中创深入了解存储提供商的生态系统
Posted 中创算力
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中创深入了解存储提供商的生态系统相关的知识,希望对你有一定的参考价值。
2022年3月2日,由ESPA主办的星际文件系统存储提供商训练营现场启动活动。该活动将为存储提供商收集在星际文件系统网络上运营和开展业务的所需的资源、指南等信息。对于那些想要迈出下一步的人,可以申请为期6个月的ESPA加速器。

从专有服务到非中心化服务的转变已经影响了许多行业,存储空间租赁也不例外。点对点架构可以采用基于集中式服务器的Web 2.0商业模式,并将其转变为依赖于激励社区的Web3开放服务。
星际文件系统网络的算法市场,作为当前云存储解决方案的开放且可行的替代方案。它旨在成为一个非中心化的存储网络,解决当前面向客户的问题,例如随意定价、锁定供应商和对手交易风险,同时为希望成为服务提供商的人降低进入市场的门槛。
为了实现这一目标,该网络协调维持其运营的多个独立参与者的角色。客户、开发者、通证持有者、生态系统合作伙伴和存储提供商都是星际文件系统岛屿经济的一部分。
存储提供商的角色
尤其是存储提供商,对于星际文件系统网络至关重要。这些参与者选择以非中心化和无需信任的方式将多余的存储空间借出。
在星际文件系统上,任何人都可以作为存储提供商加入网络并负责网络运营的核心任务。当存储提供商达到可用存储空间大于10PiB的阈值时,他们能够在链上提出新块,以跟踪数据存储和检索交易。类似于区块链中的工作量证明机制,新区块由该网络奖励
对存储提供商运营同样重要的是他们参与这些存储和检索交易。这是他们与客户互动的地方,通过提供他们的存储空间来换取补偿。
总之,存储提供商构成了星际文件系统非中心化存储市场的基础,它们的操作可以作为衡量网络稳健性的指标。了解他们的生态系统对于了解网络价值和路线图以及非中心化存储的未来至关重要。
存储提供商统计
自主网启动以来,星际文件系统网络在可供用户使用的存储能力方面持续稳定增长。存储提供商的数量已达到3,876个,其中最大的提供了高达147.65PiB的存储空间。它们总共为网络提供了超过15.6EiB的存储空间。
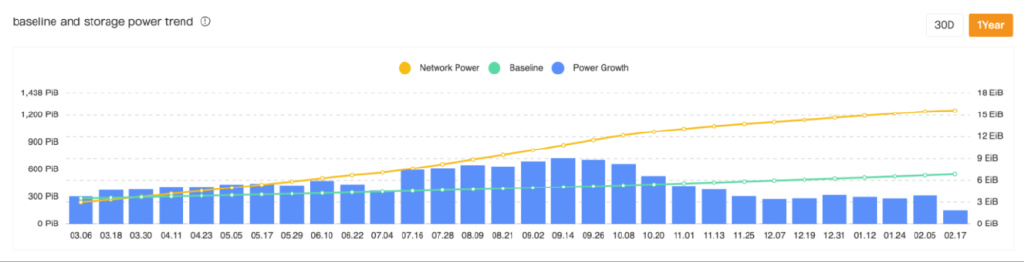
(过去一年的存储量增加的趋势图)
因此,存储在网络上的信息量也增加了,目前在1,623,282笔活跃交易中使用了36.95 PiB的存储空间。
这一切都归功于不同规模和地理位置的存储提供商组成的全球社区。
(SP集中在全球的位置)
各种规模的存储提供商
存储提供商生态系统中参与者的多样性是网络设计综合考虑的结果。星际文件系统是一个无需许可任何人都可以访问的网络,它支持企业级存储配置蓬勃发展,同时也为轻量级的个人设置提供发展机会。
这是由于此网络使用了存储证明共识算法,该算法通过简单的哈希率来奖励网络上有效资源的使用。该算法标志着星际文件系统与传统工作证明网络之间的明显差异。星际文件系统对这个问题的解决方案是组合被称为复制证明和时空证明的加密机制。这些机制允许存储提供商向客户证明他们的数据冗余且持久地存储在网络上。这形成了一个健康的生态系统,小型和大型存储提供商可以共存并满足不同用户群的存储需求。尽管具有一定的优势,但收集大型存储资源并不一定意味着取得成功,因为存储提供商能够以高于最低要求的任何容量完成交易。
欢迎更多存储供应商
自主网启动以来,存储提供商生态系统在短时间内的发展是非中心化存储的重要里程碑。随着该网络在全球范围和整体容量方面的增长,存储提供商将继续在其发展中发挥关键作用。来自世界各地的各种规模的参与者都将在其中找到一个支持和参与的社区,因为他们有助于推进互联网的持续非中心化。
深入了解Hadoop
一、了解Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二、Hadoop的特征
Hadoop是什么:分布式存储+分布式、可拓展计算平台
Hadoop能做什么:搭建大型数据仓库、PB级数据存储、处理、分析
Hadoop优势:高可靠性、低成本、搞拓展、成熟的生态圈、囊括了大数据处理的方方面面
狭义的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台
广义的Hadoop:指的是hadoop的整个生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中一个重要的基础部分,生态系统中的每一个子系统只解决某一个特定的问题域
Hadoop包括哪些模块
hadoop common
hadoop distributed file system(hdfs)负责数据存储
hadoop yarn 负责作业调度与集群资源管理
hadoop MapReduce 基于yarn系统之上可以并行处理大数据计算
三、Hadoop的推荐学习路线
1) Hadoop生态环境介绍
2) Hadoop云计算中的位置和关系
3) 国内外Hadoop应用案例介绍
4) Hadoop 概念、版本、历史
5) Hadoop 核心组成介绍及hdfs、mapreduce 体系结构
6) Hadoop 的集群结构
7) Hadoop 伪分布的详细安装步骤
8) 通过命令行和浏览器观察hadoop
9) HDFS底层工作原理
10) HDFS datanode,namenode详解
11) Hdfs shell
12) Hdfs java api
13) Mapreduce四个阶段介绍
14) Writable
15) InputSplit和OutputSplit
16) Maptask
17) Shuffle:Sort,Partitioner,Group,Combiner
18) Reducer
19) 二次排序
20) 倒排序索引
21) zui优路径
22) 电信数据挖掘之-----移动轨迹预测分析(中国棱镜计划)
23) 社交好友推荐算法
24) 互联网精准广告推送 算法
25) 阿里巴巴天池大数据竞赛 《天猫推荐算法》案例
26) Mapreduce实战pagerank算法
27) Hadoop2.x集群结构体系介绍
28) Hadoop2.x集群搭建
29) NameNode的高可用性(HA)
30) HDFS Federation
31) ResourceManager 的高可用性(HA)
32) Hadoop集群常见问题和解决方法
33) Hadoop集群管理
文末福利
将来自己,一定会感谢现在自己的,现在不努力,将来只会后悔。我们不做后悔的哪个,只做最好的自己。
想从事以上工作或者往大数据方向发展的朋友,可以点击联系我们,获取大数据相关资料和高清学习线路图,希望在你发展的道路上有所帮助。
程序员OfHome交流群:610535338
以上是关于中创深入了解存储提供商的生态系统的主要内容,如果未能解决你的问题,请参考以下文章
人民云网利用IPFS技术自主研发区块链分布式存储数据中心网 ,加快filecoin网络生态落地!
波卡生态Crust:2020“分布式存储元年”黑马?|链茶访