一、闭包
1. 闭包的概念
闭包与执行上下文、环境、作用域息息相关
执行上下文
执行上下文是用于跟踪运行时代码求值的一个规范设备,从逻辑上讲,执行上下文是用执行上下文栈(栈、调用栈)来维护的。
代码有几种类型:全局代码、函数代码、eval代码和模块代码;每种代码都是在其执行上下文中求值。
当函数被调用时,就创建了一个新的执行上下文,并被压到栈中 - 此时,它变成一个活动的执行上下文。当函数返回时,此上下文被从栈中弹出

function recursive(flag) {
// Exit condition.
if (flag === 2) {
return;
}
// Call recursively.
recursive(++flag);
}
// Go.
recursive(0);
调用另一个上下文的上下文被称为调用者(caller)。被调用的上下文相应地被称为被调用者(callee),在这段代码中,recursive 既是调用者,又是被调用者
对应的执行上下文栈
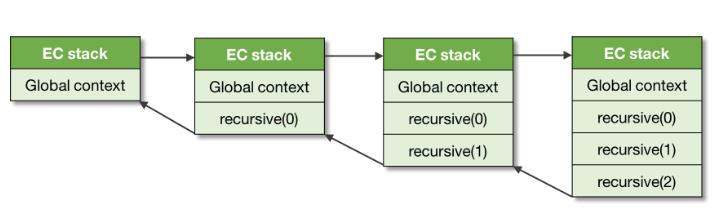
通常,一个上下文的代码会一直运行到结束。然而在异步处理的 Generator中,是特殊的。
一个Generator函数可能会挂起其正在执行的上下文,并在结束前将其从栈中删除。一旦Generator再次激活,它上下文就被恢复,并再次压入栈中
function *g() {
yield 1;
yield 2;
}
var f = g();
f.next();
f.next();
yield 语句将值返回给调用者,并弹出上下文。而在调用 next 时,同一个上下文被再次压入栈中,并恢复
环境
每个执行上下文都有一个相关联的词法环境
可以把词法环境定义为一个在作用域中的变量、函数和类的仓库,每个环境有一个对可选的父环境的引用
比如这段代码中的全局上下文与foo函数的上下文对应的环境
let x = 10;
let y = 20;
function foo(z) {
let x = 100;
return x + y + z;
}
foo(30); // 150
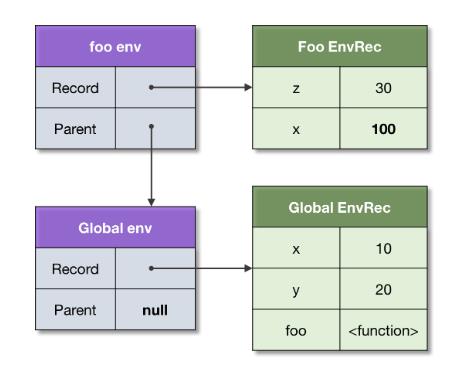
作用域
当一个执行上下文被创建时,就与一个特定的作用域(代码域 realm)关联起来。这个作用域为该上下文提供全局环境(此“全局”并非常规意义上的全局,只是一种提供上下文栈调用的意思)
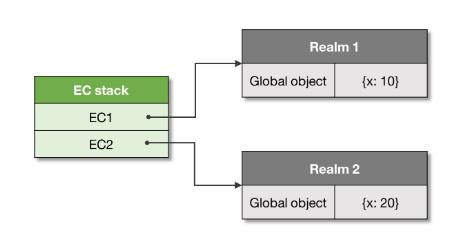
静态作用域
如果一个语言只通过查找源代码,就可以判断绑定在哪个环境中解析,那么该语言就实现了静态作用域。所以,一般也可称作词法作用域。
在环境中引用函数,同时改函数也引用着环境。静态作用域是通过捕获函数创建所在的环境来实现的。
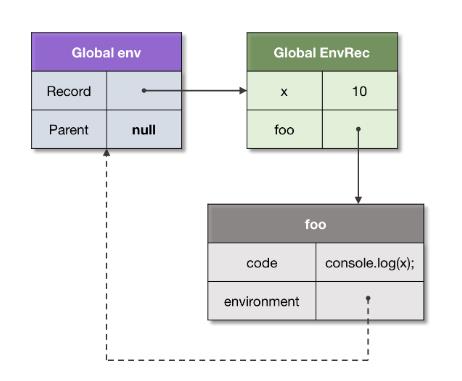
如图,全局环境引用了foo函数,foo函数也引用着全局环境
自由变量
一个既不是函数的形参,也不是函数的局部变量的变量
function testFn() {
var localVar = 10;
function innerFn(innerParam) {
alert(innerParam + localVar);
}
return innerFn;
}
对于innerFn 函数来说,localVar 就属于自由变量
闭包
闭包是代码块和创建该代码块的上下文中数据的组合,是函数捕获它被定义时所在的环境(闭合环境)。
在JS中,函数是属于一等公民(first-class)的,一般来说代码块即是函数的意思(暂不考虑ES6的特殊情况)
所以,闭包并不仅是一个函数,它是一个环境,这个环境中保存了一些相关的数据及指针引用。
理论上来说,所有的函数都是闭包。
因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用的是最外层的作用域
而从实现的角度上看,并不完全遵循理论,但也又两点依据,符合其一即可称作闭包
在代码中引用了自由变量
使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
更多相关概念可以查看 这个系列
2. 闭包的特性
- 函数嵌套函数
- 函数内部可以引用外部的参数和变量
- 参数和变量不会被垃圾回收机制回收
一般来说,闭包形式上来说有嵌套的函数,其可引用外部的参数和变量(自由变量),且在其上下文销毁之后,仍然存在(不会被垃圾回收机制回收)
3. 闭包的优点
- 使一个变量长期驻扎在内存中
- 避免全局变量的污染
- 作为私有成员的存在
按照特性,闭包有着对应的优点
比如创建一个计数器,常规来说我们可以使用类
function Couter() {
this.num = 0;
}
Couter.prototype = {
constructor: Couter,
// 增
up: function() {
this.num++;
},
// 减
down: function() {
this.num--;
},
// 获取
getNum: function() {
console.log(this.num);
}
};
var c1 = new Couter();
c1.up();
c1.up();
c1.getNum(); // 2
var c2 = new Couter();
c2.down();
c2.down();
c2.getNum(); // -2
这挺好的,我们也可以用闭包的方式来实现
function couter() {
var num = 0;
return {
// 增
up: function() {
num++;
},
// 减
down: function() {
num--;
},
// 获取
getNum: function() {
console.log(num);
}
};
}
var c1 = couter();
c1.up();
c1.up();
c1.getNum(); // 2
var c2 = couter();
c2.down();
c2.down();
c2.getNum(); // -2
可以看到,虽然couter函数的上下文被销毁了,num仍保存在内存中
在很多设计模式中,闭包都充当着很重要的角色,
4. 闭包的缺点
闭包的缺点,更多地是在内存性能的方面。
由于变量长期驻扎在内存中,在复杂程序中可能会出现内存不足,但这也不算非常严重,我们需要在内存使用与开发方式上做好取舍。在不需要的时候清理掉变量
在某些时候(对象与DOM存在互相引用,GC使用引用计数法)会造成内存泄漏,要记得在退出函数前清理变量
window.onload = function() {
var elem = document.querySelector(\'.txt\');
// elem的onclick指向了匿名函数,匿名函数的闭包也引用着elem
elem.onclick = function() {
console.log(this.innerhtml);
};
// 清理
elem = null;
};
内存泄漏相关的东西,这里就不多说了,之后再整理一篇
除此之外,由于闭包中的变量可以在函数外部进行修改(通过暴露出去的接口方法),所有不经意间也内部的变量会被修改,所以也要注意
5. 闭包的运用
闭包有很广泛的使用场景
常见的一个问题是,这段代码输出什么
var func = [];
for (var i = 0; i < 5; ++i) {
func[i] = function() {
console.log(i);
}
}
func[3](); // 5
由于作用域的关系,最终输出了5
稍作修改,可以使用匿名函数立即执行与闭包的方式,可输出正确的结果
for (var i = 0; i < 5; ++i) {
(function(i) {
func[i] = function() {
console.log(i);
}
})(i);
}
func[3](); // 3
for (var i = 0; i < 5; ++i) {
(function() {
var n = i;
func[i] = function() {
console.log(n);
}
})();
}
func[3](); // 3
for (var i = 0; i < 5; ++i) {
func[i] = (function(i) {
return function() {
console.log(i);
}
})(i);
}
func[3](); // 3
二、高阶函数
高阶函数(high-order function 简称:HOF),咋一听起来那么高级,满足了以下两点就可以称作高阶函数了
- 函数可以作为参数被传递
- 函数可以作为返回值输出
在维基中的定义是
- 接受一个或多个函数作为输入
- 输出一个函数
可以将高阶函数理解为函数之上的函数,它很常用,比如常见的
var getData = function(url, callback) {
$.get(url, function(data){
callback(data);
});
}
或者在众多闭包的场景中都使用到
比如 防抖函数(debounce)与节流函数(throttle)
Debounce
防抖,指的是无论某个动作被连续触发多少次,直到这个连续动作停止后,才会被当作一次来执行
比如一个输入框接受用户不断输入,输入结束后才开始搜索
以页面滚动作为例子,可以定义一个防抖函数,接受一个自定义的 delay值,作为判断停止的时间标识
// 函数防抖,频繁操作中不处理,直到操作完成之后(再过 delay 的时间)才一次性处理
function debounce(fn, delay) {
delay = delay || 200;
var timer = null;
return function() {
var arg = arguments;
// 每次操作时,清除上次的定时器
clearTimeout(timer);
timer = null;
// 定义新的定时器,一段时间后进行操作
timer = setTimeout(function() {
fn.apply(this, arg);
}, delay);
}
};
var count = 0;
window.onscroll = debounce(function(e) {
console.log(e.type, ++count); // scroll
}, 500);
滚动页面,可以看到只有在滚动结束后才执行
Throttle
节流,指的是无论某个动作被连续触发多少次,在定义的一段时间之内,它仅能够触发一次
比如resize和scroll时间频繁触发的操作,如果都接受了处理,可能会影响性能,需要进行节流控制
以页面滚动作为例子,可以定义一个节流函数,接受一个自定义的 delay值,作为判断停止的时间标识
需要注意的两点
要设置一个初始的标识,防止一开始处理就被执行了,同时在最后一次处理之后,也需要重新置位
也要设置定时器处理,防止两次动作未到delay值,最后一组动作触发不了
// 函数节流,频繁操作中间隔 delay 的时间才处理一次
function throttle(fn, delay) {
delay = delay || 200;
var timer = null;
// 每次滚动初始的标识
var timestamp = 0;
return function() {
var arg = arguments;
var now = Date.now();
// 设置开始时间
if (timestamp === 0) {
timestamp = now;
}
clearTimeout(timer);
timer = null;
// 已经到了delay的一段时间,进行处理
if (now - timestamp >= delay) {
fn.apply(this, arg);
timestamp = now;
}
// 添加定时器,确保最后一次的操作也能处理
else {
timer = setTimeout(function() {
fn.apply(this, arg);
// 恢复标识
timestamp = 0;
}, delay);
}
}
};
var count = 0;
window.onscroll = throttle(function(e) {
console.log(e.type, ++count); // scroll
}, 500);
三、柯里化
柯里化(Currying),又称为部分求值,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回一个新的函数的技术,新函数接受余下参数并返回运算结果。
比较经典的例子是
实现累加 add(1)(2)(3)(4)
第一种方法即是使用回调嵌套
function add(a) {
// 疯狂的回调
return function(b) {
return function(c) {
return function(d) {
// return a + b + c + d;
return [a, b, c, d].reduce(function(v1, v2) {
return v1 + v2;
});
}
}
}
}
console.log(add(1)(2)(3)(4)); // 10
既不优雅也不好扩展
修改两下,让它支持不定的参数数量
function add() {
var args = [].slice.call(arguments);
// 用以存储更新参数数组
function adder() {
var arg = [].slice.call(arguments);
args = args.concat(arg);
// 每次调用,都返回自身,取值时可以通过内部的toString取到值
return adder;
}
// 指定 toString的值,用以隐示取值计算
adder.toString = function() {
return args.reduce(function(v1, v2) {
return v1 + v2;
});
};
return adder;
}
console.log(add(1, 2), add(1, 2)(3), add(1)(2)(3)(4)); // 3 6 10
上面这段代码,就能够实现了这个“柯里化”
需要注意的两个点是
- arguments并不是真正的数组,所以不能使用数组的原生方法(如 slice)
- 在取值时,会进行隐示的求值,即先通过内部的toString()进行取值,再通过 valueOf()进行取值,valueOf优先级更高,我们可以进行覆盖初始的方法
当然,并不是所有类型的toString和toValue都一样,Number、String、Date、Function 各种类型是不完全相同的,本文不展开
上面用到了call 方法,它的作用主要是更改执行的上下文,类似的还有apply,bind 等
我们可以试着自定义一个函数的 bind方法,比如
var obj = {
num: 10,
getNum: function(num) {
console.log(num || this.num);
}
};
var o = {
num: 20
};
obj.getNum(); // 10
obj.getNum.call(o, 1000); // 1000
obj.getNum.bind(o)(20); // 20
// 自定义的 bind 绑定
Function.prototype.binder = function(context) {
var fn = this;
var args = [].slice.call(arguments, 1);
return function() {
return fn.apply(context, args);
};
};
obj.getNum.binder(o, 100)(); // 100
上面的柯里化还不够完善,假如要定义一个乘法的函数,就得再写一遍长长的代码
需要定义一个通用currying函数,作为包装
// 柯里化
function curry(fn) {
var args = [].slice.call(arguments, 1);
function inner() {
var arg = [].slice.call(arguments);
args = args.concat(arg);
return inner;
}
inner.toString = function() {
return fn.apply(this, args);
};
return inner;
}
function add() {
return [].slice.call(arguments).reduce(function(v1, v2) {
return v1 + v2;
});
}
function mul() {
return [].slice.call(arguments).reduce(function(v1, v2) {
return v1 * v2;
});
}
var curryAdd = curry(add);
console.log(curryAdd(1)(2)(3)(4)(5)); // 15
var curryMul = curry(mul, 1);
console.log(curryMul(2, 3)(4)(5)); // 120
看起来就好多了,便于扩展
不过实际上,柯里化的应用中,不定数量的参数场景比较少,更多的情况下的参数是固定的(常见的一般也就两三个)
// 柯里化
function curry(fn) {
var args = [].slice.call(arguments, 1),
// 函数fn的参数长度
fnLen = fn.length;
// 存储参数数组,直到参数足够多了,就调用
function inner() {
var arg = [].slice.call(arguments);
args = args.concat(arg);
if (args.length >= fnLen) {
return fn.apply(this, args);
} else {
return inner;
}
}
return inner;
}
function add(a, b, c, d) {
return a + b + c + d;
}
function mul(a, b, c, d) {
return a * b * c * d;
}
var curryAdd = curry(add);
console.log(curryAdd(1)(2)(3)(4)); // 10
var curryMul = curry(mul, 1);
console.log(curryMul(2, 3)(4)); // 24
上面定义的 add方法中,接受4个参数
在我们currying函数中,接受这个add方法,并记住这个方法需要接受的参数数量,存储传入的参数,直到符合数量要求时,便进行调用处理。
反柯里化
反柯里化,将柯里化过后的函数反转回来,由原先的接受单个参数的几个调用转变为接受多个参数的单个调用
一种简单的实现方法是:将多个参数一次性传给柯里化的函数,因为我们的柯里化函数本身就支持多个参数的传入处理,反柯里化调用时,仅使用“一次调用”即可。
结合上方的柯里化代码,反柯里化代码如下
// 反柯里化
function uncurry(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var arg = [].slice.call(arguments);
args = args.concat(arg);
return fn.apply(this, args);
}
}
var uncurryAdd = uncurry(curryAdd);
console.log(uncurryAdd(1, 2, 3, 4)); // 10
var uncurryMul = uncurry(curryMul, 2);
console.log(uncurryMul(3, 4)); // 24
参考资料: