Eth2.0 -合并(Merge)
Posted 兰陵97
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Eth2.0 -合并(Merge)相关的知识,希望对你有一定的参考价值。
Eth2.0 - Merge
原文链接:How The Merge Impacts Ethereum’s Application Layer
日期:2021/11/29
作者: Tim Beiko
以太坊即将向POS过渡,如何保证过渡时对以太坊的用户,智能合约和dapps提供最小的影响,即合并(The Merge)。如果相对合并有个总体上的理解,可以参考:
- Roadmap evolution
- Post-merge client architecture
想要更深一步了解,可以参考 - Execution Layer
- Consensus Layer
- Engine API
Block structure
合并后, 不会再使用POW共识算法生成新的区块了,以前的POW区块将会作为信标链的一部分,信标链将成为以太坊新的POS共识层。信标区块将包含 ExecutionPayloads字段, ExecutionPayloads就相当于POW区块。下图展示了信标区块和POW区块的关系:
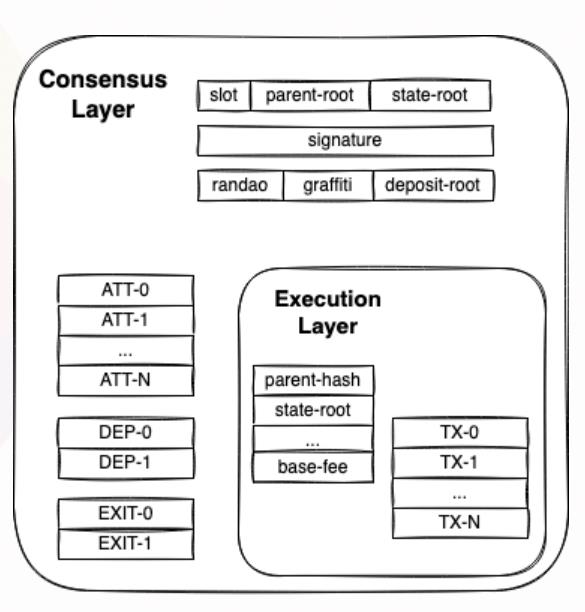
对于终端用户和App开发者来说,ExecutionPayloads是原POW链和信标链交流的地方。在这层上的交易仍由执行层客户端(execution layer clients:Besu, Erigon, Geth, Nethermind)处理。幸运的是,由于执行层的稳定,合并只会给Eth2带来很小的影响。
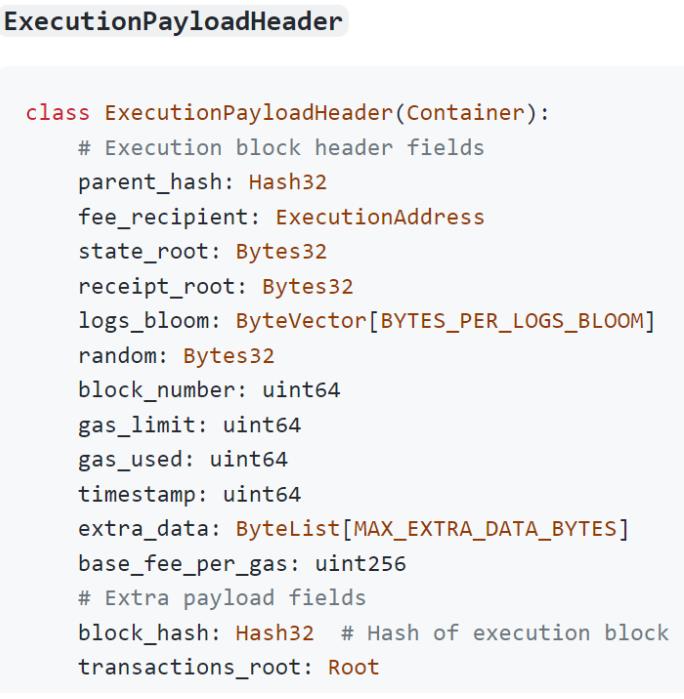
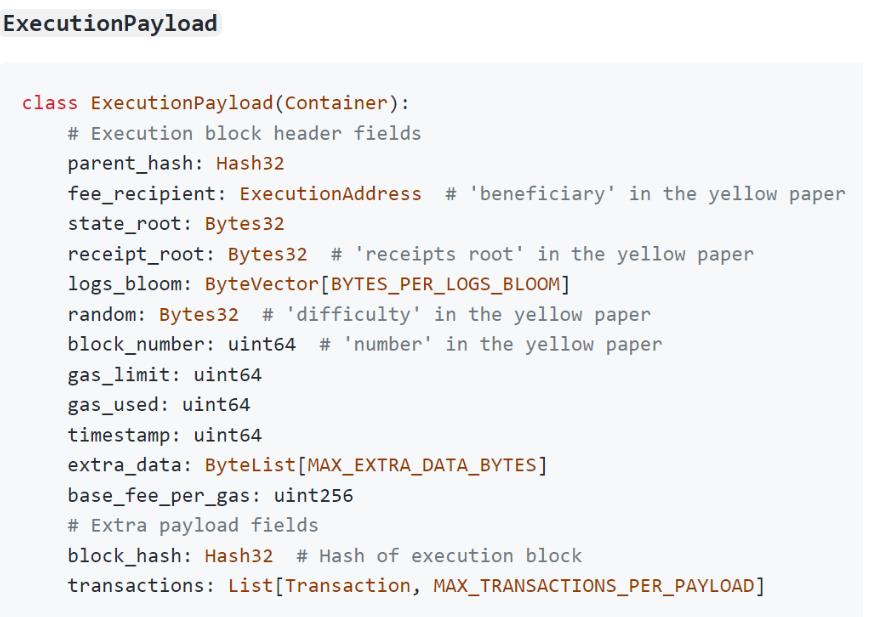
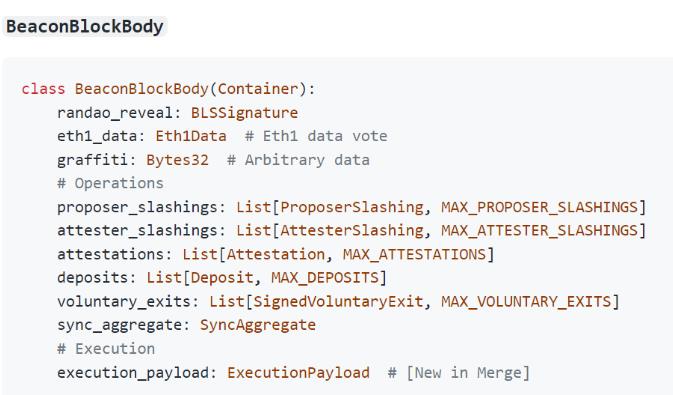
- 上图中的下面三张图片是从官网截下的图片, 分别是合并后的ExecutionPayloads、信标区块体(BeaconBlockBody)的数据结构。我们可以对比ExecutionPayloads和POW区块的数据结构, 可以发现两者的数据结构相似。同时信标区块体中包含ExecutionPayloads字段,说明该字段是信标链和分片链(原POW链)通信的关键所在。目前只有一个分片链, 那么未来要扩展到64条分片链后,这个字段会不会是一个列表呢?唯一让我疑惑是:合并后的BeaconBlockBody中为啥还有eth1_data字段, 难道是记录以前的POW区块,以及BeaconBlockBody字段的数据存储量是不是太大了?
- Eth2的整体架构就是信标链作为管理链来协调各个分片链,交易的处理都是在分片链上完成的,所以在Eth2上把分片链称为执行层,而目前分片链并未上线,只有原始的POW链作为一条分片链。在合并之前的阶段,POW链和信标链是各自挖矿的,共识算法也不一样,两条不同共识链的连接是通过信标区块体(BeaconBlockBody)中的eth1_data实现的。在合并后,POW就会被废除, 原本的POW链将转为POS链,即分片链。而我们知道原本的POW链之前一直都是稳定运行的,所以上文会说到“执行层的稳定,合并只会给Eth2带来很小的影响”, 这里的执行层就是指原来的POW链转成POS链。
- 目前,合并阶段仍然在开发中。
Mining & Ommer Block Fields
合并后, 以前在POW区块头的几个字段将不再使用,因为它们和POS链无关。为了减少对现有ETH的影响,这些字段被设置为0或者其他等价的数据结构。区块发生哪些改变,可以具体参考这里。主要包含一下字段:
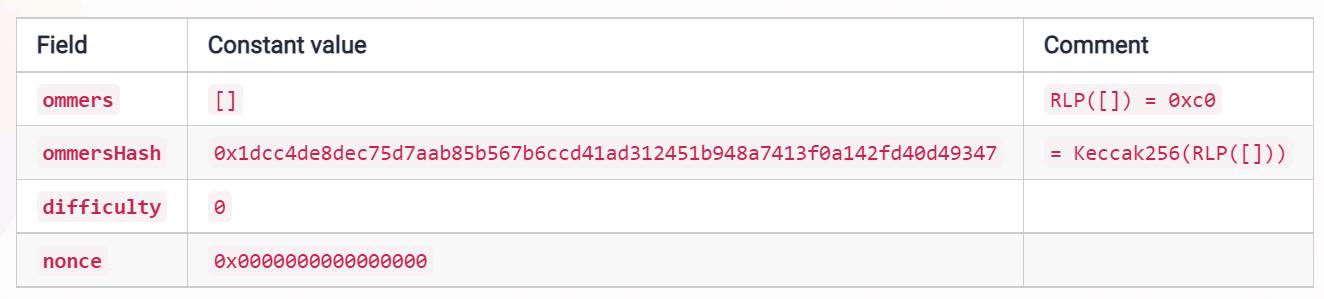
POS链不会生产叔父区块了,所有ommers置为空,ommerHash也就置为空列表。同时也不再挖矿了, 所以difficulty、nonce也没了。
但是, 原先的mixHash字段会被置为Eth2.0的信标链的RANDAO字段。下面会做介绍。
mixHash字段:一个256位的哈希值,用来与Nonce一起证明当前区块已经执行了足够的计算量
BLOCKHASH & DIFFICULTY opcodes changes
合并后,BLOCKHASH 操作码(opcode)仍将可供使用,但鉴于该操作码将不再通过POW共识算法中使用, 因此操作码提供的伪随机性也将大大减弱。
相反, DIFFICULTY 操作码(0x44)将被更新并重命名为RANDOM。合并后,它将返回由信标链提供的随机信标(randomness beacon)的输出。因此,对于应用程序开发人员来说,此操作码将是比BLOCKHASH更强大的随机性源(source of randomness),尽管它现在是有偏倚的。
RANDOM的值会被存储在ExecutionPayload中,也就是原先POW区中的mixHash字段,即mixHash的字段也将重命名为random。
这一段的描述和上图中ExecutionPayload数据结构中的random字段的注释有冲突,这篇博客说将mixHash被改成random, 而注释中说random原本是POW区块中的difficulty字段。虽然这地方可能有点冲突,但是我们只需要知道:POW区块中的mixHash字段和difficulty字段被废除了,在POS区块里以random方式存在
下图是DIFFICULTY & RANDOM操作码在合并前后的变化:
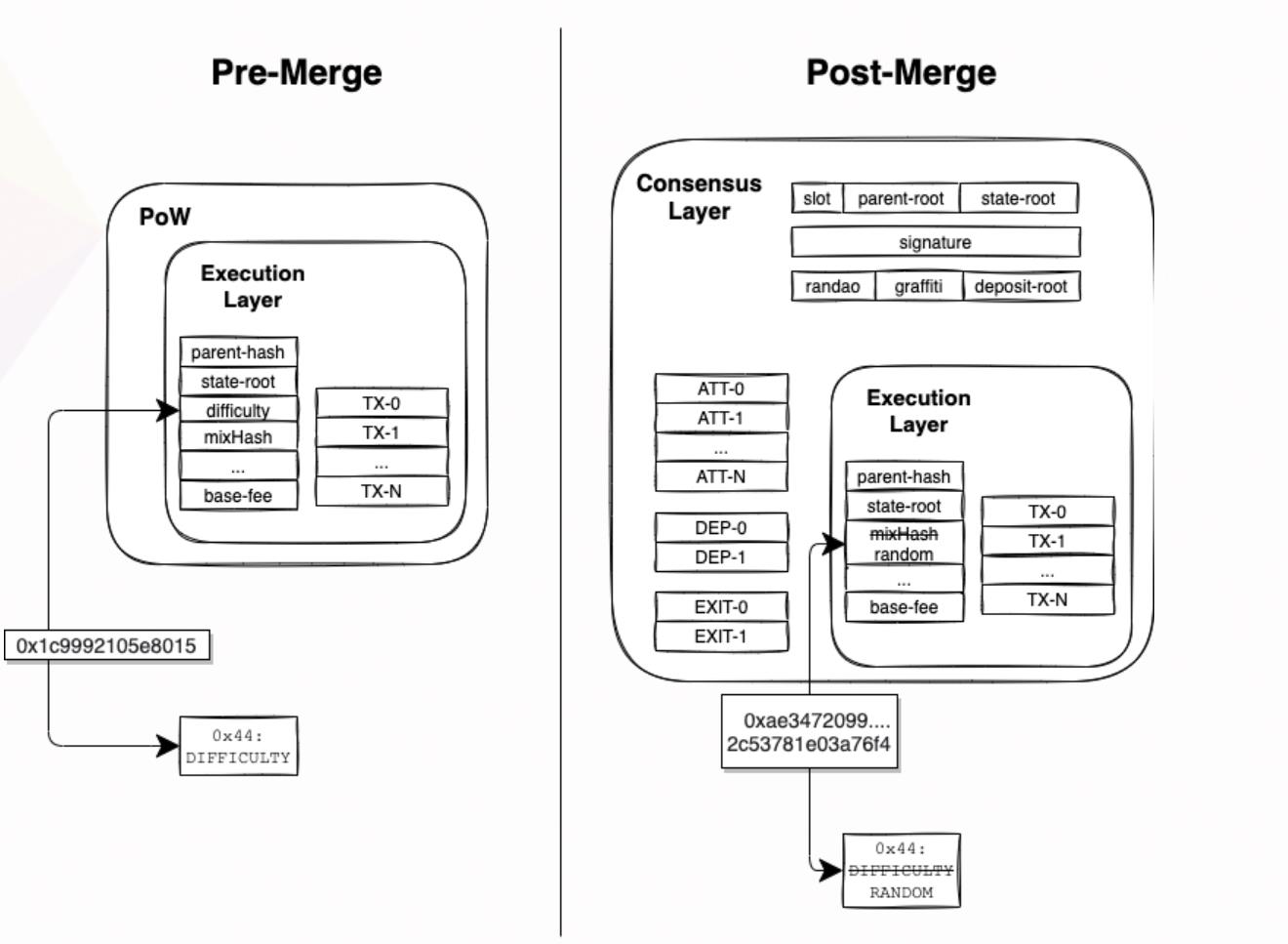 合并前,我们可以看到0x44操作码会返回区块头中difficulty字段。合并后, difficulty字段就没了,而0x44操作码返回就是信标链状态(beacon chain state)的random字段值。 这个改变也为链上应用(on-chain applications)提供了一种评估合并是否发生的方法, 详情参考 [这里](https://ethereum-magicians.org/t/eip-4399-supplant-difficulty-opcode-with-random/7368)
合并前,我们可以看到0x44操作码会返回区块头中difficulty字段。合并后, difficulty字段就没了,而0x44操作码返回就是信标链状态(beacon chain state)的random字段值。 这个改变也为链上应用(on-chain applications)提供了一种评估合并是否发生的方法, 详情参考 [这里](https://ethereum-magicians.org/t/eip-4399-supplant-difficulty-opcode-with-random/7368)
此外,该EIP提出的允许智能合约来判断是否已经升级到PoS。这可以通过分析难度操作码(DIFFICULTY opcode)的返回值来完成。当返回值大于 2**64表示交易是在PoS块中执行的
Block time
合并后,将影响以太坊的平均区块时间。目前在工作量证明中,区块平均每13秒出现一个区块,但实际出块时间有相当大的差异。而POS可以保证每隔12秒(即Slot)就会出现一个区块,除非由于验证者处于离线状态或因为它们没有及时提交区块而错过Slot。在现实中中,这种情况目前发生在<1%的Slots中。
这意味着平均出块时间减少了约 1 秒。智能合约在计算平均区块时间时需要考虑这一点。
Safe Head & Finalized Blocks
在POW共识下,区块链总是有重组(reorg)的可能性。应用程序通常需要等待在几个新区块在某个区块后被挖出,然后才会认定这个区块不太可能从合法链中删除,这个区块被确认(confirmed)。在合并之后,我们反而有了最终化(finalized )和安全头(safe head) 区块块的概念。使用这些区块比POW下"已确认"的区块更可靠,但需要理解转变才能正确使用。
一个被最终化(finalized)的区块是指已被>2/3的验证者认定为合法的区块,即被大于2/3的验证者投票。要想创建不合法的区块,攻击者必须烧毁至少 1/3 的总权益。在撰写本文时,这代表了以太坊上价值达到超过100亿美元(>250万ETH)。
安全头(safe head)区块是指在正常网络条件下,我们希望安全头被包含在合法链中。假设网络延迟小于4秒,大部分验证者都是诚实的,并且没有对分叉攻击,那么安全头永远不会被孤立。具体可以参考:Gasper High Confidence Fast Block confirmations。此外,安全头的假设和保证会在即将发表的论文中被正式定义和分析。
合并后,执行层的API(例如 JSON RPC)在请求 latest 块时将默认返回安全头。在正常网络条件下,安全头和链的实际尖端( actual tip of the chain)将是等价的(安全头仅尾随几秒钟(with safe head trailing only by a few seconds))。与当前的POW下的 latest 块证明相比,安全头被重新组织的可能性更小。为了公开POS链的实际尖端(the actual tip of the proof of stake chain),将向 JSON RPC 添加一个**unsafe ** 标志。
最终化的区块也将通过带有 finalized 标志的JSON RPC公开。这些可以作为POW的有力替代品。下表总结了这一点:

The Merge Community
问题:没看懂博客最后说的safe head是什么东西?
“整合”不同于“合并”(merge)
参考技术A Seurat V3 一度被认为是整合(Integrate,CCA+MNN)不同RNA数据集的标杆工具,在其文章Comprehensive Integration of Single-Cell Data中提到:Seurat v3引入了集成多个单细胞数据集的新方法。这些方法的目的是识别存在于不同数据集的共享的细胞状态,即使它们是从不同的个体、实验条件、技术平台甚至物种,用到的函数是FindIntegrationAnchors。业内有不少拿它和去批次的工具在一起做benchmark,其实这不是一回事。强调,整合与批次不是一回事。在V4 中整合不同的RNA数据集你依然可以用‘FindIntegrationAnchors’。在V4的WNN中也有一个“整合”,这里的整合多为多模态数据之间的整合,用到的函数FindMultiModalNeighbors。可见,这个函数在v3中对应的位置应该是FindNeighbors,即构建细胞间的图结构用的部分。然后,“整合”也不同于“合并”(merge),合并一般是在整合的前面,先把不同的dataset合并到一起看数据的最初概览,以判断需不需要整合或其他。整合这个概念是单细胞数据分析中继降维之后第二个容易语义混淆的概念。
问题:
After integration, which Assay should I use for differential expression testing?
首先,做差异分析用到的数据是integration之前的RNA
We recommend running your differential expression tests on the original / unintegrated data. By default this is stored in the RNA Assay. The integration procedure inherently introduces dependencies between data points. This violates the assumptions of the statistical tests used for differential expression.
原文链接
以上是关于Eth2.0 -合并(Merge)的主要内容,如果未能解决你的问题,请参考以下文章
万向区块链蜂巢学院 | 关于ETH2.0路线图,搞研究的大脑在想什么?
深度 | Eth2.0将要实现的Sharding(分片)是什么?