ssh 是如何实现三层架构的? 每层分别用啥技术实现?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ssh 是如何实现三层架构的? 每层分别用啥技术实现?相关的知识,希望对你有一定的参考价值。
ssh 现三层架构,和每层使用的技术如下:1.Struts应用在表示层,它是基于MVC的WEB应用框架。
Strutts提供了中央控制器(ActionServlet)和应用控制器(Action)。ActionServlet是Struts框架的核心,采用的是前端控制模式;Action则负责完成对服务的调用,对ActionServlet接受并分发下来请求进行处理。可以重写ActionServlet,也可以直接使用,然后继承Action,使其完成我们要求的功能。有了Struts提供的控制器,再运用JSTL标签、Struts标签库中的标签配以JSP或html文件,就是Struts中的视图。另外,用于视图与控制器之间表单数据传输的ActionFormBean,也被归于到了视图中。Struts并没有定义模型层的具体实现。一般情况下,Action中所使用的服务是由业务层提供的。Struts中还有不可缺少的配置文件。该配置文件描述了用户请求路径和Action映射关系的信息。ActionServlet通过解析此配置文件得知需把用户的请求发往哪一个Action。
2.Hibernate是一种映射的工具,完全着眼于关系数据库的对象——关系映射,管理对象到数据库的映射,提供数据查询和获取数据的方法。在持久层中,不仅可以使用Hibernate进行映射,还可以使用iBATIS进行SQL语句与对象之间的映射,此外,也可以直接使用JDBC对数据库进行操作。至于使用那一种工具实现持久化,可以根据自己的需求视情况而定。而Hibernate映射是否复杂取决于领域对象的关系是否复杂。
3.Spring贯穿于WEB应用中,它为我们管理对象提供了方便,降低了层与层之间的耦合度,将程序员从繁琐的事务、安全和分布式处理中解放出来,从而把更多的精力放在业务上。如果应用程序才用了Struts+Hibernate的架构,Spring可以帮助整合两者。在创建对象时,可以通过Spring进行注入;对于事务管理,可以通过Spring集成声明式事务管理到到应用程序中等。 参考技术A 三层架构是C#的说法。java叫 MVC 。 MVC的实现只需要strust 跟spring 和 hibernate 无关 参考技术B struts C 控制器 你请求跳转业务处理不都是struts做的嘛
hibernate m 模型 就是把数据库表变为你能操作的java实体类
html jsp 什么的 V 视图层 跟用户交互的界面
Spring是解耦用的 传统的servlet里 需要我们new service dao等 来操作 N多servlet 若一旦dao 或者service 变掉了 你是不要改N个servlet spring提供了bean工厂 代理了 当然也减少了 new的过程 配置一下 一般spring 三种方式 常用的是 set方式 这也叫 依赖注入 控制反转
当然Spring 3.0以后呢 他本身也是可以做C 跟M用的 但是传统上讲 没spring
三层架构的一点理解以及Dapper一对多查询
1.首先说一下自己对三层架构的一点理解
论坛里经常说会出现喜欢面相对象的写法,所以使用EF的,我个人觉得他俩没啥关系,先别反对,先听听我怎么说吧.
三层架构,基本都快说烂了,但今天还是说三层架构:UI,BLL,DAL.之前往往强调的是三层架构各司其职,但没有说三层架构中每层之间怎么交互的,以及人员之间的分工合作问题.今天重点说这个,从而回答面向对象和EF的关系.
今天说的与数据库有关,那就先说BLL和DAL之间数据的传递.有不少都是按照以下两种方式写的:
(1)以Datatable传递.可想想,一个datatable对象,里面是什么呢?对于这样的方式作为业务层和数据库之间的桥梁不直观,并且无法应对变化,还不如写成一层.
(2)那我定义成对象不就直观了,所以有些就一张表定义一个对象,对象和数据库表一模一样.这样写呢,没比第一种好到哪去.首先数据库修改之后,Model得修改,Dal层也得修改.还有,这也是最重要的,如果两个人分别开发BLL和DAL,那这两个人必须都得熟悉数据库以及他们之间的对应关系.
那怎么样比较合适呢?
随着编程越来越成熟,细分不可避免.在公司中每个人只关心自己的那部分,三层分别划分为不同的人或团队编写.这样不只是从代码层面,从管理层面更符合术业有专攻,每层专注于自己的功能:
(1)业务人员更应该了解业务的编写,业务算法的实现,计算性能等,而无需关心数据怎么存储,无需学习数据库,无需关心索引,主键等等.
(2)UI更多的关心界面怎么布局,怎么做的更好看,更符合用户的使用等,而无需关心数据怎么存储,业务怎么计算等.
(3)数据库服务层(注意现在多加了服务两个字,很关键)更应该关心数据用什么去存储去满足高性能的数据增删改查,在这我没说非是关系型数据库,还是NoSql什么的,其实如果text,excel存储方便且能满足性能要求,又有何不可呢.
三层有了,那他们之间怎么衔接呢,答案就是业务,每个业务都需要展示,计算(简单业务不需要),存储数据,这不就是三层人员需要干的事吗,根据展示的数据定义好对象作为UI和BLL层之间的传输对象.存储也一样,根据业务需要存储数据的特征定义好存储的对象,作为BLL和DAL之间交互的对象.实际这两个对象就是三层交互的公约,有了这个公约,每层开发根据公约实现每层的功能,每层的编程人员也不再需要关心其他层怎么实现的.DAl层已经不仅仅是数据库这么简单了,而是对对象增删改查.
这样做的好处:
(1)人员更加专业,分工明确后,每个人专业技能容易提升
(2)只要交互的对象不发生改变,三层随意修改,都不会影响到其他两层.
(3)编程人员更容易形成自己的模式,加快开发速度.
(4)编写人员接触多了,踩过的坑就越多,编写的代码也就越健康.等等吧,好处大大滴.
说了这么多,现在回答EF的问题,根据以上划分的三层,EF必然归数据服务层了.如果是写UI或业务的人员,那面不面向对象与EF没有任何关系.数据服务层就是实现对象的增删改查,如果使用的关系型数据库,那使用EF到底能简化多少行代码,我觉得一般般吧.
微软总喜欢给用户一整套解决方案,比如MVC,用微软的VS直接可以生成MVC框架,但MVC不是真正意义上的前后端分离.同样EF更偏向于一个人来完成所有层的编写.
2.性能
性能都说Dapper与原生ADO.NET差不多,其处理过程是一样的(个人理解,没有深究,有不对的请指导.):
ADO.NET是把查询的赋值给datatable或dataset.
Dapper是利用委托的方式,把每行的数据处理之后再赋值给对象.如果不用委托,那就直接把每行查出来的数据赋值给对象即可.最后生成一个集合.
EF应该是根据设置的主外键关系生成sql语句,然后再去查询.但对于复杂的查询,自动生成sql语句就没那么容易了,在考虑索引的问题,那就是难上加难了,可能会经常出现不使用索引的情况,导致查询速度慢.
3.Dapper实现一对多查询
既然说一对多,那就整个复杂的,两级一对多查询.有更复杂的也希望大家提供.
公司分为多个部门,每个部门又有很多员工.
3.1先建立表,并添加示例数据


1 USE [test] 2 GO 3 /****** Object: Table [dbo].[staff] Script Date: 11/12/2019 10:18:55 ******/ 4 SET ANSI_NULLS ON 5 GO 6 SET QUOTED_IDENTIFIER ON 7 GO 8 CREATE TABLE [dbo].[staff]( 9 [id] [int] IDENTITY(1,1) NOT NULL, 10 [part_id] [int] NOT NULL, 11 [name] [nvarchar](50) NULL 12 ) ON [PRIMARY] 13 GO 14 SET IDENTITY_INSERT [dbo].[staff] ON 15 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (1, 1, N‘员工1‘) 16 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (2, 1, N‘员工2‘) 17 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (3, 1, N‘员工3‘) 18 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (4, 2, N‘员工4‘) 19 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (6, 2, N‘员工5‘) 20 INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (7, 3, N‘员工6‘) 21 SET IDENTITY_INSERT [dbo].[staff] OFF 22 /****** Object: Table [dbo].[department] Script Date: 11/12/2019 10:18:55 ******/ 23 SET ANSI_NULLS ON 24 GO 25 SET QUOTED_IDENTIFIER ON 26 GO 27 CREATE TABLE [dbo].[department]( 28 [id] [int] IDENTITY(1,1) NOT NULL, 29 [com_id] [int] NOT NULL, 30 [name] [nvarchar](50) NULL 31 ) ON [PRIMARY] 32 GO 33 SET IDENTITY_INSERT [dbo].[department] ON 34 INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (1, 1, N‘部门1‘) 35 INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (2, 1, N‘部门2‘) 36 INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (3, 2, N‘部门1‘) 37 INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (4, 2, N‘部门3‘) 38 SET IDENTITY_INSERT [dbo].[department] OFF 39 /****** Object: Table [dbo].[company] Script Date: 11/12/2019 10:18:55 ******/ 40 SET ANSI_NULLS ON 41 GO 42 SET QUOTED_IDENTIFIER ON 43 GO 44 CREATE TABLE [dbo].[company]( 45 [id] [int] IDENTITY(1,1) NOT NULL, 46 [name] [nvarchar](50) NULL 47 ) ON [PRIMARY] 48 GO 49 SET IDENTITY_INSERT [dbo].[company] ON 50 INSERT [dbo].[company] ([id], [name]) VALUES (1, N‘公司1‘) 51 INSERT [dbo].[company] ([id], [name]) VALUES (2, N‘公司2‘) 52 INSERT [dbo].[company] ([id], [name]) VALUES (3, N‘公司3‘) 53 SET IDENTITY_INSERT [dbo].[company] OFF
3.2对象定义
(1)公司
1 /// <summary> 2 /// 公司 3 /// </summary> 4 public class Company 5 { 6 /// <summary> 7 /// 公司ID 8 /// </summary> 9 public int CompanyID { get; set; } 10 /// <summary> 11 ///公司名称 12 /// </summary> 13 public string CompanyName { get; set; } 14 /// <summary> 15 /// 公司包含的部门 16 /// </summary> 17 public List<Department> Department { get; set; } 18 }
(2)部门
1 /// <summary> 2 /// 部门 3 /// </summary> 4 public class Department 5 { 6 /// <summary> 7 /// 部门ID 8 /// </summary> 9 public int DepartmentID { get; set; } 10 /// <summary> 11 /// 部门名称 12 /// </summary> 13 public string DepartmentName { get; set; } 14 /// <summary> 15 /// 部门包含的员工 16 /// </summary> 17 public List<Staff> Staff { get; set; } 18 }
(3)员工
1 /// <summary> 2 /// 员工 3 /// </summary> 4 public class Staff 5 { 6 /// <summary> 7 /// 员工ID 8 /// </summary> 9 public int StaffID { get; set; } 10 /// <summary> 11 /// 员工姓名 12 /// </summary> 13 public string StaffName { get; set; } 14 }
3.3不使用委托
1 /// <summary> 2 /// 不用委托 3 /// </summary> 4 public static List<Company> NoDelegate() 5 { 6 using (IDbConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;")) 7 { 8 string sql = "SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id"; 9 return conn.Query<Company>(sql).AsList(); 10 } 11 }
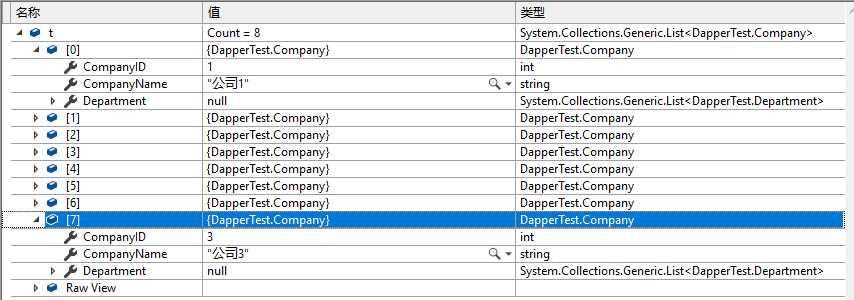
没有做级联处理,所以每一行结果就是一个Company对象,一共8行,结果就是8个Company对象的集合.
3.4使用委托
1 /// <summary> 2 /// 使用委托 3 /// </summary> 4 /// <returns></returns> 5 public static List<Company> UseDelegate() 6 { 7 using (IDbConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;")) 8 { 9 string sql = "SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN Department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id"; 10 var res = new List<Company>(); 11 conn.Query<Company, Department, Staff, Company>(sql, (com, part, staff) => 12 { 13 //查找是否存在该公司 14 var t = res.Where(p => p.CompanyID == com.CompanyID).FirstOrDefault(); 15 //如果没有该公司,则添加该公司 16 if (t == null) 17 { 18 t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName }; 19 res.Add(t); 20 } 21 //先判断该行数据的part是否为空,如果为空则不做任何处理. 22 Department parttmp = null; 23 if (part != null) 24 { 25 if (t.Department == null) 26 t.Department = new List<Department>(); 27 parttmp = t.Department.Where(p => p.DepartmentID == part.DepartmentID).FirstOrDefault(); 28 if (parttmp == null) 29 { 30 parttmp = part; 31 t.Department.Add(part); 32 } 33 } 34 //判断该行数据的员工是否为空 35 if (staff != null) 36 { 37 if (parttmp.Staff == null) 38 parttmp.Staff = new List<Staff>(); 39 parttmp.Staff.Add(staff); 40 } 41 return com;//没有任何意义,不过委托需要有返回值. 42 }, splitOn: "DepartmentID,StaffID"); 43 return res; 44 } 45 }
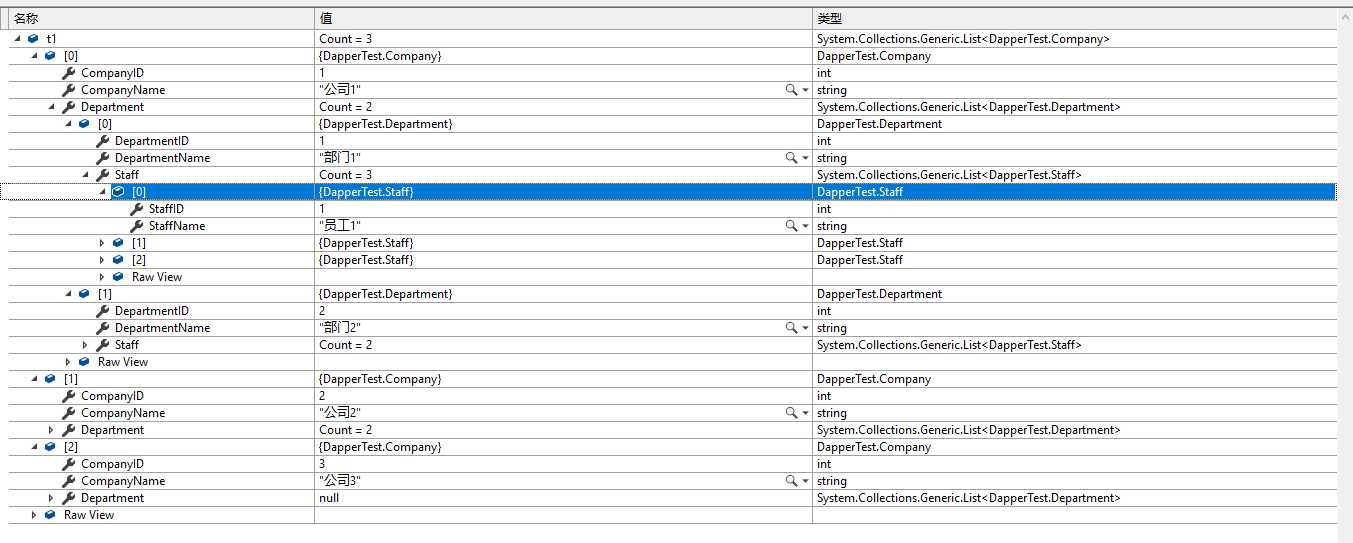
做级联处理,一共3个公司,所以结果是3个Company的集合.每个Company分别包含下属的部门和员工.
3.5使用ADO.NET查询DataTable,并转换成对象
1 /// <summary> 2 /// 利用datatable实现,为了测试性能,所以不再整理成级联的形式. 3 /// </summary> 4 /// <returns></returns> 5 public static List<Company> UseTable() 6 { 7 List<Company> res = new List<Company>(); 8 DataTable dt = new DataTable(); 9 using (SqlConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;")) 10 { 11 if (conn.State != ConnectionState.Open) 12 conn.Open(); 13 SqlCommand sqlCommand = new SqlCommand("SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN Department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id", conn) 14 { 15 CommandType = CommandType.Text 16 }; 17 SqlDataAdapter da = new SqlDataAdapter 18 { 19 SelectCommand = sqlCommand 20 }; 21 da.Fill(dt); 22 } 23 for (int i = 0; i < dt.Rows.Count; i++) 24 { 25 res.Add(new Company() 26 { 27 28 CompanyID = Convert.ToInt32(dt.Rows[i]["CompanyID"]), 29 CompanyName = dt.Rows[i]["CompanyName"].ToString(), 30 Department = new List<Department>() { 31 32 dt.Rows[i]["DepartmentID"]!=DBNull.Value? new Department() { 33 DepartmentID = Convert.ToInt32(dt.Rows[i]["DepartmentID"]), 34 DepartmentName = dt.Rows[i]["DepartmentName"].ToString(), 35 Staff = new List<Staff>() { 36 dt.Rows[i]["StaffID"]!=DBNull.Value? new Staff() { 37 StaffID =Convert.ToInt32(dt.Rows[i]["StaffID"]), 38 StaffName =dt.Rows[i]["StaffName"].ToString() }:null 39 } 40 }:null 41 } 42 }); 43 } 44 return res; 45 } 46 }
查询结果与第一种一致.
3.6性能对比
每个循环执行10000次,记录执行的时间.在自己的电脑上测试的.不同电脑有所差异,每次运行所用时间也不同,非专业测试.但能说明问题.
1 static void Main(string[] args) 2 { 3 Stopwatch sw = new Stopwatch(); 4 sw.Restart(); 5 for (int i = 0; i < 10000; i++) 6 { 7 var t = NoDelegate(); 8 } 9 sw.Stop(); 10 Console.Write("不用委托的时间:" + sw.ElapsedMilliseconds); 11 Console.WriteLine(); 12 sw.Restart(); 13 for (int i = 0; i < 10000; i++) 14 { 15 var t1 = UseDelegate(); 16 } 17 sw.Stop(); 18 Console.Write("使用委托的时间:" + sw.ElapsedMilliseconds); 19 Console.WriteLine(); 20 sw.Restart(); 21 for (int i = 0; i < 10000; i++) 22 { 23 var t2 = UseTable(); 24 } 25 sw.Stop(); 26 Console.Write("使用DataTable的时间:" + sw.ElapsedMilliseconds); 27 Console.ReadLine(); 28 }
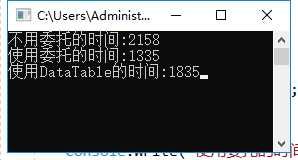
运行了好几次,结果大致就是这样:
(1)使用Dapper,但不做级联处理,时间最长.
(2)使用Dapper,做级联处理,耗时最短.
(3)使用DataTable,耗时在两者之间.
原因分析(个人理解):
以上三种情况的区别可以分为两点:
第一点执行过程:Dapper执行一次.ADO.NET先查询出DataTable,然后再转换为对象.
第二点转换对象方式:Dapper是利用Emit把数据转换成对象,使用DataTable实例化对象是先初始化对象再赋值;
基于以上的区别,三种方式执行耗时的原因如下:
第一种方式虽然不像第三种方式经过两步,但由于数据转换对象的次数较多,并且使用Emit转换而不是直接定义对象的方式赋值,所以耗时较长.
第二种方式即在每行查询的过程中给对象赋值,并且由于判断了公司和部门是否存在,数据转换到对象的次数明显少了很多.
第三种方式由于先把查询的结果赋值给DataTable,然后再把DataTable转换成对象,经过两步,比第二种方式耗时多一点,但优于第一种.
3.7第二种方式编写知识点说明
(1)执行过程,分为三步:
先定义一个Company集合,也就是返回值;
Dapper逐行处理SQL语句的查询结果,并添加到返回值的集合中;
最后返回Company集合.
(2) 解释Query中的四个对象Company,Department,Staff,Company
Dapper每行查询后会根据SQL语句和splitOn定义的分隔形成前三个对象(Company,Department,Staff)
最后一个Company定义了该Query查询的结果是Company的集合.
(3)委托的作用
委托就是定义Dapper以什么样的方式处理每行数据.本例中,处理流程:
Dapper查询出每行数据以后,定义的委托先判断在结果集合中(res:Company集合)判断是否存在该行数据指定的公司,如果不存在该公司,利用该行的公司数据初始化一个新的公司对象,并添加到res中.
然后判断该公司中是否存在该行数据指定的部门,如果不存在同样利用该行的部门数据实例化一个部门,并添加到公司对象中.
最后把员工添加到该行数据指定的部门中,员工不会出现重复.完成一行数据的处理.
以上过程可以在委托中打断点,看整个执行过程.
(4)splitOn
splitOn是为了帮助Dapper在查询每行的数据后,划分为指定的三个对象(Company,Department,Staff).在该实例中三个对象包含的字段分别是:
com.id CompanyID,com.name CompanyName;
part.id PartMentID, part.name PartMentName;
st.ID StaffID, st.name StaffName;
因此利用每个对象的第一个字段作为分隔符区分三个对象.例如splitOn: "DepartmentID,StaffID"中DepartmentID表示第二个对象(Department)的第一个字段,StaffID是第三个对象(Staff)的第一个字段.
(5)null值处理
在初始化Company和Department时,都未同时实例化其包含的部门集合和员工集合.以Company说明:
在查找结果集合中未包含当前查询行的公司时,需要实例化一个Company,然后利用该行的数据实例化一个Company对象,并添加到结果集合中.
t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName };
没有写成 t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName,Department = new List<Department>() };
也就是没有对t的Department 进行初始化.而是先判断该行的Department是否存在( if (part != null)),如果存在再判断Department 是否为空,为空则进行实例化,否则就让Department 为空.
这样是为了可以直接通过Department 是否为null判断数据的完整性,如果先实例化,那么判断数据的完整性的时候还需要判断Department 个数是否大于0.
以上是关于ssh 是如何实现三层架构的? 每层分别用啥技术实现?的主要内容,如果未能解决你的问题,请参考以下文章