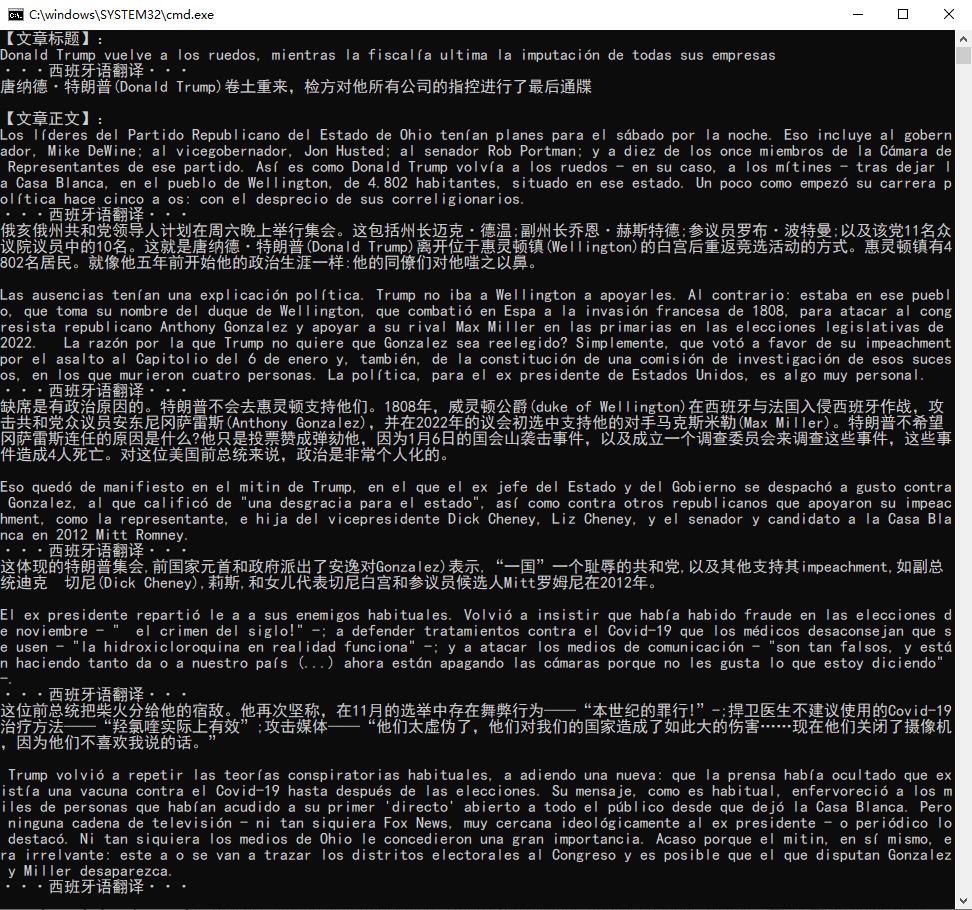
② 翻译文章示例二【唐纳德·特朗普(Donald Trump)卷土重来,检方对他所有公司的指控进行了最后通牒】
文章: 唐纳德·特朗普(Donald Trump)卷土重来,检方对他所有公司的指控进行了最后通牒
第二章:实现
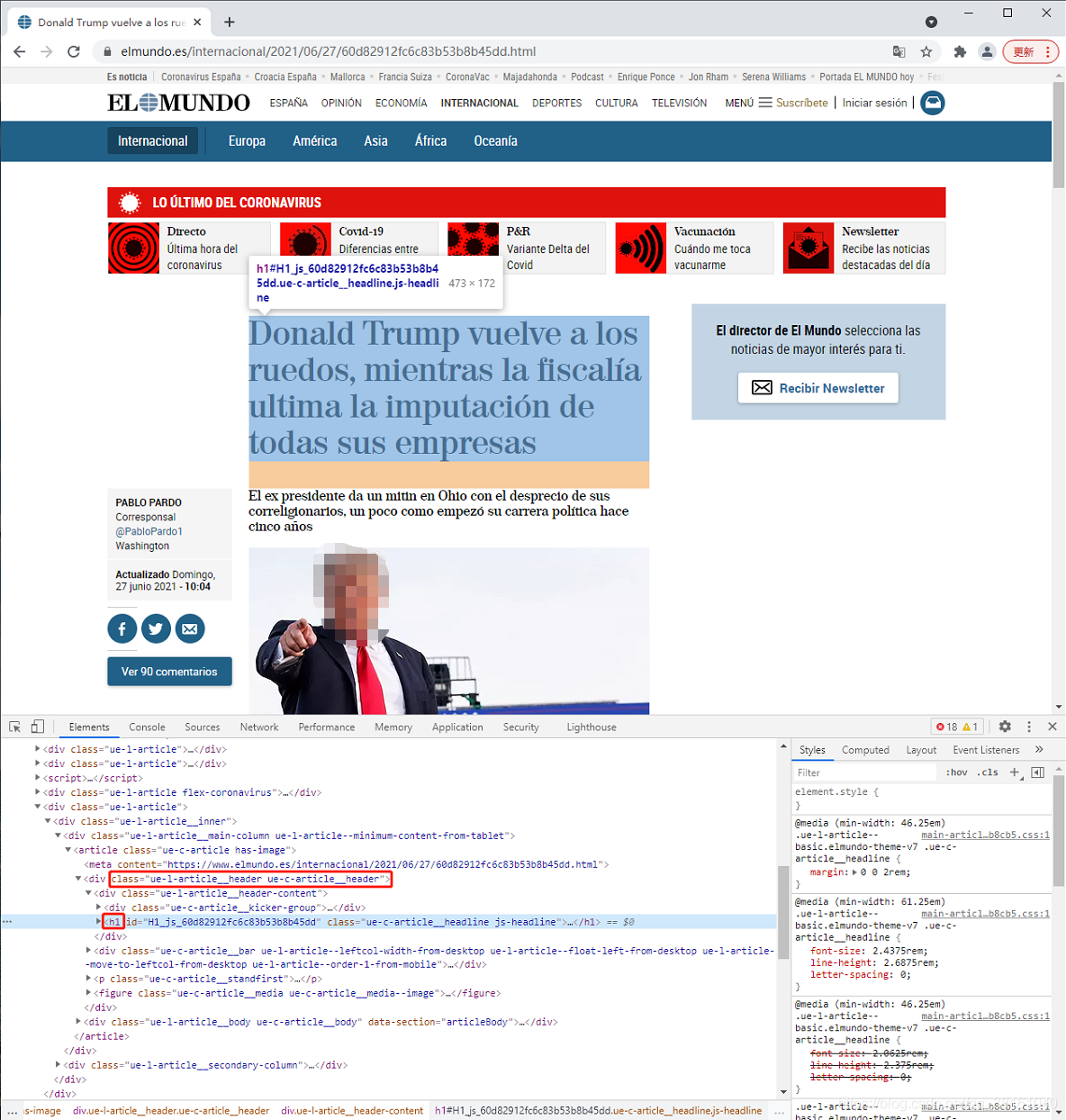
① 文章结构分析
我们可以看到文章标题是在 class="ue-l-article__header-content" 的 div 下的 h1 里的内容。
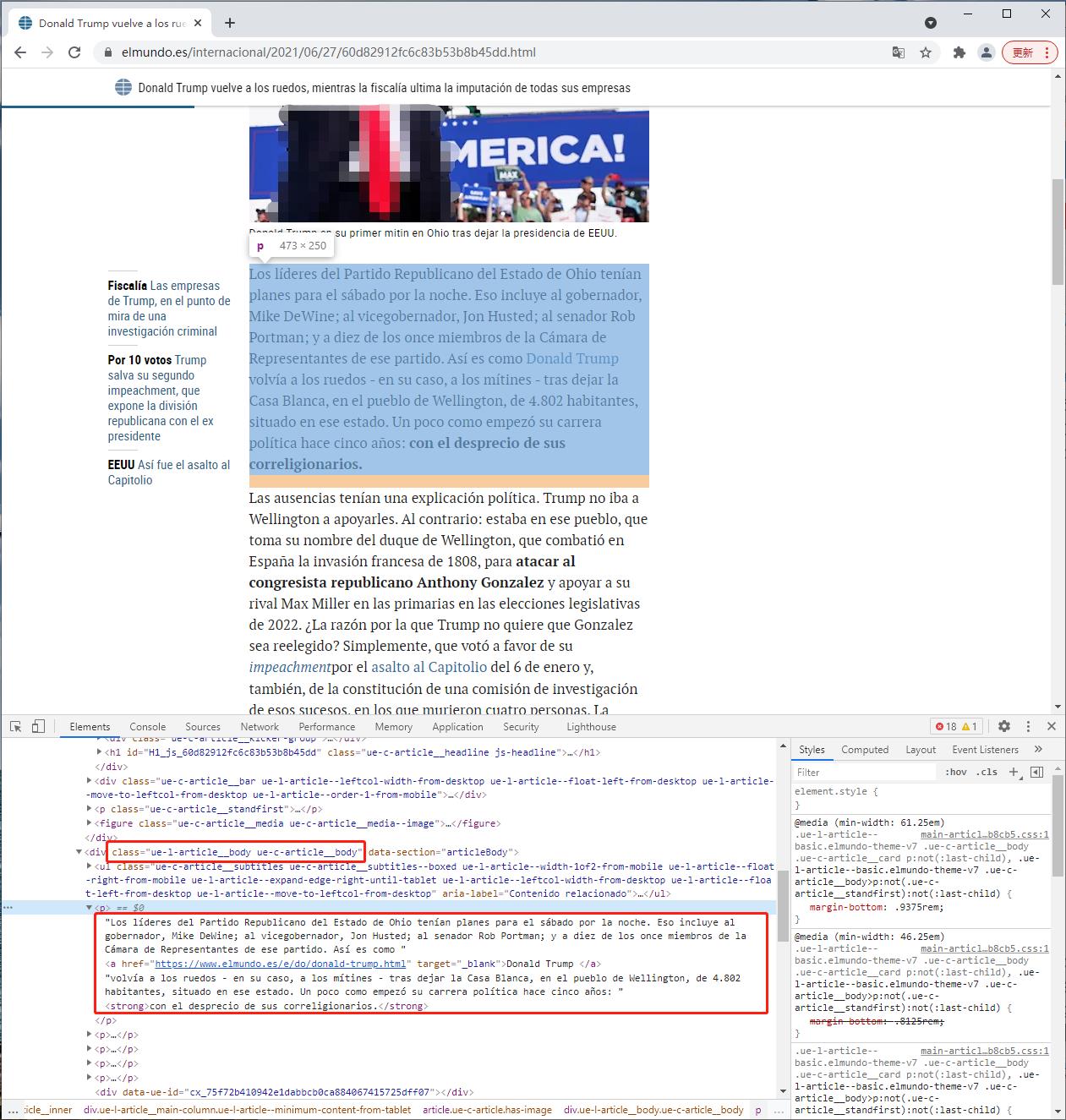
正文内容在 class="ue-l-article__body ue-c-article__body" 的 div 下的 p 元素里。
② 文章内容爬取
利用 BeautifulSoup 库对内容进行爬取。
bs4 模块通过 pip install bs4 即可进行安装。
注:文章内注释的翻译部分的代码就是后面要用到的翻译接口。
from urllib.request import urlopen
from bs4 import BeautifulSoup
def article_structure(article_url):
"""
xiaolanzao, 2021.06.27
【作用】
对传入网站的文章内容进行爬取
【参数】
article_url : 需要进行翻译的中文
【返回】
无
"""
url = urlopen(article_url)
soup = BeautifulSoup(url, 'html.parser') # parser 解析
# 读取文章标题
alert_header = soup.find('div', class_="ue-l-article__header-content").find('h1')
print("【文章标题】:")
print(alert_header.string)
# print("···西班牙语翻译···")
# print(spanish_translator(alert_header.string))
# 读取文章正文
alert_body = soup.find('div', class_="ue-l-article__body ue-c-article__body").contents # 所有body里的p节点
print("\\n【文章正文】:")
for i in alert_body:
if(i.name == "p"):
print(i.getText())
# print("···西班牙语翻译···")
# print(spanish_translator(i.getText()))
print()
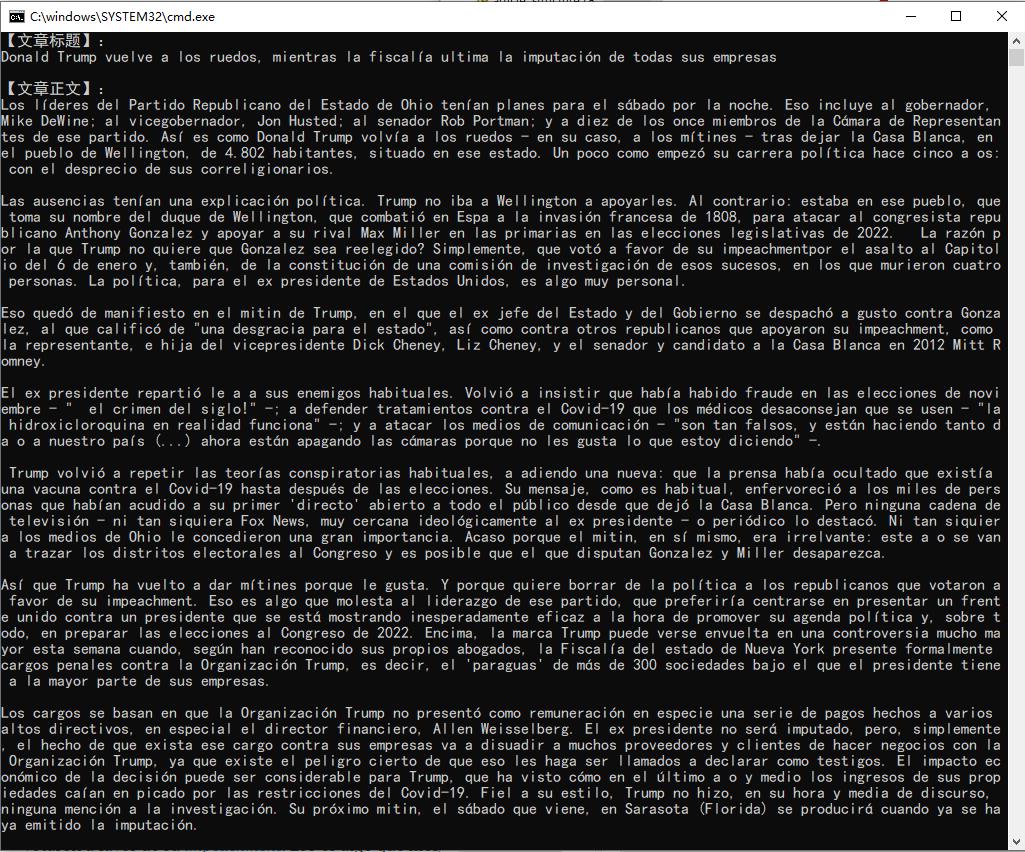
这是爬取后的文章。
③ 有道翻译接口
翻译接口如下,json 参数里面的 from,设置为西班牙文用的是 es。
实现过程,还有有道 api 的配置过程可以看我的这篇文章:
Python 技术篇-有道翻译api接口调用详细讲解、实战演示,有道智云·AI开放平台
import requests
import time
import hashlib
import uuid
def spanish_translator(translate_text):
"""
xiaolanzao, 2021.06.27
【作用】
将传入的西班牙语内容翻译为中文
【参数】
translate_text : 需要进行翻译的中文
【返回】
翻译后的西班牙文
"""
youdao_url = 'https://openapi.youdao.com/api' # 有道api地址
input_text = "" # 翻译文本生成sign前进行的处理
# 当文本长度小于等于20时,取文本
if(len(translate_text) <= 20):
input_text = translate_text
# 当文本长度大于20时,进行特殊处理
elif(len(translate_text) > 20):
input_text = translate_text[:10] + str(len(translate_text)) + translate_text[-10:]
app_id = "xxx" # 应用id
app_key = "xxx" # 应用密钥
time_curtime = int(time.time()) # 秒级时间戳获取
uu_id = uuid.uuid4() # 随机生成的uuid数,为了每次都生成一个不重复的数。
sign = hashlib.sha256((app_id + input_text + str(uu_id) + str(time_curtime) + app_key).encode('utf-8')).hexdigest() # sign生成
data = {
'q':translate_text,
'from':"es",
'to':"zh-CHS",
'appKey':app_id,
'salt':uu_id,
'sign':sign,
'signType':"v3",
'curtime':time_curtime,
}
r = requests.get(youdao_url, params = data).json() # 获取返回的json()内容
return r["translation"][0] # 获取翻译内容
喜欢的点个赞❤吧!
以上是关于2023-Python实现有道翻译接口加密解密的主要内容,如果未能解决你的问题,请参考以下文章