StarRocksStarRocks四种数据模型的使用
Posted 牧码文
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了StarRocksStarRocks四种数据模型的使用相关的知识,希望对你有一定的参考价值。
目录
一、明细模型:
1 创建表
例如,需要分析某时间范围的某一类事件的数据,则可以将事件时间(event_time)和事件类型(event_type)作为排序键。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS detail (
event_time DATETIME NOT NULL COMMENT "datetime of event",
event_type INT NOT NULL COMMENT "type of event",
user_id INT COMMENT "id of user",
device_code INT COMMENT "device code",
channel INT COMMENT ""
)
DUPLICATE KEY(event_time, event_type)
DISTRIBUTED BY HASH(user_id) BUCKETS 8
PROPERTIES (
"replication_num" = "1"
);
2 使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过
DUPLICATE KEY显式定义。本示例中排序键为 event_time 和 event_type。
如果未指定,则默认选择表的前三列作为排序键。
明细模型中的排序键可以为部分或全部维度列。
建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
二、聚合模型
1 创建表
例如需要分析某一段时间内,来自不同城市的用户,访问不同网页的总次数。则可以将网页地址 site_id、日期 date 和城市代码 city_code 作为排序键,将访问次数 pv 作为指标列,并为指标列 pv 指定聚合函数为 SUM。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.aggregate_tbl (
site_id LARGEINT NOT NULL COMMENT "id of site",
date DATE NOT NULL COMMENT "time of event",
city_code VARCHAR(20) COMMENT "city_code of user",
pv BIGINT SUM DEFAULT "0" COMMENT "total page views"
)
AGGREGATE KEY(site_id, date, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 8
PROPERTIES (
"replication_num" = "1"
);
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键。
2 使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。排序键可以通过AGGREGATE KEY 显式定义。
如果 AGGREGATE KEY 未包含全部维度列(除指标列之外的列),则建表会失败。如果不通过 AGGREGATE KEY显示定义排序键,则默认除指标列之外的列均为排序键。
排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。 指标列:通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
聚合函数:指标列使用的聚合函数。
查询时,排序键在多版聚合之前就能进行过滤,而指标列的过滤在多版本聚合之后。因此建议将频繁使用的过滤字段作为排序键,在聚合前就能过滤数据,从而提升查询性能。
建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
三、更新模型
1 创建表
在电商订单分析场景中,经常按照日期对订单状态进行统计分析,则可以将经常使用的过滤字段订单创建时间 create_time、订单编号 order_id 作为主键,其余列订单状态 order_state 和订单总价 total_price 作为指标列。这样既能够满足实时更新订单状态的需求,又能够在查询中进行快速过滤。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS orders (
create_time DATE NOT NULL COMMENT "create time of an order",
order_id BIGINT NOT NULL COMMENT "id of an order",
order_state INT COMMENT "state of an order",
total_price BIGINT COMMENT "price of an order"
)
UNIQUE KEY(create_time, order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 8
PROPERTIES (
"replication_num" = "1"
);
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键。
2 使用说明
主键的相关说明:
在建表语句中,主键必须定义在其他列之前。主键通过 UNIQUE KEY 定义。
主键必须满足唯一性约束,且列的值不会修改。设置合理的主键。查询时,主键在聚合之前就能进行过滤,而指标列的过滤通常在多版本聚合之后,因此建议将频繁使用的过滤字段作为主键,在聚合前就能过滤数据,从而提升查询性能。聚合过程中会比较所有主键,因此需要避免设置过多的主键,以免降低查询性能。如果某个列只是偶尔会作为查询中的过滤条件,则不建议放在主键中。建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
四、主键模型
1 创建表
例如,需要按天实时分析订单,则可以将时间
dt、订单编号 order_id 作为主键,其余列为指标列。建表语句如下:
create table orders (
dt date NOT NULL,
order_id bigint NOT NULL,
user_id int NOT NULL,
merchant_id int NOT NULL,
good_id int NOT NULL,
good_name string NOT NULL,
price int NOT NULL,
cnt int NOT NULL,
revenue int NOT NULL,
state tinyint NOT NULL
) PRIMARY KEY (dt, order_id)
PARTITION BY RANGE(`dt`) (
PARTITION p20210820 VALUES [('2021-08-20'), ('2021-08-21')),
PARTITION p20210821 VALUES [('2021-08-21'), ('2021-08-22')),
PARTITION p20210929 VALUES [('2021-09-29'), ('2021-09-30')),
PARTITION p20210930 VALUES [('2021-09-30'), ('2021-10-01'))
) DISTRIBUTED BY HASH(order_id) BUCKETS 4
PROPERTIES("replication_num" = "1",
"enable_persistent_index" = "true");
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键。
例如,需要实时分析用户情况,则可以将用户 ID user_id 作为主键,其余为指标列。建表语句如下:
create table users (
user_id bigint NOT NULL,
name string NOT NULL,
email string NULL,
address string NULL,
age tinyint NULL,
sex tinyint NULL,
last_active datetime,
property0 tinyint NOT NULL,
property1 tinyint NOT NULL,
property2 tinyint NOT NULL,
property3 tinyint NOT NULL
) PRIMARY KEY (user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 4
PROPERTIES("replication_num" = "1",
"enable_persistent_index" = "true");
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键。
2 使用说明
主键相关的说明:
在建表语句中,主键必须定义在其他列之前。
主键通过 PRIMARY KEY 定义。
主键必须满足唯一性约束,且列的值不会修改。本示例中主键为 dt、order_id。
主键支持以下数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。
分区列和分桶列必须在主键中。
enable_persistent_index:是否持久化主键索引,同时使用磁盘和内存存储主键索引,避免主键索引占用过大内存空间。通常情况下,持久化主键索引后,主键索引所占内存为之前的 1/10。您可以在建表时,在PROPERTIES中配置该参数,取值范围为 true 或者 false(默认值)。
自 2.3.0 版本起,StarRocks 支持配置该参数。如果磁盘为固态硬盘 SSD,则建议设置为 true。如果磁盘为机械硬盘 HDD,并且导入频率不高,则也可以设置为 true。
如果未开启持久化索引,导入时主键索引存在内存中,可能会导致占用内存较多。因此建议您遵循如下建议:
合理设置主键的列数和长度。建议主键为占用内存空间较少的数据类型,例如 INT、BIGINT 等,暂时不建议为 VARCHAR。
在建表前根据主键的数据类型和表的行数来预估主键索引占用内存空间,以避免出现内存溢出。以下示例说明主键索引占用内存空间的计算方式:
假设存在主键模型,主键为dt、id,数据类型为 DATE(4 个字节)、BIGINT(8 个字节)。则主键占 12 个字节。
假设该表的热数据有 1000 万行,存储为三个副本。
则内存占用的计算方式:
(12 + 9(每行固定开销) ) * 1000W * 3 * 1.5(哈希表平均额外开销) = 945 M自2.3.0 版本起,指标列新增支持 BITMAP、HLL 数据类型。创建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
自 2.4.0 版本起,主键模型支持单表和多表异步刷新物化视图。
使用ALTER TABLE时暂不支持修改主键的列类型,不支持调整指标列的顺序。
四种IO模型

四种IO模型
目录:
一.什么是IO ?
对于IO的简单理解,我们首先通过两个数据之间的交互过程来理解什么是IO?
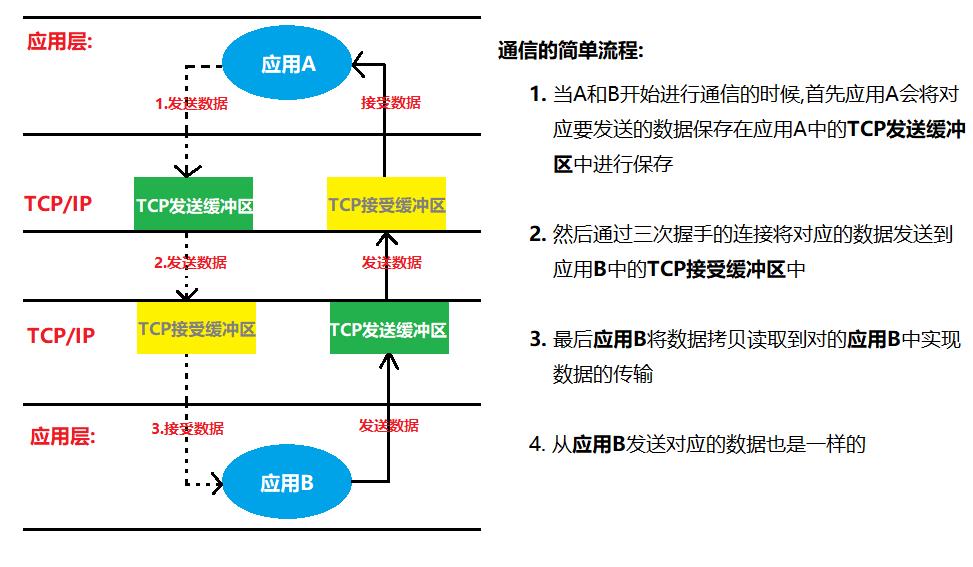
向上面这样数据从对应的发送缓冲区发送到对应的接受缓冲区的过程就叫做IO操作,对应的五种IO也是对于这里的不同操作.

二.阻塞IO

优点: 流程最为简单
~
缺点: 效率较为低下
三.非阻塞IO

优点: 效率对于阻塞队列有所提高
~
缺点: 需要进行多次循环来实现,不够实时
四.信号驱动IO

优点: 效率更高, 实时性更强
~
缺点: 操作流程比较复杂 ,需要定义信号的处理方式
五.异步IO

优点: 对于资源的利用率比较高 ,效率极高
~
缺点: 流程最为复杂

以上是关于StarRocksStarRocks四种数据模型的使用的主要内容,如果未能解决你的问题,请参考以下文章