vue前台 pdf.js瀑布流式加载大文件
Posted zwbsoft
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了vue前台 pdf.js瀑布流式加载大文件相关的知识,希望对你有一定的参考价值。
一,需求背景
在.NetCore新版项目中,针对电子文件在线浏览的实现方案做出了调整,由于需要支持跨平台,因此摒弃掉原来使用的第三方控件的方式。目前对于PDF文件的在线浏览采用的开源JS框架PDF.JS。它功能还是比较强大的,支持常用的PDF预览效果,文件下载和打印等等功能。
但如果PDF文件较大或者页数过多时,会发现PDF.JS需要等待很长时间才能将整个文件加载出来,这样用户的使用体验是不佳的,因为较长时间迷茫的等待,并且没有任何进度条提醒,会给人一种不知道是单纯的加载文件慢还是加载遇到了错误?到底该不该继续等待加载?的感觉,以至于失去耐心。
那么如何解决这种“迷茫等待”的粗劣使用体验呢?PDF.JS瀑布流加载机制应运而生......
二,前端请求机制
PDF.JS用于浏览文件的自带html页面是viewer.html,因此浏览文件都是需要跳转到该页面。
PDF.JS加载文件是有两种方式的:
(1)如图2-1.png所示,该前台页面通过ajax请求后台接口,从而获得要浏览的文件的base64格式的字符串,然后通过JS的一系列转换,生成PDF.JS能识别的数据格式,最后再对DEFAULT_URL变量进行赋值即可。

(2)JS中直接通过对html中的<iframe>控件绑定地址链接到viewer.html页面,并且需要将要浏览的文件流作为file参数传递过去,而这个文件流参数是通过get请求后台返回文件流的接口来获取的。前台示例代码如下:
document.getElementById("if1").src = \'/static/pdf/web/viewer.html?file=\'+encodeURIComponent(window.localStorage.getItem("rooturl")+\'/api/OnlineView/GetFileStreamPDF?syscode=\'+data.syscode+\'&unitsys=\'+this.$store.state.user.unit+"&username="+this.$store.state.user.name);
三,利弊对比
(1)上面第一种方式相当于把整个文件的全部数据通过一次接口请求全部获取并返回给前台PDF.JS进行渲染加载。
这种方式的优点是:前后台请求次数少只有一次,保留了文件整体性,文件的各个页会同时加载出来;
不过该方式缺点也很明显:如果文件很大或页数很多时,需要等待很长时间才能加载出文件;
(2)上面第二种方式相当于把一个文件进行分段请求和加载,PDF.JS也是支持这种加载方式的。
这种方式的优点是:可以让用户更快的先看到一部分页面,剩余页面的加载进度也可以通过界面上的加载进度条直观的体现出来。不但可以更快的浏览到一些文件页面,而且还能对加载的整体进度做到心里有数;
该方式的缺点是:需要很多次的频繁请求后台,虽然可以让用户提前浏览到一些页面,但是从文件开始加载到最终完成加载所用到的时间总和一定是要多余第一种方式的。而且分段加载的先后顺序不能很好的控制,有可能出现文件的最后一页加载完成,但是中间的某些页还没有加载出来的现象;
四,后台核心实现机制
为了提升用户浏览大文件的使用体验,我采用了PDF.JS的第二种方式。那么后台接口的写法和返回数据的格式都要有所讲究,因为需要支持分批请求加载的机制。
整体执行过程为前台第一次请求后台接口返回的响应编码为200,然后会连续不断的分批次请求后台接口,且每次请求头中会附带一个range参数表明当前请求要读取的起止位置,一直到整个文件全部加载完成为止。后续的每次请求都会向前台返回一段范围的文件流供前台渲染,且返回的响应编码均为206;
后台接口核心代码如图2-2.png所示,需要先将PDF文件从mongodb服务器上下载到项目运行目录中的临时文件中,然后通过File.Open()方法将文件转成FileStream。
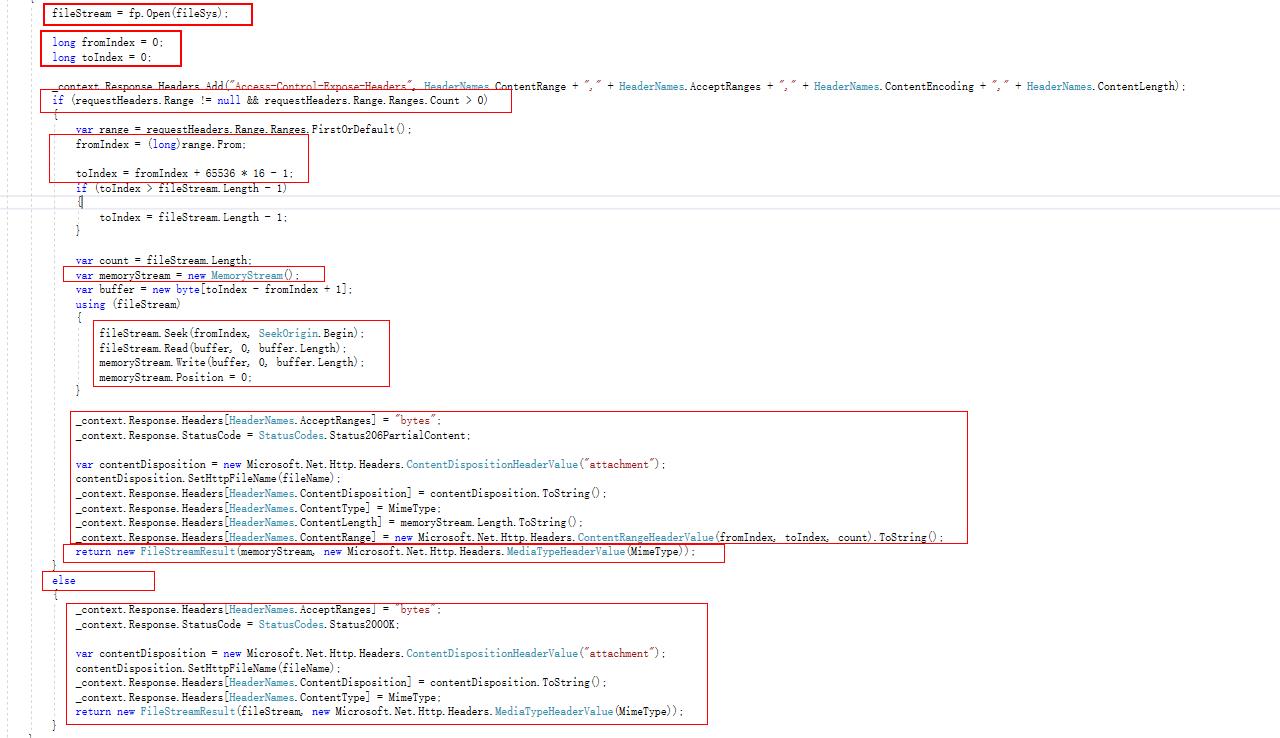
(1)当首次请求后台时,请求头是不带分段请求相关参数Range的,所以会进入else逻辑中。
这时需要将响应头中添加AcceptRanges值为bytes;
响应状态编号赋值成200;
最终向前台返回的是FileStreamResult文件流类型数据,并且直接把文件的FileStream作为参数返回;
(2)后续的后台请求时,请求头中就已经附带分段请求相关的Range参数,所以进入截图中的if逻辑中。
Range相关参数主要有From和To,其中From表示从哪里开始读取,To表示读取到哪;
这里我让每次请求默认读取1MB大小范围的文件流,所以读取终止位置没有取range.To参数(因为range.To参数默认每次只读取64KB大小的范围,为了减少请求后台的次数,我将终止位置设置为起始位置加上1MB的位置)。
然后通过stream的seek()方法定位到当前的起始位置,并将指定长度范围内的文件流写入MemoryStream中,最终也是将该MemoryStream流作为参数通过FileStreamResult类型向前台返回;
其中响应头还是要添加AcceptRanges值为bytes;
响应状态编号要赋值成206;
响应头要添加ContentLength为MemoryStream的长度;
响应头要添加ContentRange参数,这也是最核心的一个范围类型参数,通过ContentRangeHeaderValue类型传递,其中三个参数分别为本次读取的起始位置,结束位置,和读取长度;
五,注意事项
(1)浏览文件时如果直接对从mongodb上获取的文件流进行分段截取,返回到前台PDF.JS时会报JS跨域错误。因此解决的办法是先将文件保存至一个项目运行的临时目录中,然后通过File.Open方法打开文件流,供后续的分段截取;
(2)考虑到下载到临时目录中的文件名可能存在重复的情况,因此采用文件在mongodb上的唯一ID值作为文件名称,如果一个文件浏览过了,当再次浏览时不需再次下载而是直接去读取临时目录中已保存过的文件。临时目录中的文件会定期去进行统一删除;
(3)前台PDF.JS每次获取后台返回的响应头信息时,会报JS错误(默认会认为这些响应头不是安全的),因此后台接口响应头中要多加一个“Access-Control-Expose-Headers”,并将后续用到的各种响应头名称作为参数写入该响应头中,这样前台才可以顺利接收这些响应头;
以上是关于vue前台 pdf.js瀑布流式加载大文件的主要内容,如果未能解决你的问题,请参考以下文章