ElasticSearch:ELK 架构 Posted 2023-04-05 Men-DD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch:ELK 架构相关的知识,希望对你有一定的参考价值。
日志收集——》格式化分析——》检索和可视化——》风险告警
ELK架构
什么是Logstash
Logstash核心概念 Logstash数据传输原理 Logstash配置文件结构 Logstash Queue Logstash导入数据到ES 同步数据库数据到Elasticsearch 什么是Beats
FileBeat简介 FileBeat的工作原理 logstash vs FileBeat Filebeat安装 ELK整合实战
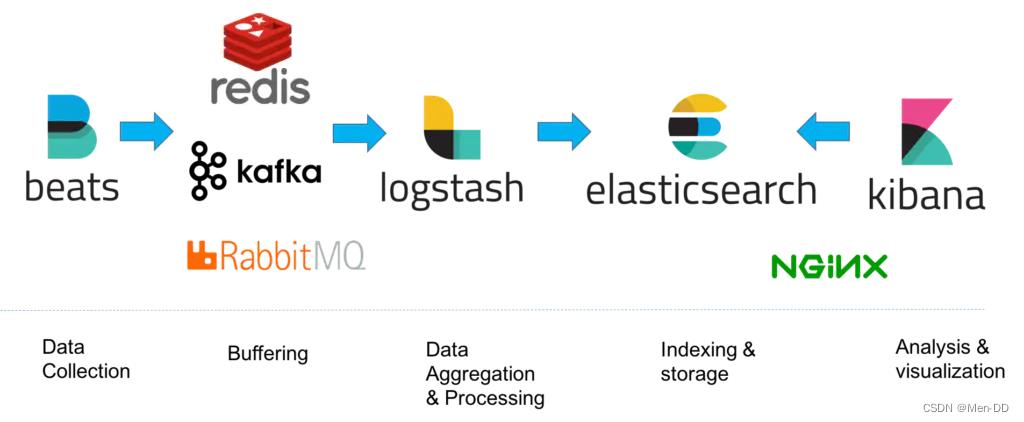
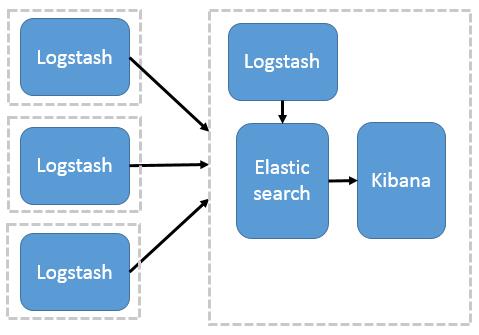
案例:采集tomcat服务器日志 使用FileBeats将日志发送到Logstash 配置Logstash接收FileBeat收集的数据并打印 Logstash输出数据到Elasticsearch 利用Logstash过滤器解析日志 输出到Elasticsearch指定索引 ELK架构分为两种,一种是经典的ELK,另外一种是加上消息队列(Redis或Kafka或RabbitMQ)和Nginx结构。
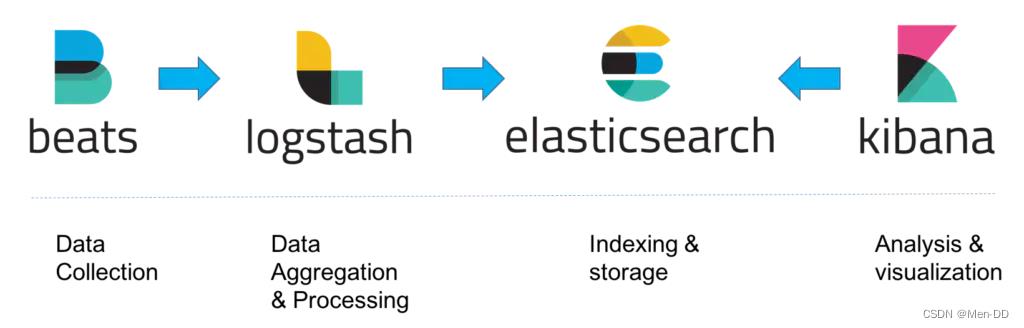
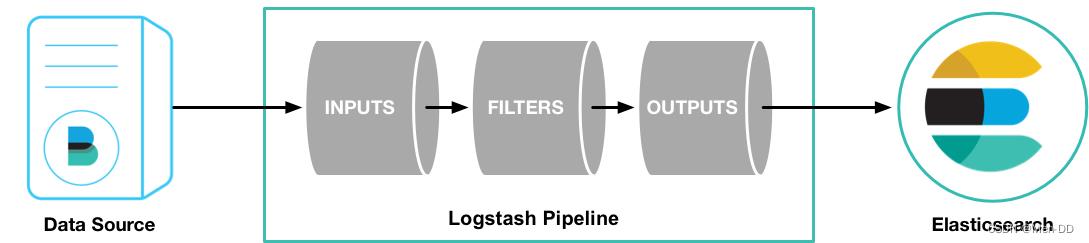
数据量小的开发环境,存在数据丢失的危险经典的ELK主要是由Filebeat + Logstash + Elasticsearch + Kibana组成,如下图:(早期的ELK只有Logstash + Elasticsearch + Kibana)
生产环境,可以处理大数据量,并且不会丢失数据这种架构,主要加上了Redis或Kafka或RabbitMQ做消息队列,保证了消息的不丢失
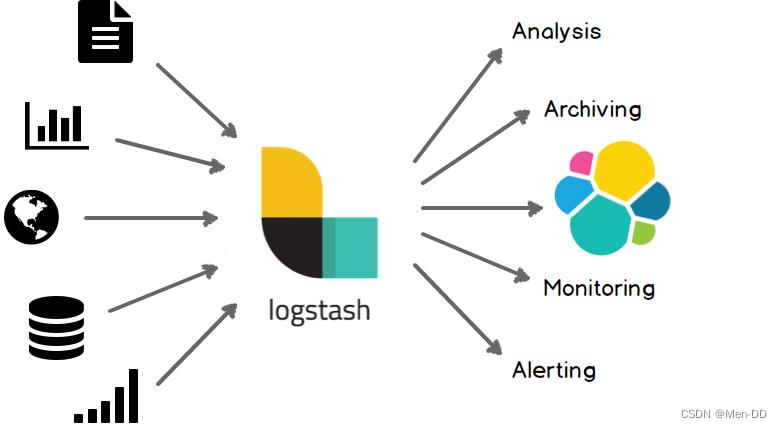
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中。
https://www.elastic.co/cn/logstash/
应用:ETL工具 / 数据采集处理引擎
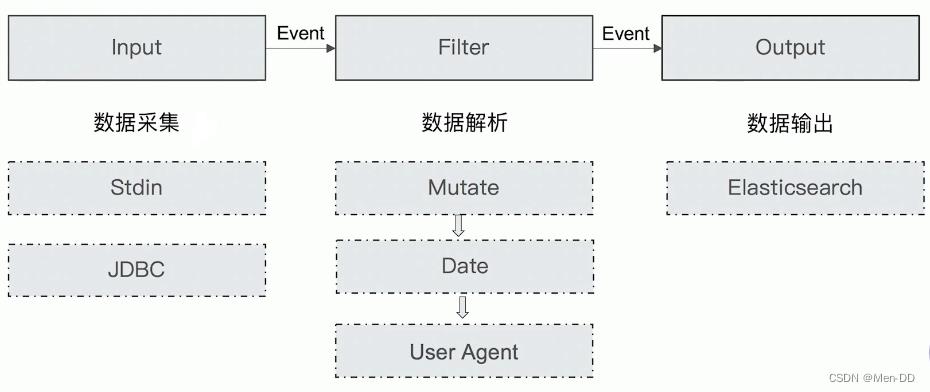
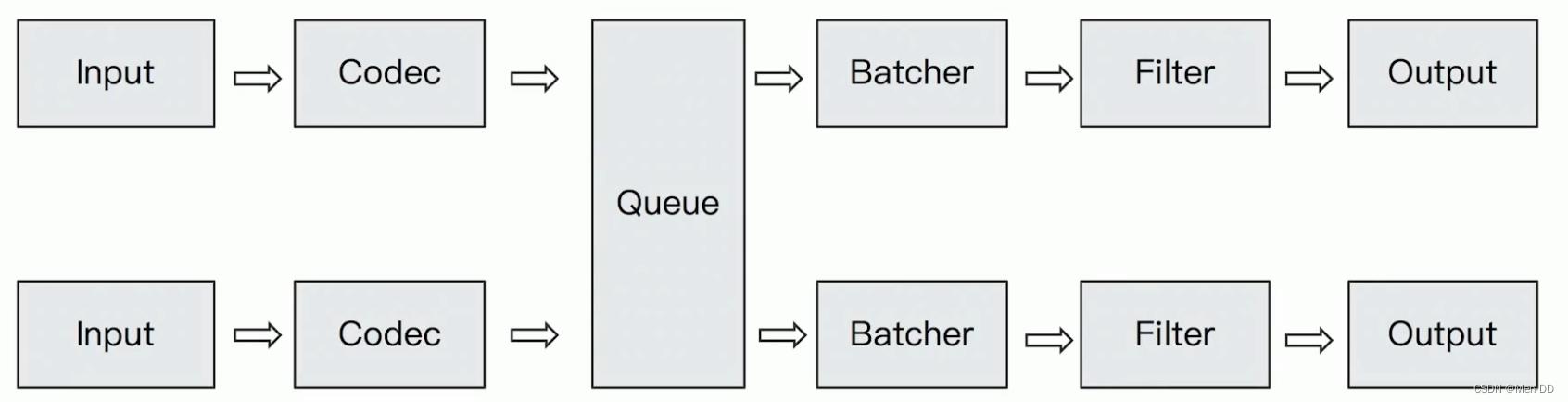
包含了input—filter-output三个阶段的处理流程
数据在内部流转时的具体表现形式。数据在input 阶段被转换为Event,在 output被转化成目标格式数据
将原始数据decode成Event; 将Event encode成目标数据
数据采集与输入:Logstash支持各种输入选择,能够以连续的流式传输方式,轻松地从日志、指标、Web应用以及数据存储中采集数据。 实时解析和数据转换:通过Logstash过滤器解析各个事件,识别已命名的字段来构建结构,并将它们转换成通用格式,最终将数据从源端传输到存储库中。 存储与数据导出:Logstash提供多种输出选择,可以将数据发送到指定的地方。 Logstash通过管道完成数据的采集与处理,管道配置中包含input、output和filter(可选)插件,input和output用来配置输入和输出数据源、filter用来对数据进行过滤或预处理。
参考:https://www.elastic.co/guide/en/logstash/7.17/configuration.html
Logstash的管道配置文件对每种类型的插件都提供了一个单独的配置部分,用于处理管道事件
input = > "message" = > "%COMBINEDAPACHELOG" date = > [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
= > [ "localhost:9200" ] = > rubydebug bin/logstash -f logstash-demo.conf
https://www.elastic.co/guide/en/logstash/7.17/input-plugins.html
https://www.elastic.co/guide/en/logstash/7.17/output-plugins.html
Elasticsearch Email / Pageduty Influxdb / Kafka / Mongodb / Opentsdb / Zabbix Http / TCP / Websocket https://www.elastic.co/guide/en/logstash/7.17/filter-plugins.html
Mutate 一操作Event的字段 Metrics — Aggregate metrics Ruby 一执行Ruby 代码 https://www.elastic.co/guide/en/logstash/7.17/codec-plugins.html
Line / Multiline JSON / Avro / Cef (ArcSight Common Event Format) Dots / Rubydebug In Memory Queue Persistent Queue queue.type : persisted
queue.max_bytes : 4gb
logstash官方文档: https://www.elastic.co/guide/en/logstash/7.17/installing-logstash.html
下载地址: https://www.elastic.co/cn/downloads/past-releases#logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.5-linux-x86_64.tar.gz
tar -zxvf logstash-7.17.5-linux-x86_64.tar.gz
cd logstash-7.17.5
bin/logstash -e 'input stdin output stdout '
bin/logstash -e "inputstdincodec=>lineoutputstdoutcodec=> rubydebug"
bin/logstash -e "inputstdincodec=>jsonoutputstdoutcodec=> rubydebug"
设置参数:
pattern: 设置行匹配的正则表达式 what : 如果匹配成功,那么匹配行属于上一个事件还是下一个事件 negate : 是否对pattern结果取反
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle( Book.java:16)
at com.example.myproject.Author.getBookTitles( Author.java:25)
at com.example.myproject.Bootstrap.main( Bootstrap.java:14)
input = > multiline = > "^\\s"
what = > "previous"
= > rubydebug -f multiline-exception.conf
https://www.elastic.co/guide/en/logstash/7.17/plugins-inputs-file.html
支持从文件中读取数据,如日志文件 文件读取需要解决的问题:只被读取一次。重启后需要从上次读取的位置继续(通过sincedb 实现) 读取到文件新内容,发现新文件 文件发生归档操作(文档位置发生变化,日志rotation),不能影响当前的内容读取 Filter Plugin可以对Logstash Event进行各种处理,例如解析,删除字段,类型转换
Date: 日期解析 Dissect: 分割符解析 Grok: 正则匹配解析 Mutate: 处理字段。重命名,删除,替换 Ruby: 利用Ruby 代码来动态修改Event 对字段做各种操作:
Convert : 类型转换 Gsub : 字符串替换 Split / Join /Merge: 字符串切割,数组合并字符串,数组合并数组 Rename: 字段重命名 Update / Replace: 字段内容更新替换 Remove_field: 字段删除 input file = > "/home/es/logstash-7.17.3/dataset/movies.csv"
start_position = > "beginning"
sincedb_path = > "/dev/null"
= > ","
columns = > [ "id" ,"content" ,"genre" ]
split = > "genre" = > "|" = > [ "path" , "host" ,"@timestamp" ,"message" ]
split = > [ "content" , "(" ]
add_field = > "title" = > "%[content][0]" = > "year" = > "%[content][1]" = > "year" = > "integer"
= > [ "title" ]
remove_field = > [ "path" , "host" ,"@timestamp" ,"message" ,"content" ]
= > "http://localhost:9200"
index = > "movies"
document_id = > "%id"
user = > "elastic"
password = > "123456"
3)运行logstashbin/logstash -f logstash-movie.conf
get / movies/ _search
"took" : 0 ,
"timed_out" : false ,
"_shards" : "total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
,
"hits" : "total" : "value" : 10000 ,
"relation" : "gte"
,
"max_score" : 1.0 ,
"hits" : [
"_index" : "movies" ,
"_type" : "_doc" ,
"_id" : "6747" ,
"_score" : 1.0 ,
"_source" : "id" : "6747" ,
"year" : 1960 ,
"title" : "Adventures of Huckleberry Finn, The" ,
"genre" : [
"Adventure" ,
"Children"
] ,
"@version" : "1"
,
"_index" : "movies" ,
"_type" : "_doc" ,
"_id" : "6748" ,
"_score" : 1.0 ,
"_source" : "id" : "6748" ,
"year" : 1979 ,
"title" : "Brood, The" ,
"genre" : [
"Horror"
] ,
"@version" : "1"
,
"_index" : "movies" ,
"_type" : "_doc" ,
"_id" : "6749" ,
"_score" : 1.0 ,
"_source" : "id" : "6749" ,
"year" : 1937 ,
"title" : "Prince and the Pauper, The" ,
"genre" : [
"Adventure" ,
"Drama"
] ,
"@version" : "1"
,
... .
]
docker pull logstash:7.17.5
docker run -d --name = logstash logstash:7.17.5
mkdir -p /data/logstash
docker cp logstash:/usr/share/logstash/config /data/logstash/
docker cp logstash:/usr/share/logstash/data /data/logstash/
docker cp logstash:/usr/share/logstash/pipeline /data/logstash/
chmod 777 -R /data/logstash
vi /mydata/logstash/config/logstash.yml
http.host : "0.0.0.0"
config.reload.automatic : true
vi /data/logstash/config/springboot.conf
input => "0.0.0.0" => "server" => 5055
codec => json_lines
=> "es.localhost.com:9200" => "elastic" => "xxxxxx" => "mendd-%+YYYY.MM.dd" => rubydebug vi /mydata/logstash/config/pipelines.yml
- pipeline.id : main
path.config : "/usr/share/logstash/pipeline"
- pipeline.id : mendd
path.config : "/usr/share/logstash/config/springboot.conf"
需求: 将数据库中的数据同步到ES,借助ES的全文搜索,提高搜索速度
需要把新增用户信息同步到Elasticsearch中 用户信息Update 后,需要能被更新到Elasticsearch 支持增量更新 用户注销后,不能被ES所搜索到 基于canal同步数据(项目实战中讲解) 借助JDBC Input Plugin将数据从数据库读到Logstash
需要自己提供所需的 JDBC Driver; JDBC Input Plugin 支持定时任务 Scheduling,其语法来自 Rufus-scheduler,其扩展了 Cron,使用 Cron 的语法可以完成任务的触发; JDBC Input Plugin 支持通过 Tracking_column / sql_last_value 的方式记录 State,最终实现增量的更新; https://www.elastic.co/cn/blog/logstash-jdbc-input-plugin 1)拷贝jdbc依赖到logstash-7.17.3/drivers目录下/srv/soft/logstash-7.17.5/drivers/mysql 2)准备mysql-demo.conf配置文件 input = > "/srv/soft/logstash-7.17.5/drivers/mysql-connector-java-5.1.49.jar"
jdbc_driver_class = > "com.mysql.jdbc.Driver"
jdbc_connection_string = > "jdbc:mysql://localhost:3306/db-es-test?useSSL=false"
jdbc_user = > "xxxxxxxx"
jdbc_password = > "xxxxx"
use_column_value = > true
tracking_column = > "last_updated"
tracking_column_type = > "numeric"
record_last_run = > true
last_run_metadata_path = > "jdbc-position.txt"
statement = > "SELECT * FROM user where last_updated >:sql_last_value;"
schedule = > " * * * * * *"
= > "%id"
document_type = > "_doc"
index = > "users"
hosts = > [ "http://localhost:9200" ]
user = > "elastic"
password = > "123456"
= > rubydebug
3)运行logstash 测试、新增、更新、删除
CREATE TABLE ` user` (
` id` int NOT NULL AUTO_INCREMENT ,
` name` varchar ( 50 ) DEFAULT NULL ,
` address` varchar ( 50 ) CHARACTER DEFAULT NULL ,
` last_updated` bigint DEFAULT NULL ,
` is_deleted` int DEFAULT NULL ,
PRIMARY KEY ( ` id` )
) ENGINE = InnoDB AUTO_INCREMENT = 2 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci;
INSERT INTO user ( name, address, last_updated, is_deleted) VALUES ( "张三" , "广州天河" , unix_timestamp( NOW ( ) ) , 0 )
# 创建 alias,只显示没有被标记 deleted的用户
POST / _aliases
"actions" : [
"add" : "index" : "users" ,
"alias" : "view_users" ,
"filter" : "term" : "is_deleted" : 0 ]
POST view_users/ _search
POST view_users/ _search
"query" : "term" : "name.keyword" : "value" : "张三"
https://www.elastic.co/guide/en/beats/libbeat/7.17/index.html
Beats 是一个免费且开放的平台,集合了多种单一用途的数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
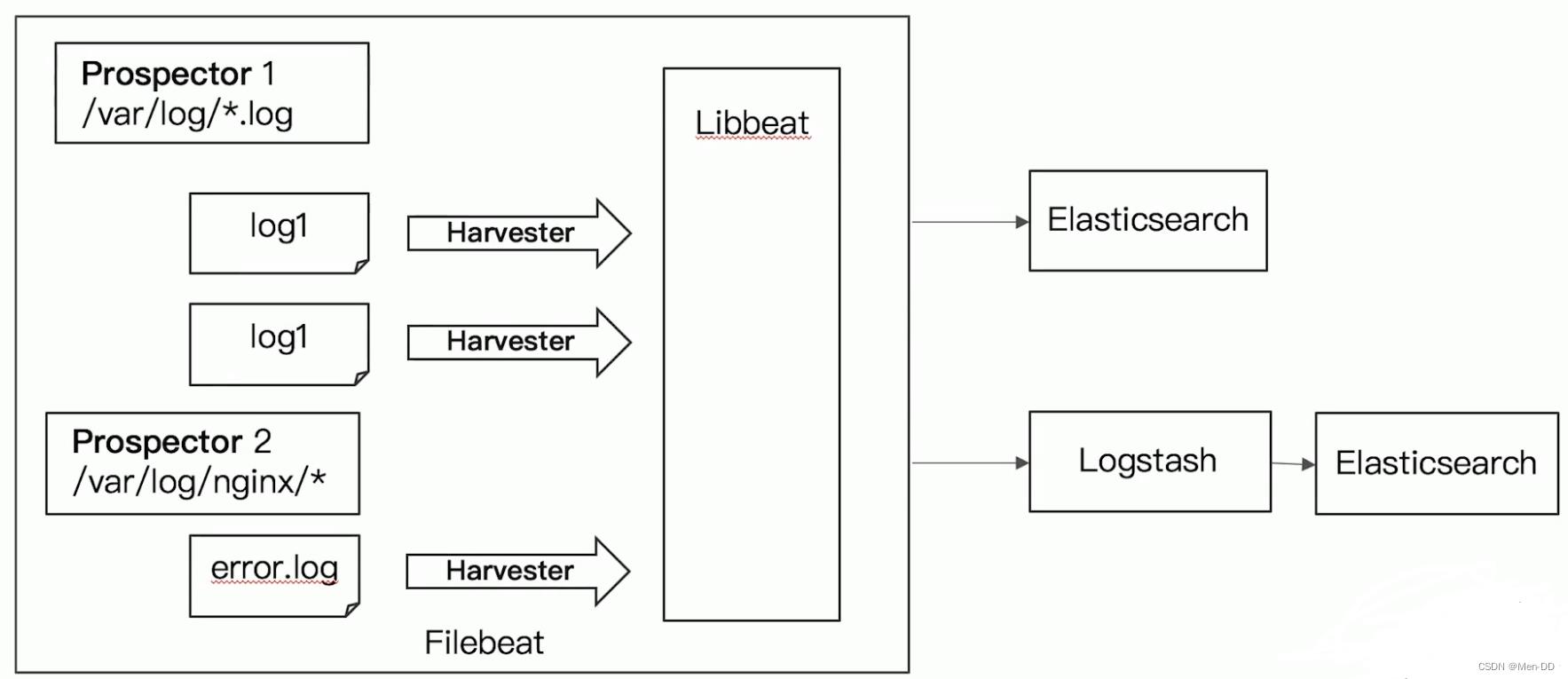
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收集到一起,并将数据发送给输出(Output)。
Logstash是在jvm上运行的,资源消耗比较大。而FileBeat是基于golang编写的,功能较少但资源消耗也比较小,更轻量级。 Logstash 和 Filebeat都具有日志收集功能,Filebeat更轻量,占用资源更少 Logstash 具有Filter功能,能过滤分析日志 一般结构都是Filebeat采集日志,然后发送到消息队列、Redis、MQ中,然后Logstash去获取,利用Filter功能过滤分析,然后存储到Elasticsearch中 FileBeat和Logstash配合,实现背压机制。当将数据发送到Logstash或 Elasticsearch时,Filebeat使用背压敏感协议,以应对更多的数据量。如果Logstash正在忙于处理数据,则会告诉Filebeat 减慢读取速度。一旦拥堵得到解决,Filebeat就会恢复到原来的步伐并继续传输数据。 https://www.elastic.co/guide/en/beats/filebeat/7.17/filebeat-installation-configuration.html
下载地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.5-linux-x86_64.tar.gz
修改 filebeat.yml 以设置连接信息:
output.elasticsearch :
hosts : [ "localhost:9200" ]
setup.kibana :
host : "xxxxx.xxxx.com:5601"
从安装目录中,运行:
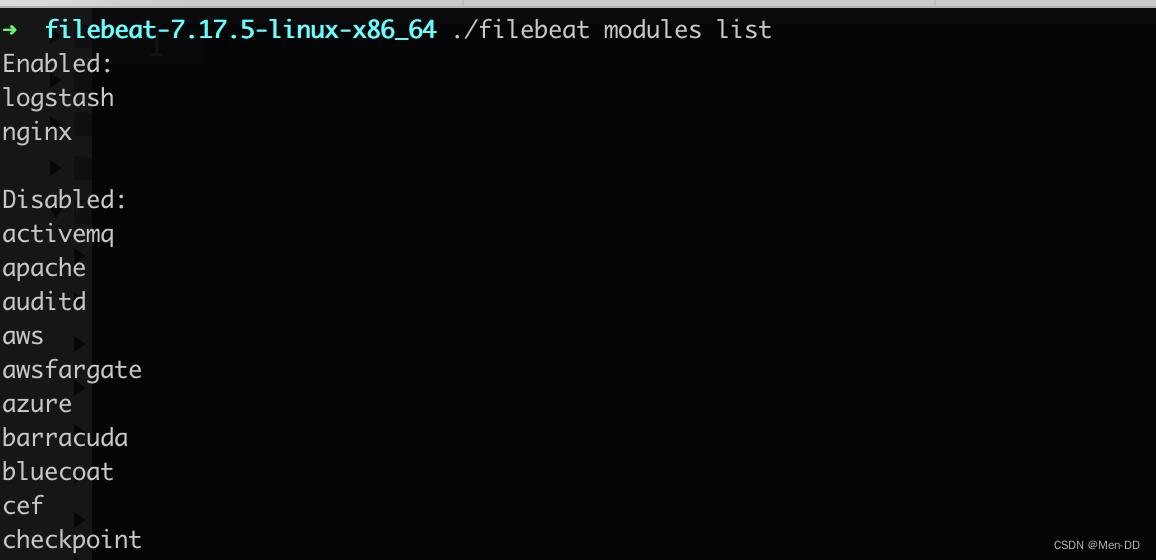
查看模块列表 ./filebeat modules list./filebeat modules enable nginx./filebeat modules enable logstash
如果需要更改nginx日志路径,修改modules.d/nginx.yml
- module : nginx
access :
var.paths : [ "/var/log/nginx/access.log*" ]
在 modules.d/logstash.yml 文件中修改设置
- module : logstash
log :
enabled : true
var.paths : [ "/srv/soft/logstash-7.17.5/logs/*.log" ]
setup命令加载Kibana仪表板。 如果仪表板已经设置,则忽略此命令./filebeat setup
启动Filebeat./filebeat -e
案例:采集tomcat服务器日志
Tomcat服务器运行过程中产生很多日志信息,通过Logstash采集并存储日志信息至ElasticSearch中
pattern:正则表达式 negate:true 或 false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行 match:after 或 before,合并到上一行的末尾或开头 vim filebeat-logstash.yml
filebeat.inputs :
- type : log
enabled : true
paths :
- /home/es/apache- tomcat- 8.5.33/logs/*access*.*
multiline.pattern : '^\\\\d+\\\\.\\\\d+\\\\.\\\\d+\\\\.\\\\d+ '
multiline.negate : true
multiline.match : after
output.logstash :
enabled : true
hosts : [ "x.x.x.x:5044" ]
./filebeat -e -c filebeat-logstash.yml
Exiting: error loading config file: config file ("filebeat-logstash.yml") can only be writable by the owner but the permissions are "-rw-rw-r--" (to fix the permissions use: 'chmod go-w /home/es/filebeat-7.17.3-linux-x86_64/filebeat-logstash.yml')chmod 644 filebeat-logstash.yml
Failed to connect to backoff(async(tcp://192.168.65.204:5044)): dial tcp 192.168.65.204:5044: connect: connection refused
vim config/filebeat-console.conf
input = > 5044
= > rubydebug
测试logstash配置是否正确bin/logstash -f config/filebeat-console.conf --config.test_and_exit
启动logstashbin/logstash -f config/filebeat-console.conf --config.reload.automatic
测试访问tomcat,logstash是否接收到了Filebeat传过来的tomcat日志
如果我们需要将数据输出值ES而不是控制台的话,我们修改Logstash的output配置。
vim config/filebeat-elasticSearch.conf
input = > 5044
= > [ "http://localhost:9200" ]
user = > "elastic"
password = > "123456"
= > rubydebug
bin/logstash -f config/filebeat-elasticSearch.conf --config.reload.automatic
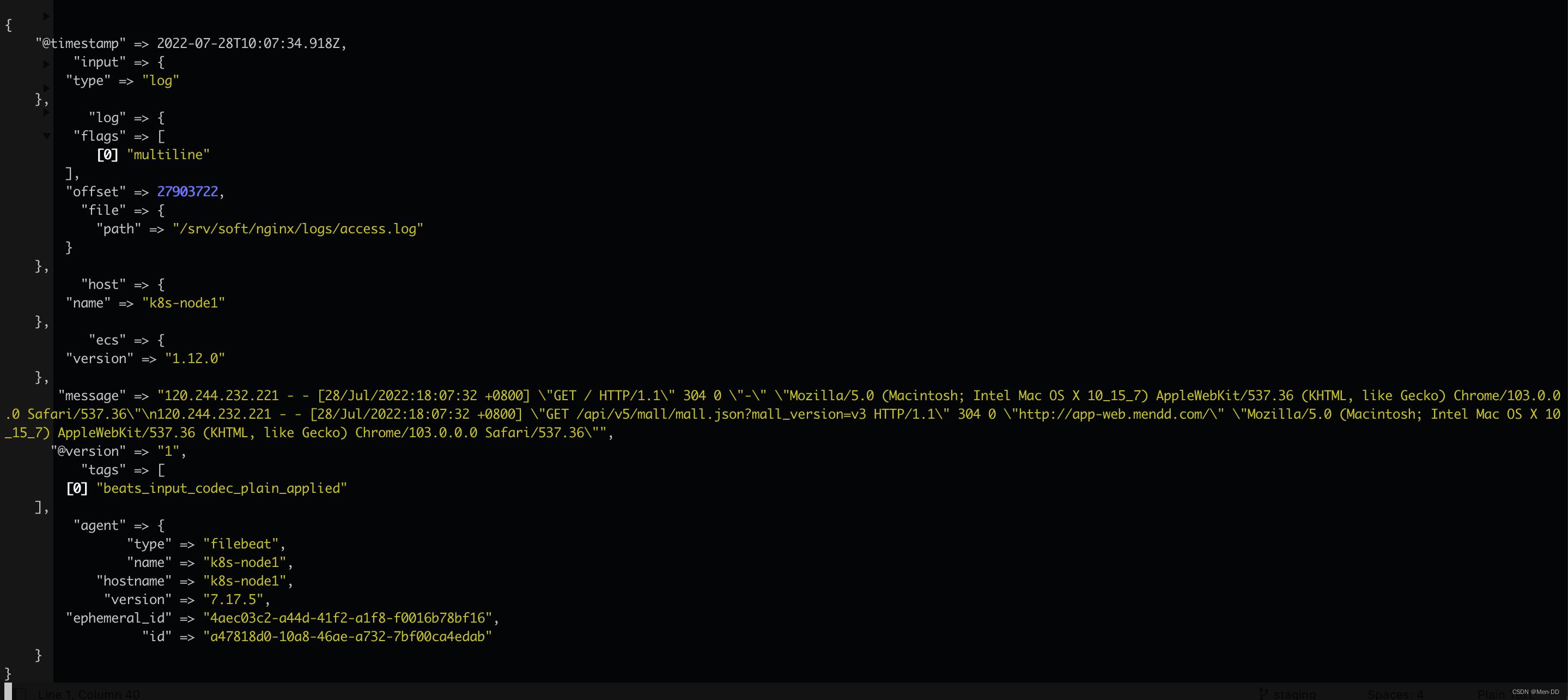
ES中会生成一个以logstash开头的索引,测试日志是否保存到了ES
get logstash- 2022.07 .28 - 000001 / _search
response
"took" : 0 ,
"timed_out" : false ,
"_shards" : "total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
,
"hits" : "total" : "value" : 1 ,
"relation" : "eq"
,
"max_score" : 1.0 ,
"hits" : [
"_index" : "logstash-2022.07.28-000001" ,
"_type" : "_doc" ,
"_id" : "
ELK 架构之 Elasticsearch 和 Kibana 安装配置
阅读目录:
1. ELK Stack 简介 2. 环境准备 3. 安装 Elasticsearch 4. 安装 Kibana 5. Kibana 使用 6. Elasticsearch 命令
最近在开发分布式服务追踪,使用 Spring Cloud Sleuth Zipkin + Stream + RabbitMQ 中间件,默认使用内存存储数据,但这样应用于生产环境,就不太合适了。
最终我采用的方案:服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana 。
这篇文章主要记录 Elasticsearch 和 Kibana 环境的配置,以及采集服务追踪数据的显出处理。
1. ELK Stack 简介
ELK 是三个开源软件的缩写,分别为:Elasticsearch、Logstash 以及 Kibana,它们都是开源软件。不过现在还新增了一个 Beats,它是一个轻量级的日志收集处理工具(Agent),Beats 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具,目前由于原本的 ELK Stack 成员中加入了 Beats 工具所以已改名为 Elastic Stack。
根据 Google Trend 的信息显示,Elastic Stack 已经成为目前最流行的集中式日志解决方案。
Elastic Stack 包含:
Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。详细可参考 Elasticsearch 权威指南 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 Elasticsearch 上去。Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。Beats 在这里是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。
目前 Beats 包含六种工具:
Packetbeat : 网络数据(收集网络流量数据)Metricbeat : 指标(收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)Filebeat : 日志文件(收集文件数据)Winlogbeat : windows 事件日志(收集 Windows 事件日志数据)Auditbeat :审计数据(收集审计日志)Heartbeat :运行时间监控(收集系统运行时的数据)
ELK 简单架构图:
2. 环境准备
服务器环境:Centos 7.0(目前单机,后续再部署集群)
Elasticsearch 和 Logstash 需要 Java 环境,Elasticsearch 推荐的版本为 Java 8,安装教程:确定稳定的 Spring Cloud 相关环境版本
另外,我们需要修改下服务器主机信息:
[root@node1 ~]# vi /etc/hostname
node1
[root@node1 ~]# vi /etc/hosts
192.168.0.11 node1
127.0.0.1 node1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 node1 localhost localhost.localdomain localhost6 localhost6.localdomain6
注意:我之前安装 Elasticsearch 和 Kibana 都是最新版本(6.x),但和 Spring Cloud 集成有些问题,所以就采用了 5.x 版本(具体 5.6.9 版本)
3. 安装 Elasticsearch
运行以下命令将 Elasticsearch 公共 GPG 密钥导入 rpm:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在/etc/yum.repos.d/目录中,创建一个名为elasticsearch.repo的文件,添加下面配置:
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
Elasticsearch 源创建完成之后,通过 makecache 查看源是否可用,然后通过 yum 安装 Elasticsearch:
[root@node1 ~]# yum makecache && yum install elasticsearch -y
修改配置(启动地址和端口):
[root@node1 ~]# vi /etc/elasticsearch/elasticsearch.yml
network.host: node1 # 默认localhost,自定义为ip
http.port: 9200
要将 Elasticsearch 配置为在系统引导时自动启动,运行以下命令:
[root@node1 ~]# sudo /bin/systemctl daemon-reload
[root@node1 ~]# sudo /bin/systemctl enable elasticsearch.service
Elasticsearch 可以按如下方式启动和停止:
[root@node1 ~]# sudo systemctl start elasticsearch.service
[root@node1 ~]# sudo systemctl stop elasticsearch.service
列出 Elasticsearch 服务的日志:
[root@node1 ~]# sudo journalctl --unit elasticsearch
-- Logs begin at 三 2018-05-09 10:13:46 CEST, end at 三 2018-05-09 10:53:53 CEST. --
5月 09 10:53:43 node1 systemd[1]: [/usr/lib/systemd/system/elasticsearch.service:8] Unknown lvalue \'RuntimeDirectory\' in section \'Service\'
5月 09 10:53:43 node1 systemd[1]: [/usr/lib/systemd/system/elasticsearch.service:8] Unknown lvalue \'RuntimeDirectory\' in section \'Service\'
5月 09 10:53:48 node1 systemd[1]: Starting Elasticsearch...
5月 09 10:53:48 node1 systemd[1]: Started Elasticsearch.
5月 09 10:53:48 node1 elasticsearch[2908]: which: no java in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin)
5月 09 10:53:48 node1 elasticsearch[2908]: could not find java; set JAVA_HOME or ensure java is in PATH
5月 09 10:53:48 node1 systemd[1]: elasticsearch.service: main process exited, code=exited, status=1/FAILURE
5月 09 10:53:48 node1 systemd[1]: Unit elasticsearch.service entered failed state.
出现了错误,具体信息是未找到JAVA_HOME环境变量,但我们明明已经配置过了。
解决方式(参考资料:https://segmentfault.com/q/1010000004715131):
[root@node1 ~]# vi /etc/sysconfig/elasticsearch
JAVA_HOME=/usr/local/java
重新启动:
sudo systemctl restart elasticsearch.service
或者通过systemctl命令,查看 Elasticsearch 启动状态:
[root@node1 ~]# systemctl status elasticsearch.service
elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled)
Active: active (running) since 一 2018-05-14 05:13:45 CEST; 4h 5min ago
Docs: http://www.elastic.co
Process: 951 ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec (code=exited, status=0/SUCCESS)
Main PID: 953 (java)
CGroup: /system.slice/elasticsearch.service
└─953 /usr/local/java/bin/java -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingO...
5月 14 05:13:45 node1 systemd[1]: Started Elasticsearch.
发现 Elasticsearch 已经成功启动。
查看 Elasticsearch 信息:
[root@node1 ~]# curl -XGET \'http://node1:9200/?pretty\'
{
"name" : "AKmrtMm",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "r7lG3UBXQ-uTLHInJxbOJA",
"version" : {
"number" : "5.6.9",
"build_hash" : "877a590",
"build_date" : "2018-04-12T16:25:14.838Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
4. 安装 Kibana
运行以下命令将 Elasticsearch 公共 GPG 密钥导入 rpm:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在/etc/yum.repos.d/目录中,创建一个名为kibana.repo的文件,添加下面配置:
[kibana-5.x]
name=Kibana repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
安装 Kibana:
[root@node1 ~]# yum makecache && yum install kibana -y
修改配置(地址和端口,以及 Elasticsearch 的地址,注意server.host只能填写服务器的 IP 地址):
[root@node1 ~]# vi /etc/kibana/kibana.yml
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is \'localhost\', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "192.168.0.11"
# The Kibana server\'s name. This is used for display purposes.
server.name: "kibana-server"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://node1:9200"
# 配置kibana的日志文件路径,不然默认是messages里记录日志
logging.dest: /var/log/kibana.log
创建日志文件:
[root@node1 ~]# touch /var/log/kibana.log; chmod 777 /var/log/kibana.log
要将 Kibana 配置为在系统引导时自动启动,运行以下命令:
[root@node1 ~]# sudo /bin/systemctl daemon-reload
[root@node1 ~]# sudo /bin/systemctl enable kibana.service
Kibana 可以如下启动和停止
[root@node1 ~]# sudo systemctl start kibana.service
[root@node1 ~]# sudo systemctl stop kibana.service
查看启动日志:
[root@node1 ~]# sudo journalctl --unit kibana
5月 09 11:14:48 node1 systemd[1]: Starting Kibana...
5月 09 11:14:48 node1 systemd[1]: Started Kibana.
然后浏览器访问:http://node1:5601
初次使用时,会让你配置一个默认的 index,也就是你至少需要关联一个 Elasticsearch 里的 Index,可以使用 pattern 正则匹配。
注意:如果 Elasticsearch 中没有数据的话,你是无法创建 Index 的。
如果 Spring Cloud Sleuth Zipkin + Stream + RabbitMQ 配置正确的话(以后再详细说明),服务追踪的数据就已经存储在 Elasticsearch 中了。
5. Kibana 使用
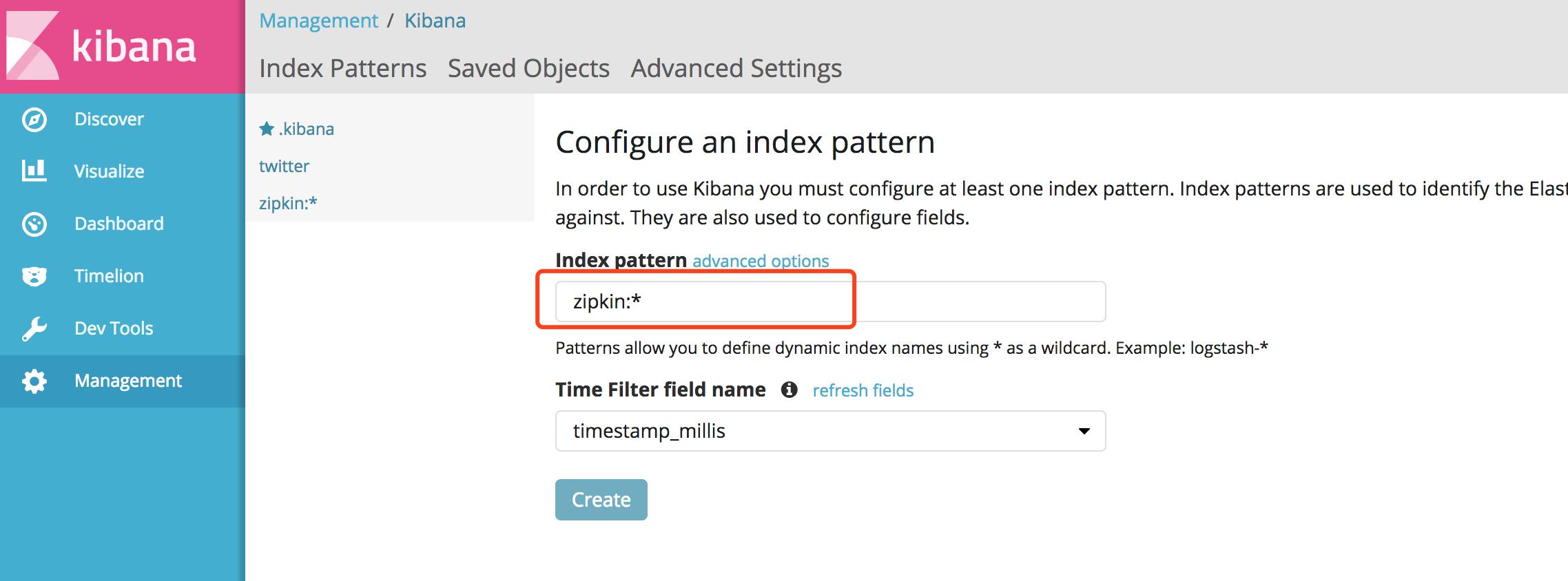
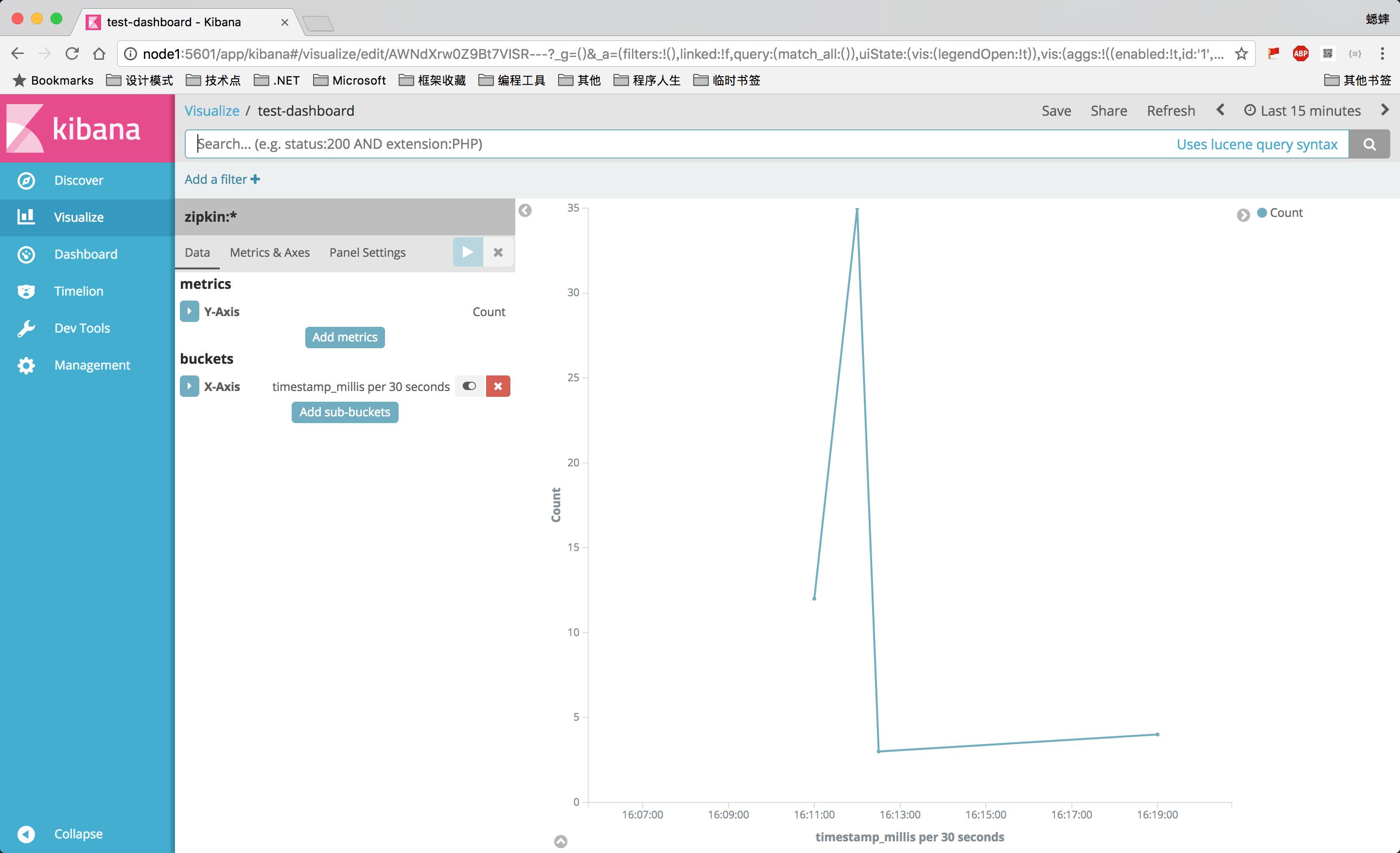
创建zipkin:*索引(*匹配后面所有字符):
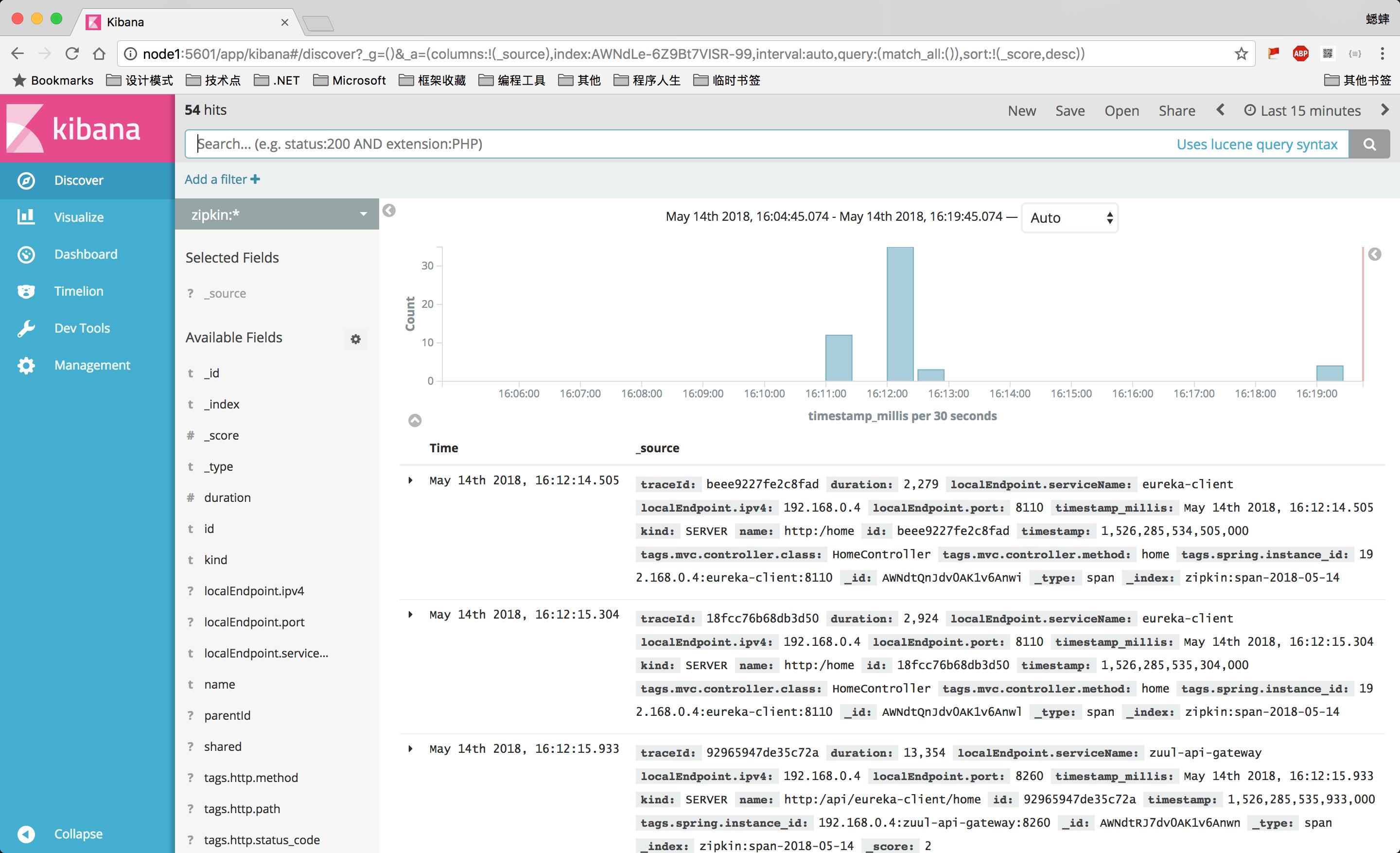
然后就可以查看服务追踪的数据了:
也可以创建自定义仪表盘:
6. Elasticsearch 命令
创建索引:
$ curl -XPUT \'http://node1:9200/twitter\'
查看 Index 索引列表:
$ curl -XGET http://node1:9200/_cat/indices
yellow open twitter k1KnzWyYRDeckjt7GASh8w 5 1 1 0 5.1kb 5.1kb
yellow open .kibana 8zJGQkq8TwC4s3JJLMX44g 1 1 1 0 4kb 4kb
yellow open student iZPqPcwrQbifGOfE9DQYvg 5 1 0 0 955b 955b
添加 Document 数据:
$ curl -XPUT \'http://node1:9200/twitter/tweet/1\' -d \'{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elastic Search"
}\'
获取 Document 数据:
$ curl -XGET \'http://node1:9200/twitter/tweet/1\'
{"_index":"twitter","_type":"tweet","_id":"1","_version":1,"found":true,"_source":{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elastic Search"
}}%
查询zipkin索引下面的数据:
$ curl -XGET \'http://node1:9200/zipkin:*/_search\'
参考资料:
以上是关于ElasticSearch:ELK 架构的主要内容,如果未能解决你的问题,请参考以下文章