impala set设置之NUM_NODES
Posted cclovezbf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了impala set设置之NUM_NODES相关的知识,希望对你有一定的参考价值。
如何使用Impala合并小文件_Hadoop实操的技术博客_51CTO博客
起因是看到这篇文章。
还是以这个sql为例
select count(1)
from odserpjdata_kd.gl_code_combinations gcc, -- 1E
odserpjdata_kd.gl_balances gb -- 1000w
where gb.code_combination_id=gcc.code_combination_id --3000w
直接explain sql

set NUM_NODES=1;
explain sql
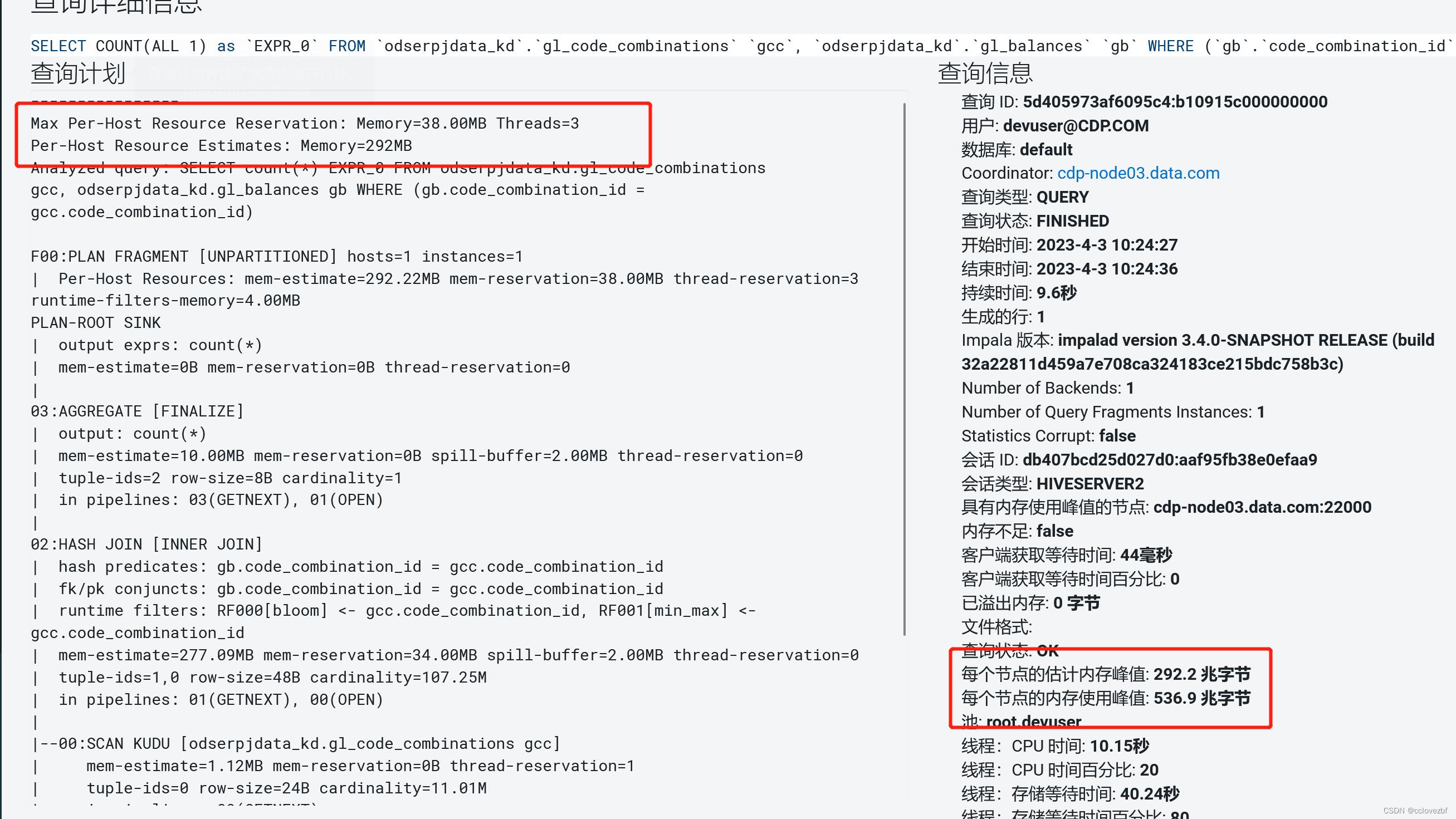 可以看到单节点的时候,所需要的内存变大了。
可以看到单节点的时候,所需要的内存变大了。
到clouder manager里看 查询时间变长,但是内存这块对于单节点负荷肯定变大

----------------------------------------------------------------------------------
看看官方文档

1.限制在查询时使用的节点数,一般用于debug的时候。 注意2点,query和debug
2. =0代表所有节点,或者=1 代表协调节点 (我说我设置=3 =10 和没设置一样。。)
3. 一般是你怀疑由于分布式查询 出现了结果错误,就用这个模式debug下
4.直接点 set NUM_NODES=1 可以减少小文件!!!
5.少用。因为单节点占用内存多,会直接和其他分布式sql查询 抢夺资源,导致其他查询慢。
-----至于小文件
impala find_in_set 与性能对比
【中文标题】impala find_in_set 与性能对比【英文标题】:impala find_in_set vs in performance 【发布时间】:2018-11-02 12:58:57 【问题描述】:谁能告诉我 find_in_set() 和 in() 哪个性能更好?
SELECT a.data_date,
lower(substr (a.cookie_id,-3,1)) cookie_type,
CASE WHEN find_in_set (lower(substr (a.cookie_id,-3,1)),'2,3,5,6,8,b,c,d') > 0 THEN 'A' ELSE 'B'END 'AB',
COUNT(a.cookie_id)
FROM dw.dw_cookie_dau_visit a,
WHERE a.data_date = '20181102'
AND a.site_id = 600
AND lower(substr(a.cookie_id,-1,1)) NOT IN ('e','f')
AND lower(substr(a.cookie_id,-3,1)) IN ('0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f')
GROUP BY a.data_date,cookie_type,AB;
SELECT a.data_date,
lower(substr (a.cookie_id,-3,1)) cookie_type,
CASE WHEN lower(substr (a.cookie_id,-3,1) in ('2', '3', '5', '6', '8', 'b', 'c', 'd') THEN 'A' ELSE 'B'END 'AB',
COUNT(a.cookie_id)
FROM dw.dw_cookie_dau_visit a,
WHERE a.data_date = '20181102'
AND a.site_id = 600
AND lower(substr(a.cookie_id,-1,1)) NOT IN ('e','f')
AND lower(substr(a.cookie_id,-3,1)) IN ('0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f')
GROUP BY a.data_date,cookie_type,AB
我应该选择哪一个?
【问题讨论】:
【参考方案1】:他们不做同样的事情。第二个版本应该是:
(CASE WHEN lower(substr(a.cookie_id, -3, 1) in ('2', '3', '5', '6', '8', 'b', 'c', 'd') THEN 'A' ELSE 'B' END) as AB,
在我看来,这是编写逻辑的更好方法,因为它为此目的使用了特定的 SQL 操作数。
至于性能,这无关紧要。查询的性能更多地取决于from 和group by 子句,而不是select 中的case 表达式。
【讨论】:
以上是关于impala set设置之NUM_NODES的主要内容,如果未能解决你的问题,请参考以下文章