推荐算法CTR中embedding层的学习和训练
Posted 山顶夕景
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法CTR中embedding层的学习和训练相关的知识,希望对你有一定的参考价值。
note
- 连续特征处理:facebook DLRM模型,对连续值的处理方式是把所有的连续值输入到一个神经网络,然后通过神经网络把它压缩到一个embedding维度大小的一个向量上,然后将Embedding和其他离散特征Embedding Concat起来,再做后面根据它的模型去做不同的计算;同时离散化(转为类别变量)然后送入embedding是常见操作。
- 分布式并行训练:数据并行;多卡切分;CPU的内存来存embedding,然后用GPU来存MLP等。
- 本文概况:
- 怎样去结合数据设计更好的模型,让模型更有针对性。
- 如何进一步提升训练效率,包括怎样去利用更多的数据,以及增快模型迭代效率。
- 怎样去增强数据处理、选择、模型调优的自动化的程度,从而解放业务或者算法同学,更多地去关注模型数据、算法和策略。
文章目录
- note
- 一、CTR模型
- 二、连续值处理(Continuous Feature)
- 三、交叉特征建模(Interaction Modelling)
- 四、大Embedding模型训练(Distributed Training)
- Reference
一、CTR模型
推广搜领域中CTR点击率预估模型的发展历史如下图,逐渐从人工经验向自动化,深度学习模型的归一化,业界期望用自适应模型解决业务问题。
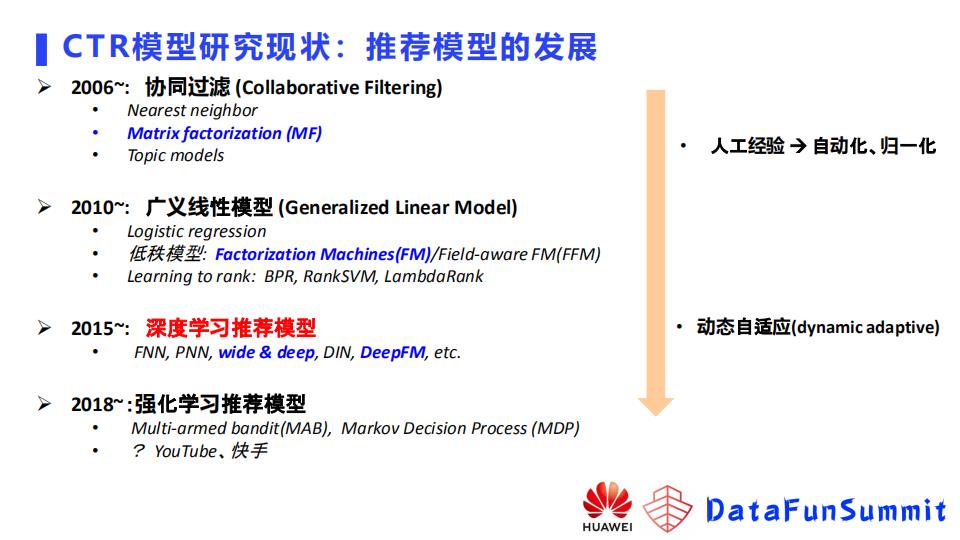
2021年IJCAI一篇综述,张伟楠和华为诺亚方舟实验室的论文,将深度学习CTR模型分类:
- 基于组合特征挖掘的模型;
- 针对用户行为的模型;
- 自动架构搜索的模型。
1.1 用户行为挖掘
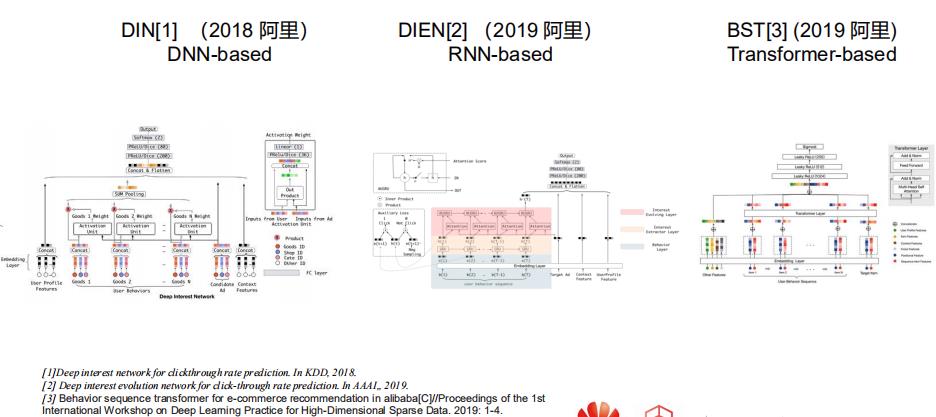
- 阿里妈妈17年的DIN,用dnn里的pooling将用户历史行为建模
- 19年阿里妈妈在DIN上增加RNN形成DIEN,规避了DIN这种将过去历史行为都等同看待的劣势,拟合序列关系
- 19年阿里BST加入transformer
1.2 组合特征挖掘

- wide&deep的wide特征之间笛卡尔积相乘后构建出新特征,加入到线性部分;当下次组合特征出现时,直接把它的权重取出做预测
- deepfm这种双塔范式,后面也衍生DCN、xDeepFM等,建模特征之间的组合关系
- PNN网络,利用分解模式构建组合特征后,还会把输出喂入MLP,拟合特征之间关系
1.3 高效利用数据

- 组合特征建模:
- 显式的交互特征喂入深度模型可以带来提升(CAN)
- 模型需要筛选交叉特征重要性(华为诺亚方舟2020年发的AutoFIS,针对交叉特征加了一组参数,用来自动去学哪些特征重要,哪些特征不重要。通过第一阶段的搜索,筛选出重要特征,把不重要的去掉,再重新输入到模型,这样做效果有明显提升。)
- 用户行为建模:
- 针对行为数据加入检索模块SIM或者UBR
- 如上图所示,用户的行为进来之后,通过一个行为建模的模块,比如RNN或者是transformer,就会得到一个用户的embedding,再和其他的特征一起注入到模型去做预测。这里的检索基于一个target,即预测目标,去对用户的行为做了一个筛选或者加权。基于这样的操作,模型会有很明显的提升。

1.4 处理大embedding
- 思路一:怎样把embedding变小,也就是将embedding压缩;
- twitter在Recsys2021发表的double hash,把特征分为高频和低频,因为高频特征相对占比娇小,给每个高频特征分配一个独立的embedding(所占空间不大),对于低频特征使用double hash压缩,减少冲突
- 百度在sigmod2021基于int16训练embedding参数,即基于低比特参数模型训练
- 探索类工作:谷歌在kdd2021上发的DHE模型, 去掉了embedding table
- 思路二:怎么用更新的分布式架构去更高效更低成本的去训练大embedding。
- 用的最多,基于GPU这种Horovod去数据同步
- 腾讯发表于SIGIR2020的DES通过模型结合硬件设计了一个分布式的方案。英伟达提出基于cude直接写了一个HugeCTR。
二、连续值处理(Continuous Feature)

- 第一种方法,No Embedding。
- 第一个是wide&Deep,在它的介绍里面,使用的是原始值,
- 另外一个是谷歌的YouTubeNet,它会对原始值做平方开根号这些变换。
- 另一个是facebook DLRM模型,对连续值的处理方式是把所有的连续值输入到一个神经网络,然后通过神经网络把它压缩到一个embedding维度大小的一个向量上,然后将Embedding和其他离散特征Embedding Concat起来,再做后面根据它的模型去做不同的计算。
- 京东的DMT模型,他们的网络是使用了归一化的输出,这种方法表示能力比较弱,因为它这里其实没有对原始的延续特征做一个很好的表示。
- 第二种处理连续值的方法是Field Embedding;
- 每个域有一个Embedding。某个域的Embedding是该域的一个连续值,乘上它的域的Embedding。这类方法的问题是表示能力比较弱,然后不同值之间是一个线性的关系。
- 第三类的方法就是离散化。离散化可以有很多方法,比方说等频、等距和取log,或者基于树的模型去做一个预训练。但这类方法有两个问题:
- 首先,就是它是两阶段的,离散化的过程不能端到端优化;
- 另外,有一些边界的问题,如下图所示的例子,一个年龄特征,假设我们按40,41来分,40以下的我们称之为青年,41以上的成为中年,其实40和41,它们是很接近的年龄,但是因为我们的离散化的方法,把它分到两个不同的桶里面,可能学到的Embedding是差异比较大的Embedding。
更多参考:华为提出的一个连续值Embedding的方法AutoDis。看线上效果,在点击率及eCPM这两个指标上都是有一个百分位的提升。
三、交叉特征建模(Interaction Modelling)

- 第一类像FNN模型,即不建模,每个特征有一个embedding,所有的特征embedding后concat拼接输入网络,后面网络自己去学,想学到什么就是什么。
- 第二类像wide&deep模型,这里统称为基于记忆的方法,就是去显示的构造组合特征,特征做交叉做笛卡尔积,然后把新构造的特征输入模型。模型就会记住这个特征,这个信号就比较强。
- 第三类方法就是基于分解的方法,例如IPNN模型,对不同的域之间的交叉关系,通过乘法的方式去做建模,得到的乘法结果会和原始embedding一起喂入到后面的MLP,然后来再次去做一个组合。不同的特征之间是不是都应该组合,或者说怎么去组合,如果我们去试的话,需要去做很多实验,能不能自动判断特征是不是要组合,以及它们之间应该用哪种组合这种关系去学到呢。
更多参考:华为提出的OptInter交叉特征建模。在Criteo、Avazu、iPinYou等经典CTR数据集效果不错。
四、大Embedding模型训练(Distributed Training)

推荐模型一般两部分:参数embedding(参数量大,计算量较少,但是GPU显存一般存不下,如上面有的模型几百个G,V100有32个G,土豪忽略);MLP参数量较少,计算量较大。

高维稀疏特征导致embedding较大。较常用的并行训练方法:
- 第一类是数据并行,例如基于all-reduce的Horovod,这种方式在每个GPU卡中存一份完整的模型副本,需要把模型都能存得下,我们模型如果变得大,GPU显存不足以存下完整模型,即使模型可以存得下,比方说有十几G几十G,基于这样一个大小的模型,它在做通信的时候,它的通信的时延很可能比它计算带来的时间的减少还要来得多,也就是说你增加节点不一定带来性能的一个提升。
- 第二类是NVIDIA提出的,之前他们的方案还是一个多卡切分的方案,但现在已经支持了一个CPU的embedding的一个存储,他们这个方法把embedding切成多份,然后在每个卡的显存里面存一部分,MLP在每个节点都存一个完整的模型。embeding通过一个all to all的通信, MLP通过all-reduce通信,这个方案有一个问题就是当它的模型很大时需要的GPU卡很多,从而它的成本也会很高。
- 第三类方法是使用CPU的内存来存embedding,然后用GPU来存MLP。CPU负责存储,MLP来负责前项以及反向的梯度的计算。对于这种方法,如果我们采用同步训练的话,它有一个问题就是因为embedding是存在CPU侧的,需要从CPU去传输到GPU,梯度需要从GPU回传到CPU,他们之间通信的时延是很高的。
Reference
[1] 郭慧丰博士. 华为技术分享.点击率预测模型Embedding层的学习和训练
推荐系统实战5——EasyRec 在DSSM召回模型中添加负采样构建CTR点击平台
推荐系统实战5——EasyRec 在DSSM召回模型中添加负采样构建CTR点击平台
学习前言
当物品池很大上百万甚至是上亿的时候,不能仅考虑少量的正样本与负样本,因为物品太多,大多数物品都是负样本,此时双塔召回模型常常需要针对每个正样本采样一千甚至一万的负样本才能达到比较好的召回效果,

EasyRec仓库地址
官方库地址:
https://github.com/alibaba/EasyRec
带注释的Config地址:
https://github.com/bubbliiiing/EasyRec-Config
DSSM实现思路
一、DSSM整体结构解析
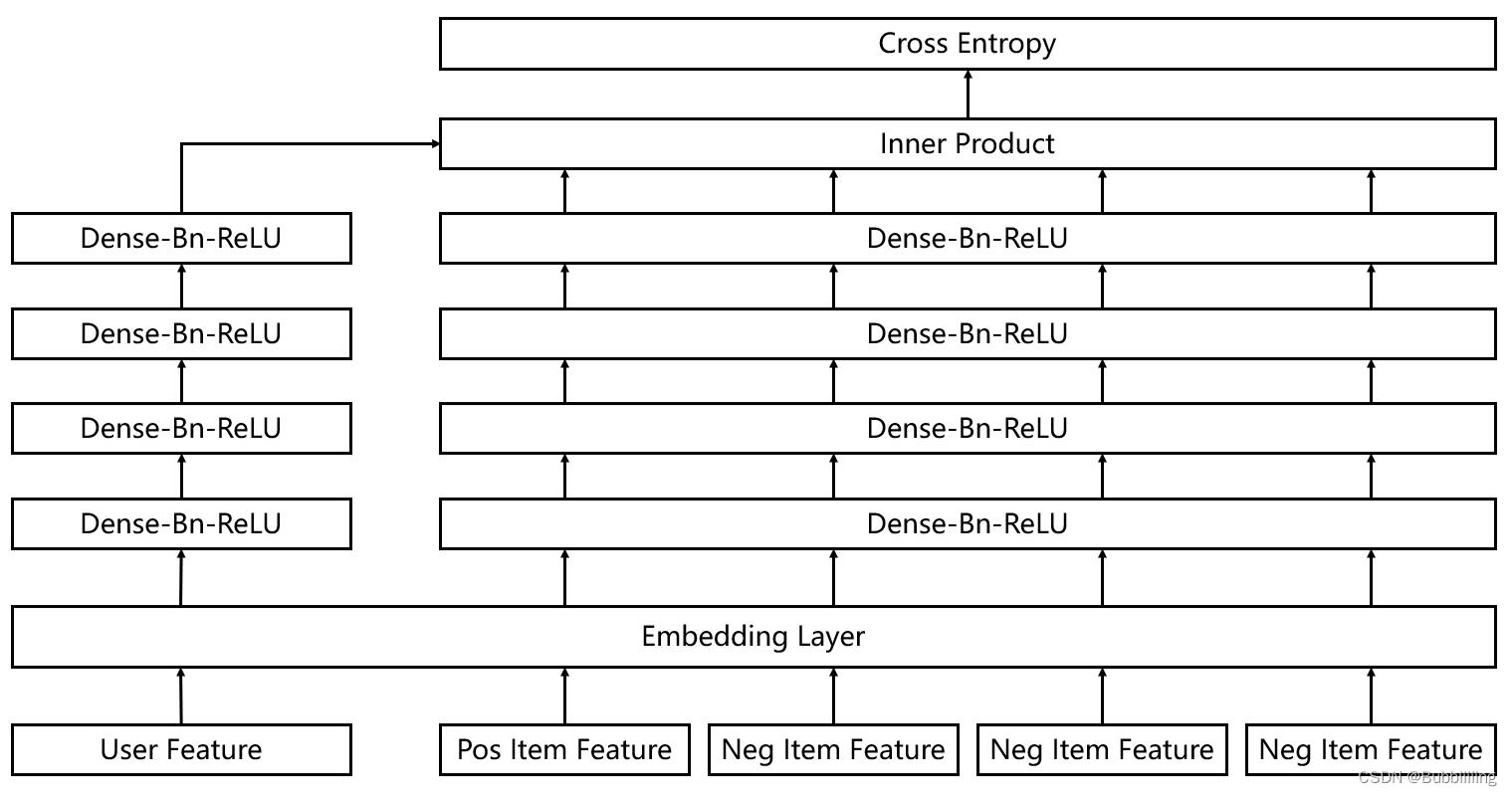
DSSM的论文地址为:
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
DSSM全称为Deep Structured Semantic Model,是微软发表的一篇论文,其核心思想是将user和item映射到到共同维度的语义空间中,通过最大化user和item语义向量之间的余弦相似度,达到检索的目的。
在推荐场景基于DSSM的双塔结构,根据user的特点与item的特点计算余弦相似度,进行个性化召回。
结构如上图所示,这是论文中的图,最左侧的输入为user特征,右侧所有的输入均为item特征,二者均经过了全连接与激活函数进行了非线性映射到共同维度,在获得高层次语义信息后,利用二者的语义信息计算余弦相似度,选择较高相似度的作为召回结果。
DSSM模型的思路非常简单,获得user和item的特征后,获得二者的相似度,然后进行推荐。但普通的DSSM存在一些小问题,面对现在市面上大多数的业务场景,很多业务的备选item都是上百万甚至上亿的,比如购物,选中的衣服只有十来款,没有选中的衣服有数十万款,双塔召回模型需要在items中针对每个正样本采样一千甚至一万的负样本才能达到比较好的召回效果,此时正负样本的比例巨大。
二、网络结构解析
1、Embedding层的构建
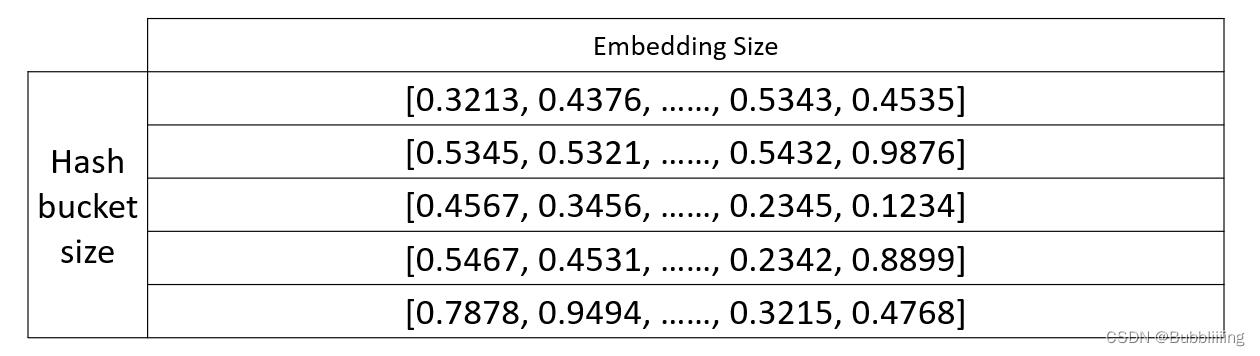
对于推荐系统而言,输入常常是字符串形式,因为不是矩阵,字符串本身无法被网络直接处理,EasyRec是基于tensorflow构建的,在tensorflow中,可以使用tf.string_to_hash_bucket_fast将输入进来的字符串转化成一个固定的数字。具体转换方式如下所示:
import tensorflow as tf
if tf.__version__ >= '2.0':
tf = tf.compat.v1
sparse_id_values = tf.string_to_hash_bucket_fast("hello", 10)
# 此时的输出为:
sparse_id_values = 6
对任意一个字符串,我们都可以将其转化成固定的数字,这个数字处于0到hash_bucket_size之间,之后之后在代码中会建立一个可查询的embedding表,他的shape为:
(hash_bucket_size, embedding_dim)
这是一个hash_bucket_size行,embedding_dim列的矩阵,当我们通过一个字符串获得一个固定的数字后,我们会通过这个固定的数字sparse_id_values,获得其中第sparse_id_values行。
比如上述的例子中,我们假设hash_bucket_size等于10,embedding_dim等于32。如果输入的字符串为hello,我们获得的sparse_id_values=6。我们此时就会获取embedding表的第6行,作为这个数据的embedding。
在EasyRec的Config中,我们只需要在feature_config指定对应的标签名、embedding_dim、hash_bucket_size就读取数据,将数据转化成特定长度的Embedding了。
如下所示:
#------------------------------------------------------#
# 用于作为特征的数据,不包括label
#------------------------------------------------------#
feature_config:
features:
input_names: "hour"
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 50
2、网络层的构建
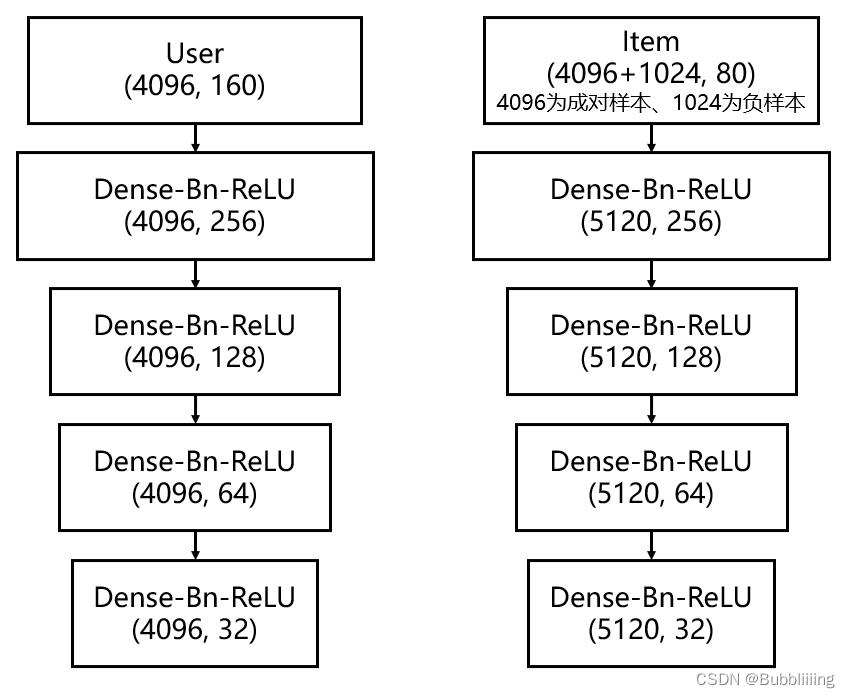
在完成Embedding层的构建后,我们会将获取到的所有特征的Embedding结果通过concat堆叠到一起。因此,无论是user还是item最终都会变成一个指定长度的向量。
在本博文中,我们称它们为embedding后的特征,它们的shape为[batch_size, embedding_size]。作为一个二维矩阵,第一维度为batch_size即批次大小,第二维度为embedding_size即该个体的特征长度。
在DSSM中,无论是user还是item,它们的网络层构建并不复杂,只是普通的DNN(全连接神经网络)。本博文使用EasyRec自带的电商演示数据集为例子进行解析,每个个体存在若干的特征,每个特征embedding后的长度为16,user存在10个特征,item存在5个特征。由于我们在DSSM召回模型中添加负采样,所以user和item的batch_size个数不同,此处我们假设基础的batch_size为4096,负采样的个数为1024。
user在embedding后的特征堆叠为[4096, 160];
item在embedding后的特征堆叠为[5120, 80]。
即存在4096个基础user,每个user需要和4096个基础item和1024个负采样的item进行匹配。
对于user而言,输入特征在embedding后的shape为[4096, 160]。在经过四次Dense-Bn-ReLU的特征映射后,网络最终输出为[4096, 32]。
对于item而言,输入的embedding的batch_size为4096(与user配对)+ 1024(额外的负采样),假设embedding的特征后的特征长度为80。在经过四次Dense-Bn-ReLU的特征映射后,网络最终输出为[5120, 32]。
在EasyRec的Config中,我们只需要在model_config部分指定对应的模型名称、每个模型所需的特征以及每个模型的构建方式,就可以对user和item各自进行构建了。如下所示,model_class表示的是模型类别,feature_groups表示的是每个模型所需的特征,dssm是模型下的模型参数。
model_config:
model_class: "DSSM"
feature_groups:
group_name: 'user'
feature_names: 'user_id'
feature_names: 'cms_segid'
feature_names: 'cms_group_id'
feature_names: 'age_level'
feature_names: 'pvalue_level'
feature_names: 'shopping_level'
feature_names: 'occupation'
feature_names: 'new_user_class_level'
feature_names: 'tag_category_list'
feature_names: 'tag_brand_list'
wide_deep:DEEP
feature_groups:
group_name: "item"
feature_names: 'adgroup_id'
feature_names: 'cate_id'
feature_names: 'campaign_id'
feature_names: 'customer'
feature_names: 'brand'
feature_names: 'price'
feature_names: 'pid'
wide_deep:DEEP
dssm
user_tower
id: "user_id"
dnn
hidden_units: [256, 128, 64, 32]
# dropout_ratio : [0.1, 0.1, 0.1, 0.1]
item_tower
id: "adgroup_id"
dnn
hidden_units: [256, 128, 64, 32]
l2_regularization: 1e-6
embedding_regularization: 5e-5
在EasyRec的源码中,DNN部分的构建代码为,在代码中,只是对hidden_units进行循环,循环时构建Dense、BN、Relu层:
# -*- encoding:utf-8 -*-
# Copyright (c) Alibaba, Inc. and its affiliates.
import logging
import tensorflow as tf
from easy_rec.python.utils.load_class import load_by_path
if tf.__version__ >= '2.0':
tf = tf.compat.v1
class DNN:
def __init__(self, dnn_config, l2_reg, name='dnn', is_training=False):
"""Initializes a `DNN` Layer.
Args:
dnn_config: instance of easy_rec.python.protos.dnn_pb2.DNN
l2_reg: l2 regularizer
name: scope of the DNN, so that the parameters could be separated from other dnns
is_training: train phase or not, impact batchnorm and dropout
"""
self._config = dnn_config
self._l2_reg = l2_reg
self._name = name
self._is_training = is_training
logging.info('dnn activation function = %s' % self._config.activation)
self.activation = load_by_path(self._config.activation)
@property
def hidden_units(self):
return self._config.hidden_units
@property
def dropout_ratio(self):
return self._config.dropout_ratio
def __call__(self, deep_fea, hidden_layer_feature_output=False):
hidden_units_len = len(self.hidden_units)
if hidden_units_len == 1 and self.hidden_units[0] == 0:
return deep_fea
hidden_feature_dict =
for i, unit in enumerate(self.hidden_units):
deep_fea = tf.layers.dense(
inputs=deep_fea,
units=unit,
kernel_regularizer=self._l2_reg,
activation=None,
name='%s/dnn_%d' % (self._name, i))
if self._config.use_bn:
deep_fea = tf.layers.batch_normalization(
deep_fea,
training=self._is_training,
trainable=True,
name='%s/dnn_%d/bn' % (self._name, i))
deep_fea = self.activation(
deep_fea, name='%s/dnn_%d/act' % (self._name, i))
if len(self.dropout_ratio) > 0 and self._is_training:
assert self.dropout_ratio[
i] < 1, 'invalid dropout_ratio: %.3f' % self.dropout_ratio[i]
deep_fea = tf.nn.dropout(
deep_fea,
keep_prob=1 - self.dropout_ratio[i],
name='%s/%d/dropout' % (self._name, i))
if hidden_layer_feature_output:
hidden_feature_dict['hidden_layer' + str(i)] = deep_fea
if (i + 1 == hidden_units_len):
hidden_feature_dict['hidden_layer_end'] = deep_fea
return hidden_feature_dict
else:
return deep_fea
因此无论是user还是item,每个个体最终都会变成一个指定长度的向量,长度在本博文中为32。在本博文中,我们将映射后的结果称为user和item的语义向量。
在l2标准化后,就可以计算user和item各自的余弦相似度了。
if self._loss_type == LossType.CLASSIFICATION:
if self._model_config.simi_func == Similarity.COSINE:
user_tower_emb = self.norm(user_tower_emb)
item_tower_emb = self.norm(item_tower_emb)
3、相似度计算
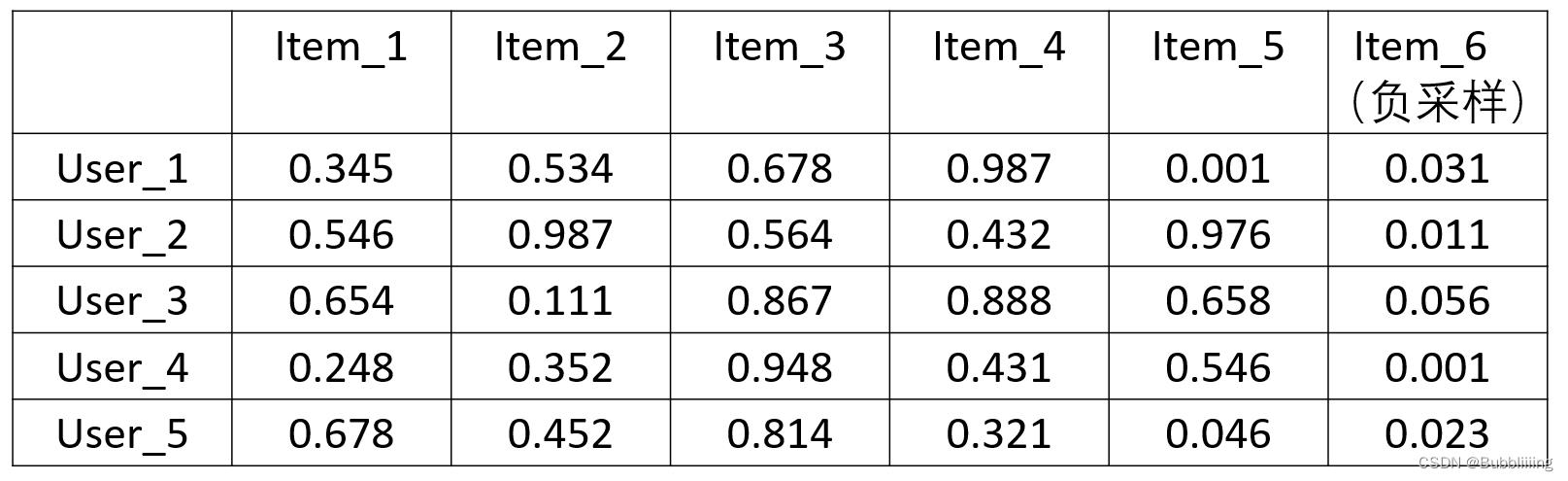
在网络层的构建中,我们获得了user和item的语义向量,它们的shape分别为[4096, 32]和[5120, 32]。我们此时需要计算语义向量之间的相似度。此时我们求取list_wise_sim。
首先对item的语义向量进行转置,此时可以获得一个[32, 5120]的矩阵。然后利用user的语义向量叉乘item转置后的语义向量,即 [ 4096 , 32 ] × [ 32 , 5120 ] [4096, 32]\\times[32, 5120] [4096,32]×[32,5120],完成后可以获得一个[4096, 5120]的矩阵,代表了4096个user和5120个item(包括负样本)的相似度。
具体运算代码为:
simple_user_item_sim = tf.matmul(user_emb, tf.transpose(simple_item_emb))
在EasyRec中,还会对获取到的相似度进行下一轮缩放,其中sim_w和sim_b是可以训练的参数。
y_pred = user_item_sim * tf.abs(sim_w) + sim_b
self._prediction_dict['probs'] = tf.nn.softmax(y_pred)
最终在对y_pred取softmax后,将其再次映射到0-1之间。
此时,如果softmax越接近于1,代表该user和该item相似性很高,应当进行推荐;如果softmax越接近于0,代表该user和该item相似性很低,不应当进行推荐。
三、训练部分解析
网络的训练部分并不复杂,在网络计算好余弦相似度后,我们对最终取softmax的结果通过事先设定好的标签进行交叉熵的计算。
在输入进来数据时,假设batch_size为4096,4096对user和item是匹配的。在上述获得的[4096, 5120]矩阵中,对角线部分的user和item是配对的。

因此我们可以创建一个在对角线上为1的矩阵作为标签。然后利用多分类交叉熵求取损失。
在代码中的实现方式为:
batch_size = tf.shape(self._prediction_dict['probs'])[0]
indices = tf.range(batch_size)
indices = tf.concat([indices[:, None], indices[:, None]], axis=1)
hit_prob = tf.gather_nd(self._prediction_dict['probs'][:batch_size, :batch_size], indices)
self._loss_dict['cross_entropy_loss'] = -tf.reduce_mean(tf.log(hit_prob + 1e-12)) * self._sample_weight
训练自己的DSSM模型
在训练自己的DSSM模型之前,需要首先配置好EasyRec环境。
本博文以EasyRec自带的电商示例数据集进行解析。数据集位于EasyRec根目录下,分别位于下面两个位置。
“data/test/tb_data/taobao_train_data”
“data/test/tb_data/taobao_test_data”
电商示例数据集包含若干特征,保存在文本文件中,尽管后缀不是csv,但实际上是csv格式,具体如下所示:
clk:点击记录
buy:是否购买
以下为商品特征:
pid:商品pid码
adgroup_id:商品广告单元id
cate_id:商品种类id
campaign_id:商品公司id
customer:商品顾客
brand:商品品牌
price:商品价格
以下为用户特征:
user_id:用户id
cms_segid:微群ID
cms_group_id:一个特征
final gender code:性别
age level:年龄层次
pvalue level:消费档次
shopping level:购物深度
occupation:是否工作
new_user_class_level:城市等级
tag_category_list:点击的种类列表
tag_brand_list:点击的品牌列表
一、数据集的准备
本文使用文本格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过示例的电商数据集进行尝试。
准备好的数据集一般存放在data/test文件夹中。在示例数据集里:
data/test/tb_data/taobao_train_data代表的是训练集,模型基于该文件进行梯度下降。
data/test/tb_data/taobao_test_data代表的是验证集(测试集),这里不单独划分一个测试集,验证集和测试集共用。
csv中直接存放特征的值即可,特征之间以’,'隔开,不需要存放特征名,如图所示,每一列的数据代表什么特征我们自己需要清楚。
二、Config配置文件的设置
Config配置文件中需要设置多方面的内容,采用prototxt格式,配置顺序为:
数据集的地址、模型保存的地址、训练相关参数设置、评估情况、数据集内容情况、数据集特征情况、模型情况。
具体的构建方式如下:
#------------------------------------------------------#
# 训练用的数据文件地址
#------------------------------------------------------#
train_input_path: "data/test/tb_data/taobao_train_data"
#------------------------------------------------------#
# 评估用的数据文件地址
#------------------------------------------------------#
eval_input_path: "data/test/tb_data/taobao_test_data"
#------------------------------------------------------#
# 训练好的权值保存的路径
#------------------------------------------------------#
model_dir: "experiments/dssm_neg_sampler_taobao_ckpt"
#------------------------------------------------------#
# 训练相关的参数
#------------------------------------------------------#
train_config
log_step_count_steps: 100
#------------------------------------------------------#
# optimizer_config 优化器参数
#------------------------------------------------------#
optimizer_config:
#------------------------------------------------------#
# adam_optimizer Adam优化器
# learning_rate 学习率下降方式
# exponential_decay_learning_rate 指数下降
# initial_learning_rate 初始学习率
# decay_steps 学习率衰减步长
# decay_factor 衰减倍数
# min_learning_rate 最低学习率
#------------------------------------------------------#
adam_optimizer:
learning_rate:
exponential_decay_learning_rate
initial_learning_rate : 0.001
decay_steps : 1000
decay_factor : 0.5
min_learning_rate : 0.00001
use_moving_average: false
#------------------------------------------------------#
# sync_replicas
# save_checkpoints_steps 保存周期
# log_step_count_steps log记录周期
# num_steps 总训练步长
#------------------------------------------------------#
sync_replicas : true
save_checkpoints_steps : 100
log_step_count_steps : 100
num_steps : 2500
#------------------------------------------------------#
# 评估参数
# 推荐系统一般使用AUC进行评估
#------------------------------------------------------#
eval_config
metrics_set:
auc
#------------------------------------------------------#
# 数据集的各类数据情况
#------------------------------------------------------#
data_config
#------------------------------------------------------#
# separator 代表分隔符,默认为","
#------------------------------------------------------#
separator: ","
#------------------------------------------------------#
# 需要注意的时,此处的数据顺序需要和csv中一样。
# input_name 代表该列数据的名称
# input_type 代表该列数据的数据类别,默认是STRING。
# default_val 代表默认值,可以不设置
#------------------------------------------------------#
input_fields
input_name:'clk'
input_type: INT32
input_fields
input_name:'buy'
input_type: INT32
input_fields
input_name: 'pid'
input_type: STRING
input_fields
input_name: 'adgroup_id'
input_type: STRING
input_fields
input_name: 'cate_id'
input_type: STRING
input_fields
input_name: 'campaign_id'
input_type: STRING
input_fields
input_name: 'customer'
input_type: STRING
input_fields
input_name: 'brand'
input_type: STRING
input_fields
input_name: 'user_id'
input_type: STRING
input_fields
input_name: 'cms_segid'
input_type: STRING
input_fields
input_name: 'cms_group_id'
input_type: STRING
input_fields
input_name: 'final_gender_code'
input_type: STRING
input_fields
input_name: 'age_level'
input_type: STRING
input_fields
input_name: 'pvalue_level'
input_type: STRING
input_fields
input_name: 'shopping_level'
input_type: STRING
input_fields
input_name: 'occupation'
input_type: STRING
input_fields
input_name: 'new_user_class_level'
input_type: STRING
input_fields
input_name: 'tag_category_list'
input_type: STRING
input_fields
input_name: 'tag_brand_list'
input_type: STRING
input_fields
input_name: 'price'
input_type: INT32
#------------------------------------------------------#
# 列名必须在data_config中出现过,代表为标签
#------------------------------------------------------#
label_fields: 'clk'
#------------------------------------------------------#
# batch_size 批次大小
# prefetch_size 提高数据加载的速度,防止数据瓶颈
# num_epochs 训练时取num_steps和num_epochs中的小值
# 看哪个先达到就结束
#------------------------------------------------------#
batch_size: 4096
num_epochs: 10000
prefetch_size: 32
#---------------------------------------------------------------------------#
# CSVInput 表示数据格式是CSV,注意要配合separator使用
# OdpsInputV2 如果在MaxCompute上运行EasyRec, 则使用OdpsInputV2
# OdpsInputV3 如果在本地或者EMR上访问MaxCompute Table, 则使用OdpsInputV3
#---------------------------------------------------------------------------#
input_type: CSVInput
#---------------------------------------------------------------------------#
# 负采样的数据集地址
#---------------------------------------------------------------------------#
negative_sampler
input_path: 'data/test/tb_data/taobao_ad_feature_gl'
num_sample: 1024
num_eval_sample: 2048
attr_fields: 'adgroup_id'
attr_fields: 'cate_id'
attr_fields: 'campaign_id'
attr_fields: 'customer'
attr_fields: 'brand'
item_id_field: 'adgroup_id'
#------------------------------------------------------#
# 用于作为特征的数据,不包括label
#------------------------------------------------------#
feature_config:
#---------------------------------------------------------------------------#
# 具体设置可参考https://easyrec.readthedocs.io/en/latest/feature/feature.html
# input_names 代表该列数据的名称
# feature_type 特征类别
# embedding_dim 该列数据在经过Embedding处理后的特征长度
# hash_bucket_size 将变量hash之后去模
#---------------------------------------------------------------------------#
features:
input_names: 'pid'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'adgroup_id'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100000
features:
input_names: 'cate_id'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10000
features:
input_names: 'campaign_id'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100000
features:
input_names: 'customer'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100000
features:
input_names: 'brand'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100000
features:
input_names: 'user_id'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100000
features:
input_names: 'cms_segid'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100
features:
input_names: 'cms_group_id'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 100
features:
input_names: 'final_gender_code'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'age_level'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'pvalue_level'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'shopping_level'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'occupation'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'new_user_class_level'
feature_type: IdFeature
embedding_dim: 16
hash_bucket_size: 10
features:
input_names: 'tag_category_list'
feature_type: TagFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 16
features:
input_names: 'tag_brand_list'
feature_type: TagFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 16
features:
input_names: 'price'
feature_type: IdFeature
embedding_dim: 16
num_buckets: 50
#------------------------------------------------------#
# 模型参数设置
#------------------------------------------------------#
model_config:
#------------------------------------------------------#
# 模型种类
#------------------------------------------------------#
model_class: "DSSM"
#------------------------------------------------------#
# group_name 指定组名
# feature_names 该组的特征
# wide_deep 模型的记忆能力和泛化能力
#------------------------------------------------------#
feature_groups:
group_name: 'user'
feature_names