创作赢红包SQL Server之索引设计
Posted Lion Long
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创作赢红包SQL Server之索引设计相关的知识,希望对你有一定的参考价值。
SQL Server之索引设计
一、前言
索引设计不佳和缺少索引是提高数据库和应用程序性能的主要障碍。 设计高效的索引对于获得良好的数据库和应用程序性能极为重要。 本索引设计指南包含关于索引体系结构的信息,以及有助于设计有效索引以满足应用程序需求的最佳做法。
二、索引设计背景知识
就像一本书,书本末尾有一个索引,可帮助快速查找书籍内的信息。 索引是按顺序排列的关键字列表,每个关键字旁边是一组页码,这些页码指向可在其中找到每个关键字的页面。
行存储索引也一样:它是按顺序排列的值列表,每个值都有指向这些值所在的数据页面的指针。 索引本身存储在页上,称为索引页。
索引是与表或视图关联的磁盘上或内存中结构,可以加快从表或视图中检索行的速度。 行存储索引包含由表或视图中的一列或多列生成的键。 对于行存储索引,这些键以树结构(B+ 树)存储,使数据库引擎可以快速高效地找到与键值关联的一行或多行。
行存储索引将逻辑组织的数据存储为包含行和列的表,物理上以行数据格式(称为 行存储1)存储,或以名为列 存储的列数据格式存储。
为数据库及其工作负荷选择正确的索引是一项需要在查询速度与更新所需开销之间取得平衡的复杂任务。 如果基于磁盘的行存储索引较窄,或者说索引关键字中只有很少的几列,则需要的磁盘空间和维护开销都较少。 而另一方面,宽索引可覆盖更多的查询。 您可能需要试验若干不同的设计,才能找到最有效的索引。 可以添加、修改和删除索引而不影响数据库架构或应用程序设计。 因此,应试验多个不同的索引而无需犹豫。
数据库引擎的查询优化器可在大多数情况下可靠地选择最高效的索引。 总体索引设计策略应为查询优化器提供可供选择的多个索引,并依赖查询优化器做出正确的决定。 这在多种情况下可减少分析时间并获得良好的性能。
不要总是将索引的使用等同于良好的性能,或者将良好的性能等同于索引的高效使用。 如果只要使用索引就能获得最佳性能,那查询优化器的工作就简单了。 但事实上,不正确的索引选择并不能获得最佳性能。 因此,查询优化器的任务是只在索引或索引组合能提高性能时才选择它,而在索引检索有碍性能时则避免使用它。
行存储是存储关系表数据的传统方法。 “行存储”是指基础数据存储格式为堆、B+ 树(聚集索引)或内存优化表的表。 “基于磁盘的行存储”排除了内存优化表。
2.1、索引设计策略包括的任务
-
了解数据库本身的特征。例如,内存优化表和索引提供无闩锁设计,尤其适用于数据库是否是频繁修改数据的联机事务处理 (OLTP) 数据库的应用场景。 或者, 列存储索引尤其适用于典型的数据仓库数据集。 列存储索引可以通过为常见数据仓库查询(如筛选、聚合、分组和星型联接查询)提供更快的性能,以转变用户的数据仓库体验。
-
了解最常用的查询的特征。 例如,了解到最常用的查询联接两个或多个表将有助于决定要使用的最佳索引类型。
-
了解查询中使用的列的特征。 例如,某个索引对于含有整数数据类型同时还是唯一的或非空的列是理想索引。
-
确定哪些索引选项可在创建或维护索引时提高性能。 例如,对某个现有大型表创建聚集索引将会受益于 ONLINE 索引选项。 ONLINE 选项允许在创建索引或重新生成索引时继续对基础数据执行并发活动。
-
确定索引的最佳存储位置。非聚集索引可以与基础表存储在同一个文件组中,也可以存储在不同的文件组中。 索引的存储位置可通过提高磁盘 I/O 性能来提高查询性能。
-
使用动态管理视图 (DMV)(例如 sys.dm_db_missing_index_details 和 sys.dm_db_missing_index_columns)识别缺失索引时,可能会在同一个表和列上获得类似的索引变体。 检查表上的现有索引以及缺失索引建议,以防止创建重复索引。
三、常规索引设计
了解数据库、查询和数据列的特征可以帮助设计出最佳索引。
3.1、数据库注意事项
设计索引时,应考虑以下数据库准则:
-
对表编制大量索引会影响 INSERT、UPDATE、DELETE 和 MERGE 语句的性能,因为当表中的数据更改时,所有索引都须适当调整。避免对经常更新的表进行过多的索引,并且索引应保持较窄,就是说,列要尽可能少;使用多个索引可以提高更新少而数据量大的查询的性能。 大量索引可以提高不修改数据的查询(例如 SELECT 语句)的性能,因为查询优化器有更多的索引可供选择,从而可以确定最快的访问方法。
-
对小表进行索引可能不会产生优化效果,因为查询优化器在遍历用于搜索数据的索引时,花费的时间可能比执行简单的表扫描还长。 因此,小表的索引可能从来不用,但仍必须在表中的数据更改时进行维护。
-
视图包含聚合、表联接或聚合和联接的组合时,视图的索引可以显著地提升性能。 若要使查询优化器使用视图,并不一定非要在查询中显式引用该视图。
-
可以选择启用自动索引优化。
-
查询存储有助于识别性能不佳的查询,并提供查询执行计划的历史记录,其中记录由优化器选择的索引。
3.2、查询注意事项
设计索引时,应考虑以下查询准则:
-
为经常用于查询中的谓词和联接条件的列创建非聚集索引。 但是,应避免添加不必要的列。 添加太多索引列可能对磁盘空间和索引维护性能产生负面影响。
-
涵盖索引可以提高查询性能,因为符合查询要求的全部数据都存在于索引本身中。 也就是说,只需要索引页,而不需要表的数据页或聚集索引来检索所需数据,因此,减少了总体磁盘 I/O。
-
将插入或修改尽可能多的行的查询写入单个语句内,而不要使用多个查询更新相同的行。 仅使用一个语句,就可以利用优化的索引维护。
-
评估查询类型以及如何在查询中使用列。 例如,在完全匹配查询类型中使用的列就适合用于非聚集索引或聚集索引。
3.3、列注意事项
设计索引时,应考虑以下列准则:
-
对于聚集索引,请保持较短的索引键长度。 另外,对唯一列或非空列创建聚集索引可以使聚集索引获益。
-
无法指定 ntext、 text、 image、 varchar(max) 、 nvarchar(max) 和 varbinary(max) 数据类型的列为索引键列。 不过, varchar(max) 、 nvarchar(max) 、 varbinary(max) 和 xml 数据类型的列可以作为非键索引列参与非聚集索引。
-
xml 数据类型的列只能在 XML 索引中用作键列。
-
检查列的唯一性。 在同一个列组合的唯一索引而不是非唯一索引提供了有关使索引更有用的查询优化器的附加信息。
-
在列中检查数据分布。 通常情况下,为包含很少唯一值的列创建索引或在这样的列上执行联接将导致长时间运行的查询。
-
考虑对具有定义完善的子集的列(例如,稀疏列、大部分值为 NULL 的列、含各类值的列以及含不同范围的值的列)使用筛选索引。 设计良好的筛选索引可以提高查询性能,降低索引维护成本和存储成本。
-
如果索引包含多个列,则应考虑列的顺序。 WHERE 子句中使用的列应位于等于 (=) 、大于 (>) 、小于 (<) 或 BETWEEN 搜索条件或参与联接的列。 其他列应该基于其非重复级别进行排序,就是说,从最不重复的列到最重复的列。
-
考虑对计算列进行索引。
3.4、索引的特征
在确定某一索引适合某一查询之后,可以选择最适合具体情况的索引类型。 索引包含以下特性:
- 聚集还是非聚集
- 唯一还是非唯一
- 单列还是多列
- 索引中的列是升序排序还是降序排序
- 非聚集索引是全表还是经过筛选
- 列存储与行存储
- 内存优化表的哈希索引与非聚集索引
也可以通过SQL Server的设置选项自定义索引的初始存储特征以优化其性能或维护。 而且,通过使用文件组或分区方案可以确定索引存储位置来优化性能。
3.5、索引排序顺序设计指南
定义索引时,请考虑索引键列的数据是按升序还是按降序存储。CREATE INDEX、CREATE TABLE 和 ALTER TABLE 语句的语法在索引和约束中的各列上支持关键字 ASC(升序)和 DESC(降序):
当引用表的查询包含用以指定索引中键列的不同方向的 ORDER BY 子句时,指定键值存储在该索引中的顺序很有用。 在这些情况下,索引就无需在查询计划中使用 SORT 运算符。因此,使得查询更有效。
检索数据以满足此条件需要将 Purchasing.PurchaseOrderDetail 表中的 RejectedQty 列按降序(由大到小)排序,并且将 ProductID 列按升序(由小到大)排序,比如:
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
此查询的下列执行计划显示了查询优化器使用 SORT 运算符按 ORDER BY 子句指定的顺序返回结果集。
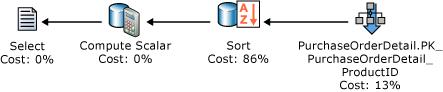
如果使用与查询的 ORDER BY 子句中的键列匹配的键列创建基于磁盘的行存储索引,则无需在查询计划中使用 SORT 运算符,从而使查询计划更有效。
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
再次执行查询后,下列执行计划显示未使用 SORT 运算符,而使用了新创建的非聚集索引。
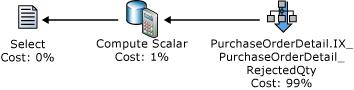
总结
覆盖索引是针对非聚集索引的指定,它直接解析一个或几个类似的查询结果,而不访问其基表,并且不会引发查找。 这意味着,由 SELECT 子句以及所有 WHERE 和 JOIN 参数返回的列都被索引所覆盖。 当与表本身的行和列相比,如果索引足够窄,那么执行查询的 I/O 可能会少得多,这意味着它是总列的一个真正子集。 如果选择大型表的一小部分,请考虑覆盖索引,其中的小部分是由一个固定谓词定义,比如一个稀疏列,例如它只包含几个非 NULL 值。

创作赢红包Java多线程:synchronized锁方法块
synchronized同步代码块 用关键字synchronized声明方法在某些情况下是有弊端的,比如A线程调用同步方法执行一个较长时间的任务,那么B线程必须等待比较长的时间。这种情况下可以尝试使用synchronized同步语句块来解决问题。看一下例子: public class ThreadDomain18
public void doLongTimeTask() throws Exception
for (int i = 0; i < 100; i++)
System.out.println(
"nosynchronized threadName = " + Thread.currentThread().getName() + ", i = " + (i + 1));
System.out.println();
synchronized (this)
for (int i = 0; i < 100; i++)
System.out.println(
"synchronized threadName = " + Thread.currentThread().getName() + ", i = " + (i + 1));
public class MyThread18 extends Thread
private ThreadDomain18 td;
public MyThread18(ThreadDomain18 td)
this.td = td;
public void run()
try
td.doLongTimeTask();
catch (Exception e)
e.printStackTrace();
public static void main(String[] args)
ThreadDomain18 td = new ThreadDomain18();
MyThread18 mt0 = new MyThread18(td);
MyThread18 mt1 = new MyThread18(td);
mt0.start();
mt1.start();
synchronized threadName = Thread-1, i = 1 synchronized threadName = Thread-1, i = 2 nosynchronized threadName = Thread-0, i = 95 synchronized threadName = Thread-1, i = 3 nosynchronized threadName = Thread-0, i = 96 synchronized threadName = Thread-1, i = 4 nosynchronized threadName = Thread-0, i = 97 synchronized threadName = Thread-1, i = 5 nosynchronized threadName = Thread-0, i = 98 synchronized threadName = Thread-1, i = 6 nosynchronized threadName = Thread-0, i = 99 synchronized threadName = Thread-1, i = 7 nosynchronized threadName = Thread-0, i = 100 ... synchronized threadName = Thread-1, i = 98 synchronized threadName = Thread-1, i = 99 synchronized threadName = Thread-1, i = 100 synchronized threadName = Thread-0, i = 1 synchronized threadName = Thread-0, i = 2 synchronized threadName = Thread-0, i = 3 ...这个实验可以得出以下两个结论: 1、 当A线程访问对象的synchronized代码块的时候,B线程依然可以访问对象方法中其余非synchronized块的部分,第一部分的执行结果证明了这一点 2、 当A线程进入对象的synchronized代码块的时候,B线程如果要访问这段synchronized块,那么访问将会被阻塞,第二部分的执行结果证明了这一点 所以,从执行效率的角度考虑,有时候我们未必要把整个方法都加上synchronized,而是可以采取synchronized块的方式,对会引起线程安全问题的那一部分代码进行synchronized就可以了。 两个synchronized块之间具有互斥性 如果线程1访问了一个对象A方法的synchronized块,那么线程B对同一对象B方法的synchronized块的访问将被阻塞,写个例子来证明一下:
public class ThreadDomain19
public void serviceMethodA()
synchronized (this)
try
System.out.println("A begin time = " + System.currentTimeMillis());
Thread.sleep(2000);
System.out.println("A end time = " + System.currentTimeMillis());
catch (InterruptedException e)
e.printStackTrace();
public void serviceMethodB()
synchronized (this)
System.out.println("B begin time = " + System.currentTimeMillis());
System.out.println("B end time = " + System.currentTimeMillis());
public class MyThread19_0 extends Thread
private ThreadDomain19 td;
public MyThread19_0(ThreadDomain19 td)
this.td = td;
public void run()
td.serviceMethodA();
public class MyThread19_1 extends Thread
private ThreadDomain19 td;
public MyThread19_1(ThreadDomain19 td)
this.td = td;
public void run()
td.serviceMethodB();
public static void main(String[] args)
ThreadDomain19 td = new ThreadDomain19();
MyThread19_0 mt0 = new MyThread19_0(td);
MyThread19_1 mt1 = new MyThread19_1(td);
mt0.start();
mt1.start();
A begin time = 1443843271982 A end time = 1443843273983 B begin time = 1443843273983 B end time = 1443843273983看到对于serviceMethodB()方法synchronized块的访问必须等到对于serviceMethodA()方法synchronized块的访问结束之后。那其实这个例子,我们也可以得出一个结论: synchronized块获得的是一个对象锁,换句话说,synchronized块锁定的是整个对象 。 synchronized块和synchronized方法 既然上面得到了一个结论 synchronized块获得的是对象锁 ,那么如果线程1访问了一个对象方法A的synchronized块,线程2对于同一对象同步方法B的访问应该是会被阻塞的,因为线程2访问同一对象的同步方法B的时候将会尝试去获取这个对象的对象锁,但这个锁却在线程1这里。写一个例子证明一下这个结论:
public class ThreadDomain20
public synchronized void otherMethod()
System.out.println("----------run--otherMethod");
public void doLongTask()
synchronized (this)
for (int i = 0; i < 1000; i++)
System.out.println(
"synchronized threadName = " + Thread.currentThread().getName() + ", i = " + (i + 1));
try
Thread.sleep(5);
catch (InterruptedException e)
e.printStackTrace();
public class MyThread20_0 extends Thread
private ThreadDomain20 td;
public MyThread20_0(ThreadDomain20 td)
this.td = td;
public void run()
td.doLongTask();
public class MyThread20_1 extends Thread
private ThreadDomain20 td;
public MyThread20_1(ThreadDomain20 td)
this.td = td;
public void run()
td.otherMethod();
public static void main(String[] args) throws Exception
ThreadDomain20 td = new ThreadDomain20();
MyThread20_0 mt0 = new MyThread20_0(td);
MyThread20_1 mt1 = new MyThread20_1(td);
mt0.start();
Thread.sleep(100);
mt1.start();
... synchronized threadName = Thread-0, i = 995 synchronized threadName = Thread-0, i = 996 synchronized threadName = Thread-0, i = 997 synchronized threadName = Thread-0, i = 998 synchronized threadName = Thread-0, i = 999 synchronized threadName = Thread-0, i = 1000 ----------run--otherMethod证明了我们的结论。为了进一步完善这个结论,把"otherMethod()"方法的synchronized去掉再看一下运行结果:
... synchronized threadName = Thread-0, i = 16 synchronized threadName = Thread-0, i = 17 synchronized threadName = Thread-0, i = 18 synchronized threadName = Thread-0, i = 19 synchronized threadName = Thread-0, i = 20 ----------run--otherMethod synchronized threadName = Thread-0, i = 21 synchronized threadName = Thread-0, i = 22 synchronized threadName = Thread-0, i = 23 ..."otherMethod()"方法和"doLongTask()"方法中的synchronized块异步执行了 将任意对象作为对象监视器 总结一下前面的内容: 1、synchronized同步方法 (1)对其他synchronized同步方法或synchronized(this)同步代码块呈阻塞状态 (2)同一时间只有一个线程可以执行synchronized同步方法中的代码 2、synchronized同步代码块 (1)对其他synchronized同步方法或synchronized(this)同步代码块呈阻塞状态 (2)同一时间只有一个线程可以执行synchronized(this)同步代码块中的代码 前面都使用synchronized(this)的格式来同步代码块,其实 Java还支持对"任意对象"作为对象监视器来实现同步的功能 。这个"任意对象"大多数是 实例变量 及 方法的参数 ,使用格式为synchronized(非this对象)。看一下将任意对象作为对象监视器的使用例子:
public class ThreadDomain21
private String userNameParam;
private String passwordParam;
private String anyString = new String();
public void setUserNamePassword(String userName, String password)
try
synchronized (anyString)
System.out.println("线程名称为:" + Thread.currentThread().getName() + "在 " + System.currentTimeMillis() + " 进入同步代码块");
userNameParam = userName;
Thread.sleep(3000);
passwordParam = password;
System.out.println("线程名称为:" + Thread.currentThread().getName() + "在 " + System.currentTimeMillis() + " 离开同步代码块");
catch (InterruptedException e)
e.printStackTrace();
public class MyThread21_0 extends Thread
private ThreadDomain21 td;
public MyThread21_0(ThreadDomain21 td)
this.td = td;
public void run()
td.setUserNamePassword("A", "AA");
public class MyThread21_1 extends Thread
private ThreadDomain21 td;
public MyThread21_1(ThreadDomain21 td)
this.td = td;
public void run()
td.setUserNamePassword("B", "B");
public static void main(String[] args)
ThreadDomain21 td = new ThreadDomain21();
MyThread21_0 mt0 = new MyThread21_0(td);
MyThread21_1 mt1 = new MyThread21_1(td);
mt0.start();
mt1.start();
线程名称为:Thread-0在 1443855101706 进入同步代码块 线程名称为:Thread-0在 1443855104708 离开同步代码块 线程名称为:Thread-1在 1443855104708 进入同步代码块 线程名称为:Thread-1在 1443855107708 离开同步代码块这个例子证明了: 多个线程持有"对象监视器"为同一个对象的前提下,同一时间只能有一个线程可以执行synchronized(非this对象x)代码块中的代码 。 锁非this对象具有一定的优点:如果在一个类中有很多synchronized方法,这时虽然能实现同步,但会受到阻塞,从而影响效率。但如果同步代码块锁的是非this对象,则synchronized(非this对象x)代码块中的程序与同步方法是异步的,不与其他锁this同步方法争抢this锁,大大提高了运行效率。 注意一下"private String anyString = new String();"这句话,现在它是一个全局对象,因此监视的是同一个对象。如果移到try里面,那么对象的监视器就不是同一个了,调用的时候自然是异步调用,可以自己试一下。 最后提一点,synchronized(非this对象x),这个对象如果是实例变量的话,指的是对象的引用, 只要对象的引用不变,即使改变了对象的属性,运行结果依然是同步的 。 细化synchronized(非this对象x)的三个结论 synchronized(非this对象x)格式的写法是将x对象本身作为对象监视器,有三个结论得出: 1、当多个线程同时执行synchronized(x)同步代码块时呈同步效果 2、当其他线程执行x对象中的synchronized同步方法时呈同步效果 3、当其他线程执行x对象方法中的synchronized(this)代码块时也呈同步效果 第一点很明显,第二点和第三点意思类似,无非一个是同步方法,一个是同步代码块罢了,举个例子验证一下第二点:
public class MyObject
public synchronized void speedPrintString()
System.out.println("speedPrintString__getLock time = " + System.currentTimeMillis() + ", run ThreadName = " + Thread.currentThread().getName());
System.out.println("----------");
System.out.println("speedPrintString__releaseLock time = " + System.currentTimeMillis()+ ", run ThreadName = " + Thread.currentThread().getName());
ThreadDomain24中持有MyObject的引用:
public class ThreadDomain24
public void testMethod1(MyObject mo)
try
synchronized (mo)
System.out.println("testMethod1__getLock time = " + System.currentTimeMillis() + ", run ThreadName = " + Thread.currentThread().getName());
Thread.sleep(5000);
System.out.println("testMethod1__releaseLock time = " + System.currentTimeMillis() + ", run ThreadName = " + Thread.currentThread().getName());
catch (InterruptedException e)
e.printStackTrace();
public class MyThread24_0 extends Thread
private ThreadDomain24 td;
private MyObject mo;
public MyThread24_0(ThreadDomain24 td, MyObject mo)
this.td = td;
this.mo = mo;
public void run()
td.testMethod1(mo);
public class MyThread24_1 extends Thread
private MyObject mo;
public MyThread24_1(MyObject mo)
this.mo = mo;
public void run()
mo.speedPrintString();
public static void main(String[] args)
ThreadDomain24 td = new ThreadDomain24();
MyObject mo = new MyObject();
MyThread24_0 mt0 = new MyThread24_0(td, mo);
MyThread24_1 mt1 = new MyThread24_1(mo);
mt0.start();
mt1.start();
testMethod1__getLock time = 1443855939811, run ThreadName = Thread-0 testMethod1__releaseLock time = 1443855944812, run ThreadName = Thread-0 speedPrintString__getLock time = 1443855944812, run ThreadName = Thread-1 ---------- speedPrintString__releaseLock time = 1443855944812, run ThreadName = Thread-1看到"speedPrintString()"方法必须等待"testMethod1(MyObject mo)"方法执行完毕才可以执行,没有办法异步执行,证明了第二点的结论。第三点的验证方法类似,就不写代码证明了。
以上是关于创作赢红包SQL Server之索引设计的主要内容,如果未能解决你的问题,请参考以下文章