使用Jsoup和htmlunit爬取动态网页
Posted silentteller
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Jsoup和htmlunit爬取动态网页相关的知识,希望对你有一定的参考价值。
在对http://zkgg.tjtalents.com.cn/newzxxx.jsp这个网页爬取内容时,如果只使用Jsoup进行解析的话,起内部的a href标签内容无法获取到。


但是实际上通过
Document doc = Jsoup.connect(url).get();
获取到的文档只是newzxxx.jsp中respose的内容。

实际我们想要的内容通过js加载得到的。
function query(){ $("formzx").fid.value = "C09.01.01.05"; $("formzx").set(\'send\',{ url: \'MainServlet.action\', onRequest: function(){ }, //成功的回调函数 onSuccess: function(responseText){ $(\'listspan\').innerhtml = responseText; }, //失败的回调函数. 404. 500. 以及返回JSON串success为false时执行 onFailure: function(responseText){ $(\'listspan\').innerHTML = responseText; } }); $("formzx").send(); }
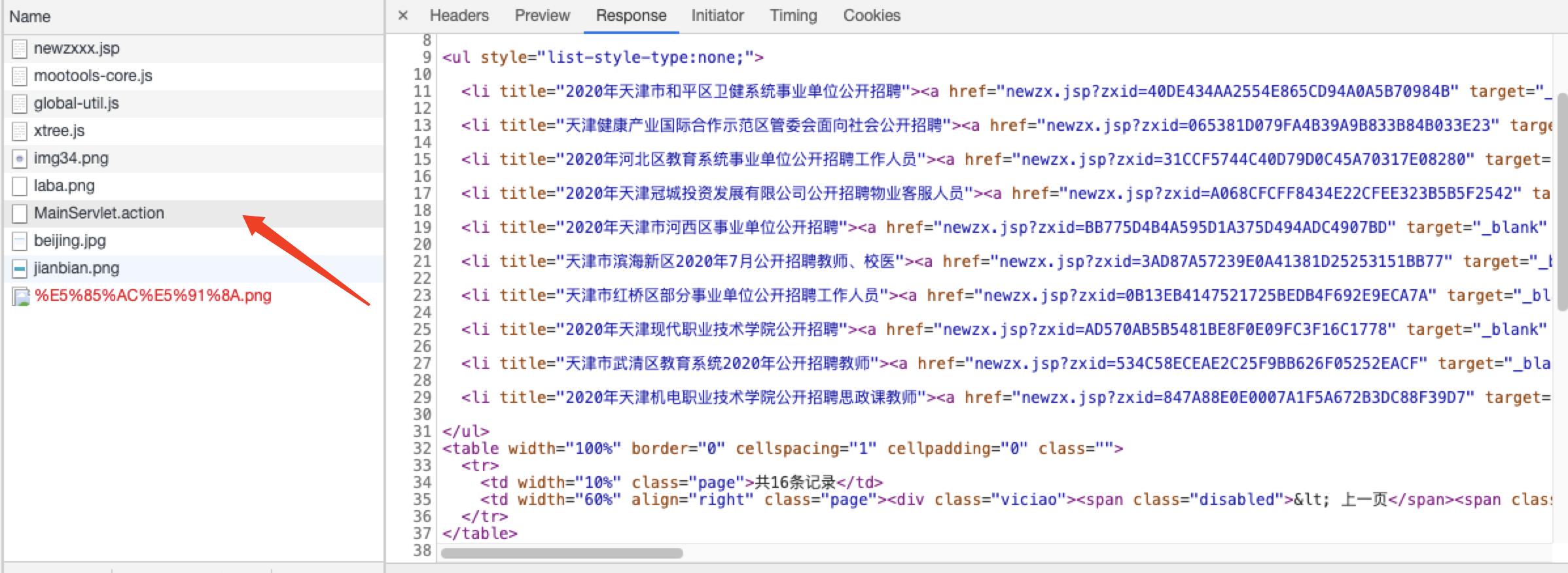
所以这种情况我们可以使用htmlunit来模拟浏览器,并且等待js加载完毕后,再读取整个页面。
public String getPageWaitJS (String url) throws IOException { WebClient webClient = new WebClient(); webClient.getOptions().setjavascriptEnabled(true); //启用JS解释器,默认为true webClient.getOptions().setCssEnabled(false); //禁用css支持 webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常 HtmlPage page = webClient.getPage(url); webClient.waitForBackgroundJavaScript(3*1000); String pageXml = page.asXml(); //以xml的形式获取响应文本 return pageXml; }
这样的话就能够获取全部的html页面,之后再使用Jsoup来对页面进行解析即可,这里就不放上Jsoup的代码了。
以上是关于使用Jsoup和htmlunit爬取动态网页的主要内容,如果未能解决你的问题,请参考以下文章
爬虫任务二:爬取(用到htmlunit和jsoup)通过百度搜索引擎关键字搜取到的新闻标题和url,并保存在本地文件中(主体借鉴了网上的资料)