arm ip核 结构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了arm ip核 结构相关的知识,希望对你有一定的参考价值。
ARM的IP核有多少种结构版本
昨晚的问题还没解决呀,我查到的有六种,呵呵..做成ppt发过去啦~应该做好了发过去了吧~?今晚可是有嵌入式导论噢~各ARM体系结构版本ARM体系结构从最初开发到现在有了很大的改进,并仍在完善和发展。
为了清楚地表达每个ARM应用实例所使用的指令集,ARM公司定义了6种主要的ARM指令集体系结构版本,以版本号V1~V6表示ARM版本Ⅰ: V1版架构
该版架构只在原型机ARM1出现过,只有26位的寻址空间,没有用于商业产品。
其基本性能有:
基本的数据处理指令(无乘法);
基于字节、半字和字的Load/Store指令;
转移指令,包括子程序调用及链接指令;
供操作系统使用的软件中断指令SWI;
寻址空间:64MB(226)。 ARM版本Ⅱ: V2版架构
该版架构对V1版进行了扩展,例如ARM2和ARM3(V2a)架构。包含了对32位乘法指令和协处理器指令的支持。
版本2a是版本2的变种,ARM3芯片采用了版本2a,是第一片采用片上Cache的ARM处理器。同样为26位寻址空间,现在已经废弃不再使用。
V2版架构与版本V1相比,增加了以下功能:
乘法和乘加指令;
支持协处理器操作指令;
快速中断模式;
SWP/SWPB的最基本存储器与寄存器交换指令;
寻址空间:64MB。 ARM版本Ⅲ : V3版架构
ARM作为独立的公司,在1990年设计的第一个微处理器采用的是版本3的ARM6。它作为IP核、独立的处理器、具有片上高速缓存、MMU和写缓冲的集成CPU。
变种版本有3G和3M。版本3G是不与版本2a向前兼容的版本3,版本3M引入了有符号和无符号数乘法和乘加指令,这些指令产生全部64位结果。
V3版架构( 目前已废弃 )对ARM体系结构作了较大的改动:寻址空间增至32位(4GB);
当前程序状态信息从原来的R15寄存器移到当前程序状态寄存器CPSR中(Current Program Status Register);
增加了程序状态保存寄存器SPSR(Saved Program Status Register);
增加了两种异常模式,使操作系统代码可方便地使用数据访问中止异常、指令预取中止异常和未定义指令异常。;
增加了MRS/MSR指令,以访问新增的CPSR/SPSR寄存器;
增加了从异常处理返回的指令功能。 ARM版本Ⅳ : V4版架构
V4版架构在V3版上作了进一步扩充,V4版架构是目前应用最广的ARM体系结构,ARM7、ARM8、ARM9和StrongARM都采用该架构。
V4不再强制要求与26位地址空间兼容,而且还明确了哪些指令会引起未定义指令异常。
指令集中增加了以下功能:
符号化和非符号化半字及符号化字节的存/取指令;
增加了T变种,处理器可工作在Thumb状态,增加了16位Thumb指令集;
完善了软件中断SWI指令的功能;
处理器系统模式引进特权方式时使用用户寄存器操作;
把一些未使用的指令空间捕获为未定义指令 ARM版本Ⅴ : V5版架构
V5版架构是在V4版基础上增加了一些新的指令,ARM10和Xscale都采用该版架构。
这些新增命令有:
带有链接和交换的转移BLX指令;
计数前导零CLZ指令;
BRK中断指令;
增加了数字信号处理指令(V5TE版); 为协处理器增加更多可选择的指令;
改进了ARM/Thumb状态之间的切换效率;
E---增强型DSP指令集,包括全部算法操作和16位乘法操作;
J----支持新的JAVA,提供字节代码执行的硬件和优化软件加速功能。 ARM版本Ⅵ : V6版架构
V6版架构是2001年发布的,首先在2002年春季发布的ARM11处理器中使用。在降低耗电量地同时,还强化了图形处理性能。通过追加有效进行多媒体处理的SIMD(Single Instruction, Multiple Data,单指令多数据 )功能,将语音及图像的处理功能提高到了原型机的4倍。
此架构在V5版基础上增加了以下功能:
THUMBTM:35%代码压缩;
DSP扩充:高性能定点DSP功能;
JazelleTM:Java性能优化,可提高8倍;
Media扩充:音/视频性能优化,可提高4倍 参考技术A ARM版本Ⅰ: V1版架构该版架构只在原型机ARM1出现过,只有26位的寻址空间,没有用于商业产品。
其基本性能有:
基本的数据处理指令(无乘法);
基于字节、半字和字的Load/Store指令;
转移指令,包括子程序调用及链接指令;
供操作系统使用的软件中断指令SWI;
寻址空间:64MB(226)。
ARM版本Ⅱ: V2版架构该版架构对V1版进行了扩展,例如ARM2和ARM3(V2a)架构。包含了对32位乘法指令和协处理器指令的支持。
版本2a是版本2的变种,ARM3芯片采用了版本2a,是第一片采用片上Cache的ARM处理器。同样为26位寻址空间,现在已经废弃不再使用。
V2版架构与版本V1相比,增加了以下功能:
乘法和乘加指令;
支持协处理器操作指令;
快速中断模式;
SWP/SWPB的最基本存储器与寄存器交换指令;
寻址空间:64MB。
ARM版本Ⅲ : V3版架构ARM作为独立的公司,在1990年设计的第一个微处理器采用的是版本3的ARM6。它作为IP核、独立的处理器、具有片上高速缓存、MMU和写缓冲的集成CPU。
变种版本有3G和3M。版本3G是不与版本2a向前兼容的版本3,版本3M引入了有符号和无符号数乘法和乘加指令,这些指令产生全部64位结果。
V3版架构( 目前已废弃 )对ARM体系结构作了较大的改动:
寻址空间增至32位(4GB);当前程序状态信息从原来的R15寄存器移到当前程序状态寄存器CPSR中(Current Program Status
Register);
增加了程序状态保存寄存器SPSR(Saved Program Status
Register);
增加了两种异常模式,使操作系统代码可方便地使用数据访问中止异常、指令预取中止异常和未定义指令异常。;
增加了MRS/MSR指令,以访问新增的CPSR/SPSR寄存器;
增加了从异常处理返回的指令功能。
ARM版本Ⅳ : V4版架构V4版架构在V3版上作了进一步扩充,V4版架构是目前应用最广的ARM体系结构,ARM7、ARM8、ARM9和StrongARM都采用该架构。
V4不再强制要求与26位地址空间兼容,而且还明确了哪些指令会引起未定义指令异常。
指令集中增加了以下功能:
符号化和非符号化半字及符号化字节的存/取指令;
增加了T变种,处理器可工作在Thumb状态,增加了16位Thumb指令集;
完善了软件中断SWI指令的功能;
处理器系统模式引进特权方式时使用用户寄存器操作;
把一些未使用的指令空间捕获为未定义指令
ARM版本Ⅴ : V5版架构V5版架构是在V4版基础上增加了一些新的指令,ARM10和Xscale都采用该版架构。
这些新增命令有:
带有链接和交换的转移BLX指令;
计数前导零CLZ指令;
BRK中断指令;
增加了数字信号处理指令(V5TE版);
为协处理器增加更多可选择的指令;
改进了ARM/Thumb状态之间的切换效率;
E---增强型DSP指令集,包括全部算法操作和16位乘法操作;
J----支持新的JAVA,提供字节代码执行的硬件和优化软件加速功能。
ARM版本Ⅵ : V6版架构V6版架构是2001年发布的,首先在2002年春季发布的ARM11处理器中使用。在降低耗电量地同时,还强化了图形处理性能。通过追加有效进行多媒体处理的SIMD(Single
Instruction, Multiple Data,单指令多数据 )功能,将语音及图像的处理功能提高到了原型机的4倍。
此架构在V5版基础上增加了以下功能:
THUMBTM:35%代码压缩;
DSP扩充:高性能定点DSP功能;
JazelleTM:Java性能优化,可提高8倍;
Media扩充:音/视频性能优化,可提高4倍
AXI-Lite总线及其自定义IP核使用分析总结
ZYNQ的优势在于通过高效的接口总线组成了ARM+FPGA的架构。我认为两者是互为底层的,当进行算法验证时,ARM端现有的硬件控制器和库函数可以很方便地连接外设,而不像FPGA设计那样完全写出接口时序和控制状态机。这样ARM会被PL端抽象成“接口资源”;当进行多任务处理时,各个PL端IP核又作为ARM的底层被调用,此时CPU仅作为“决策者”,为各个IP核分配任务;当实现复杂算法时,底层算法结构规整可并行,数据量大,实时性要求高,而上层算法则完全相反,并且控制流程复杂,灵活性高。因此PL实现底层算法后将运算结果交给PS端软件后续处理是非常高效的。
因此PS与PL端数据交互是至关重要的,在传输数据量小的控制 配置初始化等应用场合下无疑会选择简单的AXI-Lite总线,以下对总线接口 自定义IP操作及使用注意事项加以说明。打开Vivado新建工程,选择主菜单栏Tools选项下的Create and package new IP...
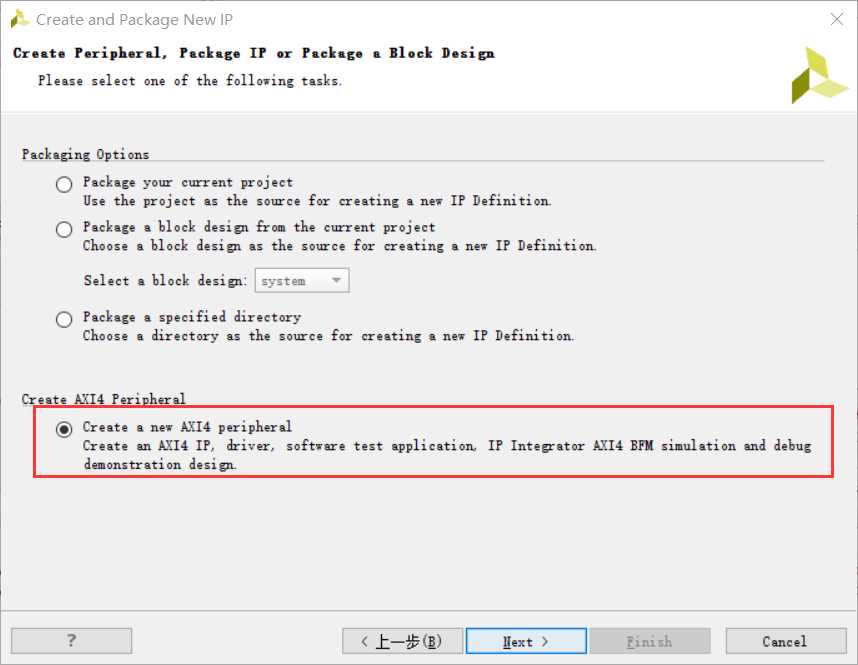
选择创建新的AXI4外设可以自动生成总线接口逻辑
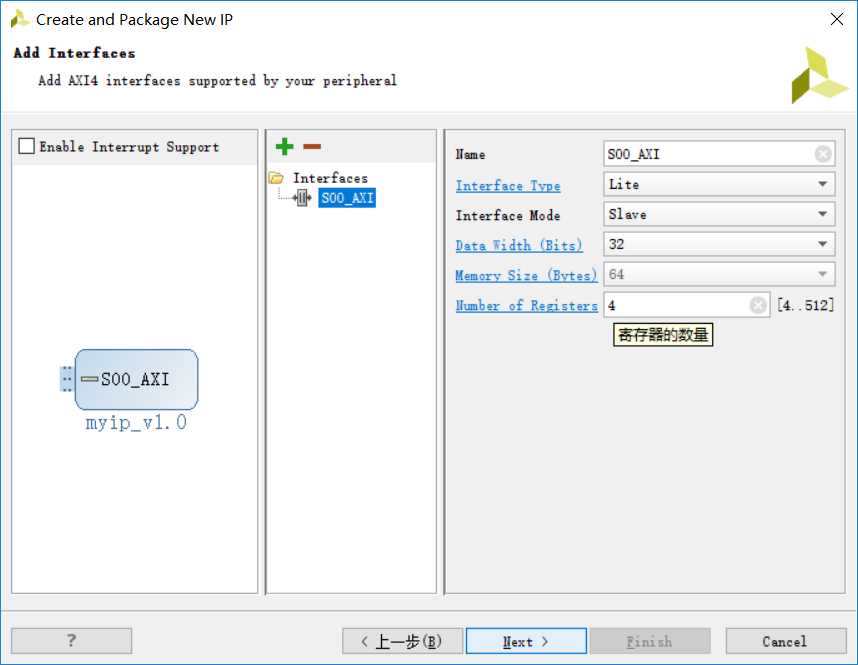
采用AXI-Lite总线的Slave模式,只有寄存器数量是可修改的。注意数据位宽固定32bit,计算机中数据以字节(8bit)为单位存储,因此各个寄存器地址的偏移量为4.这一点在写软件时会有所体现。
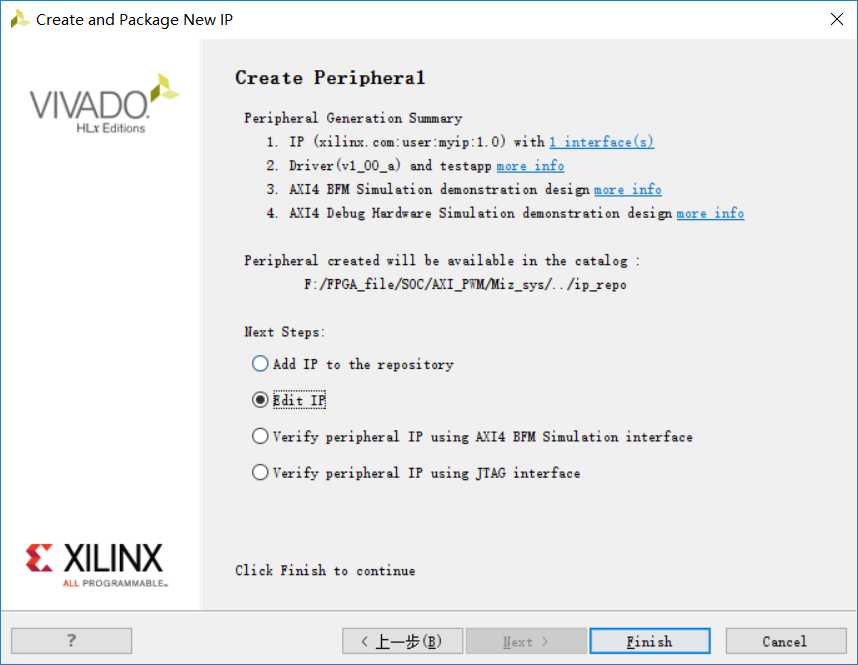
选择编辑IP,打开的工程由顶层Wrapper和AXI-Lite总线接口逻辑组成。关闭自动弹出的IP封装向导,当添加好用户自定义逻辑后再重新封装,否则封装的仅仅是软件生成的接口逻辑。接口比较多,分为写通道和通道,而每个通道基本逻辑又由地址通道和数据通道组成。除了以上四个通道外,写通道包含应答通道以返回CPU确认信息。每个接口以S_AXI_开头,之后AW代表地址写,W代表数据写,AR代表地址读,R代表数据读,B代表响应。关于AXI总线的基本特性在之前的博文中已有阐述,无非就是READY和VLD信号的“握手”。因此这五个核心信号包括VALID DATA和READY。

从上述代码可以看出,只有在写地址通道和写数据通道均握手成功时才能有效写入寄存器。
![]()
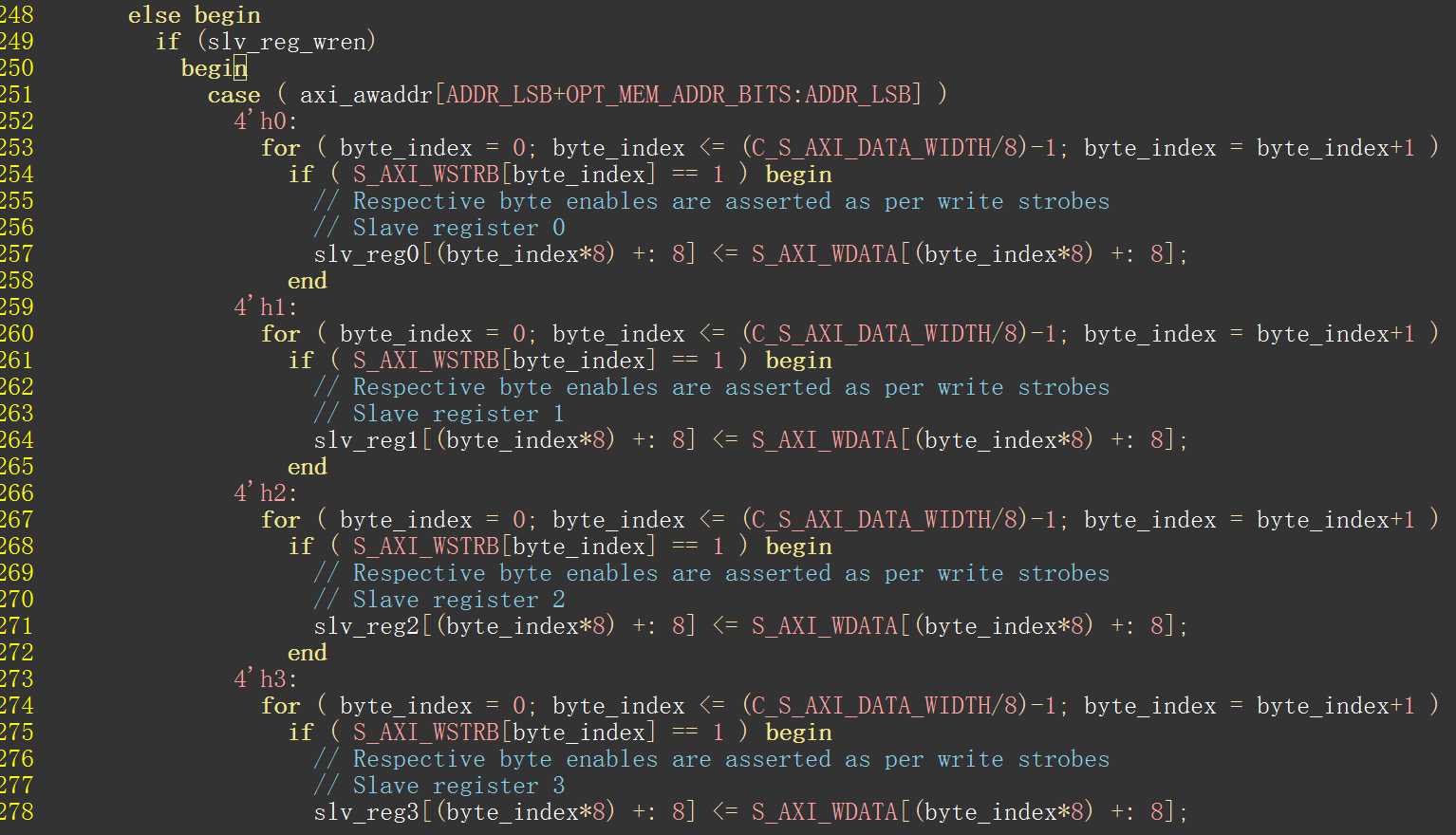
根据参数声明和寄存器选择与写操作逻辑可知,是根据地址[5:2]这四位来判断写入哪一个寄存器。如:
地址0,即6‘b0000_00
地址4,即6‘b0001_00
地址8,即6‘b0010_00
地址12,即6‘b0011_00
因此[5:2]部分依次是0 1 2 3,从而验证了之前地址偏移量是4的观点。这里的slv_regx信号就是我们需要送入自定义逻辑的控制信号了。
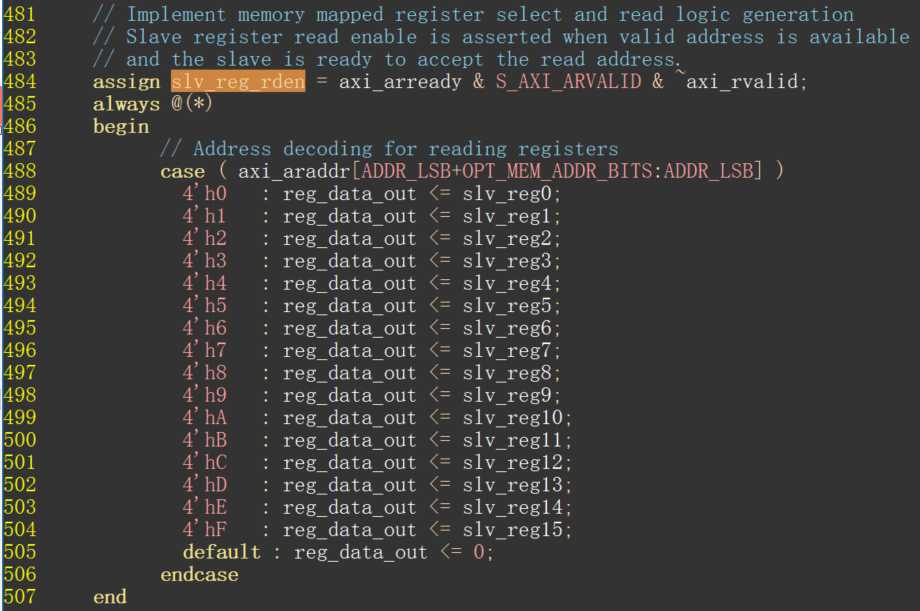
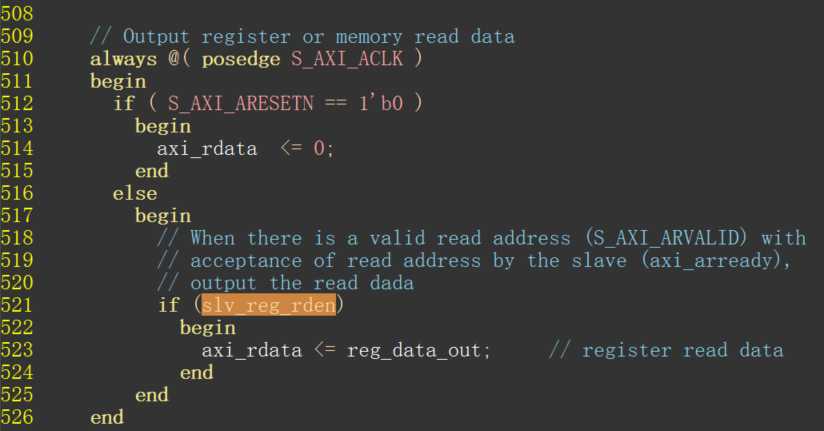
上面是读操作核心逻辑,当从机收到有效的读操作地址且准备好后,会将寄存器数据送回到主机。换句话说读操作读到的数据仅是单纯写入的控制数据,并不是自定义逻辑的处理结果。所以读操作要将489行开始的右侧数据源更换成自定义逻辑处理后有效数据。如:reg_data_out <= user_module_dout;
内部添加的自定义逻辑可以直接写在该模块内,也可以例化自定义模块或IP核。最后封装当前工程得到支持AXI-Lite总线的自定义IP核。
打开需要例化刚才产生IP核的工程,选择Project Setting -> IP -> Respository Manger添加IP核路径或,在block design或 IP Catalog中调用。
以上是关于arm ip核 结构的主要内容,如果未能解决你的问题,请参考以下文章