TF-IDF 算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF-IDF 算法相关的知识,希望对你有一定的参考价值。
参考技术A有一篇很长的文章,用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?
"智能问答"、"企业"、"问答库"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
“企业”是很常见的词,相对而言“智能问答”和“问答库”不那么常见。如果这三个词在一篇文章的出现次数一样多,我们有理由可以认为,“智能问答”和“问答库”的重要程度要大于“企业”,也就是说,在关键词排序方面,“智能问答“和”问答库“应该排在”企业“前面。
需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。
这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
需要一个语料库(corpus),用来模拟语言的使用环境。
逆文档频率(IDF)= log(语料库的文档总数/包含该词的文档数+1)
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
TF-IDF=词频(TF)*逆文档频率(IDF)
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
希望找到与原文章相似的其他文章,为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。
句子A:我喜欢吃苹果,不喜欢吃香蕉
句子B:我不喜欢吃苹果,也不喜欢吃香蕉
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
coso=a_2+b_2-c_2/2ab
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
coso=x_1x_2+y_1+y_2/sqrt()
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
如果能从3000字的文章,提炼出150字的摘要,就可以为读者节省大量阅读时间。由人完成的摘要叫"人工摘要",由机器完成的就叫"自动摘要"。
文章的信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。"自动摘要"就是要找出那些包含信息最多的句子。
句子的信息量用"关键词"来衡量。如果包含的关键词越多,就说明这个句子越重要。Luhn提出用"簇"(cluster)表示关键词的聚集。所谓"簇"就是包含多个关键词的句子片段。
3.TF-IDF算法介绍应用NLTK实现TF-IDF算法Sklearn实现TF-IDF算法算法的不足算法改进
3.TF-IDF
3.1.TF-IDF算法介绍
3.2.TF-IDF应用
3.3.NLTK实现TF-IDF算法
3.4.Sklearn实现TF-IDF算法
3.5.Jieba实现TF-IDF算法
3.6.TF-IDF算法的不足
3.7.TF-IDF算法改进—TF-IWF算法
3.TF-IDF
以下转自:https://blog.csdn.net/asialee_bird/article/details/81486700
3.1.TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其它文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词除以文章总词数),以防止它偏向长的文件。

其中ni,j是该词在文件dj中出现的次数,分母则是文件dj中所有词汇出现的次数总和;
(2)IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率(IDF):某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
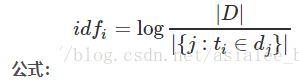
其中,|D|是语料库中的文件总和。 |{j:ti∈dj}|表示包含词语ti的文件数目(即ni,j≠0的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即:
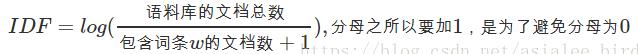
(3)TF-IDF实际上是:TF*IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式:
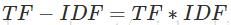
注:TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
3.2.TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
3.3.NLTK实现TF-IDF算法
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
# 首先,构建语料库corpus
sents = ['this is sentence one', 'this is sentence two', 'this is sentence three']
sents = [word_tokenize(sent) for sent in sents] # 对每个句子进行分词
print(sents) # 输出分词后的结果
'''
输出结果:
[['this', 'is', 'sentence', 'one'], ['this', 'is', 'sentence', 'two'], ['this', 'is', 'sentence', 'three']]
'''
corpus = TextCollection(sents) # 构建语料库
print(corpus) # 输出分词后的结果
'''
输出结果:
<Text: this is sentence one this is sentence two...>
'''
# 计算语料库中"one"的tf值
tf = corpus.tf('one', corpus) # 结果为: 1/12
print(tf)
'''
输出结果:
0.08333333333333333
'''
# 计算语料库中"one"的idf值
idf = corpus.idf('one') # log(3/1)
print(idf)
"""
输出结果:
1.0986122886681098
"""
# 计算语料库中"one"的tf-idf值
tf_idf = corpus.tf_idf('one', corpus)
print(tf_idf)
'''
输出结果:
0.0915510240556758
'''
3.4.Sklearn实现TF-IDF算法
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是', '算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记', '主要 思想']
# 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features=10)
# 该类会统计每个词语的tf-idf权值
tf_idf_transformer = TfidfTransformer()
# 将文本转为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
print("--------------------------tf_idf-------------------------------")
print(tf_idf)
print('--------------------------x_train_weight-----------------------')
# 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
print(x_train_weight)
print("---------------------------------------------------------------")
# 对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
输出结果:
--------------------------tf_idf-------------------------------
(0, 2) 0.7071067811865476
(0, 0) 0.7071067811865476
(1, 9) 0.3349067026613031
(1, 7) 0.4403620672313486
(1, 6) 0.4403620672313486
(1, 5) 0.4403620672313486
(1, 3) 0.4403620672313486
(1, 1) 0.3349067026613031
(2, 9) 0.22769009319862868
(2, 8) 0.29938511033757165
(2, 4) 0.8981553310127149
(2, 1) 0.22769009319862868
--------------------------x_train_weight-----------------------
[[0.70710678 0. 0.70710678 0. 0. 0.
0. 0. 0. 0. ]
[0. 0.3349067 0. 0.44036207 0. 0.44036207
0.44036207 0.44036207 0. 0.3349067 ]
[0. 0.22769009 0. 0. 0.89815533 0.
0. 0. 0.29938511 0.22769009]]
---------------------------------------------------------------
输出x_train文本向量:
[[0.70710678 0. 0.70710678 0. 0. 0.
0. 0. 0. 0. ]
[0. 0.3349067 0. 0.44036207 0. 0.44036207
0.44036207 0.44036207 0. 0.3349067 ]
[0. 0.22769009 0. 0. 0.89815533 0.
0. 0. 0.29938511 0.22769009]]
输出x_test文本向量:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]]
3.5.Jieba实现TF-IDF算法
import jieba.analyse
text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
keywords=jieba.analyse.extract_tags(text, topK=20, withWeight=False, allowPOS=())
print(keywords)
注:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本。
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight为是否一并返回关键词权重值,默认值为False
- allowPOS仅包括指定词性的词,默认为空,即不筛选
3.6.TF-IDF算法的不足
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词, 十分有效地反映单词的重要程度和特征词的分布情 况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
TF-IDF算法实现简单快速,但是仍有许多不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
3.7.TF-IDF算法改进—TF-IWF算法
https://pdf.hanspub.org//CSA20130100000_81882762.pdf
以上是关于TF-IDF 算法的主要内容,如果未能解决你的问题,请参考以下文章