数据中台架构PaaS层(平台服务层)之实时存储资源规划与架构设计
Posted 随缘清风殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据中台架构PaaS层(平台服务层)之实时存储资源规划与架构设计相关的知识,希望对你有一定的参考价值。
1、Kafka高可用设计
1.1、Kafka服务端高可用设计
- 高可用:leader挂了会通过Zookeeper重新选举,不存在单点故障问题
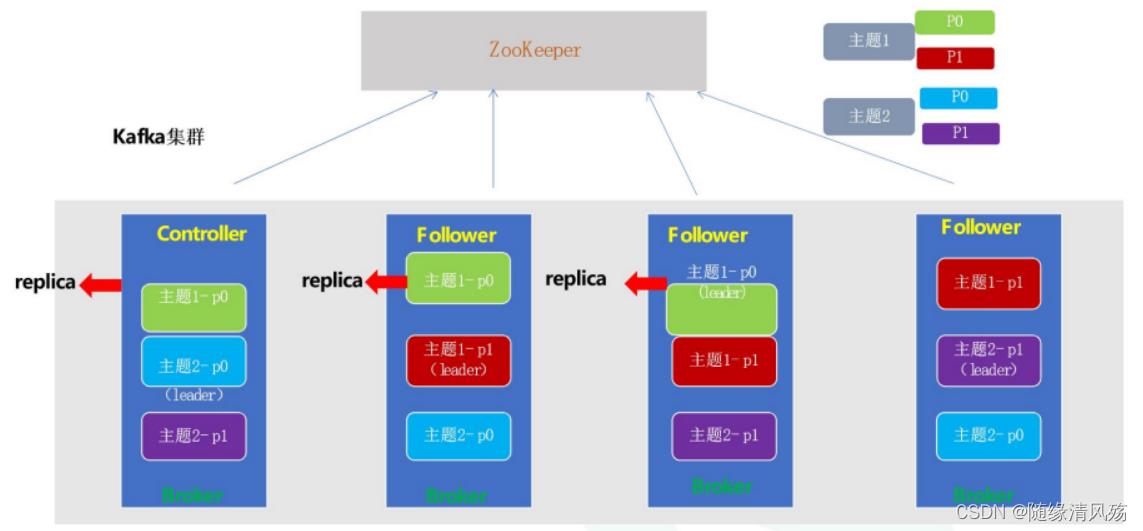
- Controller:负责各partition的Leader选举一级Replica的重新分配
kafka让所有的Broker都在Zookeeper的Controller节点注册一个Watcher,当Controller发生故障时对应的Controller临时节点会自动删除,此时注册在其上的Watcher会被触发,让所有活着的Broker都会区竞争成为新的Controller,竞选成功者即为Controller。
1.2、kafka服务端高并发设计
(1)同步顺序处理:每个请求必须等待前一个请求处理完了以后才会得到处理,吞吐量太差!

while(true)
Request request=accept(connection);
handle(request);
缺点:
-
①并发低:所有的处理放在一个线程里,这个线程压力很大,网络IO的处理总是要比CPU慢的多;
-
②网络延迟很大:如果这里有一个客户端的请求,处理比较复杂则会影响后面其他客户端的请求响应能力;
(2)半异步半同步编程:
- T1线程
while(1)
epoll_wait(...);
for()
if(fd == listenner_socket)
cfd=accpt(listenner_socket);
else
read(fd,buf,size);
enqueue(buf);
- T2线程
while(1)
wait_queue(buf);
process(buf);
- 缺点
- ①线程间需要同步;
- ②线程间有数据的拷贝(memcpy),这个拷贝也是很耗CPU
(3)异步处理:每个请求都创建一个线程去处理,请求不会阻塞,但是每个请求都创建一个线程开销太大
while(true)
Request request=accept(connection);
Thread thread = new Thread(handle(request));
thread.start();
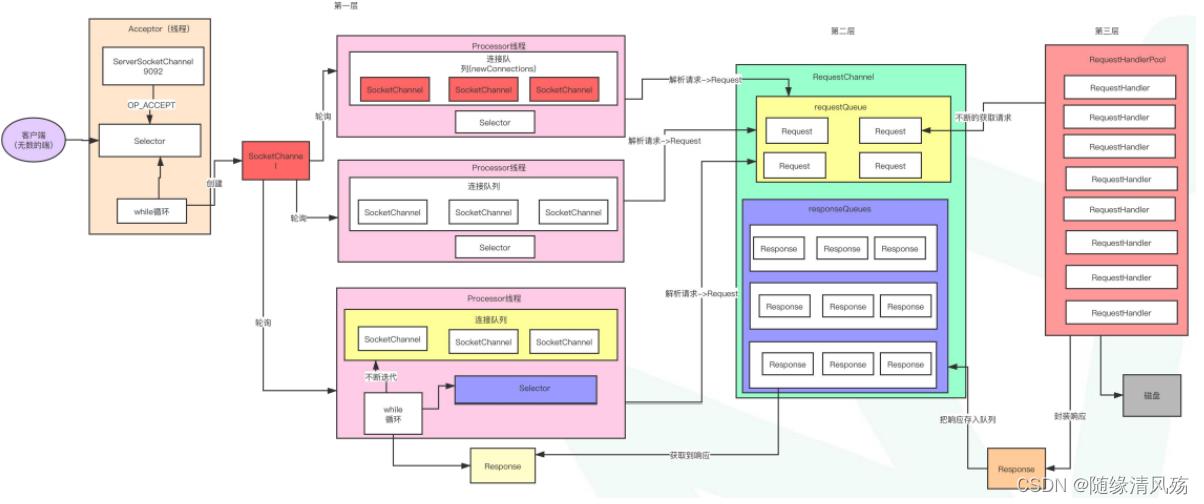
(4)Reactor设计模式:引入NIO多路复用,高并发保证
- 架构概要设计:
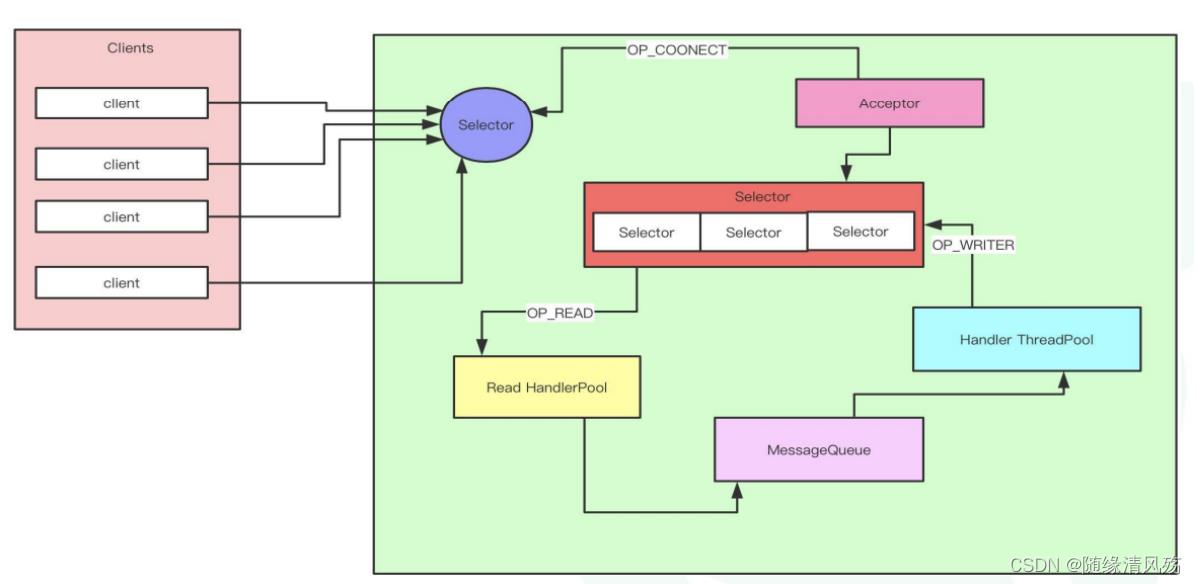
- 架构详细设计:

-
注意事项:
-
第一层:对应Read HandlePool,线程数默认num.network.threads=3,如果想提高性能则可调大参数增加线程个数
-
第二层:对应MessageQueue
-
第三层:对应Handler ThreadPool,线程数默认num.io.threads=8,如果想提供性能则可调大参数增加线程个数,最好不高于CPU个数。
每个线程:2000QPS 8个线程:2000QPS=1.6wQPS -
①客户端发送请求到服务端;
②服务端由acceptor线程监听客户端请求,如果请求到来会将其封装为SocketChannel;
③SocketChannel被发送到线程池,按照轮询的方式将其线程池的一个连接队列里面;
④SocketChannel注册OP_READ事件,真正接收到客户端发送过来的请求**,此时请求以为跨网络传输为二进制格式**;
⑤Processor线程解析请求将其封装为一个Request对象发送到RequestQueue,主要起到缓冲作用;
⑥RequestHandlerPool从RequestChannel中不断获取请求,通过工具类将数据写到磁盘;
⑦工具类封装响应结果,将Response存到ResponseQueue队列里面。
⑧Processor线程拉取Response,将其注册为OP_WRITE事件,并发送回客户端。
2、Kafka的高性能设计
2.1、Kafka的服务端高性能设计
2.1.1、数据写入高性能 - 顺序写磁盘
-
P:kafka将详细记录持久化到本地磁盘中,一般人会认为是磁盘的读写性能比较差,对kafka性能如何提出质疑。
-
A:不管是内存还是磁盘,快或慢关键在于寻址的方式。磁盘和内存都有顺序读写和随机读写,基于磁盘的顺序读写高出磁盘的随机读写三个量级,甚至高于内存随机读写。
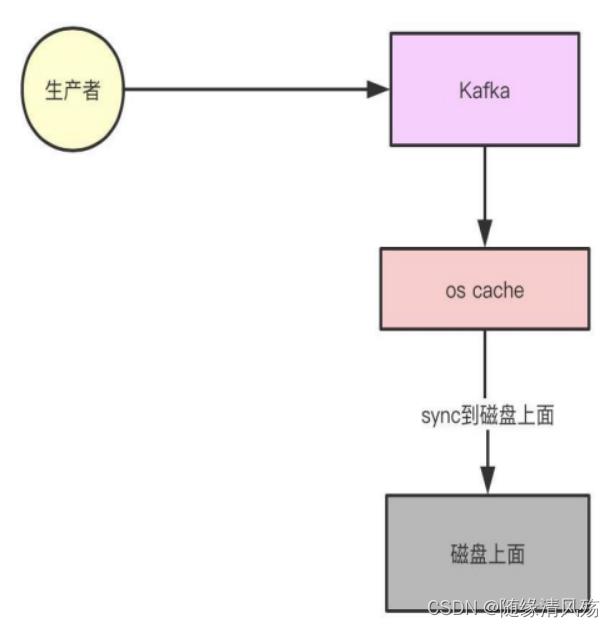
- 注意事项:kafka不断将数据写入到os cache中达到一定阈值批量顺序写磁盘。
2.1.2、数据读取高性能 - 索引文件
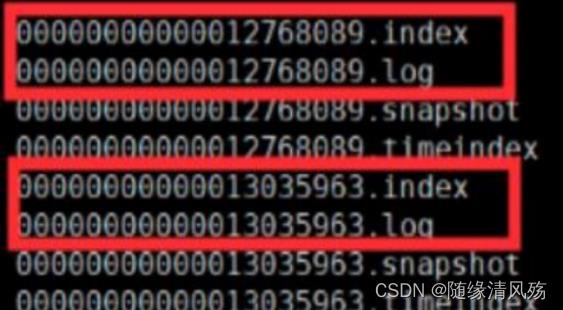
- kafka的文件存储:
- ①log文件:里面存储的是消息数据,文件名以log文件中的第一条消息的offset命名的。
- ②index文件:里面存储的是索引信息
Ⅰ、跳表设计:快速定位消息所在文件位置
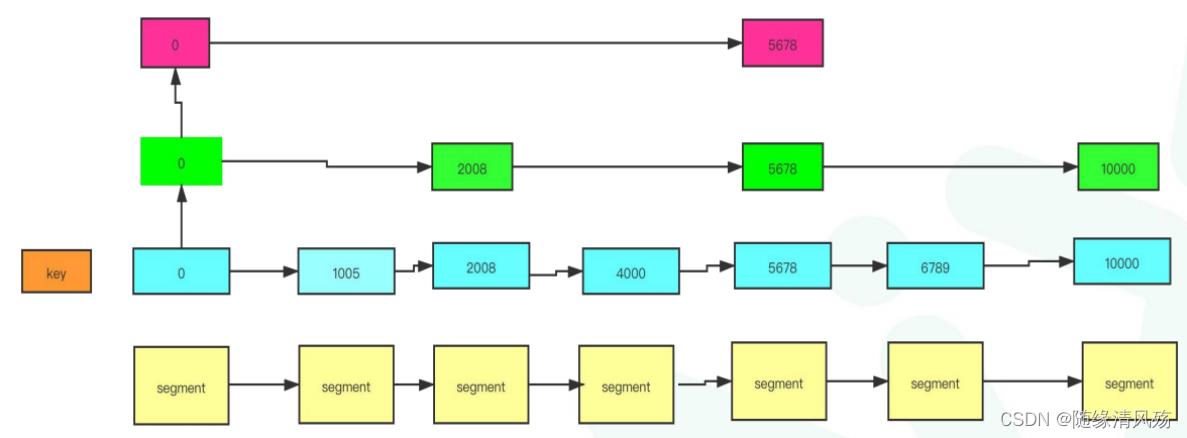
- P:快速找到offset=5000的消息
- A:跳表设计,构建多级索引,快速定位文件位置,以空间换时间。
Ⅱ、稀松索引:快速定位文件中的消息位置
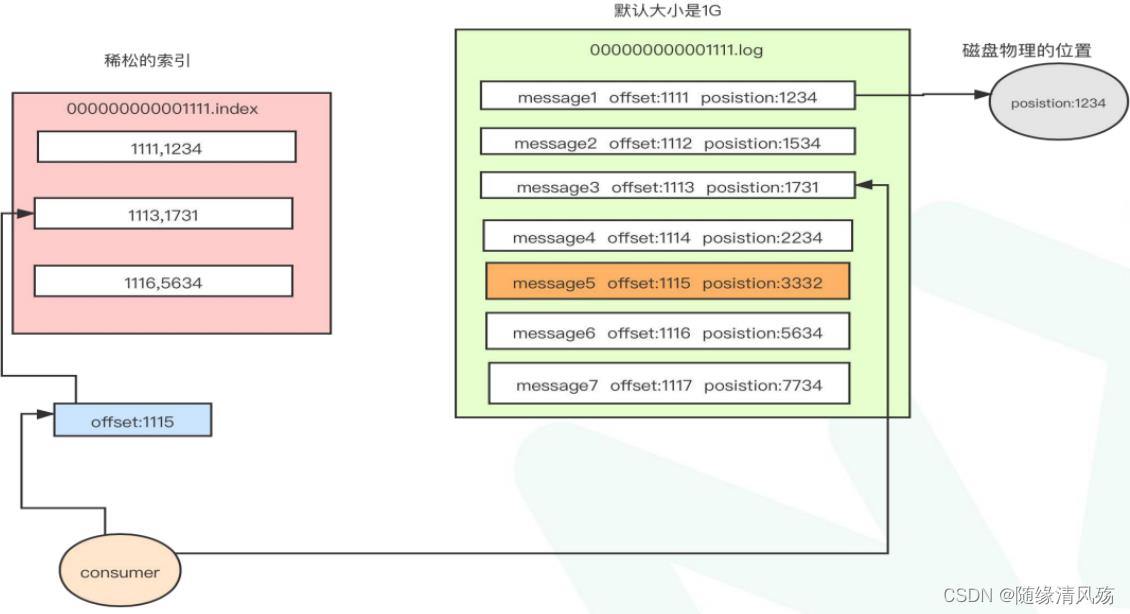
- P:如何在已定位的文件中快速找到消息位置
- A:稀疏索引(index文件),消息位置对应磁盘位置,,每隔4kb数据在index文件中记录下偏移量+物理磁盘位置。
业务场景:查找offset=1115的消息,首先在index文件中定位offset=1113的物理磁盘位置,之后顺序扫描1731之后的物理磁盘找到offset=1115的消息。
Ⅲ、零拷贝:

- 传统读取数据并发场景:
- ①操作系统将数据从磁盘文件中读取到内核空间的页面进行缓存;
- ②第一次拷贝:应用程序将数据从内核空间读入用户空间缓冲区;
- ③第二次拷贝:应用程序将读到的数据写回到内核空间并放入socket缓冲区;
- ④操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络进行发送。
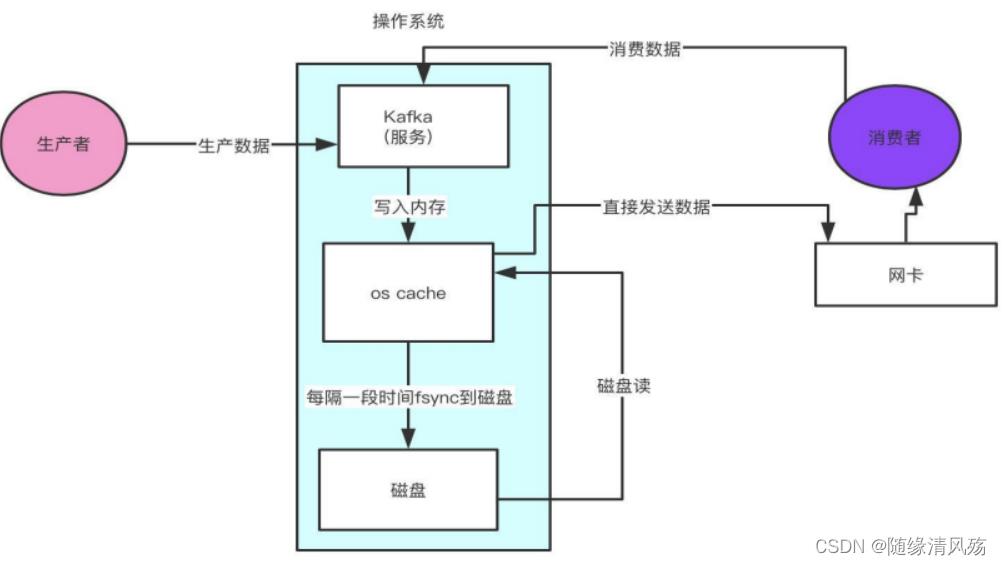
零拷贝技术只用将磁盘文件的数据复制到系统缓冲区一次,然后将数据从页面的缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面进行缓存),避免了重复复制操作。
- 零拷贝场景:如果有10个消费者,传统方式下数据复制次数为4 * 10 = 40 次,而是用零拷贝技术只需要复制1 + 10 = 11 次,其中一次为从磁盘复制到页面缓存,10 次表示10个消费者各自读取一次页面缓存,由此可以看出kafka的效率是非常高的。
2.2、kafka客户端高性能设计
2.2.1、批处理方案设计

①生产者发送消息请求,生产者将其封装为ProducerRecord对象
②将其序列化后请求broker获取集群元数据;
③根据partitionor分区算法确定将消息存储到topic的某个分区,确定好将消息发送到某台服务器上;
- 0.8以前就截至到这里:来一条消息发送一条请求,这种设计性能上会比较差,请求建立连接次数太多。
④将**消息先存入RecordAccumulator(缓存)**中
⑤Sender线程将多条消息封装成一个batch发送到服务器上
2.2.2、RecordAccumulator内存池方案设计
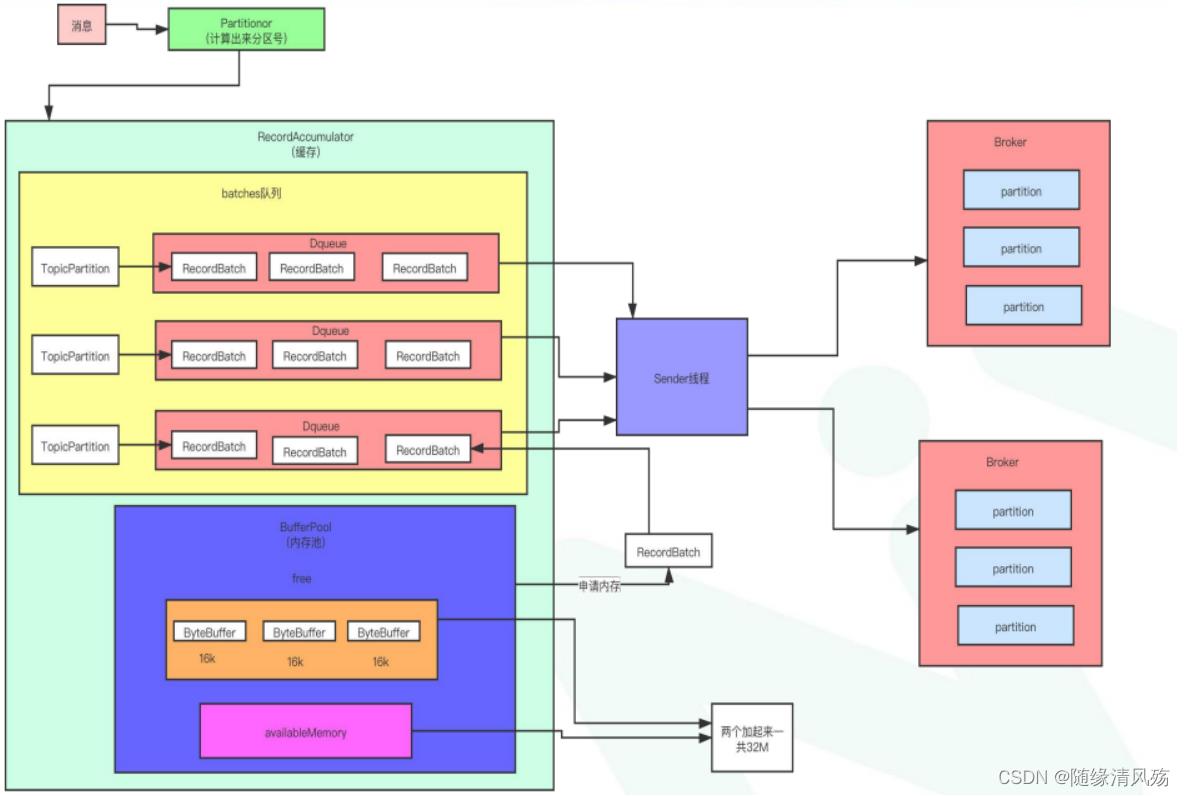
RecordAccumulator 会由业务线程写入,经过哈希/轮询等分区策略计算出分区号,最后写入到对应TopicPartition,在Batchs队列中写入到RecordBatch中,等到RecordBatch达到批处理阈值后,最后Sender 线程批量读取到Broker的partition中。
3、服务配置文件参数
(1)num.io.threads=8
- broker处理磁盘IO的线程数 :主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍.
(2)num.network.threads=3
- broker处理消息的最大线程数:主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1.
(3)log.dirs=/data/kafka-logs
- 生产环境下会有多个目录,一个目录对应一个磁盘
4、实时存储平台资源评估与架构设计
- 评估目标:平台每天hold住10亿请求
4.1、QPS设计
(1)二八法则定QPS
每天集群需要承载10亿数据请求,一天24小时,对于网站晚上12点到陵城8点这8个小时几乎没有多少数据。使用二八法则估计,也就是80%的数据(8亿)会在其余16个小时涌入,而且8亿的80%的数据(6.4亿)会在16个小时的20%时间(3个小时)涌入。
QPS计算公式=6.4亿÷(3*60*60)=6万,故高峰期集群需要抗住每秒6万的并发
(2)副本数量估算存储
每天10亿条数据,每天请求10kb,也就是9T的数据,如果保存3副本,9✖3=27T,保留最近5天的数据,故需保留27*5=135T数据。
存储资源=10kb*10亿*3副本*5天
(3)QPS评估
如果资源充足,让高峰期QPS控制在集群能承载的总QPS的30%左右,故集群能承载的总QPS为20w才是安全的,根据经验一台物理机能支持4万QPS是没问题的,所以从QPS的角度上讲,需要5台物理机,再考虑上消费者请求,增加1.5倍,需要7~8台服务器。
4.2、磁盘评估
(1)磁盘数据评估
7台物理机,需要存储135T的数据,每台存储11T的数据,一般也就是11块盘,一个盘2T,要做磁盘预留。
log.dirs=/data1,/data2,/data3,......
#多磁盘目录
(2)磁盘类型选择
SSD是固态硬盘,比机械硬盘要快,主要快在磁盘随机读写性能上。
kafka是顺序写磁盘,机械硬盘顺序写性能跟内存读取性能差不多,所以kafka集群使用机械硬盘就可以了。
4.3、内存评估
经过相关业务处理,此集群有100各topic,这100个topic的partition的数据在os cache里效果是最好的。100个topic,一个topic有9个partition,则总共会有900个partition,每个partition的Log文件大小是1G,我们有3个副本,也就是说要900个topic的artition数据都驻留在内存需要2700G的内存。
我们现在有7台服务器,所以平均下来每台服务器需要400G内存,但是其实partition的数据我们没必要所有的都要驻留在内存中,10~20%的数据在内存里就非常好了,400G*0.2=80G就可以了,kafka进程需要6G内存(并没有创建很多对象),所以需要86G内存,故我们可以挑选128G内存的服务器就非常够用了。
- 注意事项:kafka与实时结合读取最新数据,大概占比10~20%比例。
4.4、CPU评估
CPU规划主要看Kafka进程里面有多少线程,线程主要是依托多核CPU来执行的,如果线程特别多,但是CPU核很少就会导致CPU负载很高,会导致整体工作线程执行的效率不高。
- kafka进程中的线程个数:
- Acceptor线程:1个
- Processor线程:默认3个,一般设置为9个
- RequestHandle线程:默认8个,一般设置为32个
- 日志清理线程
- 感知Controller状态的线程
- 副本同步的线程
估算下来Kafka内部有接近100个线程
4个CPU core,一般来说几十个线程,在高峰期CPU几乎都快打满了,8个CPU core,也就能够比较宽裕的支撑几十个线程繁忙工作,所以Kakfa的服务器一般建议是16核,基本上可以hold住一两百线程的工作,当然如果给到32cpu core那就更好。
5、实时存储平台规划
- 总体规划:10亿写请求,6w/s的吞吐量,9T的数据,7台物理机
- 硬盘:11(SAS) 1T,7200转*
- 内存:128GB,JVM分配6G,剩余给os cache
- CPU:16核/32核
- 网络:万兆网卡更佳
6、实时存储平台架构设计
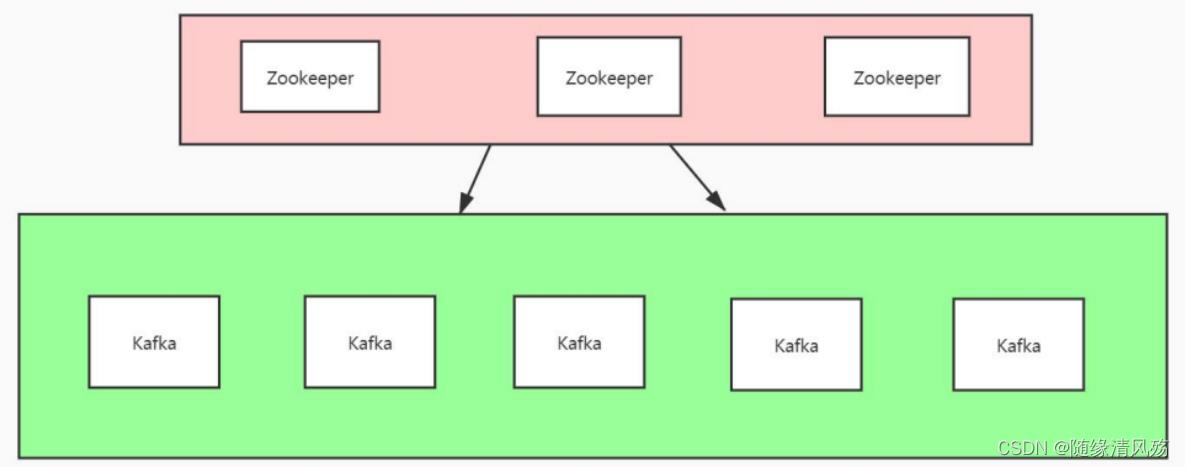
(1)Zookeeper服务器:3台
(2)Kafka服务器:台
- kafka集群和HDFS集群的zookeeper可共用,一般建议分开(除非资源遇到瓶颈)
- 风险点:zookeeper集群挂掉则两个服务都不可用
7、实时存储平台核心配置
7.1、日志保留策略配置优化
建议减少日志保留时间,建议三天或者更短时间。通过log.retention.hours来实现,例如设置:
log.retention.hours=72
7.2、段文件大小优化
段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快,相反,如果文件过小,则文件数量比较多,kafka启动 时是单线程扫描目录(log.dir)下所有数据文件,文件较多时性能会稍微降低。可通过如下选项配置段文件大小:
log.segment.bytes=1073741824
7.3、log数据文件刷盘策略优化
为了大幅度提高producer写入吞吐量,需要定期批量写文件 优化建议为:每当producer写入10000条消息时,刷数据到磁盘。可通过如下选项配置:
log.flush.interval.messages=10000
每间隔1秒钟时间,刷数据到磁盘。可通过如下选项配置:
log.flush.interval.ms=1000
7.4、提升并发处理能力
num.io.threads =8,num.network.threads =4
大数据中台架构以及建设全流程一(Paas层设计)
目录
实时存储平台----------->KAFKA(未来pulsar也不错)
设计背景
当企业发展到一定规模时候有了不同的业务线以及数据规模,因为业务的快速发展。这个时候一些数据问题就会出现。
问题点
1:数据脏乱差,各部门生产线数据重复冗余,还不可:复用用存在数据孤岛
2:数据开发部门的业务来自各部门各产品线,需求不明确,每天业务量繁复,日常工作可能成了sqlboy到处捞数据,而且在业务方面还没有业务部门了解的深入,有点缘木求鱼的意思。
这个时候数据中台也就应运而生。
中台目标
复用,赋能,降本增效
1:面向业务,数据进行建模。
2:数据整合避免烟囱式开发解决数据孤岛问题。
3:赋能给各个业务部门,将能力下放将数据的使用权限赋予各个部门,减少数据开发部门繁琐的数据sql业务。
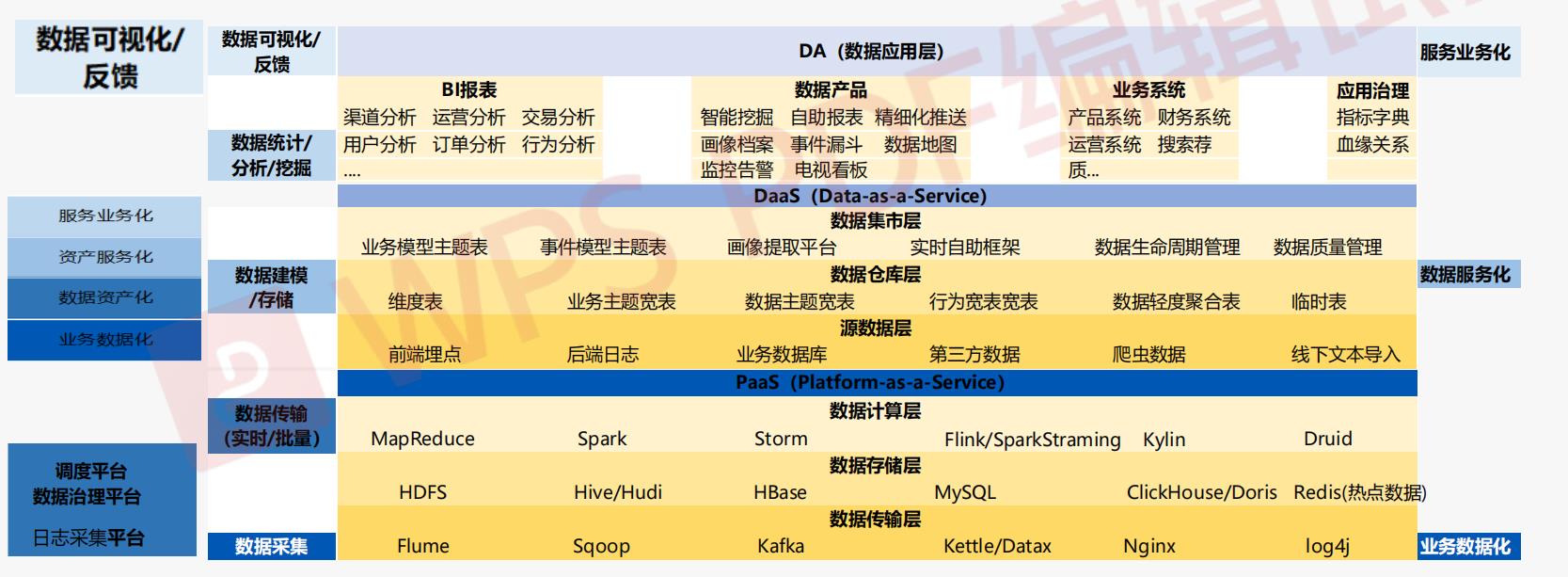
中台整体架构
Pass层技术选型
实时存储平台----------->KAFKA(未来pulsar也不错)
0.8版本标志着kafaka成熟
0.9版本提供了安全模块,偏移量也由zk转移到自己的topic进行管理了
0.10版本提供了流计算,生产者优化(提供了批次发送,默认16k发送一次),提供了机架感知
0.11版本生产者提供了幂等性和事物
1.x没啥特别优化
2.x优化stream,安全力度更细
所以0.11版本后都可以,版本太高也要考虑兼容性问题
tips:kafka因为内存是页存储,磁盘是顺序读写,因为顺序读写速度不亚于内存。所以kafka对于是内存还是磁盘需求不大
样例:假设平台每天接受一亿次实时请求,kafka如何hold住?
每天集群需要承载1亿数据请求,一天24小时,对于网站,晚上12点到凌晨8点这8个小时几乎没多少数据。使用 二八法 则估计,也就是80%的数据(8千万)会在其余16个小时涌入,而且8亿的80%的数据(6.4千万)会在这16个小时的20%时间 (3小时)涌入。 qps = 64000000/(3*60*60)= 6000,则高峰期每秒并发6000 每天1亿数据,每个请求10 kb ,也就是1T的数据。如果保存3副本,1 *3=3T, 假设kafka默认保留最近7天的数据。故需要 3 * 7 =21T tips (默认时间可以根据资源需求降低) 一个集群高峰期肯定还有很多其他业务要处理,所以高峰期的qps要控制在集群能承受的百分之30左右,所以集群能承受的总的qps在2w左右。一般来说一台物理机能承受的qps在4w左右。再加上消费者请求3三台左右就比较理想,而且kafka一般都是集群的3台起步。所以很合适。 磁盘:三台物理机需要存储21T数据,则每台7块磁盘,每个磁盘1T就可以了。tips(最好配置上kafka 的log.dir避免数据全部写到一个磁盘导致性能变差。且linux对磁盘目录数有个数限制,太多会导致有空间但是写不进去) kafka磁盘类型选择: SSD固态硬盘or普通SAS机械硬盘? SSD就是固态硬盘,比机械硬盘要快,SSD的快主要是快在磁盘随机读写 Kafka是顺序写的,机械硬盘顺序写的性能机会跟内存读写的性能是差不多的。所以对于Kafka集群使用机械硬盘就可以了。 QPS计算公式= 64qps0000000÷(3*60*60)=6万,故高峰期集群需要要抗住每秒6万的并发
64qps0000000÷(3*60*60)=6万,故高峰期集群需要要抗住每秒6万的并发
内存:假如一个集群有3个topic,这3个topic的partition的数据在os cache里效果当然是最好的。3个topic,一个topic有假如30个partition。那么 总共会有90个partition。每个partition的Log文件大小是1G,我们有 3个副本,也就是说要把90个topic的partition数据都驻留在内存里需 要270G的内存。我们现在有3台服务器,所以平均下来每天服务器需 要90G的内存,但是其实partition的数据我们没必要所有的都要驻留 在内存里面,10-20%的数据在内存就非常好了,90G * 0.2 = 18G就 可以了。所以64g内存的服务 器也非常够用了。
cpu:主要是看Kafka进程里会有多少个线程,线程主要是依托多核CPU来执行的,如果线程特别多,但是 CPU核很少,就会导致CPU负载很高,会导致整体工作线程执行的效率不太高。 来Kafka内部有100多个线程,4个cpu core,一般来说几十个线程,在高峰期CPU几乎都快打满了。8个cpu ,能够比较宽裕的 支撑几十个线程繁忙的工作。所以Kafka的服务器一般是建议16核,基本上可以hold住一两百线程的工作。当然如果可以给到32 cpu 那就更加的宽裕。
网卡:
1亿写请求,6000/s的吞吐量,3T的数据,3台物理机 硬盘:7(SAS) * 1T,7200转 内存:64GB,JVM分配6G,剩余的给os cache CPU:16核/32核 网络:万兆网卡更佳 核心配置: 日志保留策略配置优化 建议减少日志保留时间,通过log.retention.hours来实现,例如设置 log.retention.hours=72, 根据实际需求调整,默认是七天 。 段文件大小优化 段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快,相反,如果文件过小,则文件数量比较多,kafka启动 时是单线程扫描目录(log.dir)下所有数据文件),文件较多时性能会稍微降低。可通过如下选项配置段文件大小: log.segment.bytes=1073741824 log数据文件刷盘策略优化 为了大幅度提高producer写入吞吐量,需要定期批量写文件 优化建议为:每当producer写入10000条消息时,刷数据到磁盘。可通过如下选项配置: log.flush.interval.messages=10000 每间隔1秒钟时间,刷数据到磁盘。可通过如下选项配置: log.flush.interval.ms=1000 提升并发处理能力 num.io.threads =8,num.network.threads =3(均为默认值,自己根据实际情况调整)离线存储平台(Hadoop系列)
Hadoop选型
1:Apache社区版本
a:开源,免费
b:更新快,新特性多
c: Bug多,需考虑各组件兼容性
2:Cloudera
a:分开源,免费版本。目前都要收费了
b:稳定,不需要考虑兼容性问题
c:有clouderaManager管理工具可视化界面很友好
d: 版本因为稳定,更新慢。新特性尝鲜少。且收费(!这点估计很多都不会选择)
3:Hortonworks
a:万全开源免费
b:稳定,不需要考虑兼容性问题
c:有集群管理工具可视化界面很友好
d: 流行度不高
TIPS:
1.x 稳定版本
2.0支持高可用,支持联邦
2.7x流行度广比较稳定,建议2.7.5以后
3.x HA支持多个namenode,增加纠删码功能。可以减少副本,文件块里面存了一部分压缩元数据,另外一部分用于存储校验数据可以用于数据恢复。就可以减少副本存储数。当然也可以多副本和纠删码同时开启。但是缺乏数据本地性问题
机架感知
机架感知就是自动了解hadoop集群中每个机器节点所属的机架,某个datanode节点是属于哪个机柜并非是智能感知的,而是需要hadoop的管理者人为的告知hadoop哪台机器属于哪个机柜,这样在hadoop的Namenode启动初始化时,会将这些机器与机柜的对应信息保存在内存中,用来作为HDFS写数据块操作分配Datanode列表时(比如3个 block对应三台datanode)选择DataNode的策略,比如,要写三个数据块到对应的三台datanode,那么通过机架感知策略,可以尽量将三个副本分布到不同的机柜上。这个需要运维配合设置。硬件选型(PB级)
cpu:推荐4路32核等,主频至少2-2.5GHz
内存:推荐64-256GB
磁盘:分为2组,系统盘和数据盘,系统盘2T*2,做raid1,数据盘2-10T左右(SSD,SAS)磁盘当然选择ssd性能更好,但是价格偏贵。每个数据盘在2-10T左右不宜太大,数据量太大读写慢,寻址慢。比如磁盘坏了或者导数据,磁盘数据量太大就很麻烦。
网卡:万兆网卡(光纤卡),很有钱十万兆网卡也可以。
电源:均配置冗余电源,有条件的可以具备发电能力。
内存配置
NameNode
将Namenode运行在一台独立的服务器上,要设置Namenode堆内存大小,可通过在hadoop配置文件hadoop-env.sh中添加 如下内容实现: export HADOOP_HEAPSIZE_MAX= 大 export HADOOP_HEAPSIZE_MIN= 大 tips:建议Namenode堆内存大小设置为物理内存的80%,且堆内存上限和下限设置为一样大,以免jvm动态调整。因为nd需要加载很多元数据,所以内存设置的比较大。(比如128g的服务器,设置nd的的内存为100g可以hold住1000台且为20*1T硬盘的集群) DataNode 同样修改hadoop配置文件hadoop-env.sh,添加如下内容: export HDFS_DATANODE_HEAPSIZE=4096 export HDFS_DATANODE_OPTS="-Xms$HDFS_DATANODE_HEAPSIZEm -Xmx$HDFS_DATANODE_HEAPSIZEm" 建议Datanode堆内存大小设置为4GB以上。 4-8G即可 ,将更多内存留给YARN资源计算
在搭建集群时候需考虑未来一到两年的资源消耗来搭建集群。举个例子如下 1. 每天1T, 副本数为3 ,一年需要的存储资源:1 * 3 * 365 = 1095T 2. 数据需要 进行加工 (建模):1095T* 3 = 3285T 3. 数据增速是 每年50% ,3285T* ( 1.5)= 4928T 4. 磁盘只能存到 80% ,故需要3942T的存储空间 5. 压缩比,按50%估算,故需要存储1972T 机器配置:32cpu core, 128G内存,11 * 7T 故:1972/77 = 26 台 服务器 Tips:评估资源时候一定要预留充足,以及充分的扩展接口关键参数
dfs.replication 此参数用来设置文件副本数,通常设为3,不推荐修改。这个参数可用来保障HDFS数据安全,副本数越多,越浪费 磁盘存储空间,但数据安全性越高。tips:高版本可搭配纠删码使用。 dfs.block.size 此参数用来设置HDFS中数据块的大小,默认为128M,所以,存储到HDFS的数据最好都大于128M或者是128的整 数倍,这是最理想的情况,对于数据量较大的集群,可设为256MB或者512MB。数据块设置太小,会增加NameNode的压力。数据块设置过大会增加定位数据的时间。 dfs.datanode.data.dir 这个参数是设置HDFS数据块的存储路径,配置的值应当是分布在各个独立磁盘上的目录,这样可以充分利用节点的IO读写能力,提高HDFS读写性能。 dfs.datanode.max.transfer.threads 这个值是配置datanode可同时处理的最大文件数量,推荐将这个值调大,最大值可以配置为65535 hdfs-site.xml样例如下
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--指定hdfs的nameservice为zzhadoop,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>nxhadoop</value>
</property>
<!-- zzhadoop下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.zzhadoop</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.zzhadoop.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.zzhadoop.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- dn 与 nn的rpc端口-->
<property>
<name>dfs.namenode.servicerpc-address.zzhadoop.nn1</name>
<value>hadoop01:53310</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.zzhadoop.nn2</name>
<value>hadoop02:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.zzhadoop.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.zzhadoop.nn2</name>
<value>hadoop02:53310</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop03:8485;hadoop04:8485;hadoop05:8485/zzhadoop-joural</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/zdp/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.zzhadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(zdp:22)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>1000</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/zdp/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/zdp/hadoop/hdfs/dfs.namenode.name.dir</value>
</property>
<!-- 多块磁盘的话可以把fsimage与edits分开
<property>
<name>dfs.namenode.edits.dir</name>
<value>$dfs.namenode.name.dir</value>
</property>
-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data0/hdfs/dfs.data,file:///data1/hdfs/dfs.data,file:///data2/hdfs/dfs.data,file:///data3/hdfs/dfs.data,file:///data4/hdfs/dfs.data,file:///data5/hdfs/dfs.data,file:///data6/hdfs/dfs.data,file:///data7/hdfs/dfs.data,file:///data8/hdfs/dfs.data,file:///data9/hdfs/dfs.data,file:///data10/hdfs/dfs.data,file:///data11/hdfs/dfs.data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>31457280</value>
</property>
<!-- 磁盘访问策略 -->
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>2</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>6000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>107374182400</value>
</property>
<!--
<property>
<name>ha.health-monitor.rpc-timeout.ms</name>
<value>300000</value>
</property>
-->
<!-- 权限设置 -->
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>zdp</value>
</property>
<property>
<name>fs.permissions.umask-mode</name>
<value>022</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
<!-- 1019 -->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property>
<property>
<name>dfs.namenode.fs-limits.max-component-length</name>
<value>0</value>
</property>
</configuration>
core-site.xml样例如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop03:2181,hadoop04:2181,hadoop05:2181/hadoop</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/zdp/hadoop/hadoop_tmp/tmp</value>
<description>A base for other temporarydirectories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>ipc.server.read.threadpool.size</name>
<value>3</value>
<description>
Reader thread num, rpc中reader线程个数
</description>
</property>
<!-- Rack Awareness -->
<property>
<name>net.topology.script.file.name</name>
<value>/opt/soft/zdp/hadoop-2.7.5/etc/hadoop/rack_awareness.py</value>
</property>
<property>
<name>net.topology.script.number.args</name>
<value>100</value>
</property>
<!-- 改变dr.who为superuser(即启动用户), 在页面上可以访问任意目录 -->
<!--
<property>
<name>hadoop.http.staticuser.user</name>
<value>work</value>
</property>
-->
<property>
<name>hadoop.proxyuser.zdp.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.zdp.groups</name>
<value>*</value>
</property>
<!-- 功能待验证 security.client.protocol.hosts -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration>
存储平台常见故障
1:下线DataNode
(1)、修改hdfs-site.xml文件 找到namenode节点配置文件/etc/hadoop/conf/hdfs-site.xml文件如下选项: <property> <name>dfs.hosts.exclude</name> <value>/etc/hadoop/conf/hosts-exclude</value> </property> (2)、修改hosts-exclude文件 在hosts-exclude中添加需要下线的datanode主机名,执行如下操作: vi /etc/hadoop/conf/hosts-exclude 192.16.213.77 (3)、刷新配置 在namenode上以hadoop用户执行下面命令,刷新hadoop配置: [hadoop@namenodemaster ~]$hdfs dfsadmin -refreshNodes (4)、检查是否完成下线 通过执行如下命令检查下线是否完成: [hadoop@cdh5master ~]$hdfs dfsadmin -report 也可以通过查看NameNode的50070端口访问web界面,查看HDFS状态,需要重点关注退役的节点数以及复制的块数和进度 2:磁盘故障 如果某个datanode节点的磁盘出现故障,将会出现此节点不能写入操作而导致datanode进程退出,针对这个 问题,首先在故障节点上查看/etc/hadoop/conf/hdfs-site.xml文件中对应的dfs.datanode.data.dir参数设 置,去掉故障磁盘对应的目录挂载点。 然后,在故障节点查看/etc/hadoop/conf/yarn-site.xml文件中对应的yarn.nodemanager.local-dirs参数设 置,去掉故障磁盘对应的目录挂载点。最后,重启此节点的datanode服务和nodemanager服务即可。磁盘修复好了以后,重新添加回去(可以通过脚本自动监控新增磁盘)。 3:NameNode故障在HDFS集群中,Namenode主机上存储了所有的元数据信息,如果此信息丢失,那么整个HDFS上面的数据将不可用,而如果Namenode服务器发生了故障无法启动,
解决的方法分为两种情况:
如果Namenode做了高可用服务,那么在主Namenode故障后,Namenode服务会自动切换到备用的 Namenode上,这个过程是自动的,无需手工介入。
如果你的Namenode没做高可用服务,那么还可以借助于SecondaryNameNode服务,在 SecondaryNameNode主机上找到元数据信息,然后直接在此节点启动Namenode服务即可,种方式可能会丢失部分数据,因为SecondaryNameNode实现的是Namenode的冷备份。 由此可知,对Namenode进行容灾备份至关重要,在生产环境下,建议通过standby Namenode实现Namenode的高可用热备份。
4:yarn被标记为不健康
当节点被标记为不健康后,此节点相会被剔出了yarn集群,不会再有任务提交到此节点. yarn配置中,参数yarn.nodemanager.local-dirs,它用来存储NodeManager应用程序运行的中间结果,另一个参数yarn.nodemanager.log-dirs,它指定了NodeManager的日志文件存放目录列表。这两个参数都可以配置多个目录,多个目录之间使用逗号分隔。 本地目录健康检测主要涉及到以下几个参数: yarn.nodemanager.disk-health-checker.min-healthy-disks 表示正常目录数目相对于总目录总数的比例,低于这个值则认为此节点处于不正常状态,默认值为0.25。 例如指定了十二个目录(磁盘),这意味着它们中至少有3( 12的1/4)个目录必须处于正常状态才能使 NodeManager在该节点上启动新容器。 yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 此参数默认值为90,表示yarn.nodemanager.local-dirs配置项下的路径或者yarn.nodemanager.log-dirs配置项下的路径的磁盘使用率达到了90%以上,则将此台机器上的nodemanager标志为unhealthy,这个值可以设置为0 到100之间 5:磁盘存储不均 在HDFS集群中,涉及到增删磁盘时候就回到指数局部均衡。以新增磁盘为例。 有新数据会写入这个硬盘,而之前的老数据不会自动将数据平衡过来,如此下去,更换的硬盘越多,节点之 间、每个节点的各个磁盘之间的数据将越来越不平衡。 可以使用hadoop提供的Balancer程序得HDFS集群达到一个平衡的状态,执行命令 如下: [hadoop@namenodemaster sbin]$ $HADOOP_HOME/bin/start-balancer.sh –t 5% 或者执行如下命令: [hadoop@namenodemaster sbin]$ hdfs balancer -threshold 5 这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果节点与节点之间磁盘使用率偏 差小于5%,那么我们就认为HDFS集群已经达到了平衡的状态。 6:集群新增DataNode (1)、新节点部署hadoop环境 新增节点在系统安装完成后,要进行一系列的操作,比如系统基本优化设置,hadoop环境的部署和安装等等,这 些基础工作需要事先完成。 (2)、修改hdfs-site.xml文件 在namenode上查看/etc/hadoop/conf/hdfs-site.xml文件,找到如下内容: <property> <name>dfs.hosts</name> <value>/etc/hadoop/conf/hosts</value> </property> (3)、修改hosts文件 在 namenode 上修改/etc/hadoop/conf/hosts文件,添加新增的节点主机名,操作如下: vi /etc/hadoop/conf/hosts hadoop001 最后,将配置同步到所有datanode节点的机器上。 (4)、使配置生效 新增节点后,要让namenode识别新的节点,需要在namenode上刷新配置,执行如下操作: [hadoop@namenodemaster ~]$hdfs dfsadmin -refreshNodes (5)、在新节点启动dn服务 在namenode上完成配置后,最后还需要在新增节点上启动datanode服务,执行如下操作: [hadoop@ hadoop001 ~]$ hdfs --daemon start datanode 这样,一个新的节点就增加到集群中了,hadoop的这种机制可以在不影响现有集群运行的状态下,任意新增或者删除 某个节点。 7:missing blocks 这个问题也经常发生,并且会有数据丢失,因为一旦HDFS集群出现missing blocks错误,那意味着有元数据丢失或者损坏,要恢复的难度很大,或者基本无法恢复,针对这种情况,解决的办法就是先执行如下命令: [hadoop@namenodemaster sbin]$ hdfs fsck /blocks-path/ 此命令会检查HDFS下所有块状态,并给出那些文件出现了块丢失或损坏,最后执行如下命令删除这些文件 即可: [hadoop@namenodemaster sbin]$ hdfs fsck -fs hdfs://bigdata/logs/mv.log -delete 上面是删除HDFS上mv.log这个文件,因此此文件元数据丢失,无法恢复,所以只能删除。 8:KafkaBroker OOM Kafka的默认启动内存较小,Kafka的生产端首先将数据发送到broker的内存存储,随机通过主机的OS层的数据刷盘机制将数据持久化,因此Kafka需要一定大小的内存空间,在生产环境一般建议将启动内存调整,官方建议内存在4-8G左右大小; 修改$KAFKA_HOME/bin/kafka-server-start.sh脚本 9: broker运行日志大量topic不存在报错,导致节点不可用 若broker的运行日志大量刷topic不存在的WARN,并导致节点不可用;表明该集群存在topic被删除,但有发端 仍使用该topic发送数据,此时需要检查broker上的2个配置项: delete.topic.enable=true auto.create.topics.enable=false(默认是true,发送时候没有topic默认创建) 10:kafka topic动态扩分区 流程见:https://blog.csdn.net/forrest_ou/article/details/79141391 目前Kafka只支持增加分区数而不支持减少分区数。比如我们再将主题topic-config的分区数修改为1,就会报出InvalidPartitionException的异常,详解如下 (27条消息) 为什么Kafka中的分区数只能增加不能减少_rede-CSDN博客调度系统(Yarn)
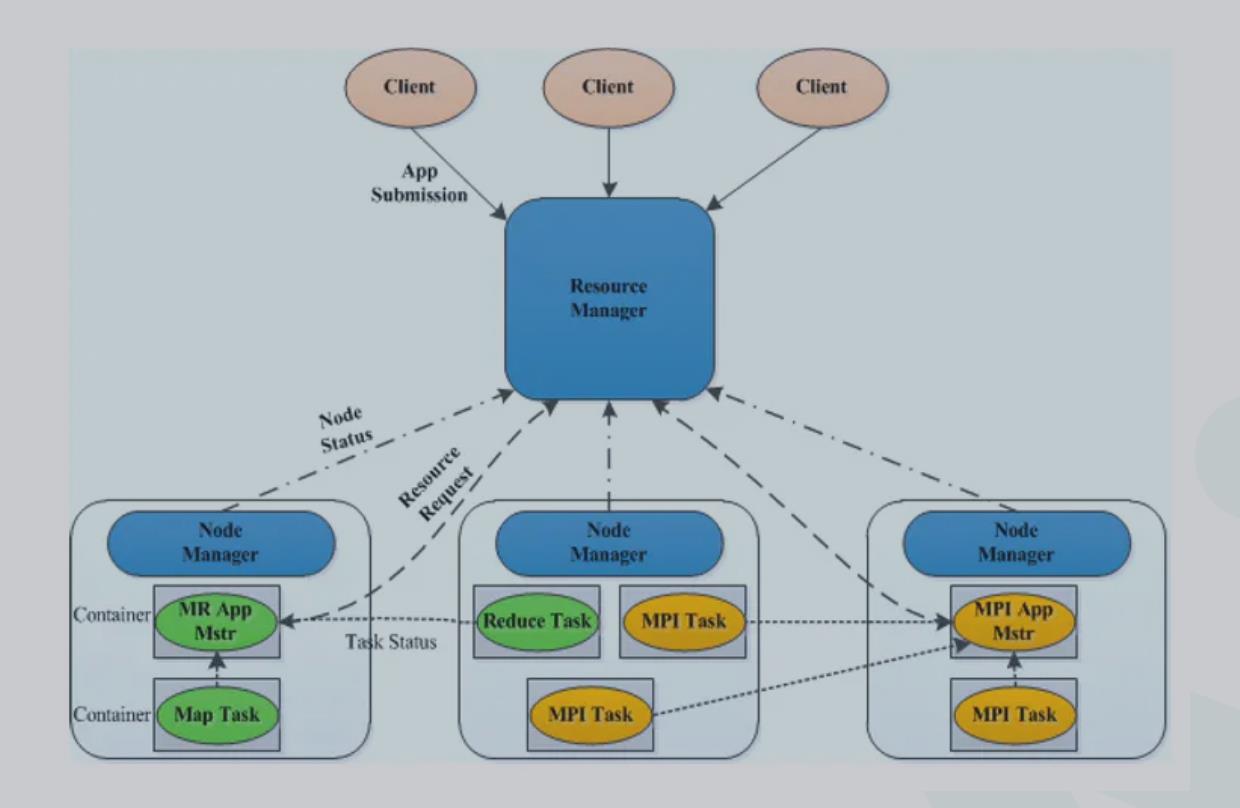
yarn-site.xml参考配置如下
<?xml version="1.0"?>
<configuration>
<!--ha related configuration-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rm</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!--rm1 address-->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop1:8088</value>
</property>
<!--rm2 address-->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop011:2181,hadoop012:2181,hadoop013:2181/zzhadoop</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/etc/hadoop/,
$HADOOP_HOME/share/hadoop/common/*,$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,$HADOOP_HOME/share/hadoop/yarn/lib/*,
$HADOOP_HOME/share/hadoop/tools/lib/*
</value>
</property>
<property>
&l以上是关于数据中台架构PaaS层(平台服务层)之实时存储资源规划与架构设计的主要内容,如果未能解决你的问题,请参考以下文章