使用 Neo4j 图数据库可视化(网络安全)知识图谱
Posted 白白净净吃了没病
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Neo4j 图数据库可视化(网络安全)知识图谱相关的知识,希望对你有一定的参考价值。
目录
a)添加系统变量 CLASS_PATH 和 JAVA_HOME
说明:本文前两节提到的 Java 和 neo4j 的安装包可以通过如下链接免费下载:
 https://download.csdn.net/download/qq_40506723/86754696
https://download.csdn.net/download/qq_40506723/86754696一、安装 Java 环境
1、下载 Java 包并解压到指定目录下
子目录如下图所示:
2、配置环境变量
a)添加系统变量 CLASS_PATH 和 JAVA_HOME
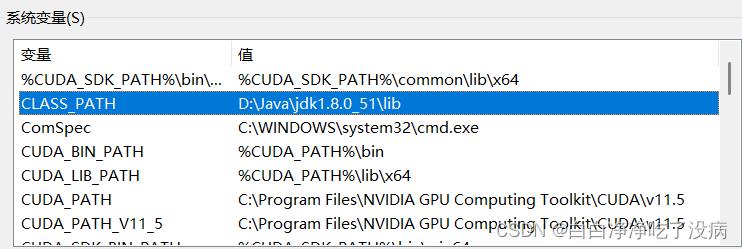
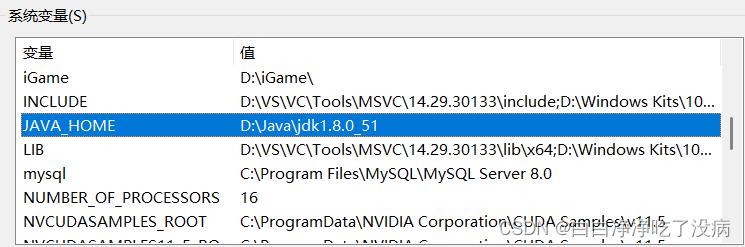
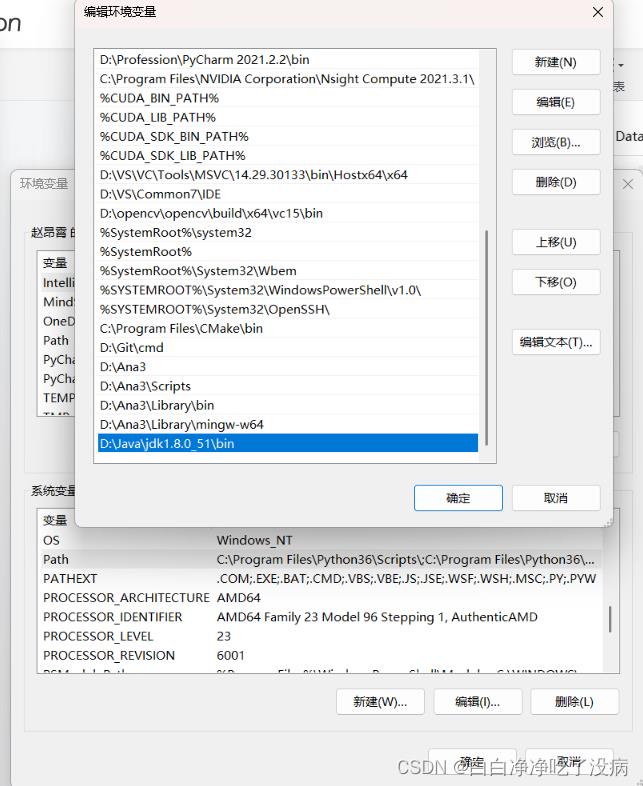
b) 在已有的系统变量 Path 中添加(新建)环境变量
根据自己的 jdk 所在目录添加,我的操作如下图所示:
3、测试 java 环境
win + R 输入 “cmd” 回车,输入 java -version,如下图所示:

如果看到版本信息,说明环境配置成功。
二、安装 Neo4j-3.5.5
1、下载 neo4j 软件包并解压到指定目录下
子目录如图所示:
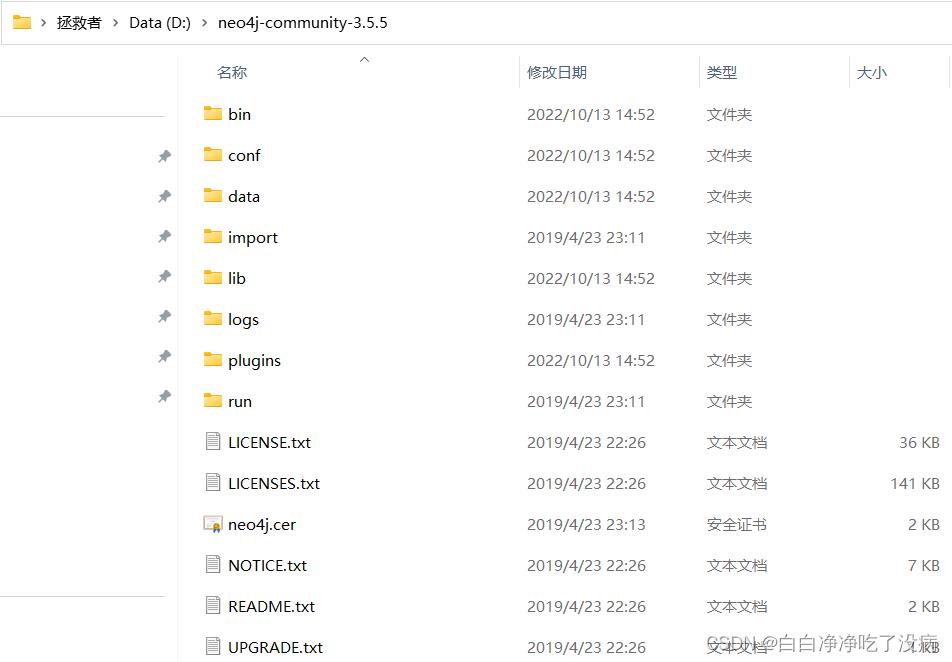
2、配置环境变量
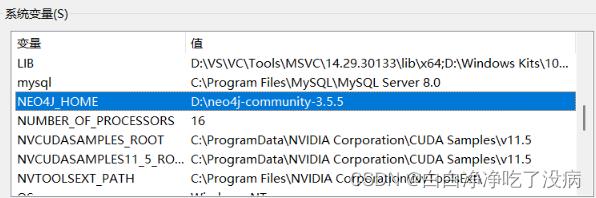
a)添加系统变量 NEO4J_HOME
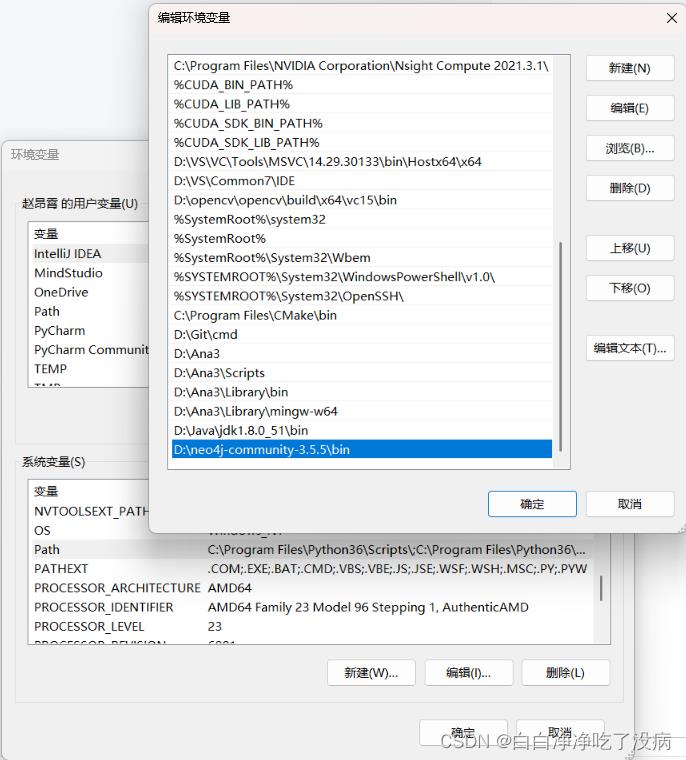
b) 在已有的系统变量 Path 中添加(新建)环境变量
3、测试 neo4j 服务是否可以正常开启
win + R 输入 “cmd” 回车,输入 neo4j.bat console,如下图所示则说明一路安装正确:

注意:此终端(服务)不要关闭,否则不能访问 Neo4j 图数据库系统
4、访问 Neo4j 图数据库系统
访问后,显示以下界面,说明此小节以上工作全部成功完成:
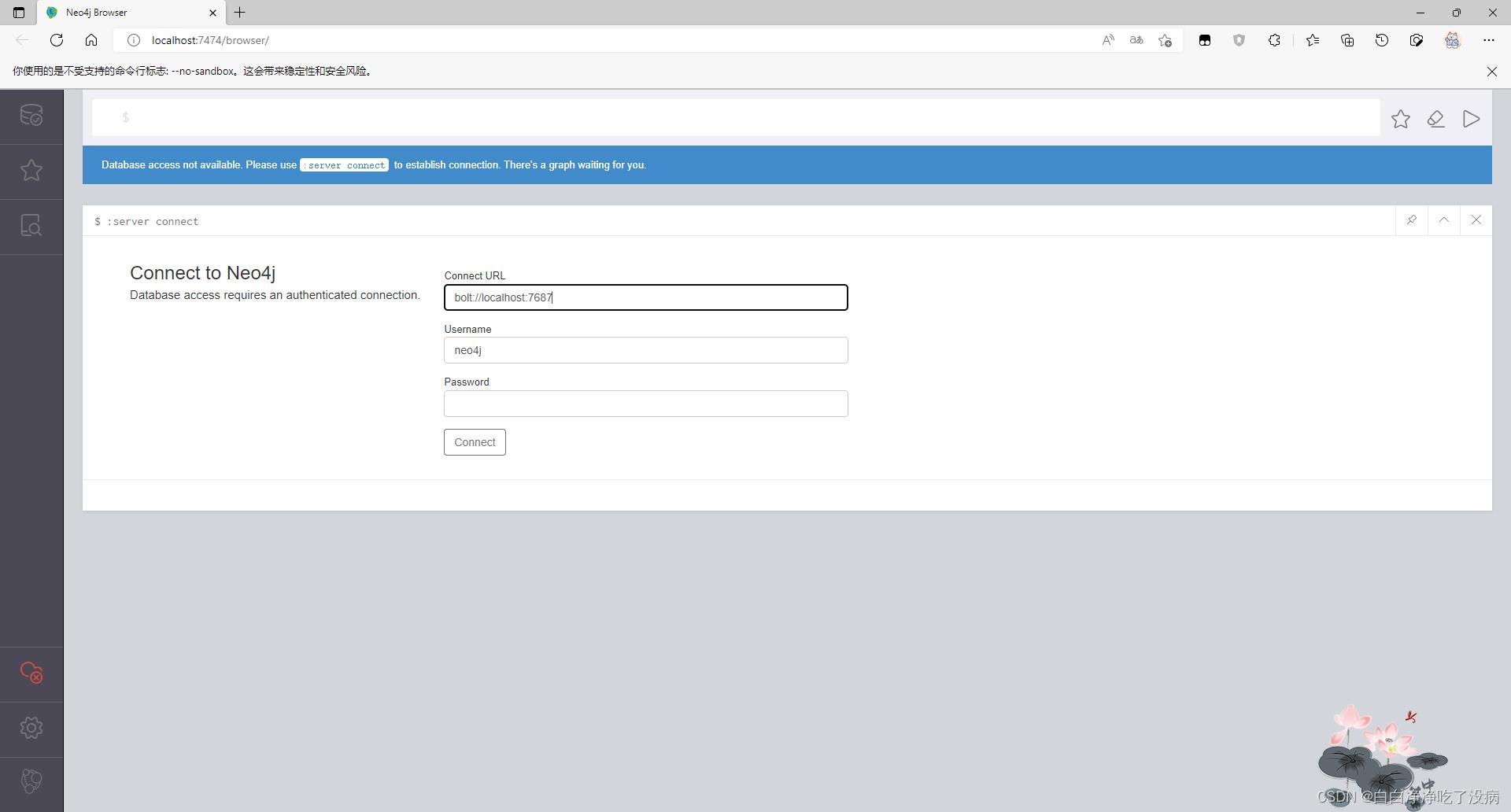
当连接成功的同时,终端也发生变化:

我们输入默认登录密码 neo4j ,点击 Connect,跳出更改密码的界面,如下图所示:
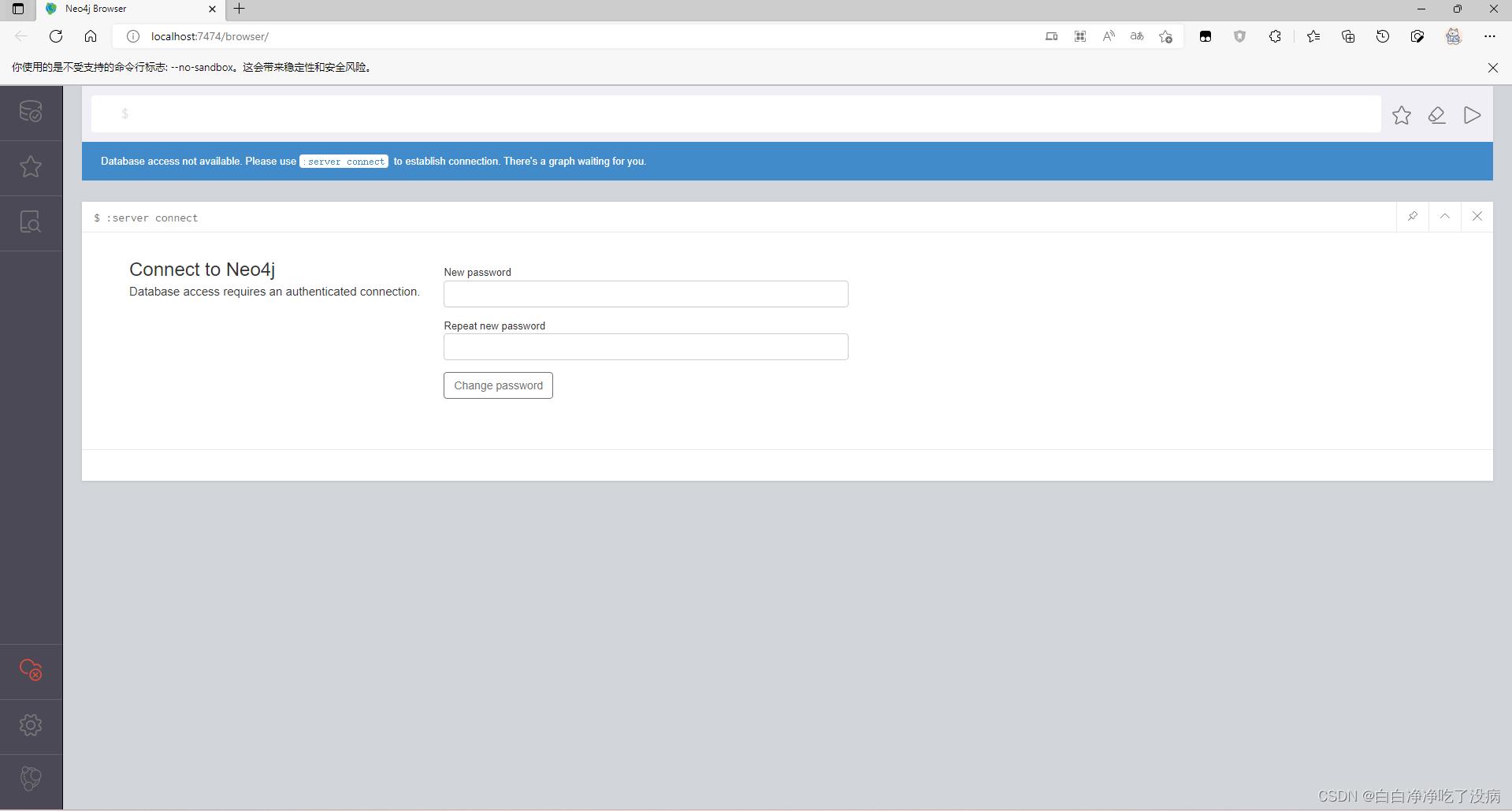
更改后,就成功进入主界面,如下图所示:
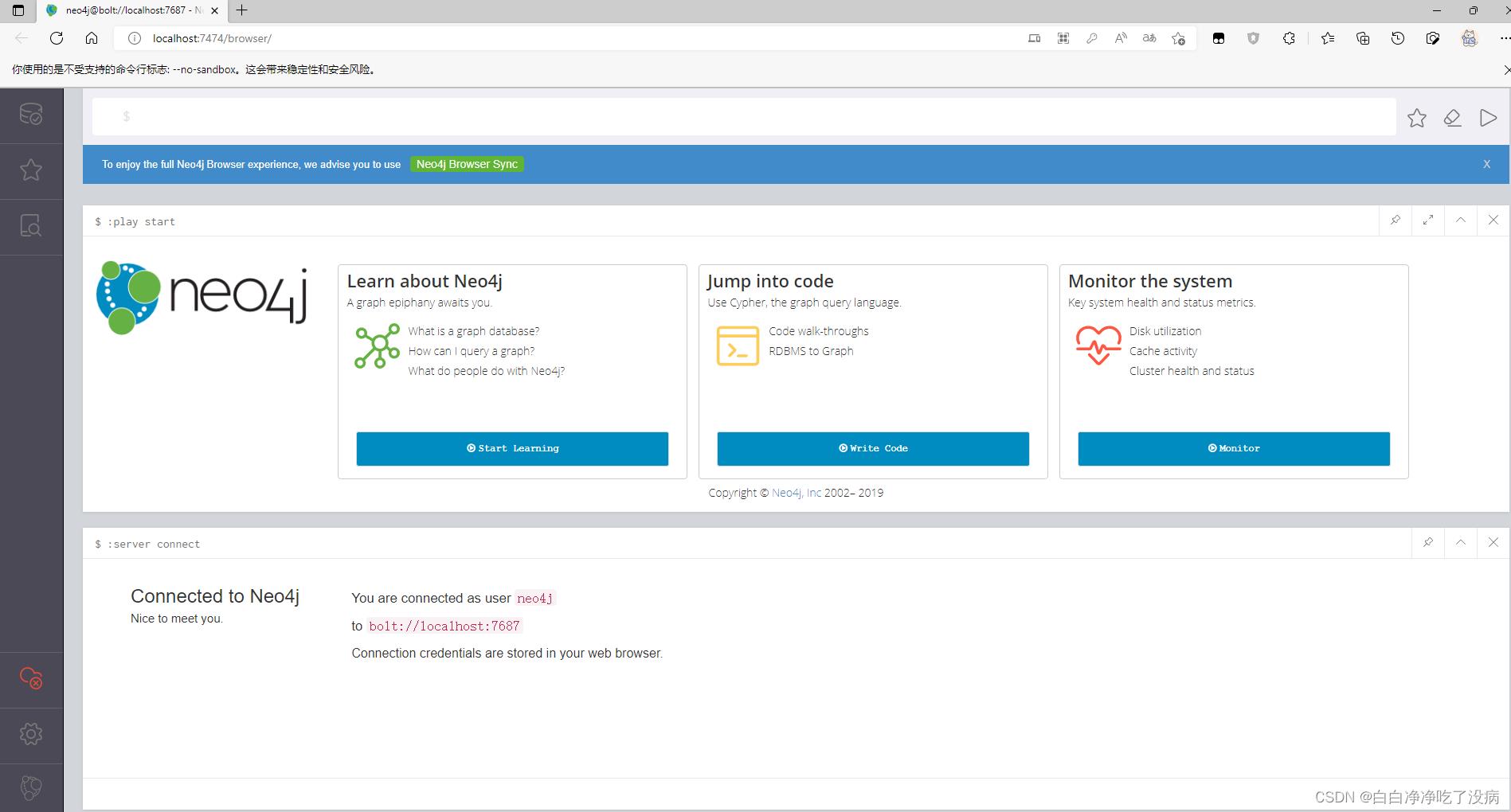
三、使用 Neo4j 数据库并可视化(网络安全)知识图谱
1、使用示例数据库
点击左侧边栏的小星星,再点击 Example Graph --> Movie Graph,界面如下:
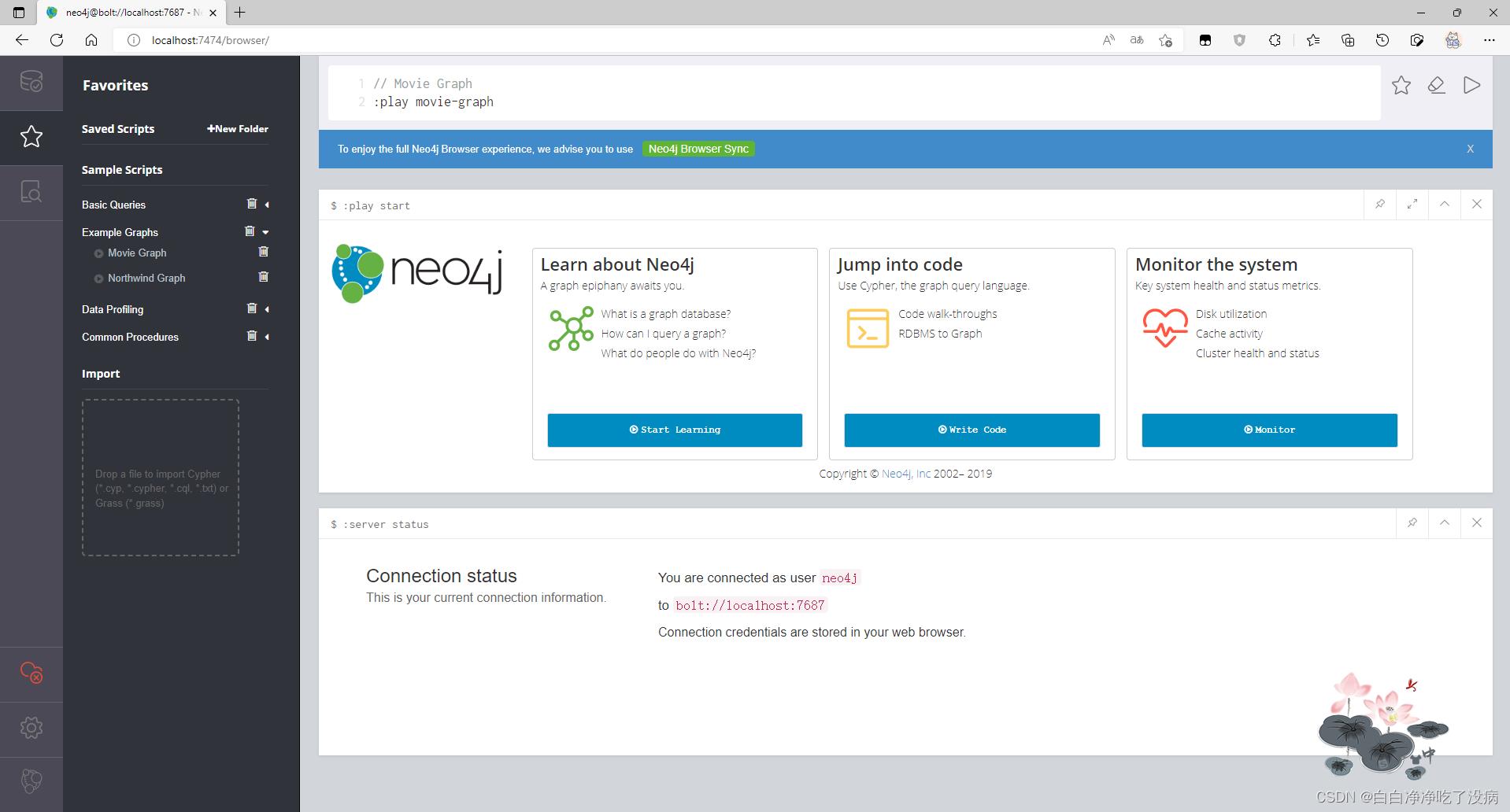
点击右侧的执行按钮,显示以下界面:
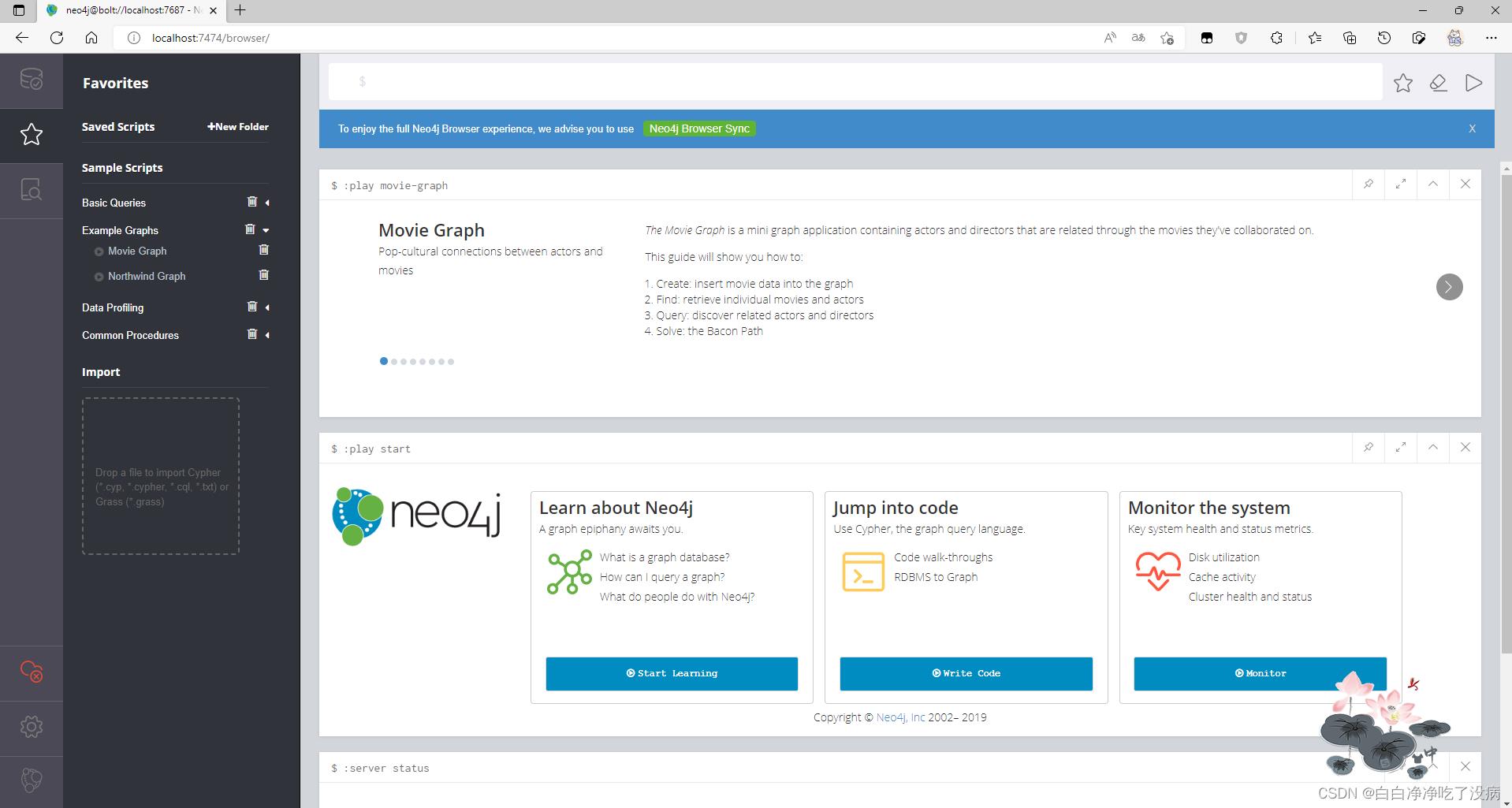
明显这是一个电影相关的图数据库,我们使用给定的查询命令试一试:
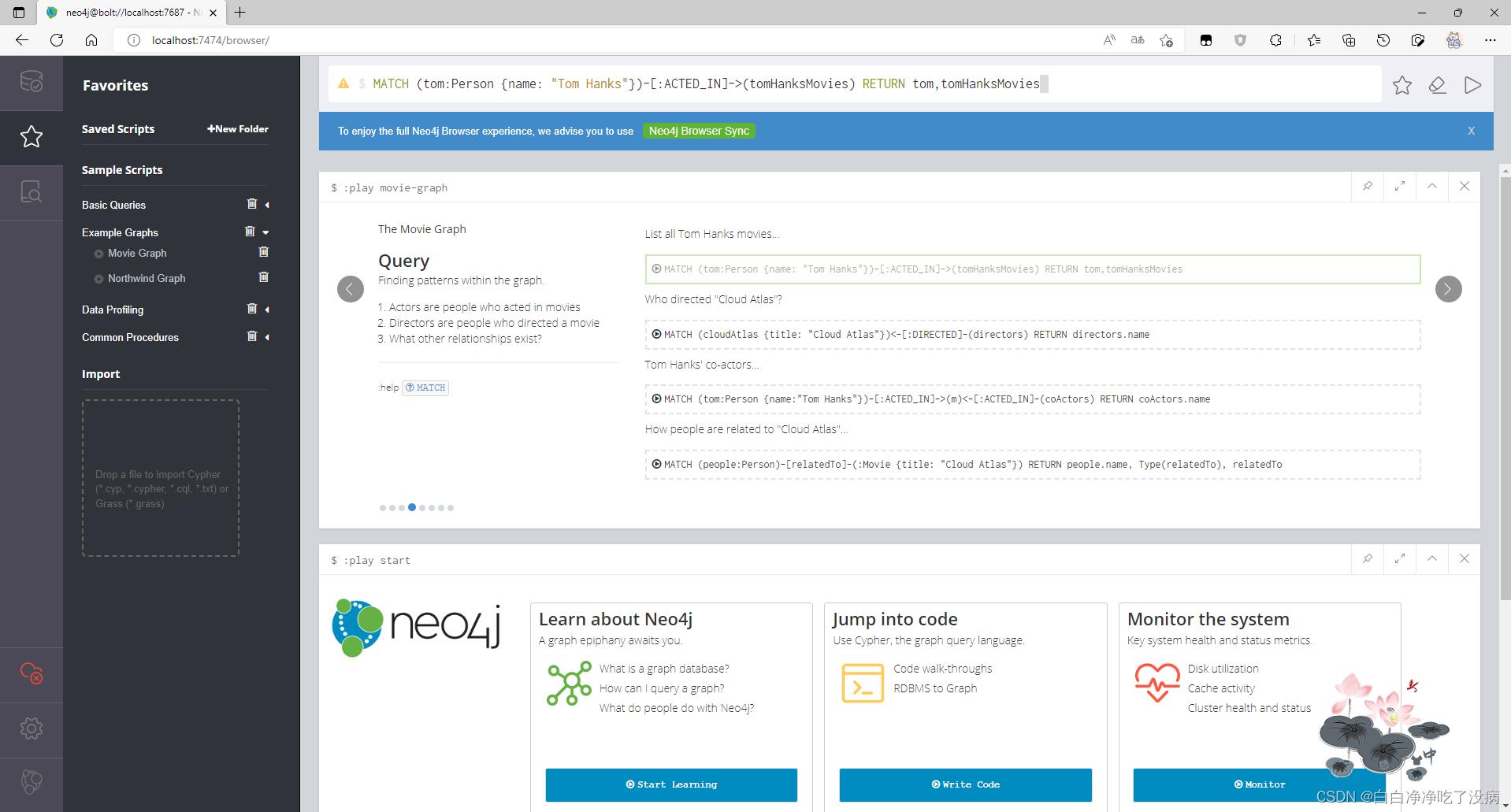
点击执行,这样我们就图数据库中查询到我们想要的结果的可视化结果,如下图所示,我们也可以得到表或代码等形式的返回结果,大家可以自行尝试:
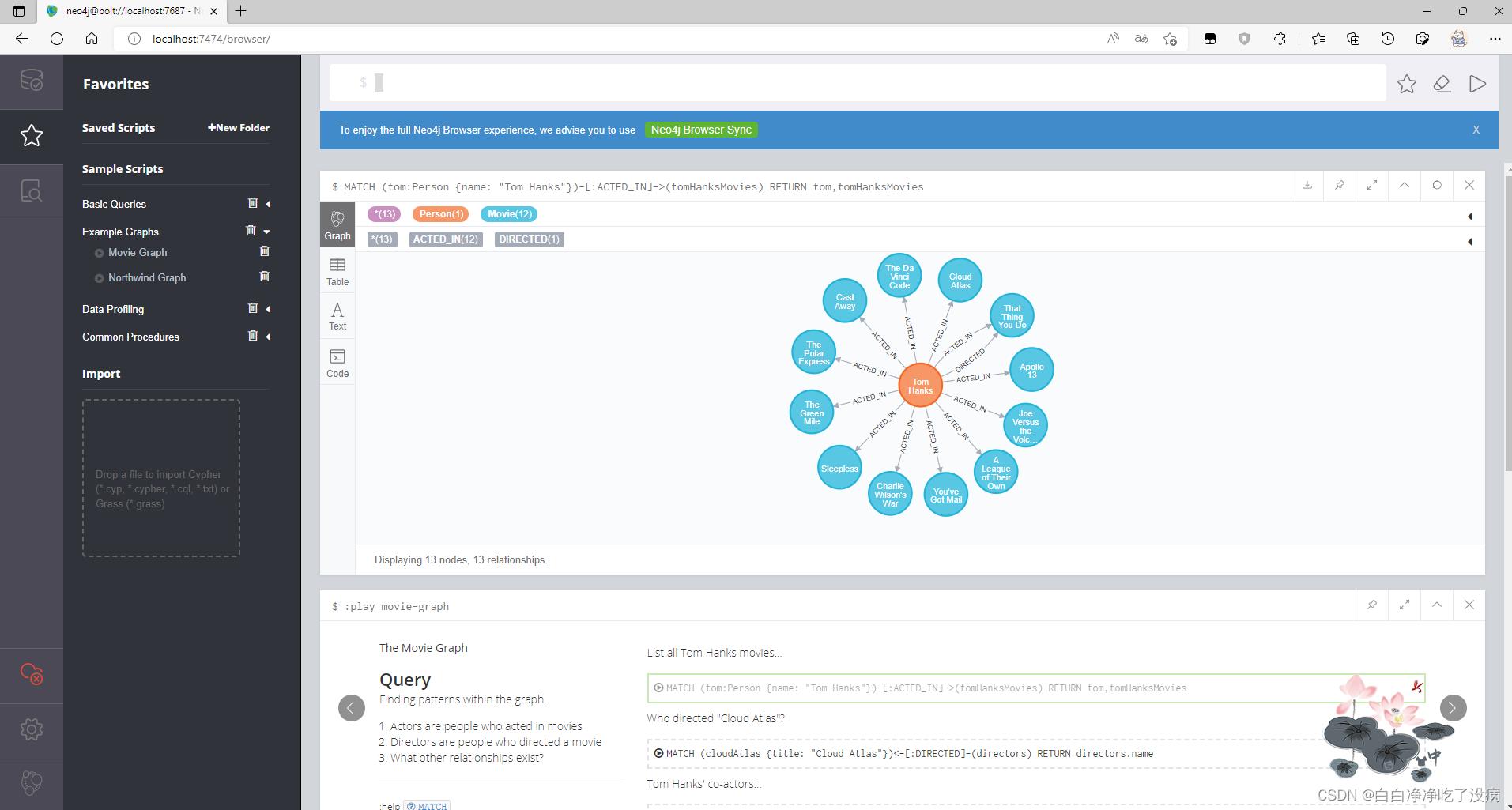
其他命令大家可以自行尝试...
2、生成我们自己的 CSV 数据,并为文件导入配置环境
a)构建并生成我们的数据(节点文件和边文件)
需要两个文件,一个是 entity.csv(数据格式:e1,兔子,my_entity)(节点文件),一个是 triples.csv(数据格式:e1,e2,爱吃)(边文件,因为边不能脱离实体存在,所以这个文件中既有实体,也有关系),可以用下面这段代码,替换数据集(训练集、验证集和测试集;它们的数据格式:兔子 胡萝卜 爱吃 )及上述两个目标文件的路径,用下面代码可以直接生成:
import csv
# 把每一行的实体加入列表进行编号(e1,e2,e3...),并存入字典
entity_dic =
# 为实体计数, 从 0 开始
ent_count = 0
def read_dataset(ds_path):
"""
输入:数据集的路径
返回:数据集中的数据构成的列表
"""
ds_list = []
with open(ds_path, 'r', encoding='UTF-8') as f:
reader = csv.reader(f)
lines = [row for row in reader]
for item in lines:
temp = []
item = item[0].split("\\t")
temp.append(item[0])
temp.append(item[1])
temp.append(item[2])
ds_list.append(temp)
f.close()
return ds_list
# 训练集、验证集和测试集的数据格式:兔子 胡萝卜 爱吃
train_data = read_dataset('D:/TSEE/datasets/neo4j_data/train.txt')
valid_data = read_dataset('D:/TSEE/datasets/neo4j_data/valid.txt')
test_data = read_dataset('D:/TSEE/datasets/neo4j_data/test.txt')
# 叠加三个数据集,用于后边对所有实体的编号
all_data = train_data + valid_data + test_data
def generate_entity_csv():
"""
输出:entity.csv文件(即实体与编号的对应文件)
数据格式:e1,兔子,my_entity
e2,胡萝卜,my_entity
"""
# 使用global关键字,在执行函数时,可以更改全局变量,防止再次创建同名的局部变量
global ent_count
for item in all_data:
if item[0] not in entity_dic.keys():
entity_dic[item[0]] = "e" + str(ent_count)
ent_count += 1
if item[1] not in entity_dic.keys():
entity_dic[item[1]] = "e" + str(ent_count)
ent_count += 1
with open('D:/TSEE/datasets/neo4j_data/entity.csv', 'w', encoding='utf-8') as o:
# print(item_dic)
o.write("entity:ID"+",")
o.write("name"+",")
o.write(":LABEL"+"\\n")
for item in entity_dic:
# print(item)
o.write(entity_dic[item] + ",")
o.write(item + ",")
o.write("my_entity" + "\\n")
o.close()
def generate_triples_csv():
"""
输出:triples.csv文件(即所有三元组数据)
数据格式:e1,e2,爱吃
"""
triples = []
for item in all_data:
temp_list = []
temp_list.append(entity_dic[item[0]])
temp_list.append(entity_dic[item[1]])
temp_list.append(item[2])
triples.append(temp_list)
with open("D:/TSEE/datasets/neo4j_data/triples.csv", 'w', encoding='utf-8') as o:
o.write(":START_ID" + ",")
o.write(":END_ID" + ",")
o.write(":TYPE" + "\\n")
for item in triples:
o.write(str(item[0]) + ",")
o.write(str(item[1]) + ",")
o.write(str(item[2]) + "\\n")
o.close()
generate_entity_csv()
generate_triples_csv()
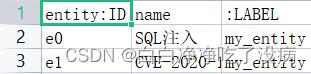
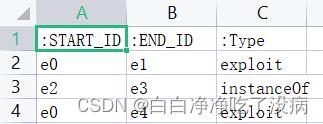
最终两个文件(数据的部分截图)如下图所示,其中第一行边的类型千万别忘了加(不管你是用脚本构造或者是手动创建)。如果忘加,Neo4j 不能有效识别文件,就会直接报错:
entity.csv 文件(节点文件):
triples.csv 文件(边文件):
b)为文件的导入配置环境
1)把如下图所示的默认的数据库,也就是 graph.db 目录给删掉:

2)打开如下我展示的目录下的文件:

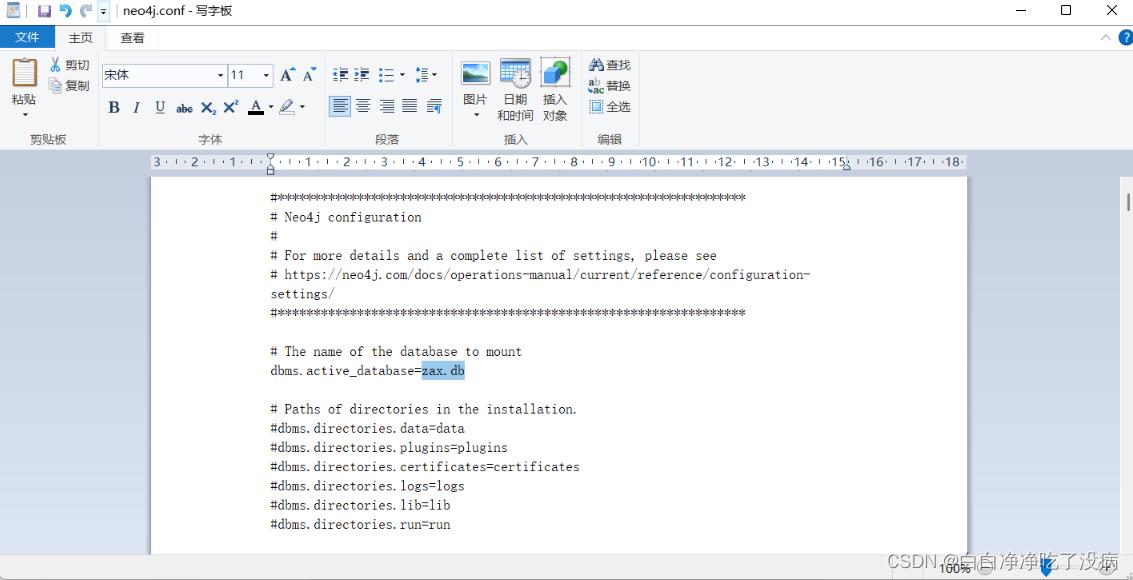
如下图所示,把 dbms.active_database=graph.db 这一行的 “#” 去掉;
并将 graph.db 更为任意名,我起的名字是 zax.db(不更改也可以,但上一步的 graph.db 目录删掉,要不然影响要导入自己数据所执行的命令的运行):
3、使用 neo4j 可视化(网络安全)知识图谱
关闭 neo4j 的运行窗口,再在 D:\\neo4j-community-3.5.5\\bin 下右键打开终端,执行以下命令:
.\\neo4j-import.bat --into D:\\\\neo4j-community-3.5.5\\\\data\\\\databases\\\\zax.db --id-type string --nodes D:\\\\neo4j-community-3.5.5\\\\entity.csv --relationships D:\\\\neo4j-community-3.5.5\\\\triples.csv如图所示:
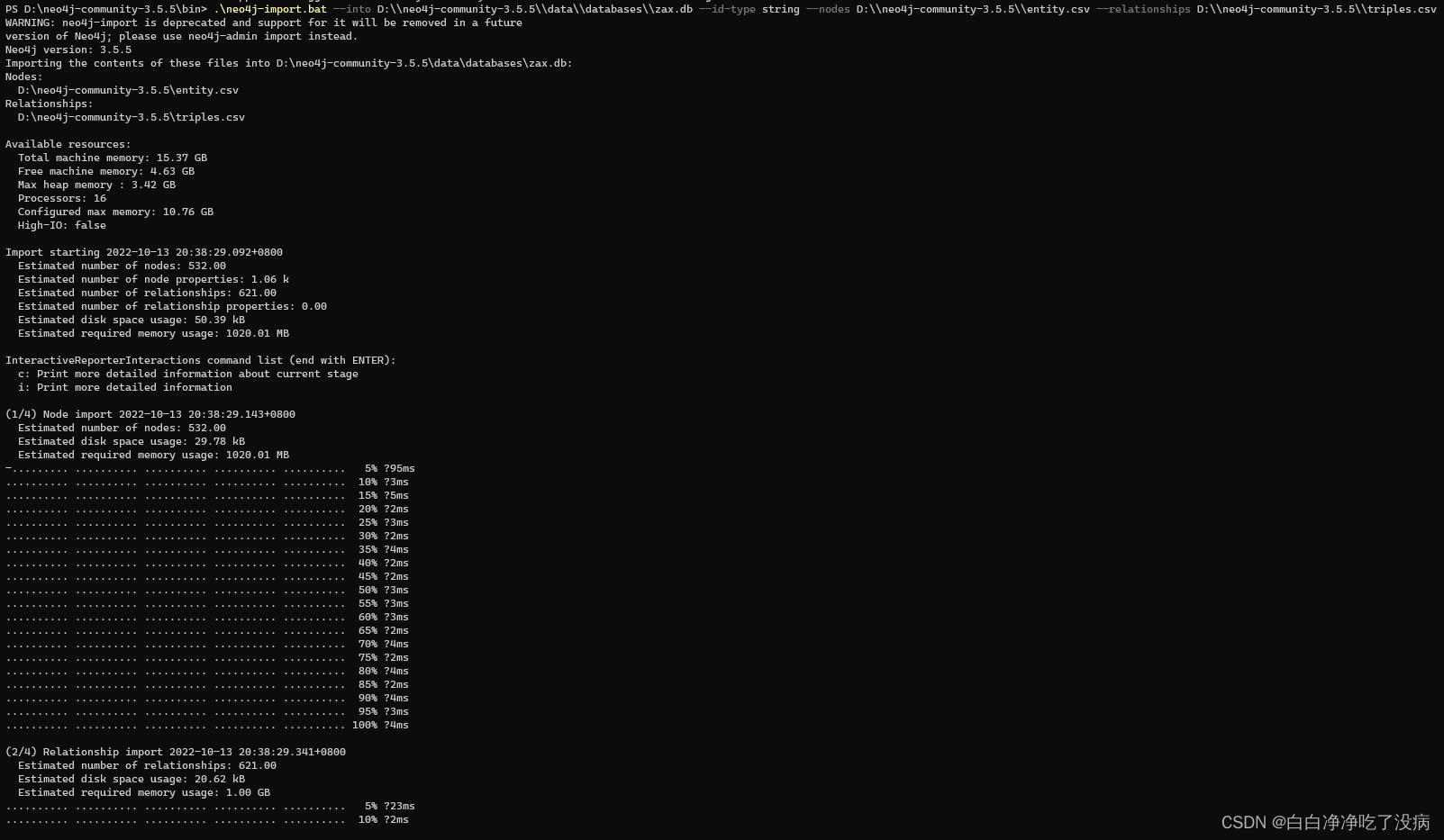
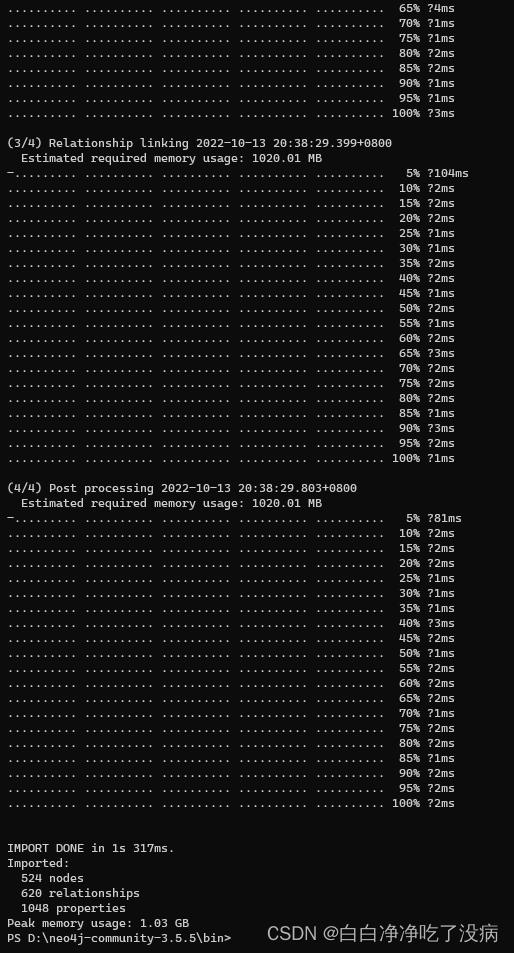
可以看到我们的两个 csv 文件已经成功导入,我们再重新打开 neo4j 服务,如下:
进入界面,点击左侧边栏的数据库图标,可以看到,我们已经成功可视化(网安)知识图谱:

大家也可以根据自己的数据来可视化知识图谱...
附录
一、Neo4j 简介及其数据结构
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。简单来说Neo4j是一个开源的基于Java开发,运行于JVM之上。
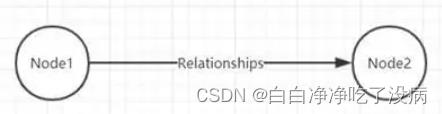
在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过 Relationships 所定义的关系相连起来,形成关系型网络结构。
二、关系型数据库和非关系型数据库
1. 关系型数据库
关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。主流的关系型数据库有Oracle、DB2、mysql、SQL Server等。推荐了解java中级程序员学习线路图。
2. 非关系型数据库
非关系型数据库,也称为NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。常见的非关系型数据库按照分类有:
键值(Key-Value): Redis、Memcached、Oracle BDB
列存储数据库:Cassandra、HBase、 Riak
文档型数据库:MongoDB、SequoiaDB
图形数据库:Neo4J、JanusGraph、TigerGraph
其中上述一、二节摘自:
什么是Neo4j?如何通过Neo4j构建《人民的名义》的关系图谱?
因此我们也可以在 Neo4J 中使用 NoSQL 命令创建结点和关系,直接可视化知识图谱:
NoSQL 简介 | 菜鸟教程NoSQL 简介 NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”。 在现代的计算系统上每天网络上都会产生庞大的数据量。这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd’s提出的关系模型的论文 'A relational model of data for large shared data banks”,这使得数据建模和应用程序编程更加简单。通.. https://www.runoob.com/mongodb/nosql.html当然,这也只是在数据量较小的情况下才可行,如果构建大型知识图谱,还得像我们之前那样,通过导入的方式来可视化知识图谱。
https://www.runoob.com/mongodb/nosql.html当然,这也只是在数据量较小的情况下才可行,如果构建大型知识图谱,还得像我们之前那样,通过导入的方式来可视化知识图谱。
补充:WARN The client is unauthorized due to authentication failure. 错误的解决办法:
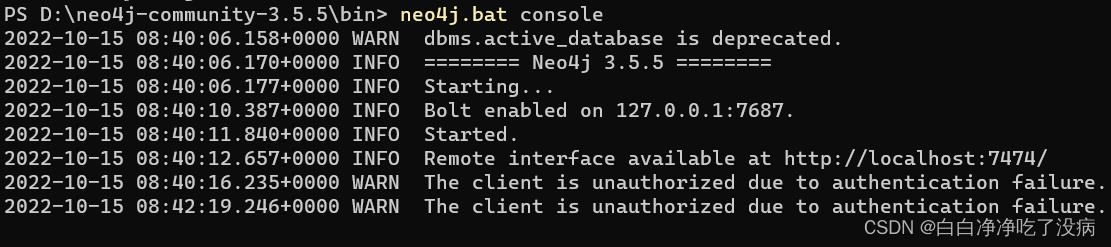
描述:当你导入其他数据库(如A.db)后,再导入另一个数据库(如B.db),并可视化后,你更改B 的图谱上的节点颜色或大小改不了,会在命令窗口报这个错,也就是授权问题。
我的理解:A 数据库在可视化图谱后,你的操作会保存在一个配置文件中(具体是哪个文件没必要管)。但当你可视化 B 数据库时,就会导入 A 的配置,当你针对 B 的图谱修改时,就对这个配置文件的内容作出了修改,但这没有经过 A 的允许 ,就会报错
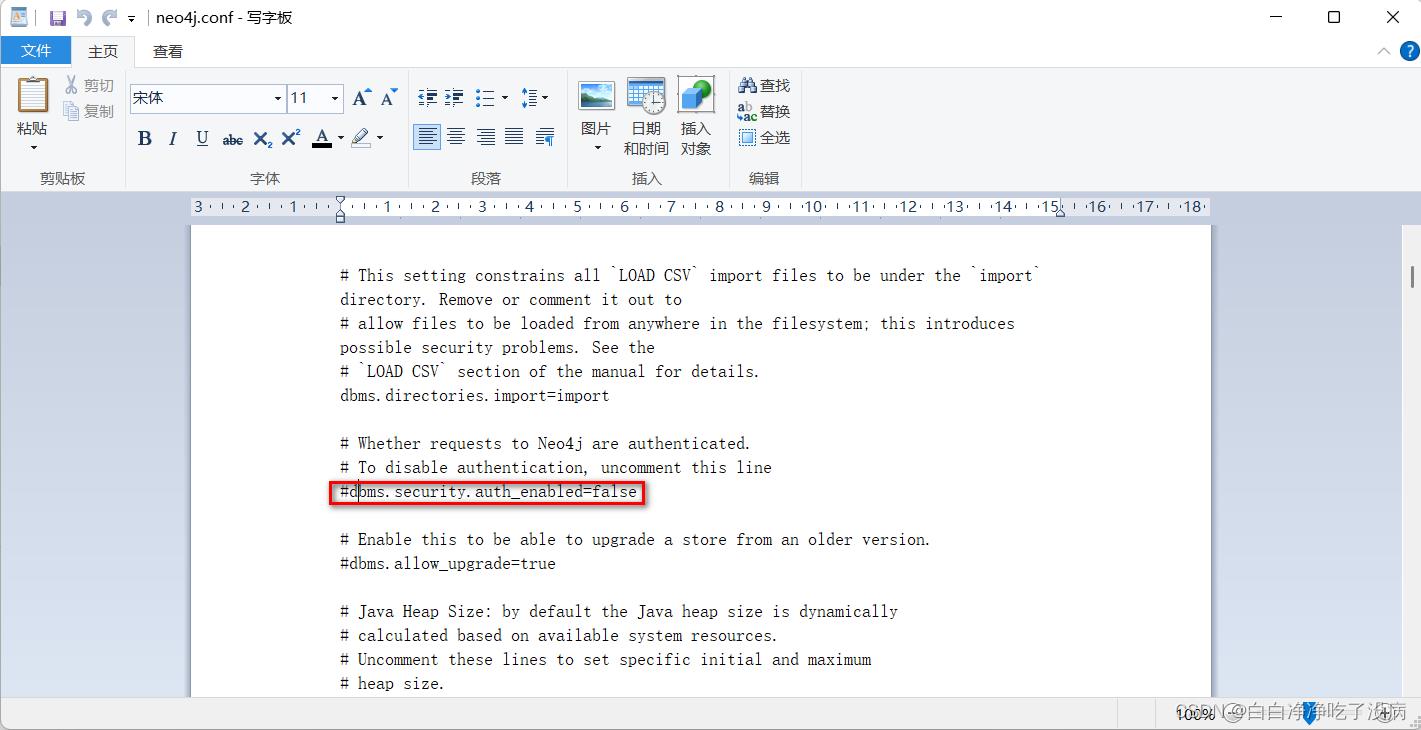
解决办法:到 D:\\neo4j-community-3.5.5\\conf 目录下修改 neo4j.conf 文件
去掉 下面这行 的 “ # ”,保证不进行任何授权验证
AngularJS中的Zoomable网络图
我想在AngularJS应用程序中可视化网络图。节点和边缘存储为JSON对象,稍后将添加和修改节点(例如每30秒一次)。我想使用Angular数据绑定在JSON对象更改时自动更新图形。该图将具有10-1000个节点。节点将是矩形文本节点,每个节点包含一个句子。我希望图表可以缩放和平移。
到目前为止我知道以下选项:
- ArborJS
使用Angular(使用
ParticleSystem.merge)可以轻松进行动态更新。然而,Arbor似乎不支持可缩放行为,并且似乎没有得到很好的支持。例如,single-node bug仍然没有得到解决。 - D3 有a zoomable force layout demo,各个地方都有关于使用d3和Angular的信息。 D3得到了很好的支持,但似乎比下面的选项更低。例如,创建a network graph with good-looking rectangular node labels似乎是不平凡的。
- VisJS VisJS支持可缩放的网络图,并且有a work-in-progress Angular library,但我不知道VisJS及其Angular库的可靠性如何。
- SigmaJS SigmaJS还支持可缩放的网络图,但我不知道它是否与Angular很好地配合。
- CytoscapeJS
- kmap
还有其他相关的图书馆吗?什么是用于此项目的最佳库,以及如何在库中实现这样的可缩放动态网络图?
我一直在以角度方式试验VisJs,到目前为止我真的很喜欢它。他们的网络既可以平移也可以缩放,您可以选择节点。文档很容易理解,他们的网站上有很多例子。由于vis的网络可以动态更新,我发现很容易将它集成到我的角度应用程序中。例如,我创建了这个指令:
app.directive('visNetwork', function() {
return {
restrict: 'E',
require: '^ngModel',
scope: {
ngModel: '=',
onSelect: '&',
options: '='
},
link: function($scope, $element, $attrs, ngModel) {
var network = new vis.Network($element[0], $scope.ngModel, $scope.options || {});
var onSelect = $scope.onSelect() || function(prop) {};
network.on('select', function(properties) {
onSelect(properties);
});
}
}
});
我在我的html中使用的是这样的:
<vis-network ng-model="network_data" options="network_options" on-select="onNodeSelect" id="previewNetwork">
</vis-network>
然后在我的控制器中我有以下内容:
$scope.nodes = new vis.DataSet();
$scope.edges = new vis.DataSet();
$scope.network_data = {
nodes: $scope.nodes,
edges: $scope.edges
};
$scope.network_options = {
hierarchicalLayout: {
direction: "UD"
}
};
$scope.onNodeSelect = function(properties) {
var selected = $scope.task_nodes.get(properties.nodes[0]);
console.log(selected);
};
$scope.nodes.add([
{id: 1, label: 'Node 1'},
{id: 2, label: 'Node 2'},
{id: 3, label: 'Node 3'},
{id: 4, label: 'Node 4'},
{id: 5, label: 'Node 5'}]);
$scope.edges.add([
{id: 1, from: 1, to: 2},
{id: 2, from: 3, to: 2}
]);
这应该是在Software Recommendation StackExchange上,但由于赏金,我不能投票结束。
GoJS支持您的所有要求,并与Angular(simple demo here)一起工作。 (内置模型存储,数据绑定,缩放和平移的JSON)
在D3中有一个带有源代码的网络地图的一个很好的演示/示例:http://christophergandrud.github.io/d3Network/功能就在那里,D3似乎与JSON很好。根据我的研究,这是可视化库的强大选择。许多其他库(石墨等)也支持相同的功能,但更难实现,并且不是非常活跃。
NVD3是为AngularJS设计的D3的变体,它也可以工作。在AngularJS中实现NVD3内的图形和图表比D3更容易。
在商业环境中,您还应该将yFiles for HTML视为一个库,以便为Angular(和AngularJS)支持的应用程序提供高质量的图形可视化。
它是一个功能齐全的图形绘制和编辑应用程序,可为您的所有图形和图表需求提供解决方案。
特别是1000个节点不是问题,至少如果这不是在低端的旧移动设备上,在这种情况下,只有简单的可视化才能提供良好的性能。但即便如此,使用独特的混合渲染引擎,可以在图表中同时利用所有SVG,Canvas和WebGL,甚至应该可行。
对于其上有一行文本的一千个节点,在低端设备上同时在屏幕上显示所有这些节点会有问题,但虚拟化在这里也有帮助。
有一些live, online demos显示不同级别的Angular(2+)和AngularJS集成,但如果您真的想在编程级别上使用该库,则应下载它并查看这些演示的非缩小源。对于Angular2 +开发,可以使用一整套TypeScript绑定,示例显示如何将角度数据绑定到图形可视化以及如何选择使用角度来模拟SVG可视化。当然,它们还包括核心图形可视化Angular组件。
披露:我为提供该图书馆的公司工作,但我并不代表我的雇主。
以上是关于使用 Neo4j 图数据库可视化(网络安全)知识图谱的主要内容,如果未能解决你的问题,请参考以下文章