改进YOLO系列:YOLOv5结合Res2Net Block骨干网络
Posted Just do it!ට⋆☆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了改进YOLO系列:YOLOv5结合Res2Net Block骨干网络相关的知识,希望对你有一定的参考价值。
这里写目录标题
论文《Res2Net: A New Multi-scale Backbone Architecture》
开源代码地址(Pytorch):
https://github.com/gasvn/Res2Net
更多研究网址:
https://mmcheng.net/res2net/
论文地址:https://arxiv.org/pdf/1904.0116
1. 摘要
摘要:在诸多视觉任务中,多尺度表示特征非常重要。backbone卷积神经网络(CNN)的最新进展不断显示出更强大的多尺度表示能力,从而在广泛的应用中实现了一致的性能提升。然而,大多数现有方法以分层的方式表示多尺度特征。在本文中,提出了一种新颖的CNN模块,叫作Res2net,在单个残差块内构造具有等级制的类似残差连接。Res2Net在粒度级别表示多尺度特征,并增加了每个网络层的感受野。可以将Res2Net模块插入最新的主干CNN模型中,例如ResNet,ResNeXt和DLA。我们在这些模型上评估Res2Net块,并在广泛使用的数据集(例如CIFAR-100和ImageNet)上展示了,该方法性能优于基准模型。关于代表性计算机视觉任务(如目标检测,类激活映射和显着目标检测)的进一步消融研究和实验结果,进一步验证了Res2Net相对于最新基准方法的优越性。
2. 创新点
不同于之前的网络结构利用不同分辨率的特征来提高多尺度能力,我们提出的多尺度方法可以在更细粒度级别上表示多尺度特征,并增加每个网络的感受野。
我们用一组更小的滤波器组替换了n个通道的3×3卷积核,每个都是w个通道(我们使用n = s×w不失一般性)。如图2所示,这些较小的滤波器组以类残差的层次化方式连接,以增加输出特征所能代表的尺度的数量。
Res2Net策略引出了一个新的维度,即scale (Res2Net块中特征组的数量),作为现有网络中的深度、宽度和基数维度之外的一个重要因素。文中实验证明,增加Scale比增加其他维度更有效。请注意,所提出的方法在更细粒度的层次上利用了多尺度的潜力,这与利用分层操作的现有方法是正交的。因此,所提出的构建块,即Res2Net模块,可以很容易地插入到许多现有的CNN架构中。
3. Res2Net 模块与ResNet区别:
通俗的理解,就是将原来的resnet中间的3x3卷积换成了右侧红色部分,该部分最少是不经过3x3卷积,直接连接。最多会经过3个3x3的卷积,这样就能理解感受野比原结构多的原因了。再来讲一下里面的结构,经过1x1卷积之后,将特征图分成4部分。第一部分线路很简单,x1不做处理,直接传到y1;第二部分线路,x2经过3x3卷积之后分为两条线路,一条继续向前传播给y2,另一条传到x3,这样第三条线路就获得了第二条线路的信息;第三条线路、第四条线路,以此类推。每条线路的通道数为n/s。
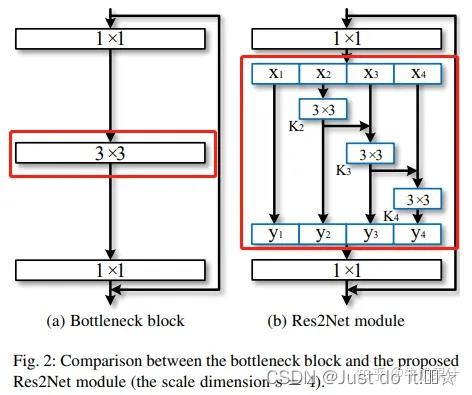
综合上图结构以及上式,可看出由于这种拆分混合连接结构,Res2Net模块的输出包含不同感受野大小的组合,该结构有利于提取全局和本地信息。为了减少参数的数量,省略了第一个分割部分x1的卷积,这也可以视为特征重用的一种形式。
除了现有的深度,宽度和通道数之外,Res2Net策略还公开了一个新的维度,即尺度(Res2Net块中特征组的数量),作为一个重要因素。我们在4.4节增大尺度比增加其他维度更有效。
注意:所提出的方法在更细粒度的水平上利用了多尺度,这与利用分层操作的现有方法正交。因此,可以很容易地将Res2Net模块插入许多现有的CNN架构中。大量的实验结果表明,Res2Net模块可以进一步提高最新的CNN的性能,例如ResNet,ResNeXt和DLA。Res2Net的巧妙之处是利用s作为尺度的控制参数。这样做的优点是s越大感受野越大,且级联(conact)引入的计算/内存开销小,可以忽略不计。
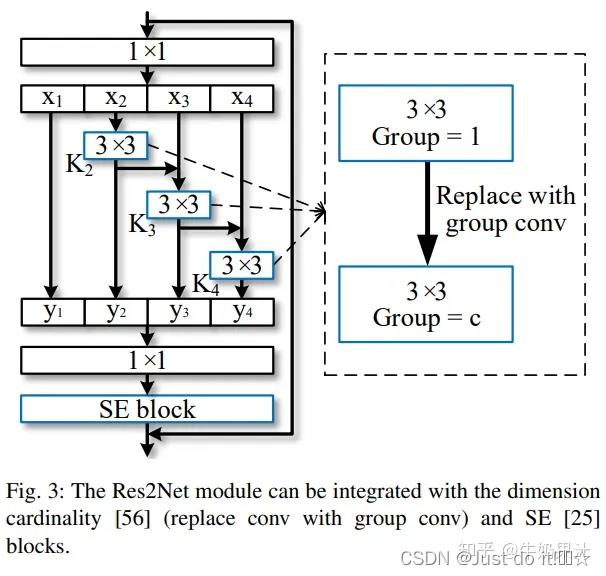
4. 集成现有模型结构的Res2Net 模块:
如果参数量较大,可以使用分组卷积代替标准卷积,实现参数量和计算量递减
YOLOv5s的yaml配置文件修改
增加以下yolov5_Resnet2.yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3res_d, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3res_d, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3res_d, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3res_d, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
common.py配置
./models/common.py文件增加以下模块
class Bottle2neck(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype='normal'):
""" Constructor
Args:
inplanes: input channel dimensionality
planes: output channel dimensionality
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3
scale: number of scale.
type: 'normal': normal set. 'stage': first block of a new stage.
"""
super(Bottle2neck, self).__init__()
# if stride != 1 or inplanes != planes * Bottle2neck.expansion:
# downsample = nn.Sequential(
# nn.AvgPool2d(kernel_size=stride, stride=stride,
# ceil_mode=True, count_include_pad=False),
# nn.Conv2d(inplanes, planes * Bottle2neck.expansion,
# kernel_size=1, stride=1, bias=False),
# nn.BatchNorm2d(planes * Bottle2neck.expansion),
# )
# planes = planes / 4
width = int(math.floor(planes * (baseWidth / 64.0)))
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
# print(residual.shape)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype == 'normal':
out = torch.cat((out, spx[self.nums]), 1)
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
# print(out.shape)
out += residual
out = self.relu(out)
return out
class C3res_d(nn.Module):#C3模块和BottleneckCSP类似, 但是少了一个Conv模块.
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3res_d, self).__init__()
# c_ = int(c2 * e) # hidden channels
# inplanes, planes, stride = c1, c2,
# self.m1 = Bottle2neck(inplanes, planes, stride, downsample=downsample,
# stype='stage', baseWidth=self.baseWidth, scale=self.scale)
# c2 = c2/4
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m2 = nn.Sequential(*[Bottle2neck(c_, c_) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1,g, 1.0, shortcut) for _ in range(n)])
# self.avg = nn.AvgPool2d(kernel_size=1,stride=1)
def forward(self, x):
return self.cv3(torch.cat((self.m2(self.cv1(x)), self.cv2(x)), dim=1))
return out
yolo.py配置修改
然后找到./models/yolo.py文件下里的parse_model函数,将加入的模块名C3res_d加入进去
在 models/yolo.py文件夹下
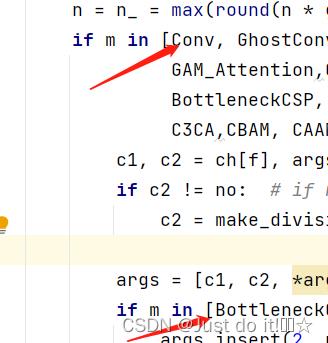
建议
- 修改basewidth可以更改每个小块的通道数,可以多测试修改。
- 添加注意力机制,原论文使用的是SELayer,加在1*1卷积后,残差操作前,也可以替换ECA注意力进行尝试。
- 可以将3*3卷积替换为分组卷积,甚至添加膨胀参数,增大网络感受野。
改进YOLOv5系列:8.增加ACmix结构的修改,自注意力和卷积集成
YOLOAir:助力YOLO论文改进🏆 、 不同数据集改进🏆、创新点改进👇

- 💡YOLOAir项目:基于 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 🌟本项目包含大量的改进方式,降低改进难度,改进点包含
Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数等部分,详情可以关注👉 YOLOAir 的说明文档。 - 🎈同时
附带各种改进点原理及对应的代码改进方式教程,用户可根据自身情况快速排列组合,在不同的数据集上实验, 应用组合写论文, 创造自己的毕业项目!🏆
🎈🎈🎈新的仓库链接👉:YOLOAir仓库:https://github.com/iscyy/yoloair
可以 fork 和 star,持续同步更新完善
本篇是《ACmix结构🚀自注意力和卷积集成》的修改 演示
使用YOLOv5网络🚀作为示范,可以无缝加入到 YOLOv7、YOLOX、YOLOR、YOLOv4、Scaled_YOLOv4、YOLOv3等一系列YOLO算法模块
文章目录
ACmix结构理论部分

论文:On the Integration of Self-Attention and Convolution
论文地址:https://arxiv.org/pdf/2111.14556.pdf
yolov5的yaml配置文件修改
增加以下yolov5s_acmix.yaml文件
# parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
#- [5,6, 7,9, 12,10] # P2/4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, ACmix, [512, 512]], #9 修改示例
[-1, 1, SPPF, [1024,5]], #10
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, CBAM, [256]], #19
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False]
[-1, 1, CBAM, [512]],
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False]
[-1, 1, CBAM, [1024]],
[[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
common.py配置
./models/common.py文件增加以下模块
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
自行插入其他层 换通道的时候,注意匹配上通道
yolo.py配置修改
不需要
提示
出现RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
解决办法:
1.train加个参数
parser.add_argument('--acmix', action='store_true', help='useacmix')
2.val.run调用的时候加个(half=not opt.acmix)传进去,因为val.py默认的half为True,要将其设置为false。
或者每次跑包含acmix模块的网络,直接将val.py的half参数改成false
训练yolov5s_acmix.yaml模型
python train.py --cfg yolov5s_acmix.yaml --acmix
基于以上yolov5s_acmix.yaml文件继续修改
关于yolov5s_acmix.yaml文件配置中的acmix模块,可以针对不同数据集自行再进行模块修改,原理一致
以上是关于改进YOLO系列:YOLOv5结合Res2Net Block骨干网络的主要内容,如果未能解决你的问题,请参考以下文章