Golang中sync.Map的实现原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang中sync.Map的实现原理相关的知识,希望对你有一定的参考价值。
参考技术A 前面,我们讲了map的用法以及原理 Golang中map的实现原理 ,但我们知道,map在并发读写的情况下是不安全。需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,今天,我们就来讲讲 sync.Map的用法以及原理sync.Map与map不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构:
我们下来看下sync.Map结构体
结构体之间的关系如下图所示:
总结一下:
Load方法比较简单,总结一下:
总结如下:
不得不知道的Golang之sync.Map解读!

导语 | 本文结合源码,分析sync.Map的实现思路和原理,希望为更多感兴趣的开发者提供一些经验和帮助。
一、背景
项目中遇到了需要使用高并发的map的场景,众所周知golang官方的原生map是不支持并发读写的,直接并发的读写很容易触发panic。
解决的办法有两个:
自己配一把锁(sync.Mutex),或者更加考究一点配一把读写锁(sync.RWMutex)。这种方案简约直接,但是缺点也明显,就是性能不会太高。
使用Go语言在2017年发布的Go 1.9中正式加入了并发安全的字典类型sync.Map。
很显然,方案2是优雅且实用的。但是,为什么官方的sync.Map能够在lock free的前提下,保证足够高的性能?本文结合源码进行简单的分析。
二、核心思想&架构
如果要保证并发的安全,最朴素的想法就是使用锁,但是这意味着要把一些并发的操作强制串行化,性能自然就会下降。
事实上,除了使用锁,还有一个办法,也可以达到类似并发安全的目的,就是原子操作(atomic)。sync.Map的设计非常巧妙,充分利用了atmoic和mutex的配合。
(一)核心思想
核心原则就是,尽量使用原子操作,最大程度上减少了锁的使用,从而接近了“lock free”的效果。
核心点:
使用了两个原生的map作为存储介质,分别是read map和dirty map(只读字典和脏字典)。
只读字典使用atomic.Value来承载,保证原子性和高性能;脏字典则需要用互斥锁来保护,保证了互斥。
只读字典和脏字典中的键值对集合并不是实时同步的,它们在某些时间段内可能会有不同。
无论是read还是dirty,本质上都是map[interface]*entry类型,这里的entry其实就是Map的value的容器。
entry的本质,是一层封装,可以表示具体值的指针,也可以表示key已删除的状态(即逻辑假删除)
通过这种设计,规避了原生map无法并发安全delete的问题,同时在变更某个键所对应的值的时候,就也可以使用原子操作了。
这里列一下Map的源码定义。篇幅问题,我去除了大量的英文原版注释,换成融合自身理解的直观解释。如果有需要可以结合原版的注释对比着看。
type Map struct
mu sync.Mutex
// read contains .... 省略原版的注释
// read map是被atomic包托管的,这意味着它本身Load是并发安全的(但是它的Store操作需要锁mu的保护)
// read map中的entries可以安全地并发更新,但是对于expunged entry,在更新前需要经它unexpunge化并存入dirty
//(这句话,在Store方法的第一种特殊情况中,使用e.unexpungeLocked处有所体现)
read atomic.Value // readOnly
// dirty contains .... 省略原版的注释
// 关于dirty map必须要在锁mu的保护下,进行操作。它仅仅存储 non-expunged entries
// 如果一个 expunged entries需要存入dirty,需要先进行unexpunged化处理
// 如果dirty map是nil的,则对dirty map的写入之前,需要先根据read map对dirty map进行浅拷贝初始化
dirty map[interface]*entry
// misses counts .... 省略原版的注释
// 每当读取的是时候,read中不存在,需要去dirty查看,miss自增,到一定程度会触发dirty=>read升级转储
// 升级完毕之后,dirty置空 &miss清零 &read.amended置false
misses int
// 这是一个被原子包atomic.Value托管了的结构,内部仍然是一个map[interface]*entry
// 以及一个amended标记位,如果为真,则说明dirty中存在新增的key,还没升级转储,不存在于read中
type readOnly struct
m map[interface]*entry
amended bool // true if the dirty map contains some key not in m.
// An entry is a slot in the map corresponding to a particular key.
// 这是一个容器,可以存储任意的东西,因为成员p是unsafe.Pointer(*interface)
// sync.Map中的值都不是直接存入map的,都是在entry的包裹下存入的
type entry struct
// p points .... 省略原版的注释
// entry的p可能的状态:
// e.p == nil:entry已经被标记删除,不过此时还未经过read=>dirty重塑,此时可能仍然属于dirty(如果dirty非nil)
// e.p == expunged:entry已经被标记删除,经过read=>dirty重塑,不属于dirty,仅仅属于read,下一次dirty=>read升级,会被彻底清理
// e.p == 普通指针:此时entry是一个不同的存在状态,属于read,如果dirty非nil,也属于dirty
p unsafe.Pointer // *interface
(二)架构设计图
初看这个结构的设计,会觉得复杂,不理解为什么要设计成这样,这里画了一个图,力求更加直观的说明read和dirty之间的配合关系。
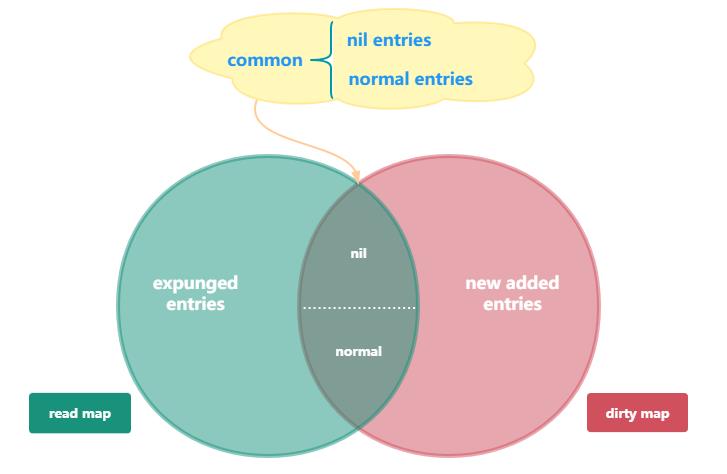
架构的进一步解释说明:
read map由于是原子包托管,主要负责高性能,但是无法保证拥有全量的key(因为对于新增key,会首先加到dirty中),所以read某种程度上,类似于一个key的快照。
dirty map拥有全量的key,当Store操作要新增一个之前不存在的key的时候,预先是增加自dirty中的。
在查找指定的key的时候,总会先去只读字典中寻找,并不需要锁定互斥锁。只有当read中没有,但dirty中可能会有这个key的时候,才会在锁的保护下去访问dirty。
在存储键值对的时候,只要read中已存有这个key,并且该键值对未被标记为“expunged”,就会把新值存到里面并直接返回,这种情况下也不需要用到锁。
expunged和nil,都表示标记删除,但是它们是有区别的,简单说expunged是read独有的,而nil则是read和dirty共有的,具体这么设计的原因,最后统一总结。
read和map的关系,是一直在动态变化的,可能存在重叠,也可能是某某一方为空;重叠的公共部分,由分为两种情况,nil和normal,它们分别的意义,会在最后统一总结。
read和dirty之间是会互相转换的,在dirty中查找key对次数足够多的时候,sync.Map会把dirty直接作为read,即触发dirty=>read升级。同时在某些情况,也会出现read=>dirty的重塑,具体方式和这么设计的原因,最后详述。
三、源码细节梳理
通过上面的分析,可以对sync.Map有一个初步的整体认知,这里再列出CURD几个关键操作的源码,进一步加深理解。同样的由于篇幅原因,我去除了大段冗长的英文注释,换成了提炼之后更加通俗的理解,有需要可以对比原文注释。
(一)Store操作(对应C/U)
// Store sets the value for a key.
func (m *Map) Store(key, value interface)
// 首先把readonly字段原子地取出来
// 如果key在readonly里面,则先取出key对应的entry,然后尝试对这个entry存入value的指针
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value)
return
// 如果readonly里面不存在key或者是对应的key是被擦除掉了的,则继续。。。
m.mu.Lock() // 上锁
// 锁的惯用模式:再次检查readonly,防止在上锁前的时间缝隙出现存储
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok
// 这里有两种情况:
// 1. 上面的时间缝隙里面,出现了key的存储过程(可能是normal值,也可能是expunge值)
// 此时先校验e.p,如果是普通值,说明read和dirty里都有相同的entry,则直接设置entry
// 如果是expunge值,则说明dirty里面已经不存在key了,需要先在dirty里面种上key,然后设置entry
// 2. 本来read里面就存在,只不过对应的entry是expunge的状态
// 这种情况和上面的擦除情况一样,说明dirty里面已经不存在key了,需要先在dirty里面种上key,然后设置entry
if e.unexpungeLocked()
// The entry was previously expunged, which implies that there is a
// non-nil dirty map and this entry is not in it.
m.dirty[key] = e
e.storeLocked(&value) // 将value存入容器e
else if e, ok := m.dirty[key]; ok
// readonly里面不存在,则查看dirty里面是否存在
// 如果dirty里面存在,则直接设置dirty的对应key
e.storeLocked(&value)
else
// dirty里面也不存在(或者dirty为nil),则应该先设置在ditry里面
// 此时要检查read.amended,如果为假(标识dirty中没有自己独有的key or 两者均是初始化状态)
// 此时要在dirty里面设置新的key,需要确保dirty是初始化的且需要设置amended为true(表示自此dirty多出了一些独有key)
if !read.amended
// We're adding the first new key to the dirty map.
// Make sure it is allocated and mark the read-only map as incomplete.
m.dirtyLocked()
m.read.Store(readOnlym: read.m, amended: true)
m.dirty[key] = newEntry(value)
// 解锁
m.mu.Unlock()
// 这是一个自旋乐观锁:只有key是非expunged的情况下,会得到set操作
func (e *entry) tryStore(i *interface) bool
for
p := atomic.LoadPointer(&e.p)
// 如果p是expunged就不可以了set了
// 因为expunged状态是read独有的,这种情况下说明这个key已经删除(并且发生过了read=>dirty重塑过)了
// 此时要新增只能在dirty中,不能在read中
if p == expunged
return false
// 如果非expunged,则说明是normal的entry或者nil的entry,可以直接替换
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i))
return true
// 利用了go的CAS,如果e.p是 expunged,则将e.p置为空,从而保证她是read和dirty共有的
func (e *entry) unexpungeLocked() (wasExpunged bool)
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
// 真正的set操作,从这里也可以看出来2点:1是set是原子的 2是封装的过程
func (e *entry) storeLocked(i *interface)
atomic.StorePointer(&e.p, unsafe.Pointer(i))
// 利用read重塑dirty!
// 如果dirty为nil,则利用当前的read来初始化dirty(包括read本身也为空的情况)
// 此函数是在锁的保护下进行,所以不用担心出现不一致
func (m *Map) dirtyLocked()
if m.dirty != nil
return
// 经过这么一轮操作:
// dirty里面存储了全部的非expunged的entry
// read里面存储了dirty的全集,以及所有expunged的entry
// 且read中不存在e.p == nil的entry(已经被转成了expunged)
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface]*entry, len(read.m))
for k, e := range read.m
if !e.tryExpungeLocked() // 只有非擦除的key,能够重塑到dirty里面
m.dirty[k] = e
// 利用乐观自旋锁,
// 如果e.p是nil,尽量将e.p置为expunged
// 返回最终e.p是否是expunged
func (e *entry) tryExpungeLocked() (isExpunged bool)
p := atomic.LoadPointer(&e.p)
for p == nil
if atomic.CompareAndSwapPointer(&e.p, nil, expunged)
return true
p = atomic.LoadPointer(&e.p)
return p == expunged
(二)Store操作(对应R)
func (m *Map) Load(key interface) (value interface, ok bool)
// 把readonly字段原子地取出来
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果readonly没找到,且dirty包含了read没有的key,则尝试去dirty里面找
if !ok && read.amended
m.mu.Lock()
// 锁的惯用套路
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended
e, ok = m.dirty[key]
// Regardless of ... 省略英文
// 记录miss次数,并在满足阈值后,触发dirty=>map的升级
m.missLocked()
m.mu.Unlock()
// readonly和dirty的key列表,都没找到,返回nil
if !ok
return nil, false
// 找到了对应entry,随即取出对应的值
return e.load()
// 自增miss计数器
// 如果增加到一定程度,dirty会升级成为readonly(dirty自身清空 & read.amended置为false)
func (m *Map) missLocked()
m.misses++
if m.misses < len(m.dirty)
return
// 直接用dirty覆盖到了read上(那也就是意味着dirty的值是必然是read的父集合,当然这不包括read中的expunged entry)
m.read.Store(readOnlym: m.dirty) // 这里有一个隐含操作,read.amended再次变成false
m.dirty = nil
m.misses = 0
// entry是一个容器,从entry里面取出实际存储的值(以指针提取的方式)
func (e *entry) load() (value interface, ok bool)
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged
return nil, false
return *(*interface)(p), true
(三)Delete操作(对应D)
// Delete deletes the value for a key.
func (m *Map) Delete(key interface)
m.LoadAndDelete(key)
// 删除的逻辑和Load的逻辑,基本上是一致的
func (m *Map) LoadAndDelete(key interface) (value interface, loaded bool)
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended
e, ok = m.dirty[key]
delete(m.dirty, key)
// Regardless of ...省略
m.missLocked()
m.mu.Unlock()
if ok
return e.delete()
return nil, false
// 如果e.p == expunged 或者nil,则返回false
// 否则,设置e.p = nil,返回删除的值得指针
func (e *entry) delete() (value interface, ok bool)
for
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged
return nil, false
if atomic.CompareAndSwapPointer(&e.p, p, nil)
return *(*interface)(p), true
四、整体思考
第一次读Map的源码,会觉得很晦涩,虽然整体思路是明确的,但是细节却很多,困惑于为什么做这样的设计,多读几遍之后,很多问题能够略窥门径。这里列出一些开始觉得困惑的问题:
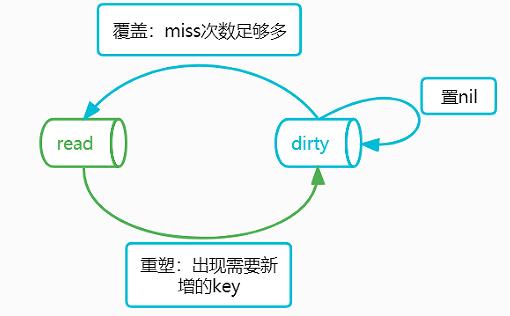
(一)dirty和read互转,分别在什么样的时机下会进行?
dirty=>read:随着load的miss不断自增,达到阈值后触发升级转储(完毕之后,dirty置空&miss清零&read.amended置false)
read=>dirty:当有read中不存在的新key需要增加且read和dirty一致的时候,触发重塑,且read.amended置true(然后再在dirty新增)。重塑的过程,会将nil状态的entry,全部挤压到expunged状态中,同时将非expunged的entry浅拷贝到dirty中,这样可以避免read的key无限的膨胀(存在大量逻辑删除的key)。最终,在dirty再次升级为read的时候,这些逻辑删除的key就可以一次性丢弃释放了(因为是直接覆盖上去)
(二)read从何而来,存在的意义又是什么?
read是有dirty升级而来,是利用了atomic.Store一次性覆盖,而不是一点点的set操作出来的。所以,read更像是一个快照,read中key的集合不能被改变(注意,这里说的read的key不可改变,不代表指定的key的value不可改变,value是可以通过原子CAS来进行更改的),所以其中的键的集合有时候可能是不全的。
相反,脏字典中的键值对集合总是完全的,但是其中不会包含expunged的键值对。
read的存在价值,在于加速读性能(通过原子操作避免了锁)
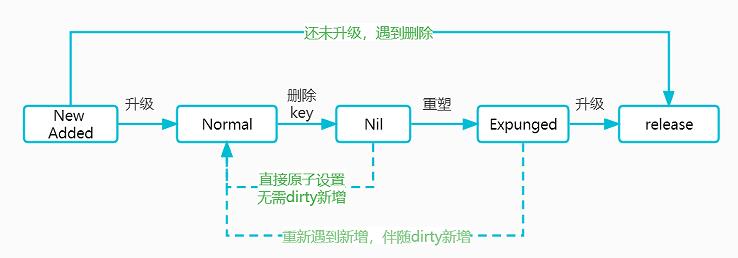
(三)entry的p可能的状态,有哪些?
e.p==nil:entry已经被标记删除,不过此时还未经过read=>dirty重塑,此时可能仍然属于dirty(如果dirty非nil)
e.p==expunged:entry已经被标记删除,经过read=>dirty重塑,不属于dirty,仅仅属于read,下一次dirty=>read升级,会被彻底清理(因为升级的操作是直接覆盖,read中的expunged会被自动释放回收)
e.p==普通指针:此时entry是一个普通的存在状态,属于read,如果dirty非nil,也属于dirty。对应架构图中的normal状态。
(四)删除操作的细节,e.p到底是设置成了nil还是expunged?
如果key不在read中,但是在dirty中,则直接delete。
如果key在read中,则逻辑删除,e.p赋值为nil(后续在重塑的时候,nil会变成expunged)
(五)什么时候e.p由nil变成expunged?
read=>dirty重塑的时候,此时read中仍然是nil的,会变成expunged,表示这部分key等待被最终丢弃(expunged是最终态,等待被丢弃,除非又出现了重新store的情况)
最终丢弃的时机:就是dirty=>read升级的时候,dirty的直接粗暴覆盖,会使得read中的所有成员都被丢弃,包括expunged。
(六)既然nil也表示标记删除,那么再设计出一个expunged的意义是什么?
expunged是有存在意义的,它作为删除的最终状态(待释放),这样nil就可以作为一种中间状态。如果仅仅使用nil,那么,在read=>dirty重塑的时候,可能会出现如下的情况:
如果nil在read浅拷贝至dirty的时候仍然保留entry的指针(即拷贝完成后,对应键值下read和dirty中都有对应键下entry e的指针,且e.p=nil)那么之后在dirty=>read升级key的时候对应entry的指针仍然会保留。那么最终;的合集会越来越大,存在大量nil的状态,永远无法得到清理的机会。
如果nil在read浅拷贝时不进入dirty,那么之后store某个Key键的时候,可能会出现read和dirty不同步的情况,即此时read中包含dirty不包含的键,那么之后用dirty替换read的时候就会出现数据丢失的问题。
如果nil在read浅拷贝时直接把read中对应键删除(从而避免了不同步的问题),但这又必须对read加锁,违背了read读写不加锁的初衷。
综上,为了保证read作为快照的性质(不能单独删除或新增key),同时要避免Map中nil的key不断膨胀等多个前提要求,才设计成了expungd的状态。
(七)对于一个entry,从生到死的状态机图
(八)注释中关于slow path和fast path的解释
慢路径其实就是经过了锁的代码路径。
快路径就是不经过锁的。
五、总结
sync.Map的源码并不长,但是里面的很多细节都非常的考究,比如对于原子和锁的使用、利用状态机的变化标记来代替map的delete从而提高性能和安全性等等。
作者简介

华起
腾讯后台开发工程师
腾讯后台研发工程师,毕业于西安电子科技大学。目前负责腾讯视频打点读取、列表筛选等业务的后端研发工作。有丰富的服务端开发经验。
推荐阅读

以上是关于Golang中sync.Map的实现原理的主要内容,如果未能解决你的问题,请参考以下文章