数据统计学习的5个基本流程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据统计学习的5个基本流程相关的知识,希望对你有一定的参考价值。
数据统计学习的5个基本流程统计学、大数据应用很广泛,常常被提及!统计学习也有一定的规律流程,下面我们大圣众包小编分享一位朋友关于统
参考技术A 数据统计学习的5个基本流程统计学、大数据应用很广泛,常常被提及!统计学习也有一定的规律流程,下面我们大圣众包小编分享一位朋友关于统计学习流程步骤的看法,看看他怎么说。
统计学习现在市面上谈论到的数据挖掘基本上都是基于统计学习的监督学习或非监督学习问题。尤其以监督学习应用面更广。
统计学习的一般流程
得到一个有限的数据集合
确定所有的学习模型集合
确定模型选择的准则,就是学习的策略
实现求解最优模型的算法并通过学习方法选择最优模型
利用学习得到的最优模型对新数据进行分析或预测
步骤一:得到一个有限的数据集合
涉及到以下多个流程:
1、数据的采集
2、原始数据的格式化、标准化
3、原始去噪,去掉错误的值(而不是误差值,这里又涉及到一个复杂的问题,如何界定错误数据)
4、预处理(针对具体需要研究的问题、抽取相应地特征组成需要研究的数据集合)
步骤二:确定所有的学习模型集合
这个问题取决于我们选择怎么样的学习方法。常见得学习方法有:
1、感知机模型
2、k近邻法
3、朴素贝叶斯法
4、决策树
5、逻辑斯谛回归和最大熵模型
6、支持向量机
7、提升方法AdaBoost
8、EM算法
9、隐马尔可夫模型
10、条件随机场
而且这些算法还可以进行变异、组合然后形成新的算法模型。也是通常认为中数据挖掘比较核心的部分。
步骤三:确定模型选择的策略
一般来说,当你确定了你的学习方法后,在学习的过程中会产生很多个模型。而如何在这些模型中间挑选最优的模型,成为了我们亟待解决的问题。
一般衡量一个模型的优秀程度我们使用两个指标:
1、拟合能力
2、泛化能力
拟合能力
表示模型的计算结果和实际结果的相差程度,我们一般使用风险函数来衡量。而风险函数是损失函数的期望。所以我们其实是使用损失函数来衡量一个模型的期望。
常见的损失函数:
1、0-1损失函数
2、平分损失函数
3、绝对值损失函数
4、对数损失函数
损失函数越小,模型的拟合能力就越好。
泛化能力泛化能力是指模型对新数据的预测能力。一般来说,越复杂的模型的拟合能力越强,但是泛化能力越弱。所以我们需要选择一个适当复杂度的模型,使其泛化能力和拟合能力都足够强。
而衡量一个模型同时具有较好地泛化能力和拟合能力,我们一般用结构风险函数。
结构风险函数是在风险函数的基础上面加上一个罚项。通过罚项来降低复杂度高的模型的结构风险函数值。从而达到筛选出合适的复杂度的模型的目的。
罚项一般取特征空间w的范数,一般有:
1、L0范数
2、L1范数
3、L2范数
4、核范数…
步骤四:实现求解最优模型的算法并通过学习方法选择最优模型
求解最优模型的算法其实就是求解结构风险函数最小值得算法,即结构风险函数最优化的问题。
如果结构风险函数在我们所关心的区域中是凸函数的话,那么任何局部最小解也是全局最优解。现在已经有稳定,快速的数值计算方法来求二次可微地凸函数的最小值。
然而,很多时候我们没有办法通过结构风险函数直接算出它的最小值。我们只能通过一些迭代的方式获得局部最优解。
常见的通过迭代的方式获得局部最优解的算法有:
1、梯度下降法
2、牛顿法
3、共轭梯度法
4、线性搜索
5、置信域方法
另外还有一些算法:
1、模拟退火
2、遗传算法
3、类免疫算法
4、演化策略
5、差异演化算法
6、微粒群算法
7、神经网络
8、支持向量机
步骤五:利用学习得到的最优模型对新数据进行分析或预测
到这一步一般来说已经成功了,然后往往现实是残酷的,辛辛苦苦20年,一朝回到解放前。
往往学习得到的模型在实际使用过程当中并不是那么的理想。这里面有很多种原因:
有可能是原始数据的原因
有可能是特征选择的原因
有可能是模型的原因
有可能是最优模型算法的问题
有可能是代码错误
总之,以上的所有步骤的所有细节都可能导致你的模型不够优秀。这就需要你再次的思考这个问题,去不断的优化你的模型。直到得到一个不错的模型。
小结
其实数据挖掘涉及的东西远比我上面说的这点东西多的多,我上面提到的还只是监督学习。就光我上面提到的几个步骤。其实每一个步骤都有很多很多东西可以讲,可以研究,工程方面的、算法理论方面的等等等等。
一入数据挖掘深似海,从此奋斗到天明。
数据挖掘还是很有意思的,你可以用机器的力量、数学的力量理解世界的运行规律。去预测他或者利用你研究到的东西做一些有意思的事情。
机器学习项目流程
机器学习项目流程
在这我们会从头开始做一个机器学习项目,向大家展示一个机器学习项目的一个基本流程与方法。一个机器学习主要分为以下几个步骤:
- 从整体上了解项目
- 获取数据
- 发现并可视化数据,以深入了解数据
- 为机器学习算法准备数据
- 选择模型并训练
- 模型调优
- 展示解决方案
- 部署、监控、以及维护我们的系统
我们不会遍历所有步骤,仅从一个例子展示一个常规的流程。
使用真实数据
在学习机器学习时,最好是使用真实数据,不要用人工代码生成的模拟数据。一些可以获取数据的地方如:
- 开放数据集
- UC Irvine Machine Learning Repository
- Kaggle 数据集
- Aamzon AWS 数据集
- 提供收集的数据集
- Data Portals
- OpenDataMonitor
- Quandl
- 其他列出开放数据集的网站
- Wikipedia 的机器学习数据集
- Quora.com
- Subreddit 数据集
在这章我我们会使用California Housing Prices 数据集,数据来源为StatLib。这个数据集基于的是1990年加州人口普查数据。数据地址如下:
https://github.com/ageron/handson-ml2/blob/master/datasets/housing/housing.tgz
查看数据结构
下载数据后,我们首先使用pandas 读取数据,并简单地查看一下数据的结构:
import pandas as pd def load_housing_data(housing_path=HOUSING_PATH): csv_path = os.path.join(housing_path, "housing.csv") return pd.read_csv(csv_path) housing = load_housing_data()
housing.head()

可以看到这个数据集一共有10个属性,以及各个属性的数据类型。下面可以使用 info() 方法查看一下数据集的描述:
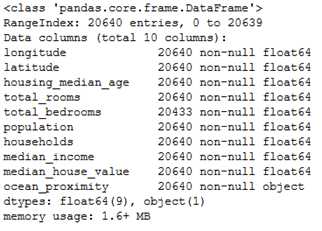
housing.info()

此方法打印出了数据的总行数为 20640,各个属性的数值类型,以及非空的数值(non-null)数目。20640行意味着这个是一个很小的数据集,而其中尤其要注意的是:total_bedrooms 的行数仅有20433,小于20640。说明有207条数据缺失这个值。
在10条属性中,有9条均为 float64 类型,仅有ocean_proximity 的属性为 object 类型。在 python 中,object 类型可以代表任何对象。由于我们已知数据是从csv读入的,所以此属性的类型应为文本(text)类型。通过head() 方法查看前五条数据,可以看到这个属性的取值均为“NEAR BAY”,所以可以大致推断这个属性的值类型为离散型的属性。对于离散型属性取值,我们可以通过value_counts()的方法查看离散值的统计信息,以及有多少条目属于某个取值:
housing[‘ocean_proximity‘].value_counts()
继续查看其它属性,describe() 方法可以打印出数值型属性的统计数据:
housing.describe()
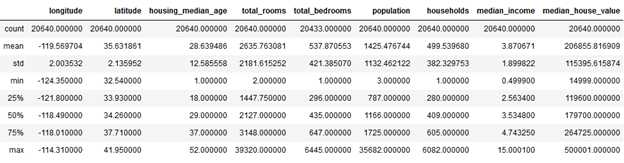
count指标表示的是条目数(空置已被忽略,所以total_bedrooms 的count数较小),mean是平均数,std是标准差(衡量的是数据的离散程度)。25% - 75% 分别是分位数。
另一个快速了解数据的方式是给数值型属性画一个直方图,直方图可以给出属性在某个取值范围内的个数。我们可以每次画出一个属性的直方图,或是在数据集上调用hist() 方法,此方法会为每个数值型属性画出它的直方图。
%matplotlib inline import matplotlib.pyplot as plt housing.hist(bins=50, figsize=(20, 15))
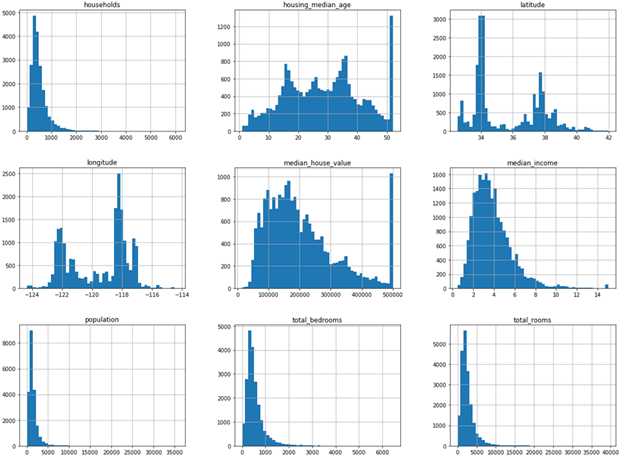
在这些直方图中,我们需要注意以下几点:
- 首先,median_income 的取值看起来并不像是美元的值,因为它的取值是从0.4999 到 15.000100,不符合我们对工资单位的认知。这是因为这个属性的取值被缩放了,所以 3 对应的应为 $30,000。同时,这个属性也被设定了上限(即15.0001)。所以在机器学习项目中,一定要了解每个属性的取值是如何计算得来的,这样我们会对数据有更清楚的认知。
- housing_median_age 以及median_house_value 都被设定了上限。对median_house_value 设置上限造成的影响可能会更大,因为这个是我们的目标属性(也就是label)。我们的机器学习模型可能会学习到:房间永远不会超过它的上限值(500001.000000)。在这种情况下,我们需要跟需求方进行沟通,需要了解这个上限对于他们来说是否是一个问题。如果他们回复说模型需要做到非常精准的预测,即使是超过$500,000 的值也是需要的,则我们接下来有以下两种方法:
- 收集原始信息,也就是这些label 在被设定上限前的数据
- 从训练数据中移除掉这些数据(同时在测试数据中也不能使用这些数据)
- 这些数值型属性的取值都处于不同的范围,需要将它们进行规范化
- 最后,很多直方图都是重尾分布:中值的右边拖的很长,而左边较短。这种分布会增加一些机器学习算法在进行模式识别时的难度。我们需要之后转化这些属性,尽量量它们的分布转为钟形分布
到现在为止,希望读者对我们要处理的数据已经有了更进一步的了解。
创建测试集
测试集在机器学习方法中用于判断模型的准确度,一般我们会从原始数据集中随机选择20%的数据作为测试集,并将它们刨除在训练集之外:
import numpy as np def split_train_test(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices] train_set, test_set = split_train_test(housing, 0.2)
这个方法是随机从数据集中取20%的数据作为测试数据。但是这个其实是有问题的,因为在多轮次训练中,若是每次均通过随机取数据条目,则最终所有数据条目都有机会被放入到训练数据中,而这也正是违背了我们最开始的初衷 —— 测试数据仅用于验证模型精准度,而不能用于模型训练。
对此,其中一个办法是:在调用 np.random.permutation() 前,为随机数加一个种子参数,如 np.random.seed(42)。这样可以保证每次获取的shufle_indices 都是一样的。另一个更简单的办法是在第一次执行时就将测试数据保存,之后在使用时再加载。
然而,以上两种方式仍有缺陷。假设我们原有数据集做了更新,增加了新的数据条目,则以上两种方法均未顾及到这点。所以一个更常规的解决方法是:使用每条数据的标识符来决定是否将此条目放入测试集(假设每条数据都有一个唯一、不可变的标识符)。例如,我们可以计算每条数据的标识符的哈希值,并将哈希值小于或等于(最大哈希值×20%)的条目放入测试集。这样可以确保在多次运行后,测试集仍保持一致。即使在之后添加了新的数据条目,测试集中的数据仍为整体数据集的20%,且不会包含任何曾经属于过训练集的数据条目。下面是一个实现:
from zlib import crc32 def test_set_check(identifier, test_ratio): return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32 def split_train_test_by_id(data, test_ratio, id_column): ids = data[id_column] in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) return data.loc[~in_test_set], data.loc[in_test_set]
第一个方法是判断是否属于最大哈希值的 20%,第二个方法是根据哈希值的大小取出训练集与测试集。
接下来的问题是:housing 数据及没有一个标识符的列。所以一个简单的办法是:直接使用条目的index 作为 ID:
housing_with_id = housing.reset_index() # add an ‘index‘ column train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, ‘index‘) len(train_set) 16512 len(test_set) 4128
但是这个方法依然有它的局限性,因为我们必须确保新加入的数据集的 index id 是以追加的方式加入到此数据集的,并且在原数据集中不能有任何条目被删除,否则就对 index id 的顺序造成了干扰。如果以上两者均无法在实际应用中达成,则我们可以尝试用其他更稳定的属性去构造一个标识符。例如,一个地区的经度与纬度理论上来说是一个稳定值,所以我们可以使用这两个属性longitude 以及 latitude 去构造一个 ID,例如:
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"] train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id") print(len(train_set), len(test_set)) 16322 4318
SciKit-Learn 库提供了几个方法,可以使用不同的方式将数据集划分为多个子集。最简单的方法为train_test_split(),这个方法与此文中定义的split_train_test() 方法基本一致,但是会提供更多的功能。首先可以提供一个 random_state 参数,用于指定随机种子,然后我们可以传入多个数据集(它们的行数相同),并将它们分割为相同的索引列表。这个功能是非常有用的,比如我们有一个DataFrame 是训练集,但是它的label却在另一个DataFrame中,这样就可以使用这个方法同时将它们分割成相同的索引列。此方法的使用例子为:
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
到目前为止,我们已经有了一个完全随机的数据采样方法。如果数据集足够大(相对于属性的数目来说),则这个随机采样法就足够用了,但是如果数据集不够大(特别是数据属性较多时),则此种采样方法可能会引入较大的采样偏差。我们举个例子,在一家调查公司进行电话访问时,决定随机选取 1000 个人进行电话采访。他们希望这1000个人能代表整个国家的意见,那么就必须考虑到构成整个国家的人口的差异。例如,假设这个国家里男性占 55%,女性占45%。则在执行采样时,这1000 个人中的男女比例也应为 11:9,也就是分别为550 人与 450 人。这种方式称为“分层采样”:人口的数据被分为多个同样类别组成的子集,称为“层”。所以在采样时,需要按比例从各层中采样,才能代表总体的数据。
假设这里我们有个专家告诉我们,median_income 是一个非常重要的指标,它与预估房价的关系非常紧密。那这里我们可能就需要确保:测试集里的数据能代表整个数据集中的各个不同收入范围样本。由于 median_income 是一个连续性的数值型属性,所以我们首先要创建一个income 的类别属性。我们再回顾一下 median_income 的直方图:
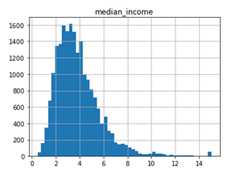
可以看到大部分median_income 的值集中在1.5 到6(也就是 $15,000 - $60,000)之间,但是直到 6 之后很远的地方(如15),仍有数据点。在采样中很重要的一点是:在每个“分层“中,都要采集足够的样本,否则每个层的重要性可能就存在偏差。也就是说,我们不能有太多的层,并且每层也应该足够大。下面的代码我们使用了 pd.cut() 方法,用于创建一个新的income 类别属性(包含5个类别,label 从1到5):类别1为0到1.5(也就是小于$15,000),类别2从1.5到3,依次类推:
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5])

可以看到每条数据的 income_cat 属性均填写了归于哪一类。
housing["income_cat"].hist()
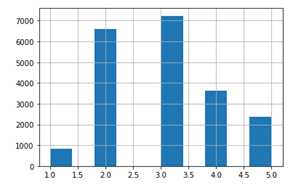
现在我们可以根据income的类别,开始做分层采样。对此,可以使用Scikit-Learn 的StratifiedShuffleSplit 类:
from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index]
检查一下结果:
strat_test_set[‘income_cat‘].value_counts() / len(strat_test_set)
3 0.350533
2 0.318798
4 0.176357
5 0.114583
1 0.039729
Name: income_cat, dtype: float64
也可以看看直方图:
start_test_set[‘income_cat‘].hist()
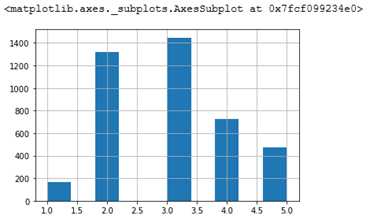
可以看到采样出来的 test 集合中,income_cat的分布与原始集合基本是一致的。
现在我们有了一个 test 的采样集合后,就可以去掉income_cat 的属性了,让数据回归原始状态:
for set_ in (strat_test_set, strat_train_set):
set_.drop("income_cat", axis=1, inplace=True)
至此,我们总结一下当前的工作:
- 获取数据集
- 查看数据结构,进一步了解数据集的属性
- 根据分层采样分割出测试集
下一步我们会继续探索、可视化数据集。
以上是关于数据统计学习的5个基本流程的主要内容,如果未能解决你的问题,请参考以下文章