贵金属实时行情看盘软件排行榜(top 10)
Posted 候鸟科讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贵金属实时行情看盘软件排行榜(top 10)相关的知识,希望对你有一定的参考价值。
贵金属实时行情看盘软件哪个好,还是得看MT4软件,MT4是俄罗斯软件公司MetaQuotes生产的一款以外汇和贵金属交易为主的软件,其功能十分全面,目前全球有超过100家贵金属公司和30个国家的银行选择MT4软件作为网络交易平台。MT4综合行情图表、技术分析、下单交易四大功能于一身,可以说为投资者提供了关于伦敦金交易的一切。
当投资者不在电脑旁时,智能手机和平板电脑就成为不可或缺的交易设备。投资者可以在iPhone/iPad 和android设备上使用移动版的MT4看盘和做单,它拥有完整的交易功能和全套的技术指标,投资者所可以随时随地捕捉市场中的交易机会。

那么贵金属实时行情看盘软件哪个好,该到哪里下载呢?大家在各大正规贵金属交易平台官网进行下载,下面给大家分享“贵金属实时行情看盘软件排行榜”供投资者参考。
1、金荣中国金融业有限公司
金荣中国金融业有限公司(upwaytrack.com/1eaa23d48af)成立于2010年,并受到香港金银业贸易场的监管。是香港金银业贸易场最高级别AA类行员,主要经营伦敦金、伦敦银、人民币公斤条等贵金属业务。
金荣中国APP:一款能与MT4通用的交易APP,金荣中国以“简单方便的操作,安全稳定的交易”获得全球451万+客户的支持与好评。平台累计处理5亿+订单,奠定了良好的行业声誉和广泛的社会影响。
行员编号:084号
点差优惠 :点差最高优惠25美元/手
交易软件:MT4交易平台/金荣APP
2、万洲金业集团有限公司
万洲金业集团有限公司(以下简称"万洲金业"),成立于2017年5月18日,专注为全球投资者提供专业的贵金属网上投资服务。万洲金业是香港金银业贸易场AA类141号行员,亦是标准金集团成员,持有贸易场认可之999.9黄金炼铸商证书,可经营伦敦金、伦敦银、九九金、公斤条港元、人民币公斤条、港币999.9五两黄金及港币999.9十五公斤白银。
行员编号:141号
入金门槛:200美元
交易软件:MT4交易平台
3、天誉金号有限公司
天誉国际为一间植根香港面向全球的金融机构,业务遍及亚太区及中国各大城市。其中天誉金号更是香港金银业贸易会员,而且同时是香港金银业贸易场的认可电子交易商。
行员编号:025号
会员类型:AA类
交易软件:MT4交易平台

4、金道贵金属有限公司
金道贵金属有限公司为金道投资控股有限公司(金道集团)之成员,于2009年在香港注册成立,持有香港金银业贸易场AA类别市场交易有效营业牌照,可经营99金、港元公斤条、伦敦金/银及人民币公斤条业务。
行员编号:074号
会员类型:AA类
交易软件:GST交易平台
5、香港国泰金业有限公司
香港国泰金业有限公司是香港金银业贸易场AA类会员,致力于为专业及个人投资者提供最优质的杠杆式黄金、白银24小时现货交易服务。
行员编号:096号
会员类型:AA类
交易软件:MT4交易平台
6、第一亚洲商人金银业有限公司
第一亚洲商人金银业有限公司,简称「第一金」,前名福而伟金号,于1991年在香港创立。第一金是香港金银业贸易场金集团成员,AA类会员,是金银业贸易场认可黄金炼铸商,可铸造9999成色的一公斤金条及伍両金条。
行员编号:114号
会员类型:AA类
交易软件:MT4交易平台
7、领峰贵金属有限公司
领峰贵金属有限公司是香港金银业贸易场AA类行员,可交易电子伦敦金银,香港99金和人民币公斤条等产品。领峰贵金属所有交易均受贸易场的认可和监管,并受香港法律的管制。
行员编号:145号
会员类型:AA类
交易软件:MT4交易平台

8、鼎展金业有限公司
鼎展金业有限公司(以下简称“鼎展金业”)为香港及国内外客户设有24小时贵金属买卖服务,鼎展金业为香港金银业贸易场"AA"类别行员。
行员编号:159号
会员类型:AA类
交易软件:MT4交易平台
9、亨达金银投资有限公司
亨达金银,全名亨达金银投资有限公司,是亨达集团全资拥有的子公司之一,于1990年于香港成立,已有25年的历史。亨达金银为香港金银业贸易业AA类行员,可经营99金、港元公斤条、人民币公斤条、伦敦金/银及电子黄金交易,AA类牌照属金银业贸易场中最高的级别。
行员编号:163号
会员类型:AA类
交易软件:MT4交易平台
10、汉声贵金属
汉声集团有限公司为香港金银业贸易场AA类208号行员,香港金银业贸易场会员,上海黄金交易所金银业贸易场(自营)国际会员,所有交易活动均受香港金银贸易场认可和监管,同时受到法律管制,可经营万足金、港元公斤条、伦敦金/银及人民币公斤条黄金业务。
行员编号:208号
会员类型:AA类
交易软件:MT4交易平台
以上就是“贵金属实时行情看盘软件排行榜(top 10)”介绍的全部内容,MT4软件是最适合新手和普通投资者的贵金属实时行情看盘软件,值得大家选择使用。
Python爬取百度实时热点排行榜
今天爬取的百度的实时热点排行榜
按照惯例,先下载网站的内容到本地:
1 def downhtml(): 2 url = \'http://top.baidu.com/buzz?b=1&fr=20811\' 3 headers = {\'User-Agent\':\'Mozilla/5.0\'} 4 r = requests.get(\'url\',headers=headers) 5 with open(\'C:/Code/info_baidu.html\',\'wb\') as f: 6 f.write(r.content)
因为我习惯把网页整个抓到本地再来分析数据,所以会有这一步,后面会贴直接抓取并分析的代码。
开始分析数据:
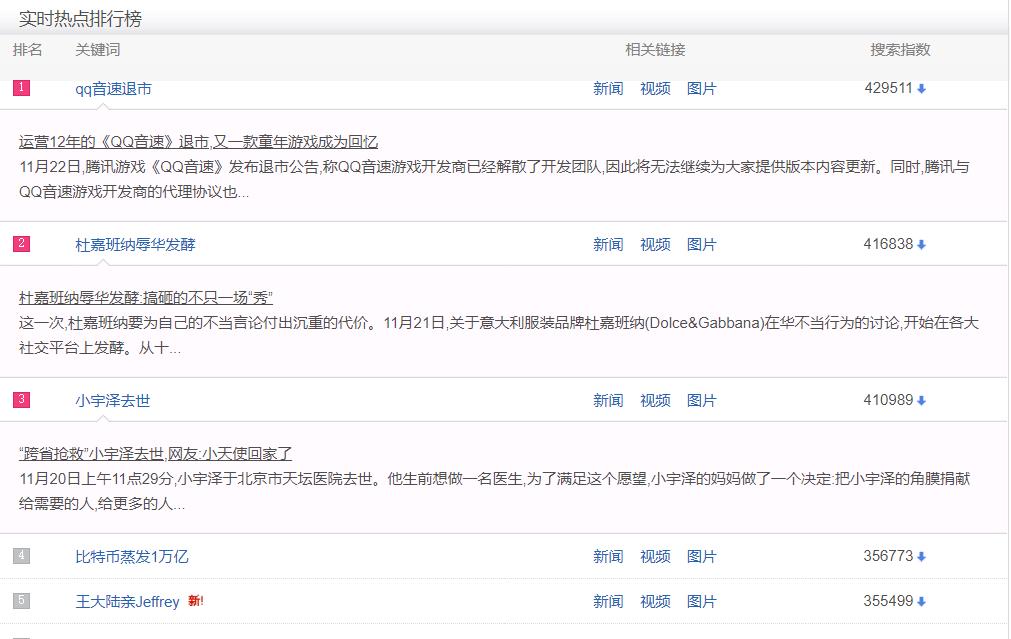
我想抓取的排名,关键词和搜索指数这三个值。
打开网页源代码:

发现每个标题的各个元素是一个个td被包装在一个tr标签里面,每一个标题都是一个tr(这里注意前三个标题的tr标签是有class=‘hideline’,而后面的则没有)
排名 :第一个td class=\'\'first\'
关键词:第二个td cass = \'keyword\'
搜索指数:最后一个td class = \'last\'
确定了我所需要的数据的位置了之后,可以开始写代码了。
写一个把打开本地html并返回给BeautifulSoup调用的函数:
def send_html():#把本地的html文件调给get_pages的BeautifulSoup path = \'C:/Code/info_baidu.html\' htmlfile= open(path,\'r\') htmlhandle = htmlfile.read() return htmlhandle
这样,我就可以在下面的直接用本地html来测试,而不用每次都去请求百度的服务器了。
def get_pages(html): soup = BeautifulSoup(html,\'html.parser\') all_topics=soup.find_all(\'tr\')[1:]#切片
因为第一个tr装的是这些东西
<tr> <th width="50" class="first">排名</th> <th>关键词</th> <th width="30%" class="tc">相关链接</th> <th width="20%" class="last">搜索指数</th> </tr>
并不是排名第一的标题,所以我用切片把它过滤掉了。
然后开始挨个赋值:
def get_pages(html): soup = BeautifulSoup(html,\'html.parser\') all_topics=soup.find_all(\'tr\')[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(\'td\',class_=\'last\').get_text()#搜索指数 topic_rank = each_topic.find(\'td\',class_=\'first\').get_text()#排名 topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text()#标题目 print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times))
这样按道理来说应该是可以输出了,但百度还是想给我一点难度。

这里出现几个问题,
1:AttributeError: \'NoneType\' object has no attribute \'get_text\'
2:输出的格式
3:只有一个值
按照惯例,第一个问题应该是里面多了一些不是Tag的类型,所以就来测试一下:
def get_pages(html): soup = BeautifulSoup(html,\'html.parser\') all_topics=soup.find_all(\'tr\')[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(\'td\',class_=\'last\')#搜索指数 print(type(topic_times))
输出如下:
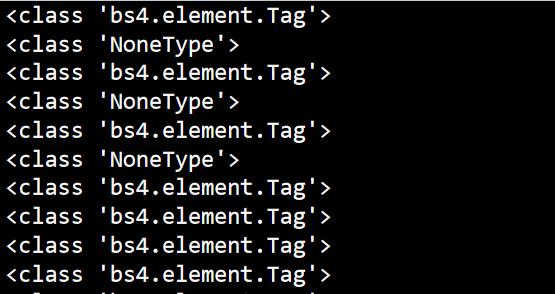
我们可以发现前几个值都参杂了NoneType(我去源代码看了一下,并不知道是什么导致的,等以后我知道了,再回来!)
因此,我们只要把NoneType给过滤掉就行。
def get_pages(html): soup = BeautifulSoup(html,\'html.parser\') all_topics=soup.find_all(\'tr\')[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(\'td\',class_=\'last\')#搜索指数 topic_rank = each_topic.find(\'td\',class_=\'first\')#排名 topic_name = each_topic.find(\'td\',class_=\'keyword\')#标题目 # print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times)) if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(\'td\',class_=\'first\').get_text() topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text() topic_times = each_topic.find(\'td\',class_=\'last\').get_text() print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times))
输出如下:

这样就解决了第一个问题,发现可以输出了,连第三个问题也解决了。
但第二个问题还在,这shit一般的格式让我很难受,导致这样的原因我猜是get_text时把一些空格符和换行符也一起输出了。
所以用replace()就应该可以解决了。
if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(\'td\',class_=\'first\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') topic_times = each_topic.find(\'td\',class_=\'last\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times))
输出如下:

哦吼,这样感觉就不错了。
但强迫症患者感觉还是很难受啊,这个热度(搜索指数)的格式也太乱了。
经过一番搜索,网友的力量还是很强大的啊哈哈哈,马上就有办法了。
if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(\'td\',class_=\'first\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') topic_times = each_topic.find(\'td\',class_=\'last\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') #print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times)) tplt = "排名:{0:^4}\\t标题:{1:{3}^15}\\t热度:{2:^7}" print(tplt.format(topic_rank,topic_name,topic_times,chr(12288)))
输出如下:

本强迫症患者终于满足了哈哈。
附上总代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 6 def send_html():#把本地的html文件调给get_pages的BeautifulSoup 7 path = \'C:/Code/info_baidu.html\' 8 htmlfile= open(path,\'r\') 9 htmlhandle = htmlfile.read() 10 return htmlhandle 11 12 def get_pages(html): 13 soup = BeautifulSoup(html,\'html.parser\') 14 all_topics=soup.find_all(\'tr\')[1:] 15 for each_topic in all_topics: 16 #print(each_topic) 17 topic_times = each_topic.find(\'td\',class_=\'last\')#搜索指数 18 topic_rank = each_topic.find(\'td\',class_=\'first\')#排名 19 topic_name = each_topic.find(\'td\',class_=\'keyword\')#标题目 20 if topic_rank != None and topic_name!=None and topic_times!=None: 21 topic_rank = each_topic.find(\'td\',class_=\'first\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 22 topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 23 topic_times = each_topic.find(\'td\',class_=\'last\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 24 #print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times)) 25 tplt = "排名:{0:^4}\\t标题:{1:{3}^15}\\t热度:{2:^7}" 26 print(tplt.format(topic_rank,topic_name,topic_times,chr(12288))) 27 28 if __name__ ==\'__main__\': 29 get_pages(send_html())
。
。
。
还有直接爬取不用下载网页的总代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def get_html(url,headers): 6 r = requests.get(url,headers=headers) 7 r.encoding = r.apparent_encoding 8 return r.text 9 10 11 def get_pages(html): 12 soup = BeautifulSoup(html,\'html.parser\') 13 all_topics=soup.find_all(\'tr\')[1:] 14 for each_topic in all_topics: 15 #print(each_topic) 16 topic_times = each_topic.find(\'td\',class_=\'last\')#搜索指数 17 topic_rank = each_topic.find(\'td\',class_=\'first\')#排名 18 topic_name = each_topic.find(\'td\',class_=\'keyword\')#标题目 19 if topic_rank != None and topic_name!=None and topic_times!=None: 20 topic_rank = each_topic.find(\'td\',class_=\'first\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 21 topic_name = each_topic.find(\'td\',class_=\'keyword\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 22 topic_times = each_topic.find(\'td\',class_=\'last\').get_text().replace(\' \',\'\').replace(\'\\n\',\'\') 23 #print(\'排名:{},标题:{},热度:{}\'.format(topic_rank,topic_name,topic_times)) 24 tplt = "排名:{0:^4}\\t标题:{1:{3}^15}\\t热度:{2:^8}" 25 print(tplt.format(topic_rank,topic_name,topic_times,chr(12288))) 26 27 def main(): 28 url = \'http://top.baidu.com/buzz?b=1&fr=20811\' 29 headers= {\'User-Agent\':\'Mozilla/5.0\'} 30 html = get_html(url,headers) 31 get_pages(html) 32 33 if __name__==\'__main__\': 34 main()
好了。完成任务,生活愉快!
以上是关于贵金属实时行情看盘软件排行榜(top 10)的主要内容,如果未能解决你的问题,请参考以下文章
好课推荐挖矿教程软件数字货币区块链实时实用技术基础理论全套视频课程
清华世界第一!2020 USNews世界大学计算机科学排行榜;区块链平均薪资1.6万;Spring Framework5.2.1