数据结构与算法图(Graph)详解
Posted 逆流°只是风景-bjhxcc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法图(Graph)详解相关的知识,希望对你有一定的参考价值。
文章目录
图
【知识框架】

图的基本概念
在线性表中,数据元素之间是被串起来的,仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继。在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关。图是一种较线性表和树更加复杂的数据结构。在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
一、图的定义
图(Graph)是由顶点的有穷非空集合V ( G ) 和顶点之间边的集合E ( G )组成,通常表示为: G = ( V , E ) ,其中,G表示个图,V 是图G中顶点的集合,E是图G中边的集合。若V = v 1 , v 2 , . . . , v n ,则用∣ V ∣表示图G中顶点的个数,也称图G的阶,E = ( u , v ) ∣ u ∈ V , v ∈ V ,用∣ E ∣表示图G中边的条数。
注意:线性表可以是空表,树可以是空树,但图不可以是空图。就是说,图中不能一个顶点也没有,图的顶点集V一定非空,但边集E可以为空,此时图中只有顶点而没有边。
二、图的基本概念和术语
1、有向图
若E是有向边(也称弧)的有限集合时,则图G为有向图。弧是顶点的有序对,记为<v, w>,其中v,w是顶点,v称为弧尾,w称为弧头,<v,w>称为从顶点v到顶点w的弧,也称v邻接到w,或w邻接自v。
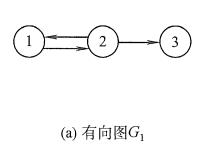
图(a)所示的有向图G1 可表示为
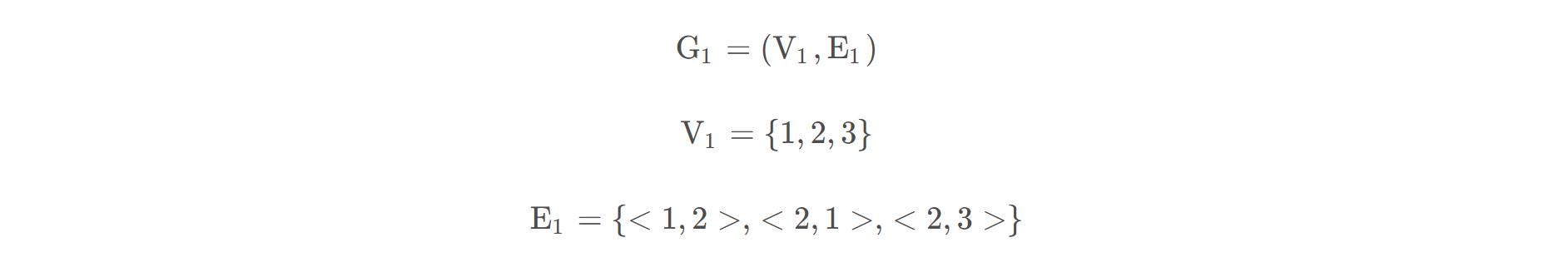
2、无向图
若E是无向边(简称边)的有限集合时,则图G为无向图。边是顶点的无序对,记为(v, w)或(w,v),因为(v,w)=(w,v), 其中v,w是顶点。可以说顶点w和顶点v互为邻接点。边(v, w)依附于顶点w和v,或者说边(v, w)和顶点v, w相关联。
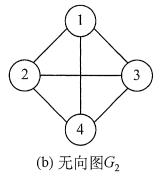
图(b)所示的无向图G2可表示为
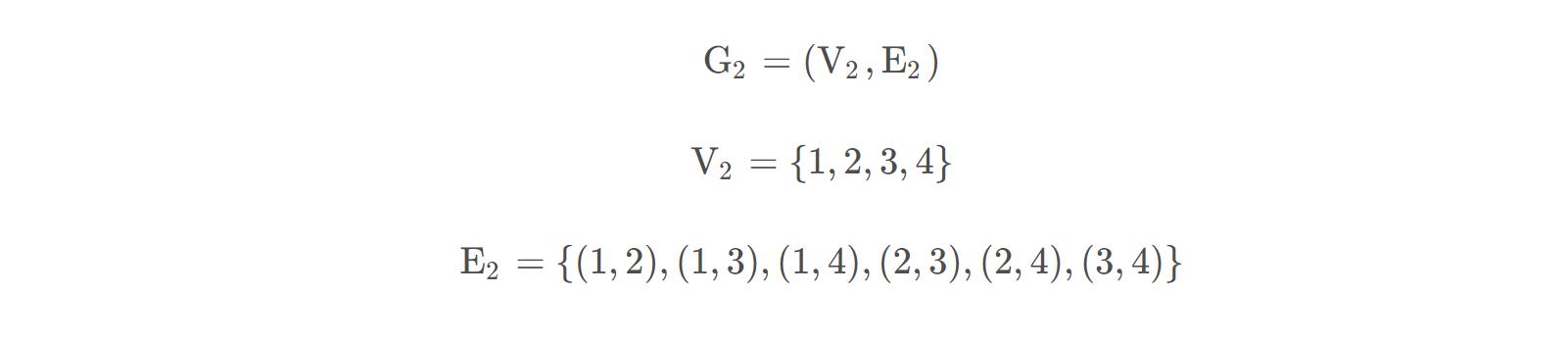
3、简单图
一个图G若满足:
①不存在重复边;
②不存在顶点到自身的边
则称图G为简单图。
上图中G 1 和G 2均为简单图。数据结构中仅讨论简单图。
4、多重图
若图G中某两个结点之间的边数多于一条,又允许顶点通过同一条边和自己关联,则G为多重图。多重图的定义和简单图是相对的。
5、完全图(也称简单完全图)
对于无向图,∣E∣的取值范围是0到n ( n − 1 ) / 2,有n ( n − 1 ) / 2 条边的无向图称为完全图,在完全图中任意两个顶点之间都存在边。对于有向图,∣E∣的取值范围是0到n ( n − 1 ) ,有n ( n − 1 ) 条弧的有向图称为有向完全图,在有向完全图中任意两个顶点之间都存在方向相反的两条弧。上图中G2 为无向完全图,而G3为有向完全图。
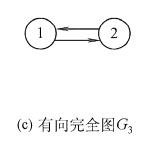
6、子图
设有两个图G = ( V , E ) 和G ′ = ( V ′ , E ′ ) ′, 若V ′ 是V的子集,且E ′是E的子集,则称G ′ 是G的子图。若有满足V ( G ′ ) = V ( G ) 的子图G′,则称其为G的生成子图。上图中G3 为G1 的子图。
注意:并非V和E的任何子集都能构成G的子图,因为这样的子集可能不是图,即E的子集中的某些边关联的顶点可能不在这个V的子集中。
7、连通、连通图和连通分量
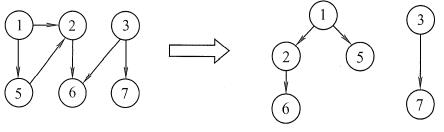
在无向图中,若从顶点v到顶点w有路径存在,则称v和w是连通的。若图G中任意两个顶点都是连通的,则称图G为连通图,否则称为非连通图。无向图中的极大连通子图称为连通分量。若一个图有n个顶点,并且边数小于n − 1,则此图必是非连通图。如下图(a)所示, 图G4有3个连通分量,如图(b)所示。
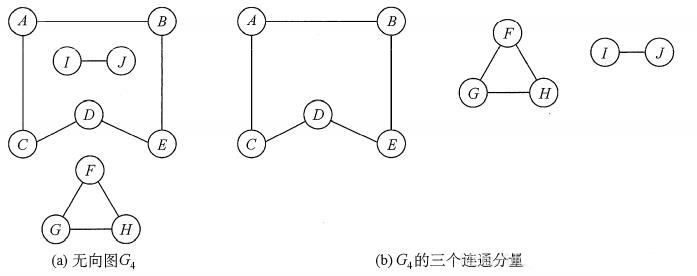
注意:弄清连通、连通图、连通分量的概念非常重要。首先要区分极大连通子图和极小连通子图,极大连通子图是无向图的连通分量,极大即要求该连通子图包含其所有的边;极小连通子图是既要保持图连通又要使得边数最少的子图。
8、强连通图、强连通分量
在有向图中,若从顶点v到顶点w和从顶点w到项点v之间都有路径,则称这两个顶点是强连通的。若图中任何一对顶点都是强连通的,则称此图为强连通图。有向图中的极大强连通子图称为有向图的强连通分量,图G 1 的强连通分量如下图所示。
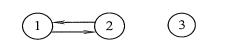
注意:强连通图、强连通分量只是针对有向图而言的。一般在无向图中讨论连通性,在有向图中考虑强连通性。
9、生成树、生成森林
连通图的生成树是包含图中全部顶点的一个极小连通子图。若图中顶点数为n,则它的生成树含有n − 1条边。对生成树而言,若砍去它的一条边,则会变成非连通图,若加上一条边则会形成一个回路。在非连通图中,连通分量的生成树构成了非连通图的生成森林。图G2的一个生成树如下图所示。
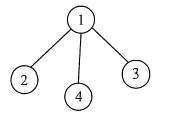
注意:包含无向图中全部顶点的极小连通子图,只有生成树满足条件,因为砍去生成树的任一条边,图将不再连通。
10、顶点的度、入度和出度
图中每个顶点的度定义为以该项点为一个端点的边的数目。
对于无向图,顶点v的度是指依附于该顶点的边的条数,记为TD(v)。
在具有n个顶点、e条边的无向图中
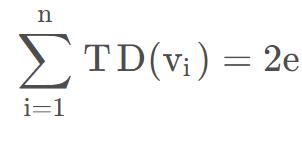
即无向图的全部顶点的度的和等于边数的2倍,因为每条边和两个顶点相关联。
对于有向图,顶点v的度分为入度和出度,入度是以顶点v为终点的有向边的数目,记为ID(v) ; 而出度是以顶点v为起点的有向边的数目,记为OD(v)。顶点v的度等于其入度和出度之和,即TD(v) = ID (v) + OD (v) 。
在具有n个顶点、e条边的有向图中
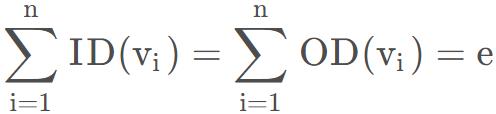
即有向图的全部顶点的入度之和与出度之和相等,并且等于边数。这是因为每条有向边都有一个起点和终点。
11、边的权和网
在一个图中,每条边都可以标上具有某种含义的数值,该数值称为该边的权值。这种边上带有权值的图称为带权图,也称网。
12、稠密图、稀疏图
边数很少的图称为稀疏图,反之称为稠密图。稀疏和稠密本身是模糊的概念,稀疏图和稠密图常常是相对而言的。一般当图G满足∣E∣ < ∣V∣ log∣V∣ 时,可以将G视为稀疏图。
13、路径、路径长度和回路
顶点vp 到顶点vq 之间的一条路径是指顶点序列vp , vi1 , vi2 , . . . , vim , vq ,当然关联的边也可以理解为路径的构成要素。路径上边的数目称为路径长度。第一个顶点和最后一个顶点相同的路径称为回路或环。若一个图有n个顶点,并且有大于n − 1条边,则此图一定有环。
14、 简单路径、简单回路
在路径序列中,顶点不重复出现的路径称为简单路径。除第一个顶点和最后一个顶点外,其余顶点不重复出现的回路称为简单回路。
15、距离
从顶点u出发到顶点v的最短路径若存在,则此路径的长度称为从u到v的距离。若从u到v根本不存在路径,则记该距离为无穷( ∞ ) (∞)(∞)。
16、有向树
一个顶点的入度为0、其余顶点的入度均为1的有向图,称为有向树。
图的存储结构
由于图的结构比较复杂,任意两个顶点之间都可能存在联系,因此无法以数据元素在内存中的物理位置来表示元素之间的关系,也就是说,图不可能用简单的顺序存储结构来表示。而多重链表的方式,要么会造成很多存储单元的浪费,要么又带来操作的不便。因此,对于图来说,如何对它实现物理存储是个难题,接下来我们介绍五种不同的存储结构。
一、邻接矩阵
图的邻接矩阵(Adjacency Matrix) 存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
设图G GG有n nn个顶点,则邻接矩阵A AA是一个n ∗ n n*nn∗n的方阵,定义为:
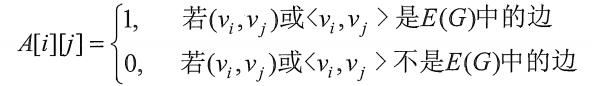
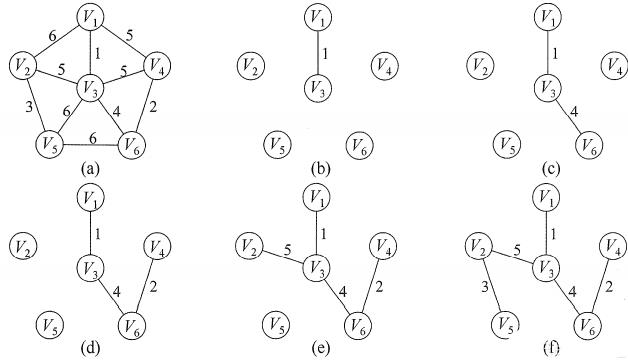
下图是一个无向图和它的邻接矩阵:
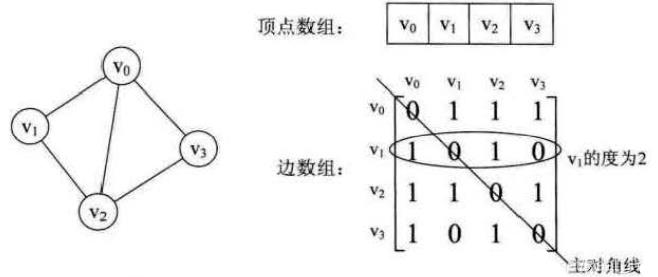
可以看出:
- 无向图的邻接矩阵一定是一个对称矩阵(即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的)。 因此,在实际存储邻接矩阵时只需存储上(或下)三角矩阵的元素。
- 对于无向图,邻接矩阵的第i行(或第i列)非零元素(或非∞元素)的个数正好是第i个顶点的度TD(vi) 。比如顶点v1 的度就是1 + 0 + 1 + 0 = 2。
求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍, A[i] [j] 为 1就是邻接点。
下图是有向图和它的邻接矩阵:
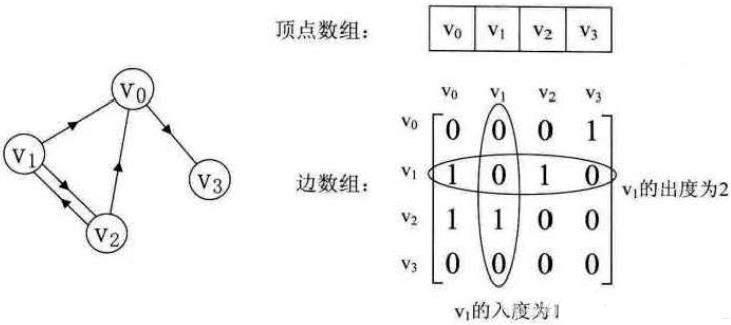
可以看出:
- 主对角线上数值依然为0。但因为是有向图,所以此矩阵并不对称。
- 有向图讲究入度与出度,顶点v1的入度为1,正好是第v1列各数之和。顶点v1 的出度为2,即第v 1v行的各数之和。
- 与无向图同样的办法,判断顶点vi 到vj 是否存在弧,只需要查找矩阵中A [i] [j] 是否为1即可。
对于带权图而言,若顶点vi和vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值
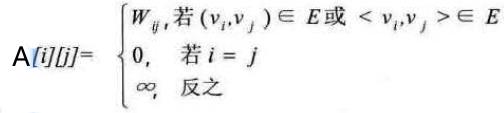
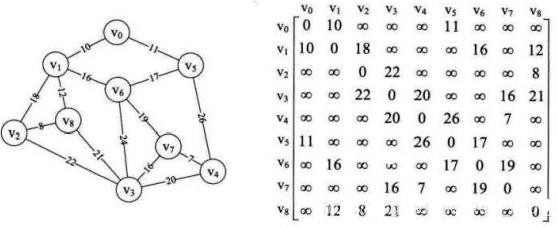
下图是有向网图和它的邻接矩阵:
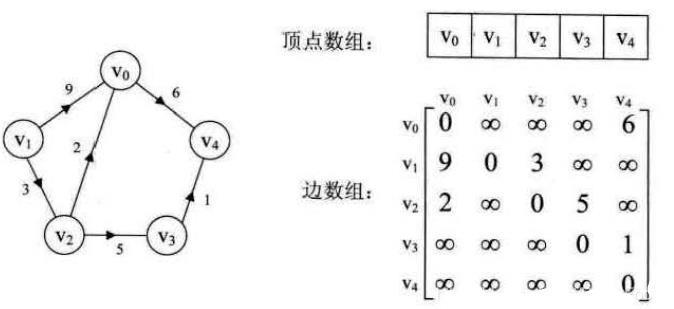
通过以上对无向图、有向图和网的描述,可定义出邻接矩阵的存储结构:
#define MaxVertexNum 100 //顶点数目的最大值
typedef char VertexType; //顶点的数据类型
typedef int EdgeType; //带权图中边上权值的数据类型
typedef struct
VertexType Vex[MaxVertexNum]; //顶点表
EdgeType Edge[MaxVertexNum][MaxVertexNum]; //邻接矩阵,边表
int vexnum, arcnum; //图的当前顶点数和弧树
MGraph;
注意: ①在简单应用中,可直接用二维数组作为图的邻接矩阵(顶点信息等均可省略)。
②当邻接矩阵中的元素仅表示相应的边是否存在时,EdgeType可定义为值为0和1的枚举类型。
③无向图的邻接矩阵是对称矩阵,对规模特大的邻接矩阵可采用压缩存储。
④邻接矩阵表示法的空间复杂度为O ( n 2 ),其中n为图的顶点数∣V |。
⑤用邻接矩阵法存储图,很容易确定图中任意两个顶点之间是否有边相连。但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大。
⑥ 稠密图适合使用邻接矩阵的存储表示。
二、邻接表
当一个图为稀疏图时(边数相对顶点较少),使用邻接矩阵法显然要浪费大量的存储空间,如下图所示:
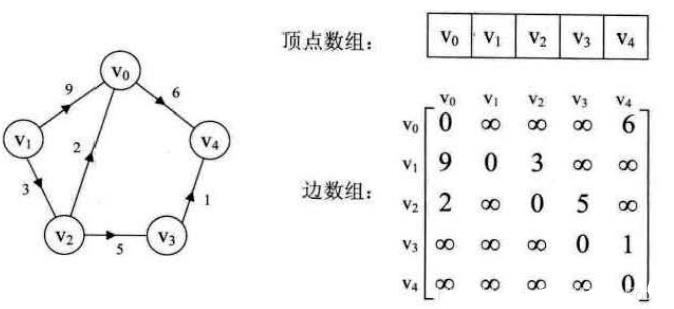
而图的邻接表法结合了顺序存储和链式存储方法,大大减少了这种不必要的浪费。
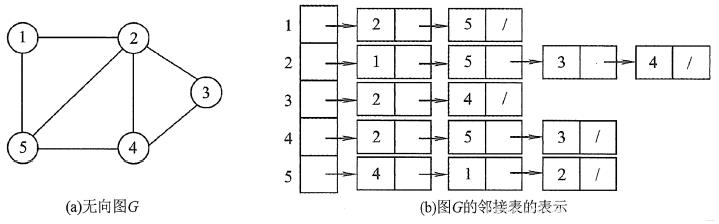
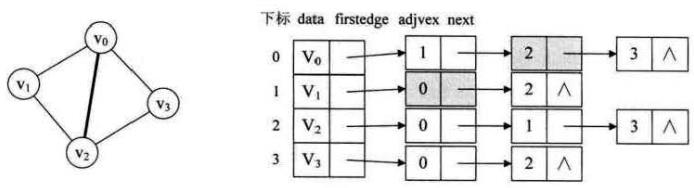
所谓邻接表,是指对图G中的每个顶点v i建立一个单链表,第i个单链表中的结点表示依附于顶点vi 的边(对于有向图则是以顶点v i为尾的弧),这个单链表就称为顶点v i的边表(对于有向图则称为出边表)。边表的头指针和顶点的数据信息采用顺序存储(称为顶点表),所以在邻接表中存在两种结点:顶点表结点和边表结点,如下图所示。

顶点表结点由顶点域(data)和指向第一条邻接边的指针(firstarc) 构成,边表(邻接表)结点由邻接点域(adjvex)和指向下一条邻接边的指针域(nextarc) 构成。
无向图的邻接表的实例如下图所示。
有向图的邻接表的实例如下图所示。
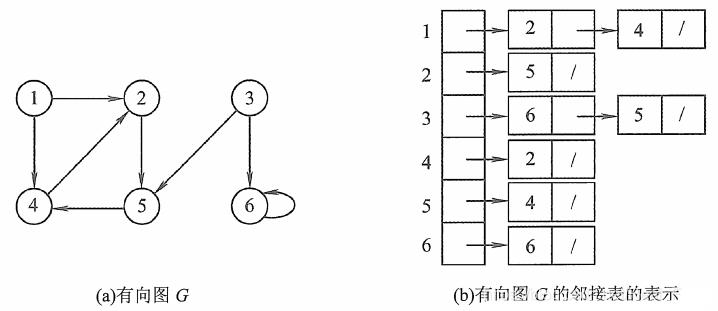
此时我们很容易就可以算出某个顶点的入度或出度是多少,判断两顶点是否存在弧也很容易实现。
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可。
图的邻接表存储结构定义如下:
#define MAXVEX 100 //图中顶点数目的最大值
type char VertexType; //顶点类型应由用户定义
typedef int EdgeType; //边上的权值类型应由用户定义
/*边表结点*/
typedef struct EdgeNode
int adjvex; //该弧所指向的顶点的下标或者位置
EdgeType weight; //权值,对于非网图可以不需要
struct EdgeNode *next; //指向下一个邻接点
EdgeNode;
/*顶点表结点*/
typedef struct VertexNode
Vertex data; //顶点域,存储顶点信息
EdgeNode *firstedge //边表头指针
VertexNode, AdjList[MAXVEX];
/*邻接表*/
typedef struct
AdjList adjList;
int numVertexes, numEdges; //图中当前顶点数和边数
图的邻接表存储方法具有以下特点
- 若G为无向图,则所需的存储空间为O ( ∣V∣ + 2 ∣E∣ ) ;若G GG为有向图,则所需的存储空间为O (∣V∣ + ∣E∣ ) 。前者的倍数2是由于无向图中,每条边在邻接表中出现了两次。
- 对于稀疏图,采用邻接表表示将极大地节省存储空间。
- 在邻接表中,给定一顶点,能很容易地找出它的所有邻边,因为只需要读取它的邻接表。在邻接矩阵中,相同的操作则需要扫描一行,花费的时间为O ( n ) 。但是,若要确定给定的两个顶点间是否存在边,则在邻接矩阵中可以立刻查到,而在邻接表中则需要在相应结点对应的边表中查找另一结点,效率较低。
- 在有向图的邻接表表示中,求一个给定顶点的出度只需计算其邻接表中的结点个数;但求其顶点的入度则需要遍历全部的邻接表。因此,也有人采用逆邻接表的存储方式来加速求解给定顶点的入度。当然,这实际上与邻接表存储方式是类似的。
- 图的邻接表表示并不唯一,因为在每个顶点对应的单链表中,各边结点的链接次序可以是任意的,它取决于建立邻接表的算法及边的输入次序。
三、十字链表
十字链表是有向图的一种链式存储结构。
对于有向图来说,邻接表是有缺陷的。关心了出度问题,想了解入度就必须要遍历整个图才能知道,反之,逆邻接表解决了入度却不了解出度的情况。有没有可能把邻接表与逆邻接表结合起来呢?答案是肯定的,就是把它们整合在一起。这就是我们现在要介绍的有向图的一种存储方法:十字链表(Orthogonal List)。
我们重新定义顶点表结点结构如下表所示。

其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点,firstout 表示出边表头指针,指向该顶点的出边表中的第一个结点。
重新定义的边表结点结构如下表所示。

其中tailvex 是指弧起点在顶点表的下标,headvex 是指弧终点在顶点表中的下标,headlink是指入边表指针域,指向终点相同的下一条边,taillink是指边表指针域,指向起点相同的下一条边。如果是网,还可以再增加一个weight域来存储权值。
接下来通过一个例子详细介绍十字链表的结构。
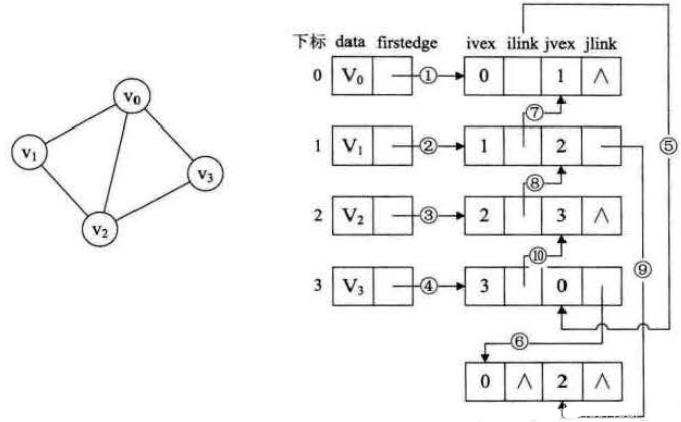
如下图所示,顶点依然是存入一个一维数组 V0, V1 , V2, V3 ,实线箭头指针的图示完全与的邻接表的结构相同。就以顶点V0 来说,firstout 指向的是出边表中的第一个结点V3 。所以V0 边表结点的headvex = 3 ,而tailvex就是当前顶点V0 的下标0,由于V0只有一个出边顶点,所以headlink和taillink都是空。
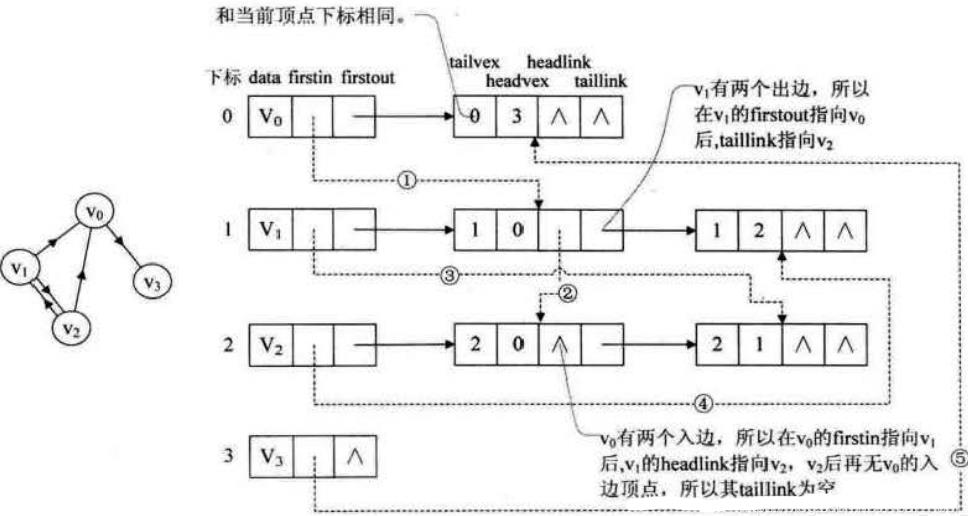
我们重点需要来解释虚线箭头的含义,它其实就是此图的逆邻接表的表示。对于V0 来说,它有两个顶点V1 和V2 的入边。因此V0 的firstin指向顶点V1 的边表结点中headvex为0的结点,如上图右图中的①。接着由入边结点的headlink指向下一个入边顶点V2 ,如图中的②。对于顶点V1 ,它有一个入边顶点V2 ,所以它的firstin指向顶点V2 的边表结点中headvex为1的结点,如图中的③。顶点V2 和V3 也是同样有一个入边顶点,如图中④和⑤。
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起, 这样既容易找到以V1 为尾的弧,也容易找到以V! 为头的弧,因而容易求得顶点的出度和入度。而且它除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图的应用中,十字链表是非常好的数据结构模型。
四、邻接多重表
邻接多重表是无向图的另一种链式存储结构。
在邻接表中,容易求得顶点和边的各种信息,但在邻接表中求两个顶点之间是否存在边而对边执行删除等操作时,需要分别在两个顶点的边表中遍历,效率较低。比如下图中,若要删除左图的( V0 , V2 ) 这条边,需要对邻接表结构中右边表的阴影两个结点进行删除操作,显然这是比较烦琐的。
重新定义的边表结点结构如下表所示。

其中ivex和jvex是与某条边依附的两个顶点在顶点表中下标。ilink 指向依附顶点ivex的下一条边,jlink 指向依附顶点jvex的下一条边。这就是邻接多重表结构。
每个顶点也用一一个结点表示,它由如下所示的两个域组成。

其中,data 域存储该顶点的相关信息,firstedge 域指示第一条依附于该顶点的边。
我们来看结构示意图的绘制过程,理解了它是如何连线的,也就理解邻接多重表构造原理了。如下图7所示,左图告诉我们它有4个顶点和5条边,显然,我们就应该先将4个顶点和5条边的边表结点画出来。
我们开始连线,如图,首先连线的①②③④就是将顶点的firstedge指向一条边,顶点下标要与ivex的值相同,这很好理解。接着,由于顶点V0 的( V0 , V1 )边的邻边有(V0 , V3) 和( V 0 , V 2 )。 因此⑤⑥的连线就是满足指向下一条依附于顶点V0的边的目标,注意ilink指向的结点的jvex一定要和它本身的ivex的值相同。同样的道理,连线⑦就是指(V1 , V0 )这条边,它是相当于顶点V1指向(V1,V2 ) 边后的下一条。V2有三条边依附,所以在③之后就有了⑧⑨。连线④的就是顶点V3在连线④之后的下一条边。 左图一共有5条边,所以右图有10条连线,完全符合预期。
到这里,可以明显的看出,邻接多重表与邻接表的差别,仅仅是在于同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。 这样对边的操作就方便多了,若要删除左图的( V0 , V2) 这条边,只需要将右图的⑥⑨的链接指向改为NULL即可。
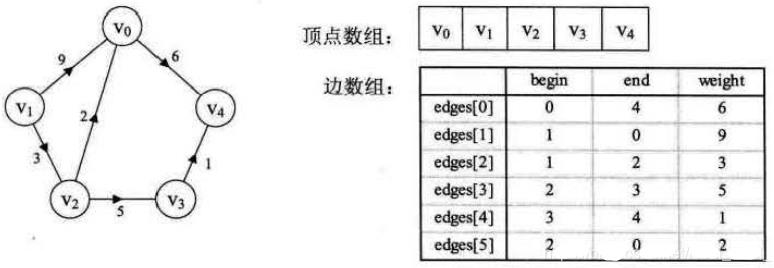
五、边集数组
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、 终点下标(end)和权(weight)组成,如下图所示。显然边集数组关注的是边的集合,在边集数组中要查找一个顶点的度需要扫描整个边数组,效率并不高。因此它更适合对边依次进行处理的操作,而不适合对顶点相关的操作。
图的遍历
图的遍历是和树的遍历类似,我们希望从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次, 这一过程就叫做图的遍历(Traversing Graph)。
对于图的遍历来,通常有两种遍历次序方案:它们是深度优先遍历和广度优先遍历。
一、深度优先遍历
深度优先遍历(Depth First Search),也有称为深度优先搜索,简称为DFS。
1、DFS算法
深度优先搜索类似于树的先序遍历。如其名称中所暗含的意思一样,这种搜索算法所遵循的搜索策略是尽可能“深”地搜索一个图。它的基本思想如下:首先访问图中某一起始顶点v,然后由v出发,访问与v邻接且未被访问的任一顶点w1 ,再访问与w1 邻接且未被访问的任一顶点…重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直至图中所有顶点均被访问过为止。
般情况下,其递归形式的算法十分简洁,算法过程如下:
bool visited[MAX_VERTEX_NUM]; //访问标记数组
/*从顶点出发,深度优先遍历图G*/
void DFS(Graph G, int v)
int w;
visit(v); //访问顶点
visited[v] = TRUE; //设已访问标记
//FirstNeighbor(G,v):求图G中顶点v的第一个邻接点,若有则返回顶点号,否则返回-1。
//NextNeighbor(G,v,w):假设图G中顶点w是顶点v的一个邻接点,返回除w外顶点v
for(w = FirstNeighbor(G, v); w>=0; w=NextNeighor(G, v, w))
if(!visited[w]) //w为u的尚未访问的邻接顶点
DFS(G, w);
/*对图进行深度优先遍历*/
void DFSTraverse(MGraph G)
int v;
for(v=0; v<G.vexnum; ++v)
visited[v] = FALSE; //初始化已访问标记数据
for(v=0; v<G.vexnum; ++v) //从v=0开始遍历
if(!visited[v])
DFS(G, v);
以下面这个无向图为例
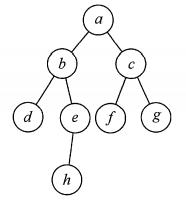
其深度优先遍历的结果为a b d e h c f g abdehcfgabdehcfg
2、DFS算法的性能分析
DFS算法是一个递归算法,需要借助一个递归工作栈,故其空间复杂度为O ( V ) O(V)O(V)。
对于n个顶点e条边的图来说,邻接矩阵由于是二维数组,要查找每个顶点的邻接点需要访问矩阵中的所有元素,因此都需要O ( V 2 ) O(V^2)O(V
2
)的时间。而邻接表做存储结构时,找邻接点所需的时间取决于顶点和边的数量,所以是O ( V + E ) O(V+E)O(V+E)。 显然对于点多边少的稀疏图来说,邻接表结构使得算法在时间效率上大大提高。
对于有向图而言,由于它只是对通道存在可行或不可行,算法上没有变化,是完全可以通用的。
3、深度优先的生成树和生成森林
深度优先搜索会产生一棵深度优先生成树。 当然,这是有条件的,即对连通图调用DFS才能产生深度优先生成树,否则产生的将是深度优先生成森林,如下图所示。基于邻接表存储的深度优先生成树是不唯一的 。
二、广度优先遍历
广度优先遍历(Breadth First Search),又称为广度优先搜索,简称BFS。
1、BFS算法
如果说图的深度优先遍历类似树的前序遍历,那么图的广度优先遍历就类似于树的层序遍历了。
广度优先搜索是一种分层的查找过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此它不是一个递归的算法。为了实现逐层的访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点。
以下是广度优先遍历的代码:
/*邻接矩阵的广度遍历算法*/
void BFSTraverse(MGraph G)
int i, j;
Queue Q;
for(i = 0; i<G,numVertexes; i++)
visited[i] = FALSE;
InitQueue(&Q); //初始化一辅助用的队列
for(i=0; i<G.numVertexes; i++)
//若是未访问过就处理
if(!visited[i])
vivited[i] = TRUE; //设置当前访问过
visit(i); //访问顶点
EnQueue(&Q, i); //将此顶点入队列
//若当前队列不为空
while(!QueueEmpty(Q))
DeQueue(&Q, &i); //顶点i出队列
//FirstNeighbor(G,v):求图G中顶点v的第一个邻接点,若有则返回顶点号,否则返回-1。
//NextNeighbor(G,v,w):假设图G中顶点w是顶点v的一个邻接点,返回除w外顶点v
for(j=FirstNeighbor(G, i); j>=0; j=NextNeighbor(G, i, j))
//检验i的所有邻接点
if(!visited[j])
visit(j); //访问顶点j
visited[j] = TRUE; //访问标记
EnQueue(Q, j); //顶点j入队列
以下面这个无向图为例
其广度优先遍历的结果为a b c d e f g h abcdefghabcdefgh。
2、BFS算法性能分析
无论是邻接表还是邻接矩阵的存储方式,BFS 算法都需要借助一个辅助队列Q, n个顶点均需入队一次,在最坏的情况下,空间复杂度为O (V) 。
采用邻接表存储方式时,每个顶点均需搜索一次(或入队一次), 在搜索任一顶点的邻接点时,每条边至少访问一次,算法总的时间复杂度为O ( V + E ) 。采用邻接矩阵存储方式时,查找每个顶点的邻接点所需的时间为O ( V ) ,故算法总的时间复杂度为O ( V2 ) 。
注意:图的邻接矩阵表示是唯一的,但对于邻接表来说,若边的输入次序不同,生成的邻接表也不同。因此,对于同样一个图,基于邻接矩阵的遍历所得到的DFS序列和BFS序列是唯一的,基于邻接表的遍历所得到的DFS序列和BFS序列是不唯一的。
三、图的遍历与图的连通性
图的遍历算法可以用来判断图的连通性。
对于无向图来说,若无向图是连通的,则从任一结点出发, 仅需一次遍历就能够访问图中的所有顶点;若无向图是非连通的,则从某一个顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。对于有向图来说,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有顶点。
故在BFSTraverse ()或DFSTraverse ()中添加了第二个for循环,再选取初始点,继续进行遍历,以防止一次无法遍历图的所有顶点。对于无向图,上述两个函数调用BFS (G,i)或DFS(G,i)的次数等于该图的连通分量数;而对于有向图则不是这样,因为一个连通的有向图分为强连通的和非强连通的,它的连通子图也分为强连通分量和非强连通分量,非强连通分量一次调用BFS (G, i)或DFS (G, i)无法访问到该连通分量的所有顶点。
如下图所示为有向图的非强连通分量。

最小生成树
一个连通图的生成树是一个极小的连通子图,它含有图中全部的顶点,但只有足以构成一棵树的n − 1 n-1n−1条边,若砍去它的一条边,则会使生成树变成非连通图;若给它增加一条边,则会形成图中的一条回路。对于一个带权连通无向图G = ( V , E ) G=(V, E)G=(V,E),生成树不同,其中边的权值之和最小的那棵生成树(构造连通网的最小代价生成树),称为G的最小生成树(Minimum-Spanning-Tree, MST)。
构造最小生成树有多种算法,但大多数算法都利用了最小生成树的下列性质:假设G = ( V , E ) G=(V, E)G=(V,E)是一个带权连通无向图,U UU是顶点集V VV的一个非空子集。若( u , v ) (u,v)(u,v)是一条具有最小权值的边,其中u ∈ U , v ∈ V − U u∈U,v∈V-Uu∈U,v∈V−U,则必存在一棵包含边( u , v ) (u, v)(u,v)的最小生成树。
基于该性质的最小生成树算法主要有Prim算法和Kruskal算法,它们都基于贪心算法的策略。
下面介绍一个通用的最小生成树算法:
GENERIC_MST(G)
T=NULL;
while T 未形成一棵生成树;
do 找到一条最小代价边(u, v)并且加入T后不会产生回路;
T=T U (u, v);
通用算法每次加入一条边以逐渐形成一棵生成树,下面介绍两种实现上述通用算法的途径。
一、普里姆(Prim)算法
Prim算法构造最小生成树的过程如下图所示。初始时从图中任取一顶点(如顶点加入树T,此时树中只含有一个顶点,之后选择一个与当前T中顶点集合距离最近的顶点,并将该顶点和相应的边加入T,每次操作后T中的顶点数和边数都增1。以此类推,直至图中所有的顶点都并入T,得到的T就是最小生成树。此时T中必然有n-1条边。
通俗点说就是:从一个顶点出发,在保证不形成回路的前提下,每找到并添加一条最短的边,就把当前形成的连通分量当做一个整体或者一个点看待,然后重复“找最短的边并添加”的操作。
Prim算法的步骤如下:
假设G = V , E 是连通图,其最小生成树T = ( U , ET ) ,ET 是最小生成树中边的集合。
初始化:向空树T = ( U , ET ) 中添加图G = ( V , E )的任一顶点u0 ,使U = u0 ,ET = N U L。
循环(重复下列操作直至U = V ):从图G中选择满足 ( u , v ) ∣ u ∈ U , v ∈ V − U 且具有最小权值的边( u , v ) ,加入树T,置U = U ∪ v ,ET = ET U ( u , v ) 。
额,不得不说这样理解起来有点抽象,为了能描述这个算法,我们先构造一个邻接矩阵,如下图的右图所示。
于是普里姆(Prim) 算法代码如下,左侧数字为行号。其中INFINITY为权值极大值,不妨设65535,MAXVEX 为顶点个数最大值,此处大于等于9即可。
/*Prim算法生成最小生成树*/
void MiniSpanTree_Prim(G)
int min, i, j, k;
int adjvex[MAXVEX]; //保存相关顶点下标
int lowcost[MAXVEX]; //保存相关顶点间边的权值
lowcost[0] = 0; //初始化第一个权值为0,即v0加入生成树
//lowcost的值为0,在这里就是此下标的顶点已经加入生成树
adjvex[0] = 0; //初始化第一个顶点下标为0
for(i=1; i<G.numVertexes; i++)
lowcost[i] = G.arc[0][i]; //将v0顶点与之组成边的权值存入数组
adjvex[i] = 0; //初始化都为v0的下标
for(i=1; i<G.numVertexes; i++)
min = INFINITY; //初始化最下权值为∞,通常设置一个不可能的很大的数字
j = 1; k = 0;
//循环全部顶点
while(j < G.numVertexes)
//如果权值不为0且权值小于min
if(lowcost[j] != 0 && lowcost[j] < min)
min = lowcost[j]; //则让当前权值成为最小值
k = j; //将当前最小值的下标存入k
j++;
print("(%d, %d)", adjvex[k], k); //打印当前顶点边中权值的最小边
for(j=1; j<G.numvertexes; j++)
//若下标为k顶点各边权值小于此前这些顶点未被加入生成树权值
if(lowcost[j] != 0 && G.arc[k][j] < lowcost[j])
lowcost[j] = G.arc[k][j]; //将较小权值存入lowcost
adjvex[j] = k; //将下标为k的顶点存入adjvex
由算法代码中的循环嵌套可得知此算法的时间复杂度为O ( n 2 ) O(n^2)O(n
2
)。
二、克鲁斯卡尔(Kruskal)算法
与Prim算法从顶点开始扩展最小生成树不同,Kruskal 算法是一种按权值的递增次序选择合适的边来构造最小生成树的方法。
Kruskal算法构造最小生成树的过程如下图所示。初始时为只有n个顶点而无边的非连通图T = V ,每个顶点自成一个连通分量,然后按照边的权值由小到大的顺序,不断选取当前未被选取过且权值最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入T ,否则舍弃此边而选择下一条权值最小的边。以此类推,直至T中所有顶点都在一个连通分量上。
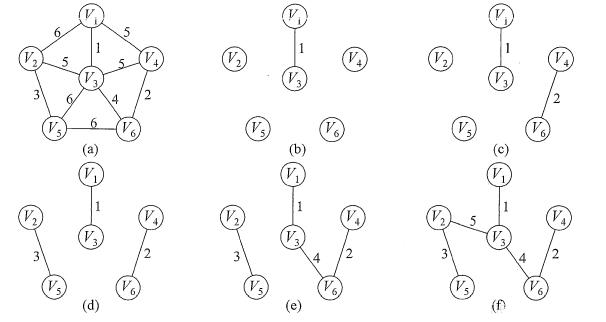
算法思路:
我们可以直接就以边为目标去构建,因为权值是在边上,直接去找最小权值的边来构建生成树也是很自然的想法,只不过构建时要考虑是否会形成环路而已。此时我们就用到了图的存储结构中的边集数组结构。以下是edge边集数组结构的定义代码:
/*对边集数组Edge结构的定义*/
typedef struct
int begin;
int end;
int weight;
Edge