浅谈策略梯度(PG)算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈策略梯度(PG)算法相关的知识,希望对你有一定的参考价值。
参考技术APolicy Optimization(策略优化)是强化学习中的一大类算法,其基本思路区别于Value-based的算法。因此,很多教科书都将model-free RL分成两大类,Policy Optimization和Value-based。本系列博客将会参考OpenAI发布的入门教程 Spinning Up [1] ,Spinning Up系列是入门Policy Optimization的非常好的教材,特别适合初学者。Policy Gradient(策略梯度,简称PG)算法是策略优化中的核心概念,本章我们就将从最简单的PG推导开始,一步步揭开策略优化算法的神秘面纱。
如果用一句话来表达 策略梯度 的直观解释,那就是“如果动作使得最终回报变大,那么增加这个动作出现的概率,反之,减少这个动作出现的概率”。这句话表达了两个含义:
本节我们将一步步推导出策略梯度的基础公式,这一小节非常重要,理解了推导过程,就基本上理解了策略梯度的核心思想。所以,一定要耐心的把这一小节的内容全部看懂,最好能够达到自行推导的地步。
我们用参数化的神经网络表示我们的策略 ,那我们的目标,就可以表示为调整 ,使得 期望回报 最大,用公式表示:
在公式(1)中, 表示从开始到结束的一条完整路径。通常,对于最大化问题,我们可以使用梯度上升算法来找到最大值。
为了能够一步步得到最优参数,我们需要得到 ,然后利用梯度上升算法即可,核心思想就是这么简单。
关键是求取最终的 回报函数 关于 的梯度,这个就是 策略梯度 (policy gradient),通过优化策略梯度来求解RL问题的算法就叫做 策略梯度算法 ,我们常见的PPO,TRPO都是属于策略梯度算法。下面我们的目标就是把公式(2)逐步展开,公式(2)中最核心的部分就是 ,这也是这篇博客最核心的地方。
在以上的推导中,用到了log求导技巧: 关于 的导数是 。因此,我们可以得到以下的公式:
所以,才有公式(5)到公式(6),接下来我们把公式(7)进一步展开,主要是把 展开。先来看看
加入log,化乘法为加法:
计算log函数的梯度,并且约去一些常量:
因此,结合公式(7)和公式(9),我们得到了最终的表达式
公式(10)就是PG算法的核心表达式了,从这个公式中可以看出,我们要求取的策略梯度其实是一个期望,具体工程实现可以采用蒙特卡罗的思想来求取期望,也就是采样求均值来近似表示期望。我们收集一系列的 ,其中每一条轨迹都是由agent采用策略 与环境交互采样得到的,那策略梯度可以表示为:
其中, 表示采样的轨迹的数量。现在,我们完成了详细的策略梯度的推导过程,长舒一口气,接下来的工作就比较轻松了,就是在公式(10)的基础上修修改改了。
再进行简单修改之前,我们再总结一下公式(10),毕竟这个公式是PG算法最核心的公式:
我们继续观察公式(10),对于公式中的 ,表示整个轨迹的回报,其实并不合理。对于一条轨迹中的所有动作,均采用相同的回报,就相当于对于轨迹中的每一个动作都赋予相同的权重。显然,动作序列中的动作有好有坏,都采取相同的回报,无法达到奖惩的目的,那我们该怎么表示 “某个状态下,执行某个动作” 的回报呢?
一种比较直观思路是,当前的动作将会影响后续的状态,并且获得即时奖励(reward),那么我们只需要使用 折扣累计回报 来表示当前动作的回报就行了,用公式表示为:
这在spinning up中叫做reward to go,所以,公式(10)可以表示为:
当然,使用reward to go的权重分配还是相当初级,我们可以使用更加高级的权重分配方式,进一步减少回报分配的方差,限于篇幅原因,我们后续再聊。
本章我们花了大量的篇幅推导了策略梯度(PG)的核心公式,得到了关键表达式(10),理解该公式对于我们后续理解整个PG算法族非常有帮助,希望大家能够认真的理解这一公式推导过程。
我们是行者AI,我们在“AI+游戏”中不断前行。
如果你也对游戏感兴趣,对AI充满好奇,就快来加入我们吧~
浅谈梯度下降算法(模拟退火实战)
文章目录
简介
简单来说,梯度下降就像是从山顶出发,到达最低的谷底,但下山过程中可能误入歧途,走入不是最低的谷底,即局部最优。
『梯度』是一个向量,表示函数在该点处的方向导数沿着该方向取得最大值,也就是说沿着该向量方向变化率最大,是最陡的。
梯度的大小: ∣ ∇ f ∣ = f x ( x , y ) ′ 2 + f y ( x , y ) ′ 2 |\\nabla f|=\\sqrtf_x(x,y)'^2+f_y(x,y)'^2 ∣∇f∣=fx(x,y)′2+fy(x,y)′2,其中 f x ( x , y ) ′ f_x(x,y)' fx(x,y)′是在点 ( x , y ) 处 (x,y)处 (x,y)处对 x x x的偏导数,其中 f y ( x , y ) ′ f_y(x,y)' fy(x,y)′是在点 ( x , y ) 处 (x,y)处 (x,y)处对 y y y的偏导数。偏导数可以理解为在点(x,y)处的切线对x或y的斜率。
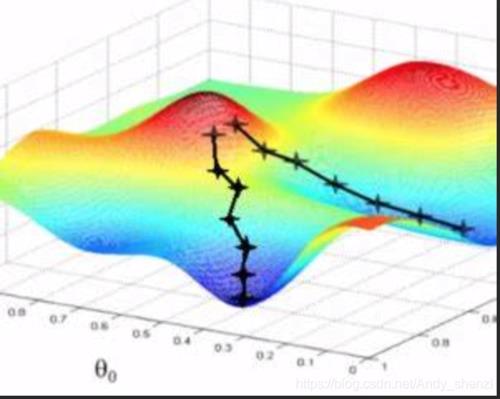
上图摘自网络。
那所谓的梯度下降法,可以理解为沿着梯度最大的反方向下山的过程。比如三维特征中,其平面图可以像是山峰和谷底,那我们就是要从山峰出发,从最陡(梯度最大)的方向进行下山,从而到达谷底取最小值,但往往可能陷入其它谷底,只取到了极小值,可以修改步长(学习率)。
Θ
1
=
Θ
0
−
α
∇
J
(
Θ
)
\\Theta^1=\\Theta^0-\\alpha\\nabla J(\\Theta)
Θ1=Θ0−α∇J(Θ)
其中
J
J
J是关于
Θ
\\Theta
Θ的一个函数,设当前点位
Θ
0
\\Theta^0
Θ0,从这个点走一段距离的步长(也就是学习率
α
\\alpha
α),然后到达
Θ
1
\\Theta^1
Θ1这个点,以此迭代,最终目标是要走到
J
J
J的最小值点,也就是谷底。
梯度下降算法中有几种方式来调节权重向量,通过为每个权重计算一个梯度,从而更新权值,使目标函数尽可能最小化。其差别在于样本的使用方式不同,包括全梯度下降算法、随机梯度下降算法、小批量梯度下降算法、随机平均梯度下降算法等,一般常用的还是随机梯度下降。
全梯度下降
全梯度下降算法(Full Gradient descent,FG)
所谓『全』的意思就是考虑全部的训练集样本,对其求和后取平均值。每次更新时在整个数据集上计算全部梯度,计算量较大,所以梯度下降的速度较慢。
此外,批梯度下降过程中不能同步更新模型,即在运行的过程中,不能增加新的样本数据。是在整个训练数据集上计算损失函数关于参数 θ \\theta θ的梯度。
θ = θ − η ⋅ ∇ θ J ( θ ) \\theta=\\theta-\\eta·\\nabla_\\theta J(\\theta) θ=θ−η⋅∇θJ(θ)
随机梯度下降
随机梯度下降算法(Stochastic Gradient descent,SG)
FG计算了全部样本,导致速度很慢且容易陷入局部最优解,故提出了SG。所谓『随机』就是每次随机带入一个样本进行计算即可,不再是全体样本误差。
使用单个样本误差更新权重,然后再随机下一个样本重复此过程,直到损失函数值停止下降,为此速度大幅提高,但是也由于每次只使用一个样本迭代,若随机到噪声样本则容易陷入局部最优解。
θ
=
θ
−
η
⋅
∇
θ
J
(
θ
;
x
(
i
)
;
y
(
i
)
)
\\theta=\\theta-\\eta·\\nabla_\\theta J(\\theta;x^(i);y^(i))
θ=θ−η⋅∇θJ(θ;x(i);y(i))
其中,
x
(
i
)
x_(i)
x(i)是训练样本
i
i
i的特征值,
y
(
i
)
y_(i)
y(i)是训练样本
i
i
i的标签值。
小批量梯度下降
小批量梯度下降算法(Mini-batch Gradient descent)
所谓『小批量』就是全部与一个的折中方案,兼顾了FG和SG两种方法的优点。即每次从训练样本集上随机抽取一个小样本集,在该小样本集上用FG来迭代更新权重。
抽出的小样本集所含样本点的个数(batch.size)通常设为2的幂次方,为了方便GPU加速处理。如果batch.size=1,就是SG;若batch.size=n就是FG。
θ = θ − η ⋅ ∇ θ J ( θ ; x ( i : i + n ) ; y ( i : i + n ) ) \\theta=\\theta-\\eta·\\nabla_\\theta J(\\theta;x^(i:i+n);y^(i:i+n)) θ=θ−η⋅∇θJ(θ;x(i:i+n);y(i:i+n))
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
随机平均梯度下降
随机平均梯度下降算法 (Stochastic Average Gradient descent,SAG)
所谓『随机平均』是在内存中为每一个样本都维护了一个旧的梯度,随机选择第
i
i
i个样本来更新此样本的梯度,其他样本的梯度保持不变,求得所有梯度的平均值来更新参数。
如此一来,每一轮更新仅需计算随机的一个样本梯度,同SG一样,但是收敛速度快得多,对大数据训练而言更有效。
模拟退火
为了更好理解梯度下降,引入实际应用背景:
物理的退火降温的过程:
给一个处于高温度的物体降温,使物体内能降到最低。
一般的思维是越快越好,尽快的温度迅速地降低。但实际上,过快地降温使得物体来不及有序地收缩,难以形成结晶,而结晶态才是物体真正内能降到最低的形态。
正确的做法,是徐徐降温,也就是退火,才能使得物体的每一个粒子都有足够的时间找到自己的最佳位置并紧密有序地排列。开始温度高的时候,粒子活跃地运动并逐渐找到一个合适的状态。在这过程中温度也会越降越低,温度低下来了,那么粒子也渐渐稳定下来,相较于以前不那么活跃了。这时候就可以慢慢形成最终稳定的结晶态了。
也就是说,不同学习率(步长)可能导致完全不同的结果。
若过大,则可能来回震荡,无法到达最优点;
若过小,则可能陷入局部最优;
合适的学习率才能取到全局最优。一般设置为0.1左右。
import numpy as np
import matplotlib.pyplot as plt
def func(x): # 函数定义
return x ** 4 + 2 * x ** 3 - 3 * x ** 2 - 3 * x
def grad_func(x): # 求导
return 4 * x ** 3 + 6 * x ** 2 - 6 * x - 3
if __name__ == "__main__":
x = np.linspace(-3, 1.9) # 定义域[-3,1.9]
fx = func(x)
plt.plot(x, fx, '--') # 虚线画出曲线
eta = 0.08 # 学习率
x0 = 1.8 # 初始值(山顶)
record_x = []
record_y = []
for i in range(50):
y0 = func(x0)
record_x.append(x0)
record_y.append(y0)
x0 -= eta * grad_func(x0) # 梯度下降
# 可视化
plt.title("学习率=0.08")
plt.scatter(record_x, record_y, marker='x', color="red")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
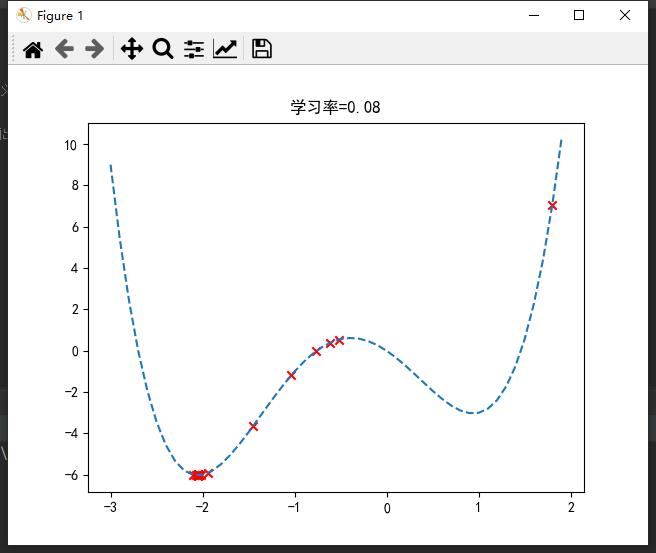
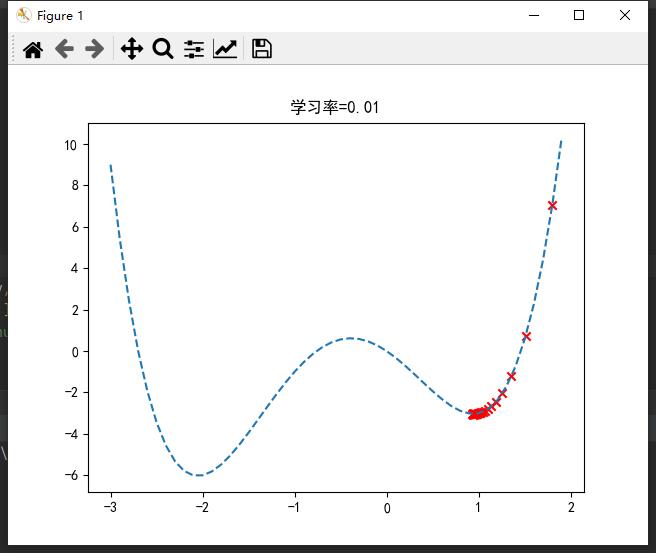
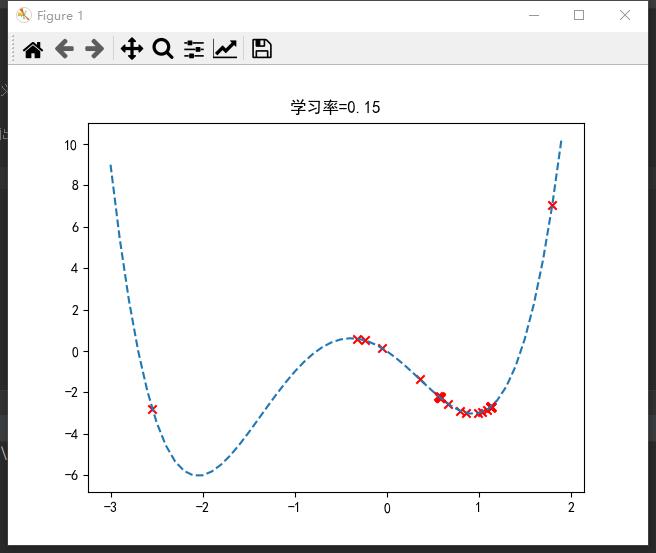
在sklearn库中,封装了SGD*随机梯度下降算法的应用,如分类SGDClassifier()、回归SGDRegressor()等(☆▽☆)。
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于浅谈策略梯度(PG)算法的主要内容,如果未能解决你的问题,请参考以下文章